prefacio
Debido al plan de capacitación y otras razones, recientemente trabajé como pasante en una empresa de visión artificial. Actualmente estoy usando el marco MMDetection. Quiero intentar usar Mask-RCNN para la capacitación de conjuntos de datos personalizados (de la empresa) y registrar la capacitación. proceso.
1. Producción de conjuntos de datos
Yo uso labelme. En primer lugar, conda activa un entorno (suponiendo que sea openmmlab), pip install labelme y se inicia en el entorno una vez completada la instalación (ingrese directamente labelme). Se omite el método específico de etiquetar el conjunto de datos, es relativamente simple y el tutorial en línea es muy amigable. Después de marcar, se generará un archivo json, que debe convertirse en un archivo coco o voc, pero para el entrenamiento, debe convertirse en un conjunto de datos COCO o un conjunto de datos VOC. El método específico es el siguiente: 1. Dividir el conjunto de verificación de conjunto de datos, pero las imágenes no se pueden guardar
automáticamente 2. Enlace de conjunto de datos oficial a COCO 3.
Enlace de conjunto de datos oficial a VOC 4. Pruebe su método la próxima vez que cree un conjunto de datos 5. Una nota al etiquetar instancias y segmentar conjuntos de datos
Dos, parte de entrenamiento de MMdetection
El método de conjunto de datos personalizado del sitio web oficial
todavía se encuentra en la etapa de imitación debido a los principiantes. Consulte el sitio web oficial para entrenar el conjunto de datos de globo personalizado. Primero, cree un archivo de configuración box_img en la carpeta de configuraciones y cree un archivo py en él. El archivo se nombra de acuerdo con el formato, y también se puede personalizar, como siempre y cuando estés cómodo. el código se muestra a continuación:

# 官方文档里的配置代码
# 新配置继承了基本配置,并做了必要的修改
# 不同数据集他继承的文件也不一样
_base_ = '../mask_rcnn/mask-rcnn_r101_fpn_2x_coco.py'
# 我们还需要更改 head 中的 num_classes 以匹配数据集中的类别数
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=1), mask_head=dict(num_classes=1)))
# 修改数据集相关配置
data_root = '../data/box_img/'
metainfo = {
'classes': ('box', ),
'palette': [
(220, 20, 60),
]
}
# 根据自己放数据集的位置进行修改
train_dataloader = dict(
batch_size=1,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/')))
val_dataloader = dict(
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/')))
test_dataloader = val_dataloader
# 修改评价指标相关配置
val_evaluator = dict(ann_file=data_root + 'annotations/instances_val2017.json')
test_evaluator = val_evaluator
# 使用预训练的 Mask R-CNN 模型权重来做初始化,可以提高模型性能 他会下载到一个cache文件夹内,不知道在哪里改,强迫症犯了
load_from = 'https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco_bbox_mAP-0.408__segm_mAP-0.366_20200505_071027-14b391c7.pth'
Después de eso, puede ejecutar train.py, solo agregue algunos parámetros necesarios y no necesita cambiar el resto.
