Finalmente llegó a las técnicas de aprendizaje automático , y luego intente mantener cada capítulo completo y actualícelo de inmediato. . Cornerstone no insistió en terminar la escritura, pero ahora miro hacia atrás y no sé lo que estaba escribiendo. Mirando las notas, siento que la escritura es un desastre y siento que me he volcado. Mejorar lentamente.
Escuché que la técnica es bastante difícil, así que publique una publicación en el blog del maestro para bendecirla:
Red Stone: ¡Creo que lo resume muy bien! !
Notas sobre técnicas de aprendizaje automático de Lin Xuantian (2)
Notas sobre técnicas de aprendizaje automático de Lin Xuantian (3)
1. SVM lineal
P1 1.1
Después de presentar las [técnicas] en torno a tres transformaciones de características después de este curso
1. Cómo usar transformaciones de características y controlar la complejidad de las transformaciones de características: use SVM (Support Vector Machine, suena bastante difícil)
2. Cómo encontrar características predictivas y mézclelos para que el modelo funcione mejor: AdaBoost (método de mejora paso a paso)
3. Cómo encontrar y aprender funciones ocultas para que la máquina funcione mejor: Aprendizaje profundo (¡aprendizaje profundo!)
P2 1.2

En PLA, en realidad podemos tener diferentes divisiones para un conjunto de datos. Las tres imágenes anteriores son todas "correctas": se garantiza que todos los puntos se dividen correctamente y, de acuerdo con el límite de VC, Eout es el mismo,
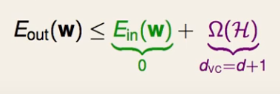
pero según el cerebro humano, la división de la imagen más a la derecha debe ser mejor.
¿por qué? Debido a que los datos tendrán algún ruido o error de medición, la situación real no está necesariamente en ooxx, puede estar distribuida en el área gris y también es razonable. Si está en la imagen de la izquierda, cerca de la x en la línea divisoria, si hay alguna vibración, será más fácil correr al rango de o, lo que resultará en errores. Por lo tanto, para mejorar la tasa de tolerancia a errores (la capacidad de tolerar errores) (¿la legendaria robustez?), es necesario llamar a una línea "más fuerte". Obviamente, la línea más fuerte es asegurarse de que todo esté correcto . línea que está más alejada del punto más cercano.
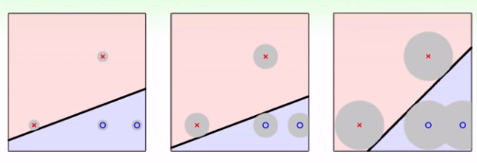

Por supuesto, también se puede transformar en "gordo" pero no en "gordo", y cuanto más grueso es el hilo, más fuerte es. Académicamente, "grasa" se llama margen. La siguiente es una fórmula para expresar la w que maximiza el margen: " La línea más fuerte es la línea que está más alejada del punto más cercano cuando se garantiza que todo estará correcto "

P3 1.3

comenzó a encontrar la distancia (xn,w). Anteriormente, se agregó un w0 a w1~wd, pero debido a que este w0 es diferente de otras operaciones de w, saltó directamente, que es b, por lo que hay: ( aquí
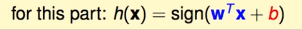
El w0(b) debe ser un elemento de sesgo, por qué hay un elemento de sesgo, debe leer el libro de sandía para obtener más detalles)
A continuación, encuentre la distancia (x,b,w), x' y x'' son puntos en el plano, x es un punto de datos (no necesariamente en el hiperplano), según wTx' + b = 0, hay wTx' = -b, la misma razón: wTx'' = -b

