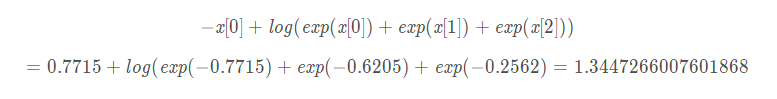ImageFolder para cargar conjuntos de datos
ImageFolderUn cargador de datos general, los datos en el conjunto de datos se organizan de la siguiente manera
La función es la siguiente
ImageFolder(root, transform``=``None``, target_transform``=``None``, loader``=``default_loader)
Explicación de parámetros
-
La raíz especifica la ruta para cargar la imagen.
-
transform: operación de transformación realizada en la imagen PIL, la entrada de transform es el objeto devuelto de usar el cargador para leer la imagen
-
target_transform: transformación de etiqueta
-
cargador: Cómo leer la imagen después de una ruta determinada, el valor predeterminado es leer el objeto Imagen PIL en formato RGB
La etiqueta se almacena en un diccionario después de ordenar en el orden del nombre de la carpeta, es decir, {nombre de clase: número de clase (comenzando desde 0)}. En términos generales, es mejor nombrar la carpeta directamente con un número que comienza desde 0, que será consistente con el ImageFolderreal label, si no es por esta convención de nomenclatura, se recomienda mirar los self.class_to_idxatributos para comprender la relación de mapeo entre la etiqueta y el nombre de la carpeta
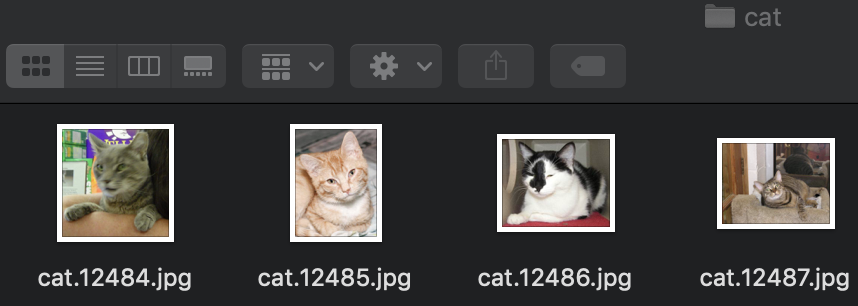
Se puede ver que se divide en dos categorías: gato y perro.
import torchvision.datasets as dset
dataset = dset.ImageFolder('./data/dogcat_2') #没有transform,先看看取得的原始图像数据
print(dataset.classes) #根据分的文件夹的名字来确定的类别
print(dataset.class_to_idx) #按顺序为这些类别定义索引为0,1...
print(dataset.imgs) #返回从所有文件夹中得到的图片的路径以及其类别
regreso
['cat', 'dog']
{
'cat': 0, 'dog': 1}
[('./data/dogcat_2/cat/cat.12484.jpg', 0), ('./data/dogcat_2/cat/cat.12485.jpg', 0), ('./data/dogcat_2/cat/cat.12486.jpg', 0), ('./data/dogcat_2/cat/cat.12487.jpg', 0), ('./data/dogcat_2/dog/dog.12496.jpg', 1), ('./data/dogcat_2/dog/dog.12497.jpg', 1), ('./data/dogcat_2/dog/dog.12498.jpg', 1), ('./data/dogcat_2/dog/dog.12499.jpg', 1)]
Ver los datos de imagen obtenidos:
#从返回结果可见得到的数据仍是PIL Image对象
print(dataset[0])
print(dataset[0][0])
print(dataset[0][1]) #得到的是类别0,即cat
regreso:
(<PIL.Image.Image image mode=RGB size=497x500 at 0x11D99A9B0>, 0)
<PIL.Image.Image image mode=RGB size=497x500 at 0x11DD24278>
0
Y luego transformconviértete en tensor
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor()
])}
train_dataset = datasets.ImageFolder(root=os.path.join(data_root, "train"),
transform=data_transform["train"])
print(train_dataset[0])
print(train_dataset[0][0])
print(train_dataset[0][1]) #得到的是类别0,即cat
obtener
(tensor([[[0.3765, 0.3765, 0.3765, ..., 0.3765, 0.3765, 0.3765],
[0.3765, 0.3765, 0.3765, ..., 0.3765, 0.3765, 0.3765],
[0.3804, 0.3804, 0.3804, ..., 0.3765, 0.3765, 0.3765],
...,
[0.4941, 0.4941, 0.4902, ..., 0.3804, 0.3765, 0.3765],
[0.5098, 0.5098, 0.5059, ..., 0.3804, 0.3765, 0.3765],
[0.5098, 0.5098, 0.5059, ..., 0.3804, 0.3765, 0.3765]],
[[0.5686, 0.5686, 0.5686, ..., 0.5843, 0.5804, 0.5804],
[0.5686, 0.5686, 0.5686, ..., 0.5843, 0.5804, 0.5804],
[0.5725, 0.5725, 0.5725, ..., 0.5843, 0.5804, 0.5804],
...,
[0.5686, 0.5686, 0.5686, ..., 0.5961, 0.5922, 0.5922],
[0.5686, 0.5686, 0.5686, ..., 0.5961, 0.5922, 0.5922],
[0.5686, 0.5686, 0.5686, ..., 0.5961, 0.5922, 0.5922]],
[[0.4824, 0.4824, 0.4824, ..., 0.4902, 0.4902, 0.4902],
[0.4824, 0.4824, 0.4824, ..., 0.4902, 0.4902, 0.4902],
[0.4863, 0.4863, 0.4863, ..., 0.4902, 0.4902, 0.4902],
...,
[0.3647, 0.3686, 0.3804, ..., 0.4824, 0.4784, 0.4784],
[0.3451, 0.3490, 0.3608, ..., 0.4824, 0.4784, 0.4784],
[0.3451, 0.3490, 0.3608, ..., 0.4824, 0.4784, 0.4784]]]), 0)
省略
图像Tensor [........]
