EPNet: mejora de las funciones de puntos con semántica de imágenes para la detección de objetos en 3D
2020ECCV
Dirección del código: https://github.com/happinesslz/EPNet
dirección en papel: https://arxiv.org/pdf/2007.08856.pdf
0. Resumen:
Este documento tiene como objetivo abordar dos problemas clave en las tareas de detección 3D, incluidos múltiples sensores (es decir, nubes de puntos LiDAR e imágenes de cámara) y la inconsistencia entre la localización y la confianza en la clasificación. Con este fin, proponemos un módulo de fusión novedoso para mejorar las características semánticas de la imagen punto por punto sin agregar anotaciones en la imagen. Además, la coherencia de la localización y la confianza en la clasificación se fomenta explícitamente mediante el método de pérdida de aplicación de la coherencia. Diseñamos un marco EPNet de aprendizaje integral para integrar estos dos componentes. Extensos experimentos con conjuntos de datos KITTI y SUN-RGBD demuestran la superioridad de EPNet en comparación con los métodos más avanzados. El código y los modelos están disponibles en https://github.com/happinesslz/EPNet.
Sin embargo, fusionar representaciones de imágenes LIDAR y de cámara no es una tarea trivial por dos razones. Por un lado, tienen características de datos muy diferentes. Por otro lado, las imágenes de la cámara son sensibles a la iluminación, la oclusión, etc. (como se muestra en la Figura 1(b)), lo que puede introducir información de ruido, que es perjudicial para las tareas de detección de objetos 3D. El trabajo previo generalmente fusiona estos dos sensores con la ayuda de anotaciones de imagen (es decir, cuadros delimitadores 2D). De acuerdo con las diferentes formas de utilizar los sensores, agrupamos los trabajos previos en dos categorías , que incluyen 1) métodos en cascada [27, 37, 42] que usan diferentes sensores en diferentes etapas , y 2) fusiones que razonan conjuntamente sobre entradas de múltiples sensores . 17,18]. Si bien son efectivos, estos métodos tienen algunas limitaciones. Los métodos en cascada no pueden aprovechar la complementariedad entre diferentes sensores y su rendimiento está limitado por cada etapa. Los métodos de fusión [17, 18] necesitan generar datos BEV a través de proyección en perspectiva y voxelización , lo que inevitablemente conduce a la pérdida de información. Además, solo pueden establecer aproximadamente una correspondencia relativamente aproximada entre las características de vóxel y las características semánticas de la imagen. Proponemos un módulo de fusión de imágenes guiada por LiDAR ( LI-Fusion ) para abordar los dos problemas anteriores. El módulo LI-Fusion establece la correspondencia entre los datos de la nube de puntos original y la imagen de la cámara punto por punto y estima de forma adaptativa la importancia de las características semánticas de la imagen. Este método utiliza funciones de imagen útiles para mejorar las funciones de puntos y eliminar las funciones de imagen perturbadoras. En comparación con los métodos anteriores, este método tiene cuatro ventajas principales: 1) la correspondencia de puntos finos de los datos de imagen de cámara y lidar se logra a través de una canalización más simple, sin el complicado proceso de generación de datos BEV; 2) se mantiene la geometría original, sin pérdida de información; 3) Resolver el problema de la información de interferencia que pueden traer las imágenes de la cámara; 4) En comparación con trabajos anteriores [27, 18], no hay anotación de imagen, es decir, anotación de cuadro delimitador 2D.
Además de la fusión multisensor, también observamos inconsistencias entre la confianza de clasificación y la confianza de localización, que representa si un objeto existe en un cuadro delimitador y cuánto se superpone con la realidad del terreno. Como se muestra en la Fig. 1(c), los cuadros delimitadores con mayor confianza de clasificación tienen una menor confianza de localización. Esta incoherencia dará lugar a un rendimiento de detección deficiente, ya que el proceso de supresión no máxima (NMS) filtra automáticamente las casillas con gran superposición pero baja confianza de clasificación. Sin embargo, en las tareas de detección 3D, este tema rara vez se discute. Jiang y otros intentaron paliar este problema mejorando el proceso NMS. Introducen una nueva rama para predecir la confianza de localización y reemplazan el umbral del proceso NMS con el producto de la confianza de clasificación y la confianza de localización. Si bien esto funciona hasta cierto punto, no existen restricciones explícitas que impongan la coherencia de estos dos fideicomisos. A diferencia de [9], proponemos una pérdida de aplicación de coherencia (pérdida de CE) para garantizar explícitamente la coherencia de estos dos fideicomisos. Con su ayuda, se fomenta que las cajas con una alta confianza de clasificación tengan una gran superposición con la realidad del suelo y viceversa. Este enfoque tiene dos ventajas. En primer lugar, nuestra solución es fácil de implementar sin modificar la arquitectura de la red de detección . En segundo lugar, nuestra solución no requiere absolutamente ningún parámetro de aprendizaje ni sobrecarga de tiempo de inferencia adicional.
Nuestras principales contribuciones son las siguientes :
1. Nuestro módulo LI-Fusion procesa directamente los puntos LIDAR y las imágenes de la cámara, y mejora de manera efectiva las características de los puntos mediante el uso de las características de imagen semántica correspondientes en forma de puntos sin agregar anotaciones de imagen.