Hay un lugar especial aquí, que es demostrar que w es el vector normal de este hiperplano. (Sobre el hiperplano, leí el artículo de otra persona , pero no parecía explicar por qué w es un vector normal...)
Conociendo el vector normal, si hay un punto x' en el plano, la distancia entre x y x ' es en realidad el vector xx 'La proyección en w, por lo que es:
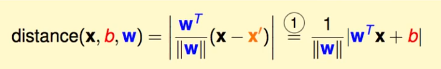
debido a que esta es una SVM de margen duro, por lo que esta línea se dividirá en pares para todos los puntos, por lo que hay: 
y yn=±1, por lo que puede quitar el valor absoluto:

luego bajar por la conveniencia de resolver:
Definición: 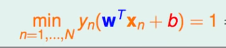
Entonces hay: 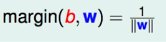
Por qué es 1, de hecho, cualquier constante está bien. Aquí, el aluvión dice que involucra el conocimiento de intervalos funcionales y geométricos. intervalos ? ? . Mire la piedra roja y diga que w y b están escalados al mismo tiempo, y el plano obtenido sigue siendo el mismo, por lo que puede controlar yn ( w 1 T xn + b 1 ) = 1 y_n(w1^Tx_n+b1 )=1yn( w 1TX _n+b1 ) _=1 (Oh O o??)
En este momento, debido a que se requiere el margen más grande (para ensanchar la línea), es necesario hacer w más grande y satisfacermin ( n = 1... N ) yn ( w 1 T xn + b 1 ) = 1 min_(n=1...N) y_n(w1^Tx_n+b1)=1m i n(norte=1...N)yn( w 1TX _n+b1 ) _=1
Pero aún es difícil de resolver, por lo que relajamos las condiciones, sea yn ( w T xn + b 1 ) > = 1 y_n(w^Tx_n+b1)>=1yn( wTX _n+b1 ) _>=1 , y demuestre que después de la relajación, la mejor solución o h satisfaráyn ( w T xn + b 1 ) = 1 y_n(w^Tx_n+b1)=1yn( wTX _n+b1 ) _=1
Suponga que encuentra un conjunto de soluciones óptimas (b1,w1) tales queyn ( w 1 T xn + b 1 ) > 1,126 y_n(w1^Tx_n+b1)>1,126yn( w 1TX _n+b1 ) _>1 . 1 2 6 , entonces también podemos encontrar un conjunto de mejores soluciones (b 1 1.126 \frac{b1}{1.126}1 . 1 2 6segundo 1,w 1 1.126 \frac{w1}{1.126}1 . 1 2 61 _), según margen = 1 ∣ ∣ w ∣ ∣ margen=\frac{1}{||w||}margen _ _ _ _ _=∣ ∣ w ∣ ∣1, w/1.126 se vuelve más pequeño, por lo que el margen es más grande. Por lo tanto, la solución óptima anterior (b1, w1) no es óptima y existe una contradicción. Entonces, siempre que haya una solución de grupo tal que yn ( w T xn + b 1 ) > 1 y_n(w^Tx_n+b1)>1yn( wTX _n+b1 ) _>1 , podemos encontrar una mejor solución tal queyn ( w T xn + b 1 ) = 1 y_n(w^Tx_n+b1)=1yn( wTX _n+b1 ) _=1 , por lo que sabemos que la solución óptima seríayn ( w T xn + b 1 ) = 1 y_n(w^Tx_n+b1)=1yn( wTX _n+b1 ) _=1 _
Finalmente, antes buscaba min. Para unificar, pon 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||}∣ ∣ w ∣ ∣1Tome la inversa. Encuentra max 1 ∣ ∣ w ∣ ∣ max\frac{1}{||w||}mx _ _∣ ∣ w ∣ ∣1Cambiar a min ∣ ∣ w ∣ ∣ min||w||metro yo norte ∣ ∣ w ∣ ∣ . Debido a que ||w|| tiene un signo de raíz, entonces elimine el signo de raíz y conviértalo en el cuadrado de w, expresado en una matriz es wTw, y finalmente agregue1 2 \frac{1}{2}21(¿Parece que se agregó para la derivación?). Finalmente se convierte en:
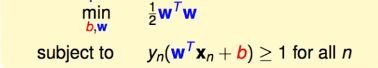
el tiempo de diversión final, tenga en cuenta que la fórmula x1x2 puede corresponder a xey en y=kx+b respectivamente. Entonces según d = ∣ A x 1 + B x 2 + C ∣ ( A 2 + B 2 ) d=\frac{|Ax1+Bx2+C|}{\sqrt{(A^2+ B^2)} }d=( Un2 +B2 )∣ A x 1 + B x 2 + C ∣, simplificar x 1 + x 2 = 1 x1+x2=1x1 _+x2_ _=1 es1 ∗ x 1 + 1 ∗ x 2 − 1 = 0 1*x1+1*x2-1=01∗x1 _+1∗x2_ _−1=0 , entoncesA = 1 , B = 1 , C = − 1 A=1,B=1,C=-1A=1 ,B=1 ,C=− 1 , sustituye x1 y x2 de x1 (en realidad x e y de x1), que es como sigue:

P4 1.4
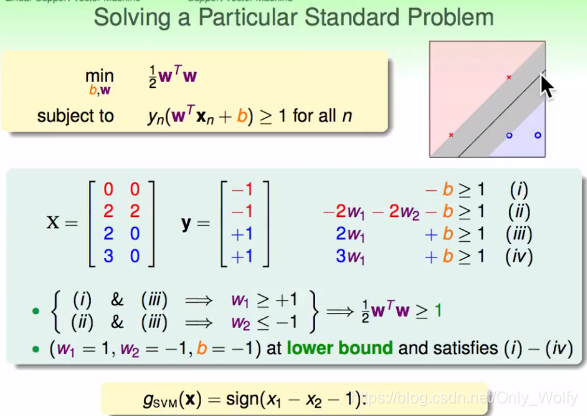
Tomando este grupo (X, Y) como ejemplo, se puede obtener (i)~(iv), luego se puede determinar que w1>=1, w2<=-1, entonces w1^2 + w2^2 >=2 , entonces hay 1 2 w T w > = 1 \frac{1}{2}w^Tw>=121wT w>=1 , asigne valores apropiados a w1, w2 y b, luego se obtienesvm= sign (x1 - x2 - 1)
Entonces, ¿cómo lidiar con el caso general? Resuelve este problema:
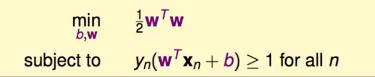 tiene dos características:
tiene dos características:

la programación cuadrática (programación cuadrática/optimización convexa/es un problema QP) ya tiene una solución conocida, y luego solo la sustitución es suficiente: finalmente,

para el problema no lineal, solo usa el espacio z antes

La diferencia entre P5 1.5
SVM y la regularización anterior (espacio z o algo así) se llama contacto:

se puede ver que los objetivos de los dos son casi opuestos, por lo que SVM también es un tipo de regularización, pero sea Ein=0.
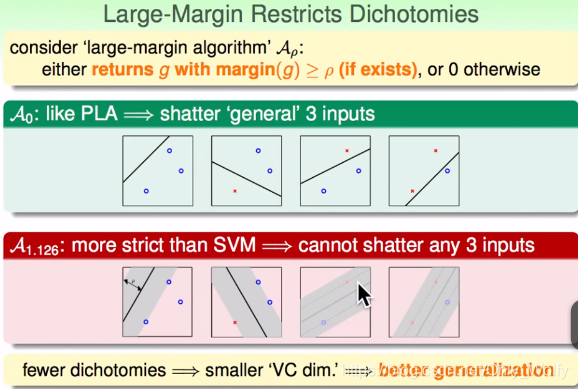
Cuando el margen se establece en 0 ( A 0 A_0A0), igual que PLA. Cuando el ancho sea A 1.126 , si no cumple con las reglas, no lo elija, será mayor que A 0 A_0A0Hay menos tipos, por lo que hay menos situaciones -> (falso) la dimensión de VC es menor -> mejor generalización.

Para esta esfera ρ = 0 ρ=0r=0 puede romper 3 puntos, entonces dvc= 3, siρ = 3 2 ρ=\frac{\sqrt{3}}{2}r=23Si , el radio de este círculo es 3 \sqrt{3}3, debido a que hay tres puntos, a lo sumo un par está en el lado opuesto y hay otro punto que no se puede romper, entonces d vc < 3 en este momento. Así es:

la próxima lección presentará SVM no lineal que combina hiperplanos de gran margen y transformación de características:
