Come gelatina sin escupir piel de gelatina2023-07-29 12:22Publicado en Sichuan
Recomendación del editor:
Este artículo describe los principios y detalles de LoRA en detalle; al mismo tiempo, hace una interpretación detallada de los experimentos en el documento.
El siguiente artículo proviene de Notas breves sobre los ladrillos móviles del gran simio, del autor Meng Yuan.

Breves notas sobre los grandes simios moviendo ladrillos.
Un agricultor de código con experiencia en contabilidad, aprendiendo con todos.
【Haga clic】Únase al grupo de intercambio de tecnología de modelos grandes
En cuanto a la explicación de la parte LORA, la dividiremos en "artículos de principio" y "artículos de código fuente" .
En el capítulo principal, analizaremos en detalle los temas centrales, como cómo usar LoRA, por qué funciona y qué ventajas y desventajas existen por medio de diagramas . Especialmente cuando estás aprendiendo LoRA, si estás confundido acerca de la definición y la función de "rango", entonces este artículo puede proporcionar algunas interpretaciones concretas.
En el capítulo del código fuente, analizaremos juntos el código fuente de Microsoft LoRA y ayudaremos a todos a usar la GPU gratuita en la plataforma Google Colab para crear un entorno de ajuste fino de LoRA , de modo que todos puedan ejecutar el código LoRA original por sí mismos, y profundizar en la comprensión del mecanismo operativo de LoRA (La felicidad sin dinero es la verdadera felicidad).

1. Ajuste fino de parámetros completos
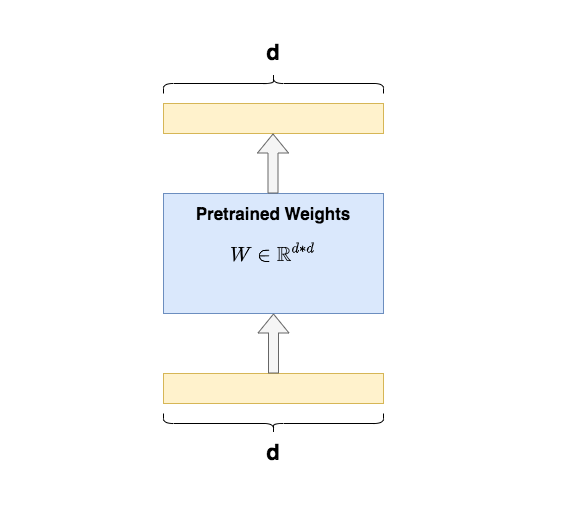
Sabemos que el significado del ajuste fino es tomar el modelo preentrenado y darle datos específicos de la tarea posterior, de modo que el modelo continúe entrenando en los pesos preentrenados hasta que cumpla con los estándares de rendimiento de la tarea posterior. El modelo de preentrenamiento es como un extractor de funciones , que puede extraer funciones efectivas para nosotros en función de la experiencia aprendida de los datos de entrenamiento anteriores , lo que mejora en gran medida el efecto del entrenamiento y la velocidad de convergencia de las tareas posteriores.
El ajuste fino completo se refiere a la actualización de cada parámetro del modelo preentrenado durante el entrenamiento de las tareas posteriores . Por ejemplo, en la figura, se da un ejemplo de ajuste fino completo de la matriz Q/K/V de Transformer Para cada matriz, sus parámetros deben participar en la actualización durante el ajuste fino .d*d
Una desventaja significativa del ajuste fino completo es que es costoso de entrenar . Por ejemplo, el volumen del parámetro de GPT3 es 175B , y solo puedo mantenerme alejado de los nobles de una sola tarjeta, sin mencionar la abrumación cuando se encuentra un error en el ajuste fino. Al mismo tiempo, dado que el modelo ha consumido suficientes datos y ganado suficiente experiencia en la etapa previa al entrenamiento, solo necesito encontrar una manera de agregar un módulo de conocimiento adicional al modelo , para que este pequeño módulo pueda adaptarse a mi flujo de trabajo. tareas, y el cuerpo principal del modelo permanece Simplemente déjelo sin cambios (congelar) .
¿Cómo agregar un módulo de conocimiento tan pequeño?
2. Ajuste de adaptador y ajuste de prefijo
Veamos dos métodos principales de ajuste local antes de que apareciera LoRA: Ajuste de adaptador y Ajuste de prefijo. Estos son también los dos métodos de ajuste fino para comparaciones clave en el documento original de LoRA.
2.1 Adaptación del adaptador
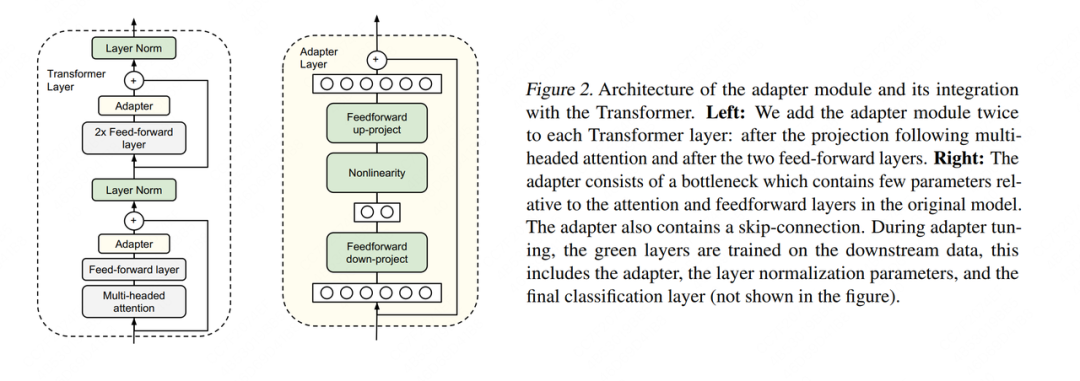
Hay muchos métodos de ajuste del adaptador. Aquí citamos el método propuesto por Houlsby et al., 2019, que también es el primer artículo citado cuando se menciona esta tecnología en el documento de LoRA.
