Tabla de contenido
1 CNN (Red Neuronal Convolucional)
https://www.zhihu.com/question/52668301
Capa convolucional -> Capa no lineal -> Capa de agrupación -> Capa completamente conectada
Estructura clásica:
entrada→convolución→ReLU→convolución→ReLU→agrupación→ReLU→convolución→ReLU→agrupación→conexión completa
1.1 Capa de convolución
La entrada de la primera capa es la imagen original, y la entrada de la segunda capa convolucional es la salida del mapa de activación de la primera capa. Es decir, la entrada a esta capa representa aproximadamente la posición de las características de bajo nivel en la imagen original.
Aplicando un conjunto de filtros encima de esto (pasándolo a través de la segunda capa convolucional), la salida será un mapa de activación que representa características de nivel superior . Estas características pueden ser semicírculos (una combinación de curvas y líneas) o cuadriláteros (una combinación de varias líneas). A medida que profundice en la red y atraviese más capas convolucionales, obtendrá mapas de activación de características más complejas.
1.2 Capa completamente conectada
En pocas palabras, esta capa procesa la entrada (que podría ser la salida de una capa convolucional, una capa ReLU o una capa de agrupación) y genera un vector N-dimensional, donde N es el número de clases que el programa tiene para elegir.
Si hay 10 números, N es igual a 10. Cada número en este vector N-dimensional representa la probabilidad de una clase particular.
Una capa completamente conectada observa el resultado de la capa anterior (que representa el mapa de activación para las características de nivel superior) y determina qué clase se ajusta mejor a esas características. Por ejemplo, si el programa predice que una imagen es sobre un perro, los valores altos en el mapa de activación representarían características de alto nivel como patas o cuatro patas.
1.3 Aplicación de la convolución
https://blog.csdn.net/zhu_hongji/article/details/81562746
Convolucionar con una plantilla y una imagen Para un punto en la imagen, deje que el origen de la plantilla coincida con el punto, luego multiplique el punto en la plantilla con el punto correspondiente en la imagen, y luego agregue los productos de cada punto a get Se obtiene el valor de convolución del punto. Haga esto para cada punto de la imagen.
Dado que la mayoría de las plantillas son simétricas, las plantillas no se giran.
La convolución es una operación integral utilizada para encontrar el área donde se superponen dos curvas. Se puede considerar como una suma ponderada, que se puede utilizar para eliminar el ruido y mejorar las características .
Convolución : Es una operación en el procesamiento de imágenes, que es la operación del kernel en cada píxel de la imagen.
Núcleo : Esencialmente, una matriz de matrices de tamaño fijo cuyo punto central se denomina punto de anclaje.
Red de 2 puntos
2.1 Estructura de la red

2.2 Limitaciones
Faltan características locales
Cada punto se asigna a un espacio de alta dimensión y luego se combina con un máx. Dado que su red agrupa violentamente todos los puntos en una característica global, la red no aprende la conexión entre los puntos locales.
=> Las redes neuronales convolucionales de PointCNN pueden explotar correlaciones espaciales locales de datos (como imágenes) densamente representados en una cuadrícula.
3 PointCNN:Convolución en puntos transformados en X
PointCNN: Convolución en puntos transformados en XPointCNN
: Convolución en puntos transformados en X
3.1 Resumen
Hacer una pregunta:
- El método de PointNet provocará la pérdida de características locales.
- Las nubes de puntos son irregulares y desordenadas, por lo que la convolución directa de núcleos con características asociadas con puntos dará como resultado la pérdida de información de forma y cambios en el orden punto a punto.
Resolver el problema:
Proponemos aprender una transformada X a partir de puntos de entrada para facilitar dos razones simultáneamente:
- El primero es el peso de la característica de entrada asociada con el punto
- El segundo es ordenar los puntos en un orden canónico potencial y latente.
3.2 Introducción
En primer lugar, se introduce que la nube de puntos no es adecuada para la convolución porque no tiene un formato de datos estandarizado.
3.3 Trabajo relacionado
El método CNN explota efectivamente la correlación local espacial en la imagen.