标签Tensor [0]
Puedes saber train_dataset[0]que uno tuplees tensor y el otro es escalar
print(train_dataset[0][0].shape)
print(train_dataset[0][1])
regreso
torch.Size([3, 224, 224])
0
DataLoader genera datos de entrenamiento por lotes
for epoch in range(epoch_num):
for image, label in train_loader:
print("label: ", labels, labels.dtype)
print("imges: ", images, images.dtype)
regreso
label: tensor([0]) torch.int64
imges: tensor([[[[0.2275, 0.2275, 0.2235, ..., 0.2196, 0.2196, 0.2196],
[0.2275, 0.2275, 0.2235, ..., 0.2196, 0.2196, 0.2196],
[0.2235, 0.2235, 0.2235, ..., 0.2157, 0.2157, 0.2157],
...,
[0.2392, 0.2392, 0.2392, ..., 0.2235, 0.2235, 0.2235],
[0.2353, 0.2353, 0.2353, ..., 0.2235, 0.2275, 0.2275],
[0.2353, 0.2353, 0.2353, ..., 0.2235, 0.2275, 0.2275]],
[[0.2392, 0.2392, 0.2353, ..., 0.2275, 0.2275, 0.2275],
[0.2392, 0.2392, 0.2353, ..., 0.2275, 0.2275, 0.2275],
[0.2353, 0.2353, 0.2353, ..., 0.2235, 0.2235, 0.2235],
...,
[0.2275, 0.2275, 0.2314, ..., 0.2196, 0.2196, 0.2196],
[0.2235, 0.2235, 0.2275, ..., 0.2196, 0.2196, 0.2196],
[0.2235, 0.2235, 0.2275, ..., 0.2196, 0.2196, 0.2196]],
[[0.1961, 0.1961, 0.1961, ..., 0.1765, 0.1765, 0.1765],
[0.1961, 0.1961, 0.1961, ..., 0.1765, 0.1765, 0.1765],
[0.1922, 0.1922, 0.1922, ..., 0.1725, 0.1725, 0.1725],
...,
[0.1529, 0.1529, 0.1529, ..., 0.1686, 0.1686, 0.1686],
[0.1490, 0.1490, 0.1490, ..., 0.1686, 0.1686, 0.1686],
[0.1490, 0.1490, 0.1490, ..., 0.1686, 0.1686, 0.1686]]]]) torch.float32
enumerar carga
La función enumerate () se utiliza para convertir un objeto de datos transitable (como una lista,TuplaO cadena) se combina en una secuencia de índice, que enumera datos y subíndices de datos al mismo tiempo, que generalmente se usa en un bucle for.
Puede usar este bucle para cargar batchsizecada uno de los siguientes 元组para obtenerImágenes y etiquetas correspondientes
Asignación de varios elementos
Cuando Python detecta que hay múltiples variables a la izquierda del signo igual y una lista o tupla a la derecha, descomprimirá automáticamente la lista y la tupla y las asignará a los elementos correspondientes a su vez.:
l = [1, 2]
a, b = l
Así que puedes
for step, data in enumerate(train_bar):
images, labels = data
Finalmente, nn.CrossEntropyLoss () calcula la regresión de pérdidas
nn.CrossEntropyLoss()Es nn.logSoftmax()e nn.NLLLoss()integración, se puede utilizar directamente para reemplazar tanto el funcionamiento de la red. Echemos un vistazo al proceso de cálculo.
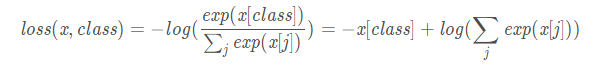
Donde x es el vector de salida de la red y clase es la etiqueta real
Por ejemplo, la salida de una red de tres clasificaciones para una muestra de entrada es [-0.7715, -0.6205, -0.2562], la etiqueta verdadera de la muestra es 0 y la nn.CrossEntropyLoss()pérdida calculada es