El lado izquierdo de la leyenda es una capa de estructura de Capa de Transformador, el Adaptador es lo que llamamos "módulo de conocimiento adicional"; el lado derecho es la estructura específica de Adatper. Al realizar el ajuste fino, a excepción de la parte del adaptador, el resto de los parámetros se congelan (congelan) , para que podamos reducir efectivamente el costo de la capacitación. La arquitectura interna del Adaptador no es el tema central de este artículo, por lo que no la presentaremos aquí.
Pero una arquitectura de diseño de este tipo tiene una desventaja significativa: después de agregar el Adaptador, la cantidad total de capas del modelo será más profunda, lo que aumentará la velocidad de entrenamiento y la velocidad de razonamiento . Las razones son:
-
Necesita gastar potencia informática adicional en el adaptador
-
Cuando usamos el entrenamiento paralelo (por ejemplo: el paralelismo del modelo de tensor que se usa comúnmente en la arquitectura de Transformer), la capa del adaptador generará tráfico de comunicación adicional y aumentará el tiempo de comunicación.
2.2 Sintonización de prefijos

También hay muchos métodos de sintonización de prefijos. Aquí elegimos Li&Liang, 2021 para una breve introducción. En este artículo, el autor afina agregando un prefijo a los datos de entrada. Por supuesto, el prefijo no solo puede cargar la capa de entrada, sino que también puede agregarse a la salida de la capa intermedia mediante la capa del transformador. Los amigos interesados pueden buscar documentos y hacer su propia investigación.
Como se muestra en la figura, para un modelo generativo como GPT , se agrega un token de prefijo al frente de la secuencia de entrada y se agregan dos tokens de prefijo a la leyenda. En aplicaciones prácticas, el número de tokens de prefijo es un hiperparámetro, que se puede ajustar de acuerdo con el modelo real El efecto se ajusta. Para el modelo de arquitectura Codificador-Decodificador como BART , el token de prefijo se agrega delante de xey al mismo tiempo. En el ajuste fino posterior, solo necesitamos congelar el resto del modelo y entrenar los parámetros relacionados con el token de prefijo por separado.Cada tarea posterior puede entrenar un conjunto de tokens de prefijo por separado.
Entonces, ¿cuál es el significado del prefijo ? La función del prefijo es guiar al modelo para extraer información relacionada con x, y luego generar y mejor. Por ejemplo, si queremos hacer una tarea de resumen , después de un ajuste fino, el prefijo puede darse cuenta de que lo que estamos haciendo es una tarea de "formulario de resumen", y luego guiar al modelo para extraer información clave de x; si queremos hacer una tarea de clasificación de sentimiento , el prefijo puede guiar al modelo para extraer la información semántica relacionada con la emoción en x, y así sucesivamente. Esta explicación puede no ser tan rigurosa, pero puede comprender aproximadamente el papel del prefijo.
Aunque Prefix Tuning parece conveniente, también tiene las siguientes dos desventajas significativas :
-
Es difícil de entrenar y el efecto del modelo no aumenta estrictamente con el aumento del parámetro del prefijo, que también se señala en el documento original.
-
Reducirá la longitud de información efectiva de la capa de entrada. Para ahorrar memoria de cálculo y video, generalmente fijamos la longitud de los datos de entrada. Después de agregar el prefijo, queda menos espacio para los datos del texto original, por lo que la capacidad expresiva del mensaje en el texto original puede verse reducida.
3. Qué es LoRA
En resumen, el ajuste fino de parámetros completos es demasiado costoso, el ajuste de adaptador tiene retrasos de entrenamiento e inferencia, el ajuste de prefijo es difícil de entrenar y reducirá la longitud efectiva del texto en los datos de entrenamiento originales, por lo que existe un método de ajuste fino que pueda mejorar estas deficiencias?
Impulsado por tal motivación, el autor propuso un método de ajuste como LoRA (Adaptación de rango bajo, adaptador de rango bajo) . Dejemos de lado la explicación de palabras abstractas como "rango bajo" y "adaptador". Primero veamos cómo se ve LoRA y cómo usarlo. En la siguiente sección, explicaremos en detalle el principio del efecto de "rango bajo".
3.1 Arquitectura general de LoRA
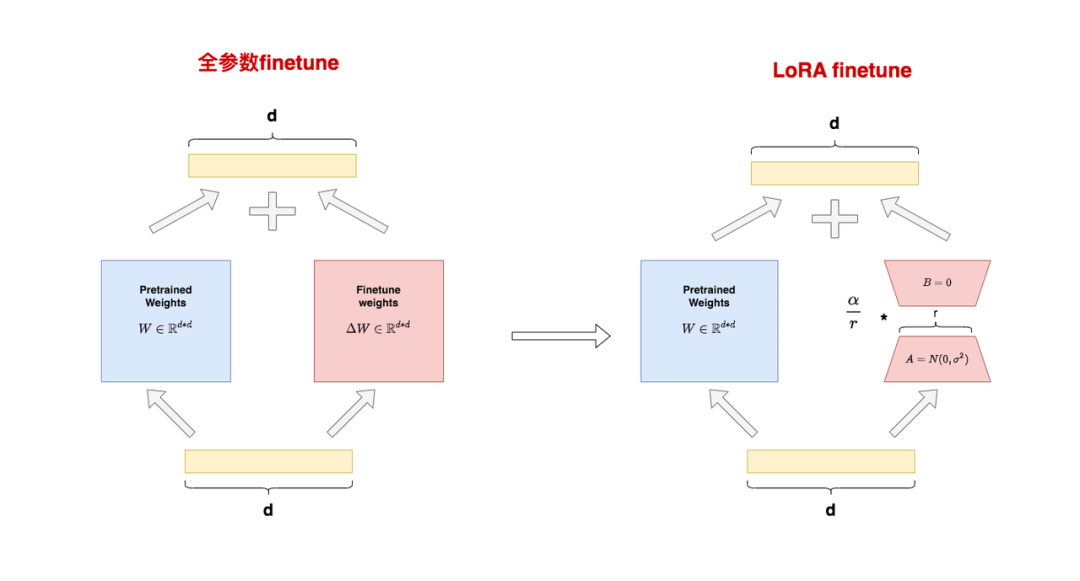
El lado izquierdo de la figura muestra el escenario de "ajuste fino de parámetros completos" . Dividimos los parámetros en dos partes:
-
: pesos preentrenados
-
: ajuste fino del peso incremental
El motivo de esta división es que el ajuste fino de parámetros completo puede entenderse como "pesos congelados antes del entrenamiento" + "cantidad de actualización de peso generada durante el ajuste fino" . Si la entrada es y la salida es, entonces:
El lado derecho de la figura representa la escena de "LoRA finetune" . En LoRA, usamos las matrices A y B para aproximar la expresión:
-
: Una matriz de rango bajo, donde se llama "rango", inicializada con una Gaussiana para .
-
: Matriz de rango bajo, inicializada en cero para B.
Después de tal división, reescribiremos el formulario para d*dreducir la cantidad de parámetros de ajuste fino de a 2*r*d, sin cambiar la dimensión de los datos de salida, es decir, bajo LoRA tenemos:
Además, en el documento original se mencionó que para dos matrices de bajo rango, se usará un hiperparámetro (una constante) para realizar ajustes, pero no explica el papel de este hiperparámetro. Después de leer el código fuente de LoRA, descubrí que este hiperparámetro se multiplica directamente por la matriz de rango bajo como tasa de escala, es decir, el resultado final es :
En la práctica, generalmente se toma, por ejemplo, cuando el código fuente de LoRA está ajustado a GPT2, y cuando se realizan tareas de NLG, se toma. Más adelante presentaremos en detalle la función de esta tasa de escala, así como el significado específico de "rango".
Métodos de inicialización para A y B
Cabe señalar que el propósito de usar la inicialización gaussiana y la inicialización cero aquí es hacer que el valor al comienzo del entrenamiento sea 0, de modo que no traiga ruido adicional al modelo. Entonces es posible que desee preguntar, ¿ puedo hacer inicialización cero e inicialización gaussiana? De todos modos, parece que solo deja que la inicialización sea 0.
En respuesta a este problema, encontré una respuesta de LoRA sobre el problema de github:
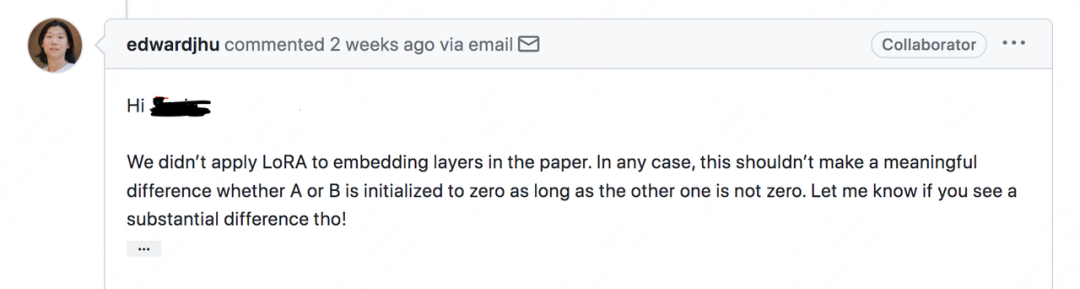
En resumen, el autor actual no ha encontrado una diferencia significativa en el método de inicialización de conversión, siempre que cualquiera de los dos sea 0 y el otro no sea 0 .
Comer gelatina sin escupir piel de gelatina
Largoplacismo, centrándose en la implementación de la ingeniería de IA (LLM/MLOps).