Aprendizaje de características de dominios regulares Aprendizaje de características en dominios regulares
Extienda CNN a vóxeles 3D => Dado que tanto el kernel de entrada como el kernel de convolución son de alta dimensión, la cantidad de cálculo y almacenamiento se expande rápidamente.
Se han propuesto métodos basados en Octrees, Kd-Tree y Hash para ahorrar cálculos al omitir circunvoluciones en espacios vacíos.
En comparación con estos métodos, PointCNN es escaso tanto en la representación de entrada como en el kernel de convolución.
Comprensión de la escasez : la escasez se puede explicar simplemente de la siguiente manera. Si consideramos que una neurona se activa cuando su salida es cercana a 1 y se inhibe cuando su salida es cercana a 0, entonces la restricción que hace que la neurona esté inhibida la mayor parte del tiempo se denomina restricción de escasez.
Aprendizaje de funciones de dominios irregulares Aprendizaje de funciones de dominio irregular
PointNet y Deep set propusieron lograr la invariancia del orden de entrada mediante el uso de una función simétrica en la entrada.
PointNet++ y SO-Net aplican PointNet jerárquicamente para capturar mejor las estructuras locales.
Con el fin de mejorar métodos como PointNet, se propone la correlación Kernel y la agrupación de gráficos (Kernel correlación and graph pooling)
Los RNN se utilizaron en [18] para procesar características agregadas mediante la agrupación de segmentos de nubes de puntos ordenados.
[50] proponen explotar estructuras de vecindad tanto en espacios de puntos como de características.
Si bien estos métodos basados en agrupación simétrica, así como los de [10, 58, 36], tienen garantías para lograr la invariancia del orden, tienen el costo de descartar información.
[43, 3, 44] proponen primero "interpolar" o "proyectar" funciones en dominios regulares predefinidos donde se pueden aplicar las CNN típicas.
En estos métodos, el kernel asociado con cada punto se parametriza individualmente, mientras que la transformación X de nuestro método se aprende de cada vecindad y, por lo tanto, puede ser más adecuada para las estructuras locales.
Además de ser nubes de puntos, los datos escasos en regiones irregulares se pueden representar como gráficos o mallas, y se han propuesto varios trabajos para el aprendizaje de características a partir de tales representaciones [31, 55, 30].
Invarianza frente a Equivarianza Invariancia frente a Equivarianza
Se ha propuesto una serie de trabajos pioneros destinados a lograr la equivarianza para abordar el problema de pérdida de información de la agrupación cuando se logra la invariancia [16, 40].
En PointCNN, se supone que la transformación X se usa tanto para la ponderación como para la permutación y, por lo tanto, se modela como una matriz genérica.
3.4 PuntoCNN
Primero, presentamos circunvoluciones jerárquicas en PointCNN, similares a las CNN de imagen, luego, explicamos en detalle el operador central X-Conv y, finalmente, presentamos la arquitectura PointCNN para varias tareas.
3.4.1 Convolución jerárquica

Explicación de la Figura 2:
Mitad superior: en las cuadrículas regulares, las circunvoluciones se aplican recursivamente a los parches de la cuadrícula local, lo que normalmente reduce la resolución de la cuadrícula (4 × 4 → 3 × 3 → 2 × 2) al tiempo que aumenta la cantidad de canales (a través de la Visualización del grosor del punto).
Mitad inferior: de manera similar, en las nubes de puntos, X-Conv se aplica recursivamente a la información de "proyecto" o "agrupamiento" de los vecindarios en menos puntos representativos (9 → 5 → 2), pero cada uno tiene información más rica.
Entrada a las CNN basadas en cuadrícula:
1. Característica de entrada F 1 F_1F1(R 1 × R 1 × C 1 R_1\times R_1\times C_1R1×R1×C1)
R 1 R_1R1: resolución espacial C 1 C_1C1: característica profundidad del canal
2. KK nuclearK(K × K × C 1 × C 2 K\veces K \veces C_1\veces C_2k×k×C1×C2) con F_1 de F 1F1的lote(K × K × C 1 K\times K \times C_1k×k×C1) Convolución para generar mapa de características F 2 F_2F2(R 2 × R 2 × C 2 R_2\times R_2\times C_2R2×R2×C2)
En la Figura 2, R 1 = 4 , K = 2 , R 2 = 3 R_1=4, K=2, R_2=3R1=4 , k=2 ,R2=3
con F 1 F_1F1Comparado con F 2 F_2F2Suelen tener una resolución más baja ( R 2 < R 1 R_2< R_1R2<R1) y canales más profundos ( C 2 > C 1 C_2>C_1C2>C1) y codificar información de nivel superior.
Este proceso se aplica recursivamente, produciendo mapas de características con resolución espacial reducida (4×4 → 3×3 → 2×2), pero con canales más profundos (visibles a través de puntos cada vez más gruesos en la parte superior de la Fig. 2).
Entrada a PointCNN:
Representa cada punto p 1 , i p_{1,i}pag1 , yoHay una función f 1 , i f_{1,i}F1 , yo,且{ f 1 , i : f 1 , i ∈ RC 1 } \left\{f_{1, i}: f_{1, i} \in \mathbb{R}^{C_{1}}\right\ }{ f1 , yo:F1 , yo∈RC1}
Esperamos que en F 1 F_1F1Aplique X-Conv para obtener una representación de nivel superior:
F 2 = { ( p 2 , i , f 2 , i ) : f 2 , i ∈ RC 2 , i = 1 , 2 , … , N 2 } \ mathbb {F}_{2}=\left\{\left(p_{2, i}, f_{2, i}\right): f_{2, i} \in \mathbb{R}^{C_{ 2 }}, i=1,2, \ldots, N_{2}\right\}F2={
( pag2 , yo,F2 , yo):F2 , yo∈RC2,i=1 ,2 ,…,norte2}
F2 tiene una resolución espacial más pequeña y canales de características más profundos que F1,N 2 < N 1 , C 2 > C 1 N_2<N_1, C_2>C_1norte2<norte1,C2>C1
p 2 , yo p_ {2, i}pag2 , yoes p 1 , i p_{1,i}pag1 , yoUn conjunto de puntos representativos
al transformar recursivamente F 1 F_1 usando XF1Gire a F 2 F_2F2Cuando , los puntos de entrada con características se "proyectan" o "agrupan" en menos puntos (9→5→2), pero cada uno con características cada vez más ricas (en la Fig. 2 a través de puntos cada vez más gruesos para visualizar más abajo).
Los puntos representativos p2i se generan mediante muestreo descendente aleatorio en la tarea de clasificación.
3.4.2 Operador de convolución X
Para explotar las correlaciones espaciales locales, similares a las circunvoluciones en los sistemas nerviosos centrales basados en cuadrículas, X-Conv opera en regiones locales.
Dado que la característica de salida debe corresponder al punto representativo { p 2 , i } \left\{p_{2, i}\right\}{ pag2 , yo} están asociados, por lo que X-Conv los coloca en{ p 1 , i } \left\{p_{1, i}\right\}{ pag1 , yo} y las características asociadas se utilizan como entrada para la convolución.
orden ppp esp 2 , yo p_{2, yo}pag2 , yoPuntos representativos en fff esppCaracterísticas de p ,NNN está enp 1 , i p_{1, i}pag1 , yoPp medioKKde pK vecinos.
因此,p的X-Conv输入为:S = { ( pi , fi ) : pi ∈ N } \mathbb{S}=\left\{\left(p_{i}, f_{i}\right): p_ {i} \en \mathbb{N}\derecho\}S={ ( pagyo,Fyo):pagyo∈n }
S \mathbb{S}S se puede transformar enK × D im K \times Dimk×D im función:P = ( p 1 , p 2 , ... , p K ) T \mathbf{P}=\left(p_{1}, p_{2}, \ldots, p_{K}\right) ^ {T}PAG=( pag1,pag2,…,pagk)T , y unK×C 1 K×C_1k×C1Matriz de tamaño: F = ( f 1 , f 2 , … , f K ) T \mathbf{F}=\left(f_{1}, f_{2}, \ldots, f_{K}\right)^{ T}F=( f1,F2,…,Fk)T
dondeKKK representa el kernel de convolución que se puede entrenar
Con estas entradas, queremos calcular la característica Fp F_pFpag, que es la característica de entrada al punto representativo ppp的“proyección” o “polimerización”
Expresión del algoritmo X_conv:
F p = X − Conv ( K , p , P , F ) = Conv ( K , MLP ( P − p ) × [ MLP δ ( P − p ) , F ] ) \mathbf{F}_{p}=\mathcal{X}}\operatorname{Conv}(\mathbf{K}, p, \mathbf{P}, \mathbf{F})=\ operatorname {Conv}\left(\mathbf{K}, MLP(\mathbf{P}-p) \times\left[ML P_{\delta}(\mathbf{P}-p), \mathbf{F}\ right ]\bien)Fpag=X−Conv ( K ,pag ,pag _f )=conversión( k ,M L P ( PAG−pag )×[ M L Pd( PAG−pag ) ,F ] )
MLP δ ( ⋅ ) ML P_{\delta}(\cdot )M L Pd( ⋅ ) indica que se aplica un perceptrón multicapa por separado en cada punto (igual que el algoritmo PointNet).X_Conv
es diferenciable, por lo que se puede insertar en la red neuronal para el entrenamiento mediante retropropagación.

Al igual que los métodos basados en PointNet, la forma de elevar las coordenadas a las entidades es a través de un puntoMLP δ ( ⋅ ) ML P_{\delta}(\cdot)M L Pd( ⋅ ) realizado. Sin embargo, el método de elevación de coordenadas a características no se implementa a través de funciones simétricas => en su lugar,junto con las características asociadas, se ponderan y permutan mediante una transformación X aprendida conjuntamente por todos los vecinos.
El X resultante depende del orden de los puntos, que es exactamente lo que se espera, ya que los puntos de entrada deberían transformar X en F ∗ F_*F∗, por lo que se debe conocer el orden de entrada específico.
Para una nube de puntos de entrada sin características adicionales, es decir, f está vacía, la primera capa X-Conv usa solo F δ F_{\delta}Fd. PointCNN puede manejar nubes de puntos con o sin características adicionales de una manera robusta y uniforme.
3.4.3 Arquitectura PointCNN

donde NNN yCCC indica que la salida representa el número de puntos y dimensiones de características,KKK es el número de puntos adyacentes para cada punto representativo y D es la tasa de dilatación X-Conv.
a:
PointCNN simple con dos capas X-Conv que convierten progresivamente los puntos de entrada (con o sin características) en menos puntos de representación, pero cada punto de representación tiene características más ricas. Después de la segunda capa X-Conv, solo queda un punto representativo, que agrega la información de todos los puntos de la capa anterior. En PointCNN, podemos definir aproximadamente el campo receptivo de cada punto representativo como K / NK / NRelación K / N , dondeKKK es el número de puntos adyacentes,NNN es el número de puntos en la capa anterior.
Con esta definición, el último punto "ve" todos los puntos de la capa anterior y, por lo tanto, tiene un campo receptivo de 1.0: tiene una vista global de la forma completa y sus características son informativas para la comprensión semántica de la forma. Podemos agregar una capa completamente conectada encima de la salida de la última capa X-Conv, seguida de una pérdida, para entrenar la red.
// no completamente completado
3.5 Experimentos de clasificación
3.5.1 Conjuntos de datos
ModelNet40, ScanNet, TU-Berlin, Dibujo rápido, MNIST, CIFAR10
3.5.2 Resultados
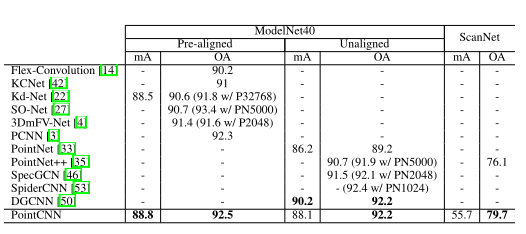
mA: Precisión media por clase
oA: Precisión total
Experimentos basados en 1024 puntos
4 implementación de código
Implementación de código específico: https://github.com/Kandy990125/PointClouds_cls/tree/main/PointCNN_Pytorch
Código de referencia: https://github.com/hxdengBerkeley/PointCNN.Pytorch