2. Proponemos la pérdida de CE para mejorar la consistencia entre la clasificación y la confiabilidad de la localización, lo que da como resultado resultados de detección más precisos.
3. Integramos el módulo LI-Fusion y la pérdida de CE en un nuevo marco, EPNet, y lo obtuvimos en dos conjuntos de datos de referencia de detección de objetos 3D de uso común, el conjunto de datos KITTI [6] y el conjunto de datos SUN-RGBD [33]. resultados de última generación.
2. Trabajo relacionado
Detección de objetos 3D a partir de imágenes de cámara . Los métodos recientes de detección de objetos en 3D se centran principalmente en imágenes de cámara, como imágenes monoculares [23, 29, 12, 15, 20] e imágenes estéreo [16, 35]. Chen y otros [1] utilizan un detector de objetos basado en CNN para obtener cuadros delimitadores 2D y utilizan información semántica, contextual y de forma para inferir los cuadros delimitadores 3D correspondientes. Mousavian y otros utilizan restricciones geométricas proyectivas para estimar la localización y la orientación a partir del cuadro delimitador 2D de un objeto. Sin embargo, los métodos basados en imágenes de cámara tienen dificultades para generar cuadros delimitadores 3D precisos debido a la falta de información de profundidad.
Detección de objetos 3D basada en Lidar. En los últimos años se han propuesto muchos métodos basados en LIDAR [39, 24, 40]. VoxelNet [43] divide las nubes de puntos en vóxeles y utiliza capas de codificación de características de vóxel apiladas para extraer características de vóxel. El segundo [38] introduce la operación de convolución dispersa, que mejora la eficiencia computacional de [43]. PointPillars [14] convierte las nubes de puntos en imágenes falsas y elimina las operaciones de convolución 3D que consumen mucho tiempo. PointRCNN [31] es un detector seminal de dos etapas que consta de una red de propuesta de región (RPN) y una red de refinamiento. La red RPN predice puntos de primer plano y genera un cuadro delimitador grueso, que luego es refinado por una red de refinamiento. Sin embargo, los datos LIDAR suelen ser muy escasos, lo que plantea desafíos para una localización precisa.
Detección de objetos 3D basada en sensores múltiples. En los últimos años se ha avanzado mucho en el desarrollo de multisensores como imágenes de cámara y LiDAR. Qi y otros [27] propusieron un método en cascada F-PointNet que primero genera propuestas 2D a partir de imágenes de cámara y luego genera cuadros 3D correspondientes a partir de nubes de puntos LiDAR. Sin embargo, los métodos en cascada requieren anotaciones 2D adicionales y su rendimiento está limitado por los detectores 2D. Muchos enfoques intentan realizar inferencias conjuntas en imágenes de cámaras y BEV. MV3D [3] y AVOD [11] refinan el cuadro de detección al fusionar los mapas de características de cámara y BEV de cada región ROI. Confusion [18] propone una nueva capa de fusión continua que logra la alineación de los BEV con orientaciones de vóxel de mapas de características de imagen. A diferencia de trabajos anteriores, nuestro módulo LI-Fusion opera directamente en datos LIDAR y establece una correspondencia puntual más fina entre las características de imagen de cámara y LIDAR.
3 métodos
El uso de información complementaria de múltiples sensores es de gran importancia para la detección precisa de objetos en 3D. Además, este método también es de gran importancia para resolver el cuello de botella de rendimiento causado por la inconsistencia de la localización y la confianza en la clasificación.
En este artículo, proponemos un nuevo marco, EPNet , para mejorar el rendimiento de detección 3D desde estos dos aspectos. EPNet consiste en un RPN de dos flujos para la generación de propuestas y una red de refinamiento para la optimización del cuadro delimitador, que se puede entrenar de extremo a extremo. El RPN de dos flujos combina de manera efectiva funciones de puntos LIDAR y funciones de imágenes semánticas a través del módulo LI-Fusion. Además, proporcionamos pérdida de cumplimiento de consistencia (pérdida de CE) para mejorar la consistencia entre la clasificación y la confianza de localización. A continuación, brindamos los detalles de la RPN de doble vapor y la red de refinamiento en la Sección 3.1 y la Sección 3.2, respectivamente. Luego detallamos la pérdida de CE y la función de pérdida general en la subsección 3.4.
3.1 RPN de doble flujo
Nuestro RPN de dos flujos consta de un flujo de geometría y un flujo de imágenes. Como se muestra en la Figura 2, el flujo de geometría y el flujo de imágenes generan características de puntos y características de imágenes semánticas, respectivamente. Empleamos múltiples módulos LI-Fusion para aumentar las características de puntos con las características de imagen semántica correspondientes en diferentes escalas, lo que lleva a representaciones de características más discriminatorias.