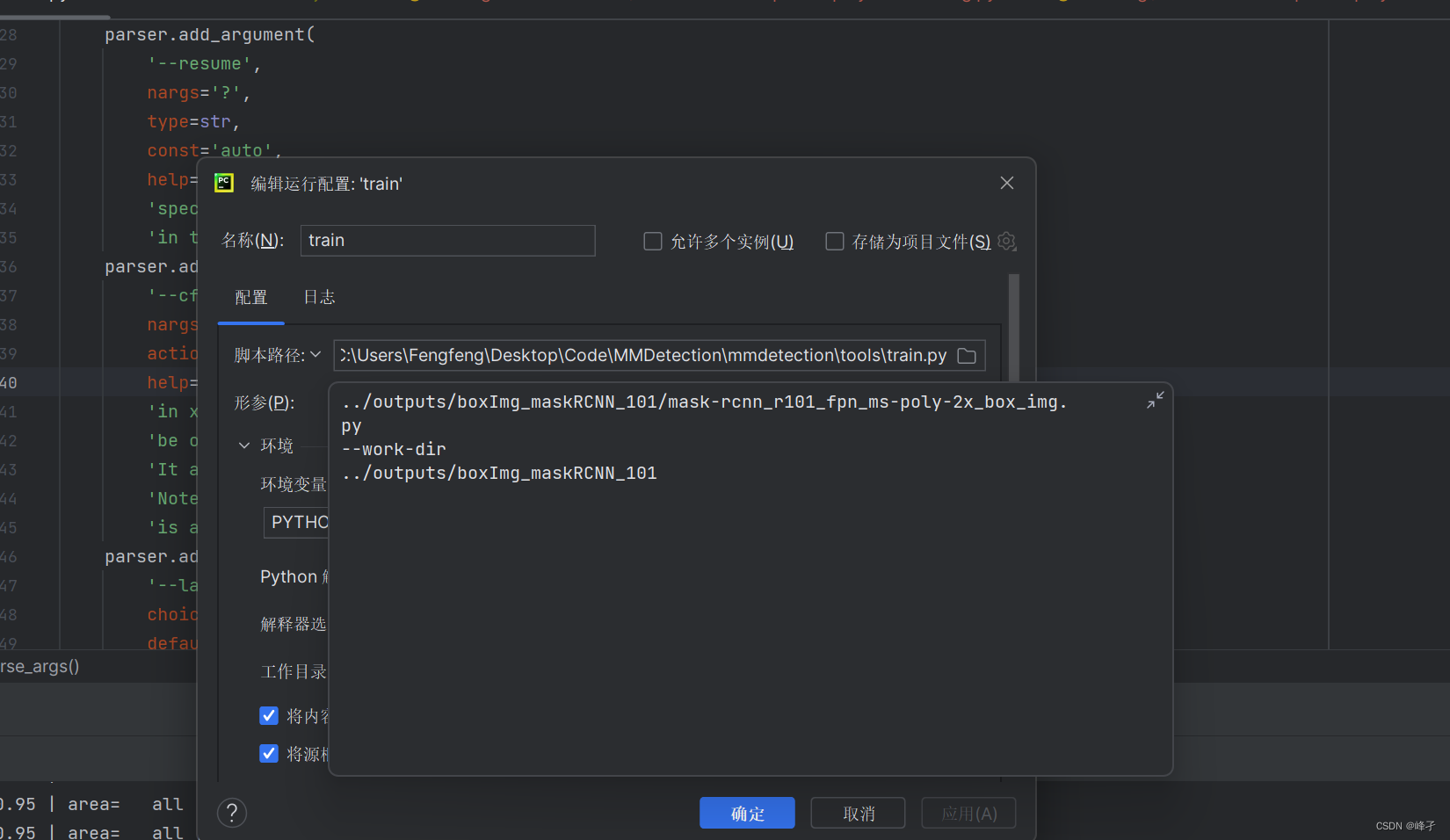
Después de comenzar el entrenamiento, se creará una carpeta con nombre de tiempo y un archivo de configuración más detallado en output/boxImg_maskRCNN_101, que es el archivo py en la figura a continuación (epoch se generó durante mi último proceso de entrenamiento, y es razonable que sea aún no está allí)
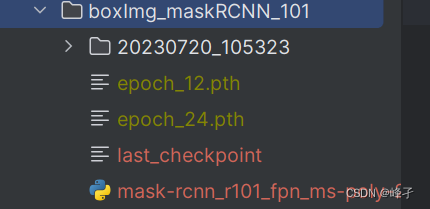
Posteriormente, en este archivo, el modelo se modifica aún más, como cuántas épocas se guardan cada vez, cuál es el intervalo de guardado del registro, etc. Después de la modificación, cambie el archivo py en la configuración del tren al de arriba , vuelva a ejecutar el archivo train.py y comience a entrenar.
3. Parte de prueba
No hay mucho que decir, el test.py es bastante detallado, solo agregue elementos de configuración de acuerdo con el formato