3.2 Proceso de entrenamiento y razonamiento de LoRA
En 3.1, presentamos la arquitectura general de LoRA : las matrices de bajo rango A y B se utilizan para aproximar las actualizaciones incrementales en la ruta de derivación de la matriz original previamente entrenada. Puede hacer esto en la capa del modelo que desee, como el peso de la capa MLP en Transformer, o incluso el peso de la parte de incrustación. En el documento original de LoRA, solo se realiza una adaptación de bajo rango a los parámetros de la parte Atención, pero en la operación real, podemos establecer de manera flexible el plan experimental de acuerdo con las necesidades y encontrar el mejor plan de adaptación.
3.2.1 Formación
Durante el entrenamiento , fijamos los pesos preentrenados y solo entrenamos en la suma de la matriz de rango bajo. Al guardar pesos, solo necesitamos guardar partes de la matriz de rango bajo . De acuerdo con las estadísticas del documento de LoRA, dicha operación reduce el consumo de memoria de 1,2 TB a 350 GB cuando se ajusta GPT3 175B; cuando r=4, el modelo guardado final cae de 350 GB a 35 MB, lo que reduce en gran medida la sobrecarga de capacitación.
Con respecto a la parte de entrenamiento, veamos otra pregunta interesante: en general, LoRA ahorra memoria de video de manera significativa, pero ¿LoRA puede ahorrar memoria de video en cada momento del entrenamiento ?
Al considerar hacia atrás, para calcular el gradiente, de acuerdo con (para la conveniencia de escribir la fórmula, se ignora temporalmente un elemento), tenemos:
Preste atención a este elemento, y encontrará que tiene exactamente la misma dimensión que el peso pre-entrenado d*d , es decir, para el gradiente calculado, necesitamos usar el mismo resultado de valor intermedio de tamaño que en el ajuste fino de parámetros completo proceso. Por lo tanto, para LoRA, la memoria máxima de esta capa es básicamente la misma que el ajuste fino completo (si se cuenta un elemento, es mayor que el ajuste fino completo).
Pero, ¿por qué LoRA puede reducir el uso general de la memoria , porque:
-
LoRA no actúa en todas las capas del modelo, por ejemplo, LoRA en el papel solo actúa en la parte de atención.
-
Aunque LoRA hará que la memoria máxima de una capa determinada sea mayor que la cantidad total de ajuste fino, después de calcular el gradiente, el resultado intermedio se puede borrar y no se guardará para siempre.
-
Cuando el peso a entrenar
d*dse reduce de2*r*d, los estados del optimizador que se deben guardar también se reducen (es decir, fp32).
3.2.2 Razonamiento
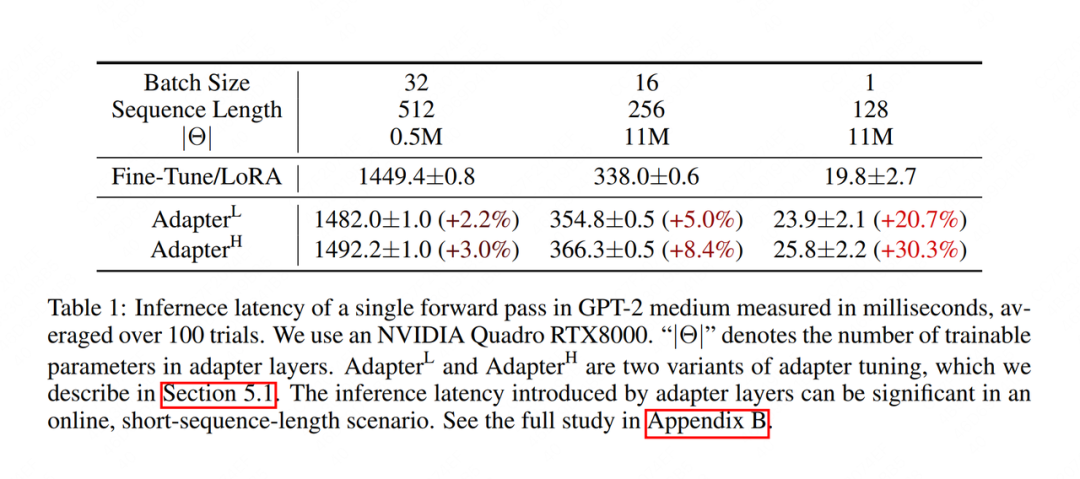
En el proceso de inferencia , fusionamos la matriz de rango bajo y los pesos preentrenados de acuerdo con el método , y luego hacemos la inferencia directa normalmente. De esta manera, no cambiaremos la arquitectura del modelo en absoluto, por lo que no habrá retraso de razonamiento como Adapter Tuning . La siguiente figura muestra los resultados experimentales en el documento. La unidad de tiempo de razonamiento es milisegundos. Se puede encontrar que la velocidad de razonamiento de LoRA es significativamente mayor que la de Adapter Tuning.
Al cambiar entre diferentes tareas posteriores , podemos eliminar de manera flexible partes de peso de bajo rango. Por ejemplo, primero hacemos la tarea A descendente, luego combinamos los pesos y mantenemos los pesos de rango bajo por separado. Cuando cambiamos a la tarea B aguas abajo, podemos ajustar restando la parte de peso de rango bajo de ella y luego encender el nuevo LoRA. Es decir, cada tarea posterior puede tener su propio conjunto de pesos de rango bajo.
Es posible que desee preguntar, después de cada ajuste, ¿tengo que combinar los pesos de rango bajo en el medio ? ¿Puedo almacenar "pesos preentrenados" y "pesos de rango bajo" por separado? Por supuesto, no hay problema, LoRA es muy flexible, puede reescribir el código según sus propias necesidades, decidir cómo ahorrar peso, siempre que domine un principio básico: si es adecuado o no, siempre puede distinguir entre pre-entrenamiento y parte LoRA, en la línea. En el capítulo de interpretación del código fuente, veremos este punto en detalle.
¡Felicidades! En este punto, dominas la estructura de LoRA. ¿No es muy simple, estás ansioso por probarlo? Sin embargo, como alquimista calificado, para depurar mejor el proceso de entrenamiento, necesitamos estudiar el principio de LoRA más profundamente.
4. El principio de la adaptación de bajo rango de LoRA
En el artículo anterior, hemos mencionado repetidamente el concepto de "rango" y explicado que el rango de LoRA es el hiperparámetro. Al mismo tiempo, también hemos enfatizado constantemente la aproximación de sí. En esta sección, daremos un vistazo concreto al "rango" y explicaremos por qué es "aproximado". Después de entender esto, podemos interpretar el papel de los hiperparámetros y captar una cierta sensación de alquimia .
4.1 ¿Qué es el rango?
Veamos primero una matriz A:
A = [[1, 2, 3],
[2, 4, 6],
[3, 6, 9]]
En esta matriz, fila2 = fila1 * 2, fila3 = fila1*3, es decir, cada fila de la matriz se puede representar linealmente por la primera fila .
Veamos otra matriz B:
B = [[1, 2, 3],
[7, 11, 5],
[8, 13, 8]]
En esta matriz, cualquier fila siempre se puede representar mediante una combinación lineal de las otras dos filas .
Veamos finalmente una matriz C:
C = [[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
En esta matriz, ninguna fila puede derivarse de una combinación lineal de las filas restantes.
Llamando np.linalg.matrix_ranka la función, podemos calcular el rango de cualquier matriz.Los rangos de las tres matrices anteriores son:
A = np.array(A)
B = np.array(B)
C = np.array(C)
print("Rank of A:", np.linalg.matrix_rank(A)) # 1
print("Rank of B:", np.linalg.matrix_rank(B)) # 2
print("Rank of C:", np.linalg.matrix_rank(C)) # 3
Para la matriz A, el rango de A es 1 porque mientras se domine cualquier fila, el resto de las filas se pueden derivar linealmente de esta fila.
Para la matriz B, el rango de B es 2 porque siempre que se dominen dos filas, el resto de las filas se pueden derivar de la combinación lineal de estas dos filas.
Para la matriz C, el rango de C es 3 porque se deben dominar por completo tres filas para obtener una C completa.
Al ver esto, ¿ya tiene una comprensión perceptiva del rango? El rango representa la cantidad de información en una matriz . Si una cierta dimensión en la matriz siempre se puede derivar linealmente a través de las otras dimensiones, entonces para el modelo, la información de esta dimensión es redundante y se expresa repetidamente. Para el caso de A y B, lo llamamos rango deficiente , y para el caso de C, lo llamamos rango completo . Para una definición matemática más rigurosa, puede consultar "Álgebra lineal" (狗头).
Con esta comprensión del rango, naturalmente pensamos que el peso incremental en el ajuste fino de parámetros completos también puede tener información redundante, por lo que no necesitamos representarlo d*dcon un tamaño completo. Entonces, ¿cómo encontramos la dimensión de característica realmente útil en ? La descomposición SVD (Singular Value Decomposition) , puede ayudarnos a resolver este problema
4.2 Descomposición SVD
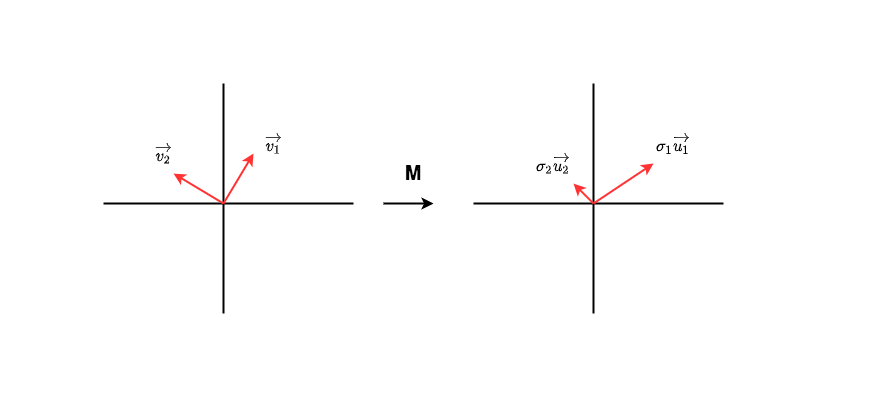
Como se muestra en la figura, la matriz es la matriz que necesitamos para verificar la cantidad de información. Supongamos que en el espacio de características de los datos de entrada hay un conjunto de vectores unitarios ortogonales.Después de la transformación, se convierten en otro conjunto de vectores ortogonales, que también son un conjunto de vectores unitarios ortogonales , que representan respectivamente el módulo en la dirección correspondiente . El cambio anterior se puede escribir como:
Con un poco de reescritura, hay:
No es difícil encontrar que hay un indicio de "volumen de información" implícito en . En este caso las transformaciones transformadas se proyectan sobre , enfatizando la información implícita en la dirección 1.
Ahora, de manera un poco más amplia, si podemos encontrar un conjunto de sumas de este tipo y organizar los valores de la matriz de mayor a menor, entonces podemos desmontarlo y, al mismo tiempo, descubrir los resaltados durante el proceso de desmontaje. orientación de características? Es decir:
Cuando encontramos una matriz de este tipo, sacamos las r filas (o columnas) superiores correspondientes de las tres, lo que equivale a prestar atención a las características de pocas dimensiones más enfatizadas, y luego podemos usar matrices de menor dimensión, Come a una expresión aproximada ? El método para desmantelar M de acuerdo con este tipo de pensamiento se llama descomposición SVD (descomposición en valores singulares) . No describiremos su método específico en este artículo, amigos que estén interesados, oye, también puedes referirte a "Álgebra lineal".
Usemos otro ejemplo de código para sentir esta aproximación de manera más intuitiva. Preste atención a los comentarios (ejemplo adaptado de: https://medium.com/@Shrishml/lora-low-rank-adaptation-from-the-first -principle- 7e1adec71541)
import torch
import numpy as np
torch.manual_seed(0)
# ------------------------------------
# n:输入数据维度
# m:输出数据维度
# ------------------------------------
n = 10
m = 10
# ------------------------------------
# 随机初始化权重W
# 之所以这样初始化,是为了让W不要满秩,
# 这样才有低秩分解的意义
# ------------------------------------
nr = 10
mr = 2
W = torch.randn(nr,mr)@torch.randn(mr,nr)
# ------------------------------------
# 随机初始化输入数据x
# ------------------------------------
x = torch.randn(n)
# ------------------------------------
# 计算Wx
# ------------------------------------
y = W@x
print("原始权重W计算出的y值为:\n", y)
# ------------------------------------
# 计算W的秩
# ------------------------------------
r= np.linalg.matrix_rank(W)
print("W的秩为: ", r)
# ------------------------------------
# 对W做SVD分解
# ------------------------------------
U, S, V = torch.svd(W)
# ------------------------------------
# 根据SVD分解结果,
# 计算低秩矩阵A和B
# ------------------------------------
U_r = U[:, :r]
S_r = torch.diag(S[:r])
V_r = V[:,:r].t()
B = U_r@S_r # shape = (d, r)
A = V_r # shape = (r, d)
# ------------------------------------
# 计算y_prime = BAx
# ------------------------------------
y_prime = B@A@x
print("SVD分解W后计算出的y值为:\n", y)
print("原始权重W的参数量为: ", W.shape[0]*W.shape[1])
print("低秩适配后权重B和A的参数量为: ", A.shape[0]*A.shape[1] + B.shape[0]*B.shape[1])
La salida es:
原始权重W计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
W的秩为: 2
SVD分解W后计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
原始权重W的参数量为: 100
低秩适配后权重B和A的参数量为: 40
El número de parámetros se reduce, pero no afecta el resultado de salida final . A través de este ejemplo, ¿pueden todos comprender mejor el papel de las matrices de bajo rango?
4.3 Adaptación de bajo rango de LoRA
Bueno, dado que la descomposición SVD es tan efectiva, puedo hacer SVD directamente y encontrar la matriz de rango bajo correspondiente, ¿no está hecho?
Aunque la idea es buena, la dificultad es obvia: la premisa de poder hacer SVD directamente es cierta , pero en realidad, a medida que aumenta el peso en el ajuste fino de los parámetros completos, si no ajusta los parámetros completos de nuevo, ¿cómo puedes saber cómo es? Y si ha realizado un ajuste fino completo, ¿qué necesita hacer con la adaptación de bajo rango?
Oye, puedes pensar de nuevo: ¿Puedo hacer SVD en los pesos preentrenados, porque es seguro?
Aunque la idea es buena, la lógica es irracional: dijimos que el propósito del ajuste fino es inyectar nuevos conocimientos de dominio relacionados con las tareas posteriores en el modelo . Es decir, el significado de la expresión de y es diferente, el primero es nuevo conocimiento y el segundo es viejo conocimiento , nuestro propósito es desmontar la dimensión rica en información en el nuevo conocimiento.
Bueno, dado que no es factible hacer SVD directamente a través de métodos matemáticos, ¡dejemos que el modelo aprenda cómo hacer SVD por sí mismo ! Por lo tanto, la última estrategia de adaptación de rango bajo de LoRA es: tomo el rango como un hiperparámetro y luego dejo que el modelo aprenda la matriz de rango bajo por sí mismo. ¡No es esto simple y sin problemas!
Bien, aquí tenemos una comprensión concreta del principio de la adaptación de bajo rango de LoRA, y también sabemos la diferencia del significado expresado. Ahora, podemos ver las preguntas que quedaron del artículo anterior: ¿Qué significa hiperparámetro ?
4.4 Hiperparámetros
Veamos primero la explicación del par de papeles:

Este pasaje significa aproximadamente que cuando usamos a Adam como optimizador, el ajuste es equivalente a ajustar la tasa de aprendizaje. En términos generales, establecemos las configuraciones a las que establecimos cuando experimentamos por primera vez, luego las arreglamos y luego solo las ajustamos. La ventaja de esto es que cuando probamos diferentes, no necesitamos ajustar otras. Es demasiado alto .
No sé cómo te sentiste cuando leíste este pasaje por primera vez, pero de todos modos no lo entendí. Google buscó de nuevo, pero no encontró una explicación específica. Hasta que analicé las ideas de diseño de la adaptación de bajo rango de LoRA en orden, parecía entender algo. Permítanme hablar sobre mis opiniones personales a continuación.
Primero, revise nuestro método de cálculo de salida como:
donde , denota los pesos pre-entrenados (conocimiento antiguo), y denota la aproximación de los pesos incrementales (conocimiento nuevo). Teóricamente hablando, cuando es más pequeño, extraemos la dimensión con más información en el medio, y la información es refinada pero no completa; cuando es más grande, nuestra aproximación de bajo rango es más cercana , y la información es más completa en este tiempo, pero con el que viene más ruido (contiene mucha información redundante y no válida).
Con base en esta conjetura, cuando hagamos el experimento por primera vez, intentaremos ajustarlo lo más grande posible, por ejemplo: 32, 64, y supondremos que bajo este rango, los pesos de rango bajo ya son muy similares, entonces lo configuramos en este momento, lo que significa que entonces asumimos que el efecto del ajuste fino de rango bajo de LoRA es igual al del ajuste fino de parámetros completos.
Así que a continuación, definitivamente intentaremos ir al pequeño. En este momento, lo arreglamos, lo que significa que a medida que disminuye, se volverá más y más grande. La razón por la que hacemos esto es:
-
Cuando el valor es menor, la información representada por la matriz de rango bajo es refinada pero no completa. Amplificamos la influencia de los nuevos conocimientos sobre el modelo en el proceso de avance ajustando el tamaño.
-
Cuando es más pequeño, la información representada por la matriz de bajo rango se refina y hay menos ruido/información redundante. En este momento, la dirección de descenso del gradiente es más segura. Por lo tanto, podemos aumentar el ritmo del gradiente. descenso aumentándolo, lo que equivale a ajustar la tasa de aprendizaje hacia arriba.
Bueno, aquí hemos aprendido juntos la idea central de la adaptación de bajo rango de LoRA. Como dijimos antes, debido a que SVD no se puede usar para la descomposición directa, el autor espera que LoRA pueda "aprender" la matriz de descomposición real de bajo rango, pero ¿cómo probar que lo que aprende LoRA está relacionado con lo que SVD descompone? A continuación, interpretemos juntos el experimento del autor.
5. Experimento LoRA: verificar la efectividad de la matriz de bajo rango
5.1 Efecto general
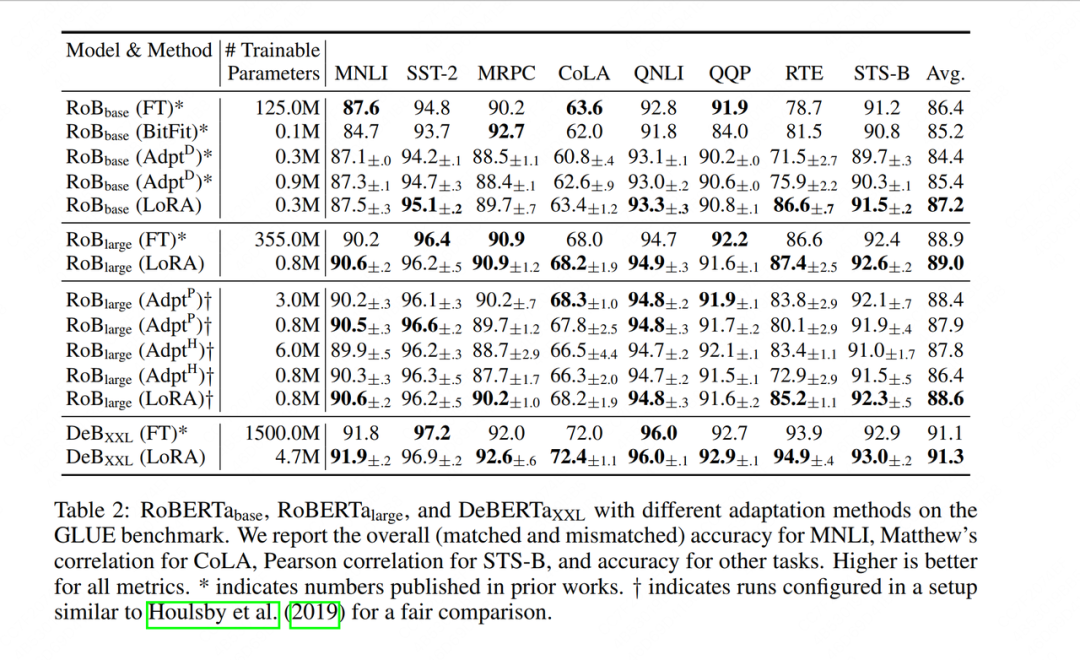
En primer lugar, el autor comparó LoRA con otros métodos de ajuste fino (ajuste fino de parámetros completos, ajuste de Adatper, etc.). Las columnas verticales representan diferentes modelos de ajuste fino, las columnas horizontales representan diferentes conjuntos de datos y las partes en negrita representan los mejores indicadores de rendimiento. Se puede encontrar que LoRA ha logrado un buen desempeño tanto en el índice de precisión de ajuste fino de cada conjunto de datos como en el índice de precisión de ajuste fino promedio final (Avg.), y la cantidad de parámetros que puede entrenar también es muy pequeña.