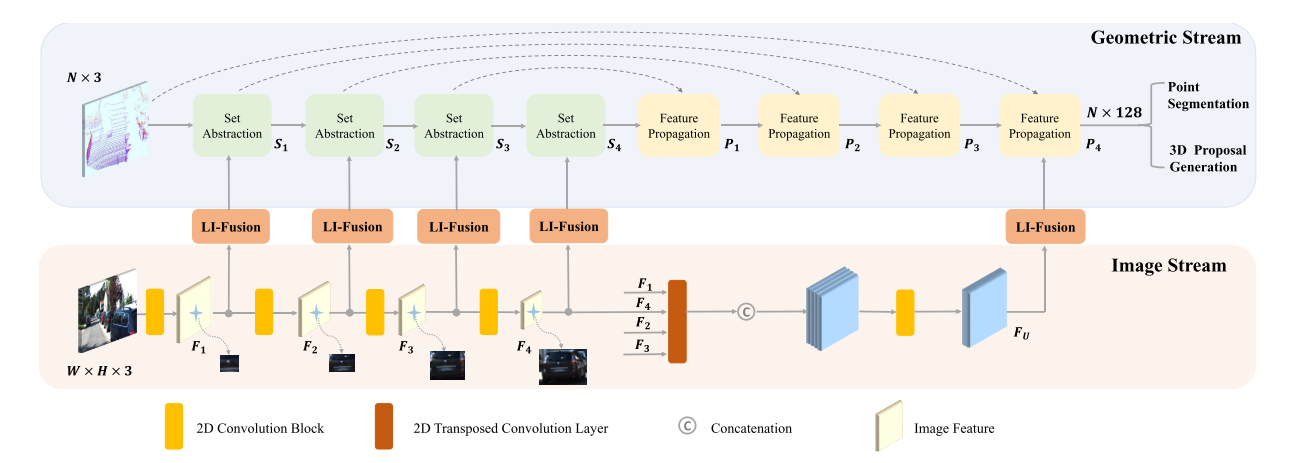
Figura II. Arquitectura de un RPN de dos flujos que consta de un flujo de geometría y un flujo de imágenes . Las características de puntos LIDAR y las características de imagen semántica correspondientes se mejoran en múltiples escalas utilizando el módulo LI-Fusion. N es el número de puntos LiDAR. H y W denotan la altura y el ancho de la imagen de la cámara de entrada, respectivamente.
flujo de imagen El flujo de imágenes toma las imágenes de la cámara como entrada y extrae la información semántica de la imagen a través de un conjunto de operaciones de convolución. Empleamos una estructura particularmente simple que consta de cuatro bloques convolucionales livianos. Cada bloque convolucional consta de dos capas convolucionales de 3×3, una capa de normalización por lotes [8] y una función de activación de ReLU. Establecemos el tamaño de paso de la segunda capa convolucional en 2 en cada bloque para expandir el campo de recepción y ahorrar memoria GPU. Fi (i=1,2,3,4) denota la salida de estos cuatro bloques convolucionales. Como se muestra en la Figura 2, Fi proporciona suficiente información de imagen semántica para enriquecer las características de los puntos LiDAR en diferentes escalas. Además, empleamos 4 capas convolucionales transpuestas paralelas con diferentes pasos para restaurar la resolución de la imagen, lo que da como resultado un mapa de características con el mismo tamaño que la imagen original. Los concatenamos para obtener un mapa de características de Fourier más representativo que contiene información rica en imágenes semánticas con diferentes campos receptivos. Como se muestra más adelante, los mapas de características también se utilizan para mejorar las características de los puntos LiDAR para generar propuestas más precisas.
flujo geométrico. Geometry Flow toma una nube de puntos LiDAR como entrada y genera propuestas 3D. Geometry Flow consta de cuatro pares: capas de extracción de conjuntos (SA) [28] y capas de propagación de características (FP) [28] para la extracción de características. Para facilitar la descripción, las salidas de la capa SA y la capa FP se indican como Si y Pi (i=1, 2, 3, 4) respectivamente. Como se muestra en la Fig. 2, combinamos características puntuales Si y características de imagen semántica Fi con la ayuda del módulo LI-Fusion. Además, la característica de punto P4 se enriquece aún más con características de imagen de múltiples escalas para obtener una representación de características compacta y discriminatoria, que luego se envía al cabezal de detección para la segmentación de puntos de primer plano y la generación de propuestas en 3D.
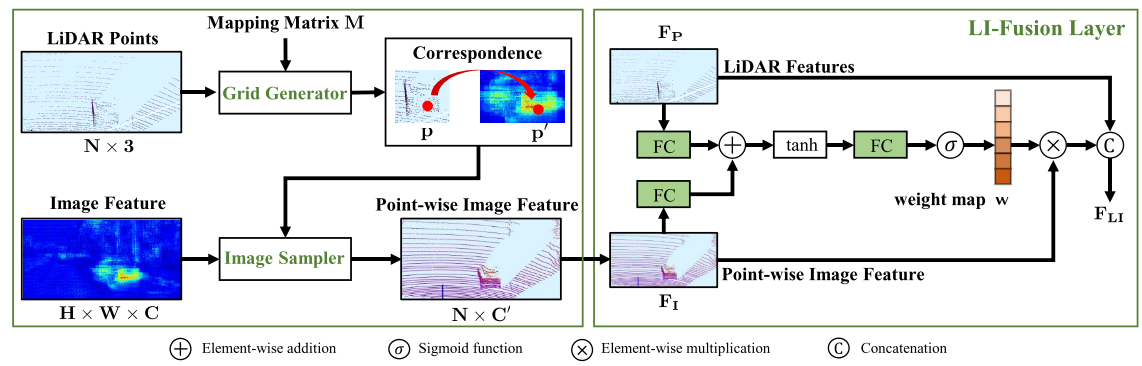
imagen 3. Esquema del módulo LI-Fusion, que incluye un generador de malla , una muestra de imágenes y una capa LI-Fusion .
Módulo LI-Fusion. El módulo de fusión de imágenes guiado por lidar consta de un generador de mallas , un muestreador de imágenes y capas LI-Fusion . Como se muestra en la Figura 3, el módulo LI-Fusion consta de dos partes, a saber, generación de correspondencia puntual y fusión guiada por lidar. Específicamente, proyectamos los puntos LiDAR en la imagen de la cámara, denotando la matriz de mapeo como M. El generador de mallas toma la nube de puntos LiDAR y la matriz de mapeo M como entrada y genera la correspondencia punto por punto entre los puntos LiDAR y la imagen de la cámara a diferentes resoluciones. Específicamente, para un punto específico p(x, y, z) en la nube de puntos, se puede obtener su posición correspondiente en la imagen de la cámara, que se puede escribir como:

donde el tamaño de M es 3×4. Tenga en cuenta que en la fórmula de procesamiento de proyección (1), convertimos yp en vectores 3D y 4D en coordenadas homogéneas.
Después de establecer la correspondencia, proponemos utilizar un muestreador de imágenes para obtener una representación de características semánticas para cada punto. Específicamente, nuestro muestreador de imágenes toma una ubicación de muestreo y un mapa de características de imagen F como entrada, y genera una representación de características de imagen por puntos V para cada ubicación de muestreo. Teniendo en cuenta que la posición de muestreo puede estar entre píxeles adyacentes, utilizamos la interpolación bilineal para obtener características de la imagen en coordenadas continuas, que se pueden expresar como:
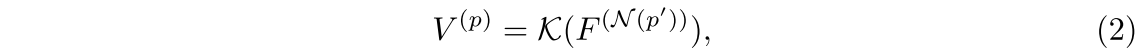
Entre ellos, V(p) es la característica de la imagen correspondiente al punto p, K es la función de interpolación bilineal y F(N( )) es
la característica de la imagen de los píxeles adyacentes en la posición de muestreo.
Dado que las imágenes de la cámara se ven desafiadas por muchos factores, como la iluminación y la oclusión, la fusión de las funciones LIDAR y las funciones de imagen puntuales no es trivial. En estos casos, las características de la imagen por puntos introducirán información de ruido. Para abordar este problema, empleamos una capa de fusión guiada por lidar para estimar de forma adaptativa la importancia de las características de la imagen de manera puntual utilizando características lidar . Como se muestra en la Figura 3, primero alimentamos las funciones LiDAR FP y las funciones puntuales FI en una capa completamente conectada y las mapeamos en el mismo canal. Luego los sumamos para formar una representación de características compacta, que luego se comprime en un mapa de peso de un solo canal w por otra capa completamente conectada. Normalizamos el mapa de peso w al rango [0,1] usando una función de activación sigmoidea.
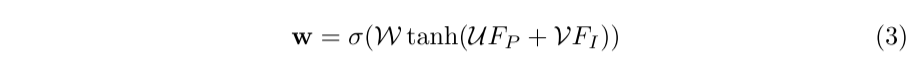
donde W, U, V denotan la matriz de peso aprendible en la capa LI-Fusion. σ es la función de activación sigmoidea.
Luego de obtener el mapa de peso w, concatenamos la función LiDAR FP y la función de imagen semántica FI, que se puede expresar como:
![]()
(Breve resumen, las características fusionadas generarán un peso, que afecta la relación final de las características de la imagen)
3.2 Red de refinamiento
Usamos el proceso NMS para mantener propuestas de alta calidad y enviarlas a la red de refinamiento. Para cada propuesta de entrada, generamos su descriptor de características seleccionando aleatoriamente 512 puntos en el cuadro delimitador correspondiente en la última capa SA del RPN de dos flujos. Para aquellas propuestas con menos de 512 puntos, simplemente rellenamos el descriptor con 0s. La red refinada consta de tres capas SA y dos subredes para extraer descriptores globales compactos y dos capas convolucionales 1×1 en cascada para clasificación y regresión, respectivamente.
3.3 Pérdida por cumplimiento de coherencia Pérdida por cumplimiento de coherencia
Los detectores de objetos 3D comunes suelen generar más cuadros delimitadores que la cantidad de objetos reales en la escena. Cómo elegir un borde de alta calidad es un gran desafío. NMS intenta filtrar los cuadros delimitadores que no cumplen los requisitos en función de su confianza de clasificación. En este caso, se plantea la hipótesis de que la confianza de la clasificación puede servir como indicador del IOU real entre la verdad de los límites y la verdad del terreno, es decir, la confianza de la ubicación. Sin embargo, la confianza de clasificación y la confianza de localización a menudo son inconsistentes, lo que da como resultado un rendimiento deficiente.
Esto nos motiva a introducir una pérdida de cumplimiento de consistencia para garantizar la consistencia entre la confianza de localización y la confianza de clasificación, de modo que las cajas con una confianza de localización alta tengan una confianza de clasificación alta y viceversa. La pérdida por fortalecimiento de la consistencia se escribe de la siguiente manera: 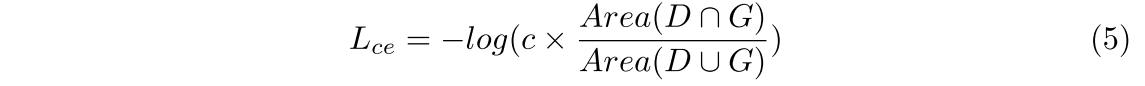
donde D y G denotan los cuadros delimitadores predichos y la realidad fundamental. c es la confianza de clasificación de d. Para optimizar esta función de pérdida, la confianza de clasificación y la confianza de localización (es decir, IoU) son donde D y G denotan el cuadro delimitador predicho y la realidad del terreno, respectivamente. c es la confianza de clasificación de d. Para optimizar esta función de pérdida, recomendamos que tanto la confianza de clasificación como la confianza de localización (es decir, IoU) sean lo más altas posible juntas. Por lo tanto, las cajas con superposiciones más grandes tendrán una mayor probabilidad de clasificación y se conservarán en el proceso NMS. Relación de pérdida del pagaré. Nuestra pérdida de CE es similar a la pérdida de IoU [41] en la formulación, pero la motivación y el papel son completamente diferentes. La pérdida de IoU intenta generar regresiones más precisas mediante la optimización de la métrica de IoU, mientras que la pérdida de CE tiene como objetivo garantizar la coherencia entre la localización y la confianza en la clasificación para ayudar al proceso NMS a mantener cuadros delimitadores más precisos. Aunque la formulación es simple, los resultados cuantitativos y el análisis de la Sección 4.3 demuestran la eficacia de nuestra pérdida de CE para garantizar la coherencia y mejorar el rendimiento de la detección 3D.
3.4 Función de pérdida global Función de pérdida global
Optimización conjunta de RPN de dos flujos y red de refinamiento utilizando la función de pérdida multitarea. La pérdida total se puede expresar como:

En la fórmula, Lrpn y Lrcnn representan los objetivos de entrenamiento del RPN de dos flujos y la red refinada, y los objetivos de optimización del RPN de dos flujos y la red refinada son similares, incluida la pérdida de clasificación, la pérdida de regresión y la pérdida de CE. Adoptamos la pérdida focal [19] como pérdida de clasificación, equilibrando muestras positivas y negativas bajo la condición de α = 0,25 y γ = 2,0. Para un cuadro delimitador, la red debe regresar a su punto central (x, y, z), tamaño (l, h, w) y orientación θ.
Dado que el rango del eje y (eje vertical) es relativamente pequeño, usamos directamente la pérdida L1 suavizada [7] para calcular su compensación de la realidad fundamental. Asimismo, el tamaño del cuadro delimitador (h, w, l) también está optimizado para suavizar la pérdida de L1. Para el eje x, el eje z y la dirección θ, adoptamos la pérdida de regresión basada en intervalos [31, 27]. Para cada punto de primer plano, dividimos su vecindad en varios contenedores. La pérdida basada en contenedores primero predice en qué contenedor cae el punto central y luego retrocede el desplazamiento restante ru dentro del contenedor. La expresión de la función de pérdida es la siguiente:
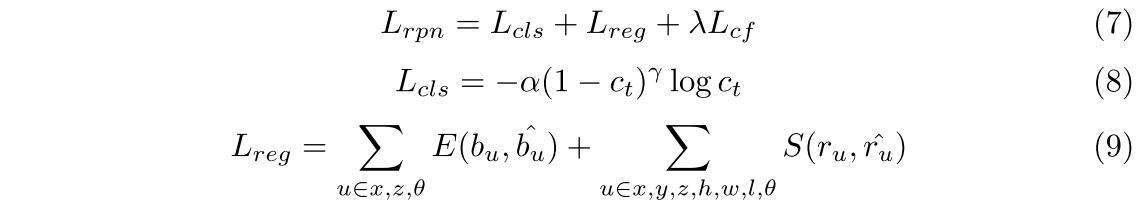
4 experimentos
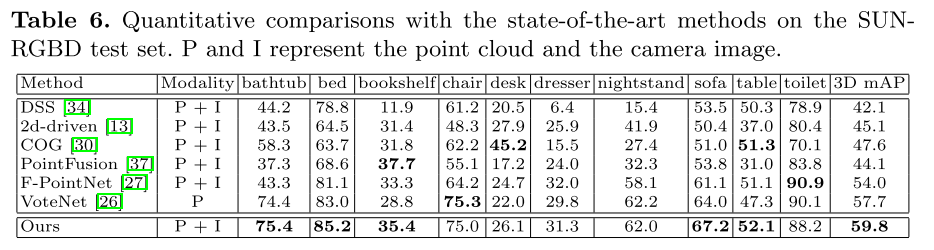
Evaluamos el método utilizando el conjunto de datos KITTI [6] y el conjunto de datos SUN-RGBD [33]. KITTI es un conjunto de datos de exteriores, mientras que SUN-RGBD es un conjunto de datos de escenas de interiores. En la siguiente subsección 4.1, primero presentamos brevemente estos conjuntos de datos. Luego proporcionamos detalles de implementación en la subsección 4.2. En la subsección 4.3 se presenta un análisis completo de los módulos LI-Fusion y la pérdida de CE. Finalmente, mostramos comparaciones con métodos de vanguardia en el conjunto de datos KITTI y el conjunto de datos SUN-RGBD en la Sección 4.4 y la Sección 4.5, respectivamente.
4.1 Conjuntos de datos y métricas de evaluación
El conjunto de datos de KITTI es un conjunto de datos de referencia estándar para la conducción autónoma, que contiene 7481 marcos de entrenamiento y 7518 marcos de prueba. Siguiendo el mismo protocolo de división de conjuntos de datos que [27, 31], los 7481 marcos se dividen aún más en 3712 marcos para entrenamiento y 3769 marcos para validación. En nuestros experimentos, presentamos resultados de validación y conjuntos de prueba para los tres niveles de dificultad, es decir, fácil, medio y difícil. Los objetos se dividen en diferentes niveles de dificultad según el tamaño, la oclusión y el truncamiento.
El conjunto de datos SUN-RGBD es un conjunto de datos de referencia en interiores para la detección de objetos 3D. El conjunto de datos consta de 10 335 imágenes y 700 categorías de objetos anotados, de los cuales 5285 imágenes se usan para entrenamiento y 5050 imágenes se usan para pruebas. Siguiendo el trabajo previo [37, 27], informamos los resultados de 10 categorías principales de objetos en el conjunto de prueba, ya que los objetos en estas categorías son relativamente grandes.
medida _ Adoptamos la precisión promedio (AP) como la métrica, siguiendo los protocolos de evaluación oficiales del conjunto de datos KITTI y el conjunto de datos SUN-RGBD. Recientemente, se aplicó un nuevo protocolo de evaluación [32] al conjunto de datos KITTI, que utiliza 40 ubicaciones de recuperación en lugar de las 11 ubicaciones de recuperación anteriores. Por lo tanto, es un protocolo de evaluación más justo. Bajo este nuevo esquema de evaluación, comparamos nuestro método con métodos de última generación.
4.2 Detalles de implementación
configuración de la red. El RPN de dos flujos toma nubes de puntos LIDAR e imágenes de cámara como entrada. Para cada escena 3D, las distancias de la nube de puntos LiDAR a lo largo del eje X (derecha), el eje Y (abajo) y el eje Z (frontal) de las coordenadas de la cámara son [- 40,40], [- 1,3], [ 0, 70,4] m. La orientación de θ está en el rango [-π, π]. Submuestreamos 16384 puntos de la nube de puntos LiDAR sin procesar como entrada para el flujo de geometría, al igual que PointRCNN [31]. El flujo de imágenes toma imágenes con una resolución de 1280 × 384 como entrada. Submuestreamos la nube de puntos LiDAR de entrada con cuatro conjuntos de capas de abstracción, con tamaños 4096, 1024, 256 y 64, respectivamente. Utiliza cuatro capas de propagación de características para recuperar el tamaño de la nube de puntos para la segmentación en primer plano y la generación de propuestas en 3D. De manera similar, reducimos la muestra de la imagen de entrada usando cuatro bloques convolucionales con paso 2. Además, también empleamos cuatro convoluciones transpuestas paralelas con pasos 2, 4, 8, 16 para recuperar la resolución de los mapas de características a diferentes escalas. Durante el proceso de NMS, seleccionamos las 8000 casillas principales de las casillas generadas por los dos RPN de transmisión en función de su clasificación de confianza. Luego, filtramos las cajas redundantes con un umbral de gestión de red de 0,8 para obtener 64 cajas candidatas positivas, que son refinadas por la red de refinamiento. Para estos dos conjuntos de datos, adoptamos un diseño arquitectónico similar para el RPN de dos flujos discutido anteriormente.
plan de entrenamiento Nuestra red de refinamiento y RPN de dos flujos se puede entrenar de extremo a extremo. En la fase de entrenamiento, la pérdida de regresión Lreg y la pérdida de CE solo son aplicables a la propuesta directa, es decir, la propuesta generada por el punto de primer plano en la etapa RPN, y la propuesta con un IoU superior a 0.55 compartido con la verdad de tierra en el escenario RCNN.
Optimización de parámetros . La red se optimiza utilizando la estimación de momento adaptativo (Adam) [10]. La tasa de aprendizaje inicial, la caída del peso y el factor de impulso se establecen en 0,002, 0,001 y 0,9, respectivamente. Entrenamos el modelo durante unas 50 épocas de forma integral en 4 GPU Titan XP con un tamaño de lote de 12. El peso de equilibrio λ en la función de pérdida se establece en 5.
aumento de datos Para evitar el sobreajuste, se adoptan tres estrategias de aumento de datos de uso común, que incluyen transformaciones de rotación, volteo y escalado. Primero, rotamos aleatoriamente la nube de puntos a lo largo del eje vertical en el rango [−π/18, π/18]. Luego, la nube de puntos se voltea aleatoriamente a lo largo del eje de avance. Además, cada cuadro de verdad fundamental se escala aleatoriamente de acuerdo con una distribución uniforme en [0.95, 1.05]. Muchos métodos basados en lidar toman muestras de cuadros de datos reales de todo el conjunto de datos y los colocan en marcos 3D sin procesar para simular escenas realistas con objetos abarrotados detrás [43, 38]. Aunque este método de aumento de datos es efectivo, necesita obtener la información previa del plano de la carretera, que es difícil de obtener para varios escenarios reales. Por lo tanto, no explotamos la aplicabilidad y la generalidad de este mecanismo de aumento en nuestro marco.
4.3 Ablación
Llevamos a cabo extensos experimentos en el conjunto de datos de validación de KITTI para evaluar la efectividad y la pérdida de CE del módulo LI-Fusion.
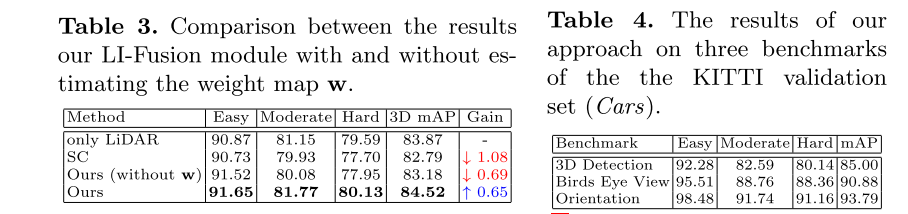
Análisis de la arquitectura de fusión. Para verificar la efectividad de los módulos LI-Fusion, eliminamos todos los módulos LI-Fusion. Como se muestra en la Tabla 1, después de agregar el módulo LI-Fusion, el rendimiento de 3D mAP mejora en un 1,73 %, lo que demuestra la eficacia de combinar características de puntos y características semánticas de imágenes. Comparamos además dos esquemas de fusión diferentes en la Tabla 2. Una alternativa es Simple Connect (SC). Modificamos la entrada del flujo de geometría para que sea una combinación de imágenes de cámara sin procesar y nubes de puntos LIDAR, en lugar de sus representaciones de características. Específicamente, unimos los canales RGB de la imagen de la cámara al canal de coordenadas espaciales de la nube de puntos LIDAR. Vale la pena señalar que SC no emplea transmisión de imágenes. Otra opción es la fusión de escala única (SS), que tiene una estructura similar a nuestro RPN de dos flujos. La diferencia es que eliminamos todos los módulos de LI-Fusion en la capa de abstracción de la colección y solo mantenemos el módulo de LI-Fusion en la última capa de propagación de funciones (consulte la Figura 2). Como se muestra en la Tabla 2, el mAP 3D generado por SC disminuye en un 0,28 % en comparación con la línea de base, lo que indica que las combinaciones simples en el nivel de entrada no pueden proporcionar suficiente información de orientación. Además, nuestro método supera al mAP 3D de SS en un 1,31 %. Ilustra la efectividad del módulo LI-Fusion para aplicaciones de múltiples escalas.
Visualización de características de imagen semántica aprendidas. Cabe señalar que no agregamos información de supervisión explícita (como anotaciones de cuadros de detección 2D) en el flujo de imágenes del RPN de dos flujos. El flujo de imágenes se optimiza junto con el flujo de geometría, y la información de monitoreo de las cajas 3D se obtiene del final del RPN de dos flujos. Teniendo en cuenta las diferentes características de datos de las imágenes de la cámara y las nubes de puntos LiDAR, visualizamos las características semánticas de la imagen para comprender lo que se aprende mediante la transmisión de imágenes, como se muestra en la Figura 4. Aunque no se utilizó una supervisión explícita, el flujo de imágenes distingue sorprendentemente bien los objetos de primer plano de los de fondo y extrae ricas características semánticas de las imágenes de la cámara, lo que demuestra que el módulo LI-Fusion construye lidar con precisión. La correspondencia entre la nube de puntos y la imagen de la cámara puede proporcionar información de imagen semántica complementaria. para características puntuales. Vale la pena señalar que el flujo de imágenes se concentra principalmente en el área representativa del objeto en primer plano, y el área poco iluminada y el área adyacente muestran características muy obvias, como lo indica la flecha roja. Esto sugiere que es necesario estimar adaptativamente la importancia de las características semánticas en las imágenes, ya que los cambios en las condiciones de iluminación pueden introducir información de ruido perjudicial. Por lo tanto, a continuación analizamos más a fondo el mapa de peso w de las características de la imagen semántica.

Análisis de mapa de peso de capa LI-Fusion. En escenas reales, las imágenes de la cámara suelen verse perturbadas por la luz, lo que da como resultado una subexposición y una sobreexposición. Para verificar la efectividad del mapeo de peso w para aliviar la información de ruido que traen las imágenes de cámara insatisfactorias, simulamos el entorno real cambiando la iluminación de las imágenes de cámara. Para cada imagen en el conjunto de datos de KITTI, simulamos los cambios de iluminación transformando y = a∗x+b, donde x e y denotan los valores RGB originales y transformados del píxel. A y b denotan coeficiente y compensación, respectivamente. Relajamos aleatoriamente (respuesta. a 3(respuesta. 0.3) yb a 5 para imágenes de cámara en el conjunto de datos KITTI. Los resultados cuantitativos se dan en la Tabla 3. Para comparar, eliminamos el flujo de imágenes y usamos un modelo solo LiDAR basado en Como referencia, se obtiene un mAP 3D del 83,87 %. También presentamos los resultados de una combinación simple de coordenadas RGB y coordenadas LiDAR en la etapa de entrada (SC), lo que da como resultado una caída significativa del rendimiento del 1,08 %, lo que ilustra la mala imagen. la calidad para la tarea de detección 3D es perjudicial. Además, nuestro método no estima el mapa de peso w, lo que también conduce a una caída del 0,69 %. Sin embargo, guiado por el mapa de peso w, nuestro método mejora en un 0,65 % con respecto a la línea base. Esto significa que la introducción de gráficos de peso puede seleccionar de manera adaptativa características favorables mientras ignora las dañinas.
Análisis de pérdidas CE . Como se muestra en la Tabla 1, la adición de la pérdida de CE mejora significativamente la línea de base en un 3,93 %. Y la comparación cuantitativa con la pérdida de IOU verifica la superioridad de la pérdida de CE para mejorar el rendimiento de detección 3D. Como se muestra en la figura 5(a), la pérdida de CE conduce a una mejora del 1,28 % en el mAP 3D en comparación con la pérdida de IoU, lo que demuestra que es beneficioso garantizar la consistencia de la clasificación y la confiabilidad de la localización en las tareas de detección 3D.
Para ver cómo mejora la concordancia entre estos dos intervalos de confianza, realizamos un análisis completo de la pérdida de CE. Para facilitar la descripción, denotamos las casillas pronosticadas cuya superposición es mayor que un umbral τ de IoU predefinido como candidatos positivos. Además, adoptamos otro umbral υ para filtrar propuestas positivas con menor confianza de clasificación. Por lo tanto, la consistencia se puede evaluar mediante la relación de R con el número de casillas candidatas positivas retenidas, que se puede escribir como:
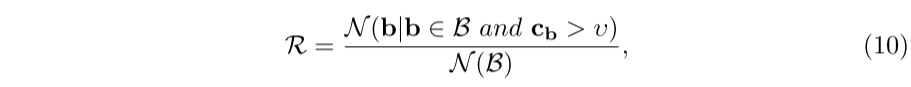
4.4 Experimento KITTI
La Tabla 5 presenta los resultados cuantitativos en el conjunto de prueba KITTI. En términos de mAP 3D, el método de este documento supera a los métodos basados en sensores múltiples F-PointNet[27], MV3D[3], AVOD-FPN[11], PC-CNN[5], ContFuse[18] y MMF [17] Aumentaron un 10,37%, 17,03%, 7,71%, 6,23%, 9,85% y 2,55% respectivamente. Cabe señalar que MMF [17] aprovecha múltiples tareas auxiliares, como detección 2D, estimación de superficie y finalización de profundidad para mejorar el rendimiento de detección 3D, lo que requiere muchas anotaciones adicionales. Estos experimentos muestran consistentemente que nuestro método supera a los métodos en cascada [27], así como a los métodos de fusión basados en ROI [3, 11, 5] y en vóxeles [18, 17].
También proporcionamos los resultados cuantitativos de la separación de validación de KITTI en la Tabla 4 para compararlos con trabajos futuros. Además, presentamos resultados cualitativos sobre el conjunto de datos de validación de KITTI en el material complementario.
5 resumen
Proponemos EPNet, un novedoso detector de objetos 3D, que consiste en un RPN de dos flujos y una red mejorada. Con el módulo LI-Fusion, diferentes sensores, como nubes de puntos LIDAR e imágenes de cámaras, se combinan para mejorar de manera efectiva las características de los puntos. Además, la inconsistencia entre la confianza de clasificación y la confianza de localización se resuelve mediante la pérdida de CE propuesta, que garantiza explícitamente la consistencia entre la confianza de localización y la confianza de clasificación. Extensos experimentos han verificado la efectividad y la pérdida de CE del módulo LI-Fusion. En el futuro, exploraremos cómo utilizar la información de profundidad de la nube de puntos LIDAR para mejorar la representación de características de la imagen y su aplicación en tareas de detección 2D.
resume por ti mismo
innovación
1. Método de fusión, las características fusionadas en sí mismas actúan como pesos para afectar el empalme de imágenes. Todo el proceso de fusión también es muy claro.
2. Mejorar la función de pérdida para que la categoría y la posición puedan equilibrarse
En duda
En última instancia, esta estructura debería ser una estructura de dos cabezas, una es la cuadrícula 3D y la otra es la segmentación de la nube de puntos. No sé qué parte corresponde al resultado y la estructura de la segmentación de la nube de puntos. Bienvenido a discutir ~