5.2 Verificación del contenido de la información de la matriz de bajo rango
Como dijimos antes, cuanto menor es el valor, más refinada es la información contenida en la matriz de rango bajo, pero al mismo tiempo puede ser menos completa. Entonces, ¿cuánto es apropiado?
5.2.1 Verificar directamente el efecto de ajuste fino bajo diferentes valores de r
Aunque en teoría podemos incrustar adaptadores de rango bajo (como Incrustación, Atención, MLP, etc.) en cualquier capa del modelo, pero en LoRA, solo elegimos incrustarlos en la capa de Atención, y hemos realizado experimentos relacionados (el papel también anima a los lectores a hacer más Otros intentos), veamos los resultados experimentales de la capa Atención:
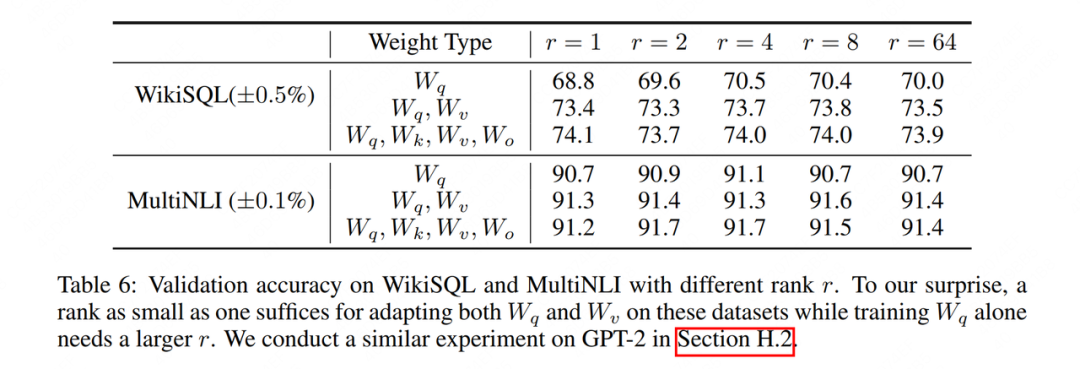
WikiSQLy MultiNLIes el conjunto de datos utilizado para el ajuste fino, y el tipo de ponderación indica qué parte de la atención se utiliza para la adaptación de bajo rango. Se puede encontrar que el efecto de Yu es casi el mismo, o incluso ligeramente mejor. Esto ilustra aún más la eficacia de "rango bajo". Para verificar esto más visualmente, observamos más a fondo el grado de intersección con estos dos espacios de bajo rango.
5.2.2 Grado de intersección de diferentes espacios de bajo rango
Asumiendo que y son matrices de rango bajo entrenadas bajo y respectivamente, ahora queremos hacer tal cosa:
-
Tome la dimensión más informativa (de la cual)
-
Tome la dimensión más informativa (de la cual)
-
Calcule el grado de intersección entre esta dimensión y una dimensión para determinar el grado de coincidencia de la información entre dos matrices de bajo rango
Bueno, ¿cómo averiguo la dimensión superior con la mayor cantidad de información? No olvides que tenemos el método SVD y esta vez la suma es determinista. Por lo tanto, podemos realizar la descomposición SVD en la matriz de bajo rango y luego obtener la matriz singular correcta de las dos (es decir, la mencionada anteriormente), pero en el artículo de LoRA, se usa para representar la matriz singular correcta, por lo que hacemos como los romanos, hacemos:
-
La matriz singular derecha representada por la matriz singular derecha representa la dimensión más informativa de la matriz singular derecha (revise el artículo anterior y juzgue el contenido de la información)
-
La matriz singular derecha representada por es la dimensión más informativa de la matriz singular derecha.
Bueno, después de aclarar estas definiciones, podemos mirar la dimensión de la característica y calcular el grado de intersección con la dimensión de la característica.Este índice de intersección también se llama " distancia de Grassmann ".
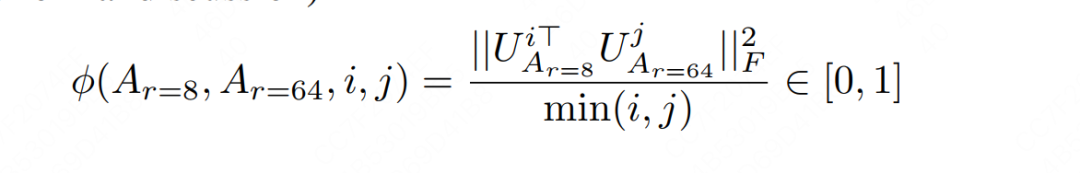
Se puede ver a partir de la fórmula anterior que el grado de intersección (distancia de Grassmann) es entre y cuanto mayor sea el valor, más similares serán los dos subespacios correspondientes. Los amigos interesados pueden consultar las pruebas pertinentes en el apéndice G del artículo. Aquí sólo nos centramos en la conclusión.
Bien, después de calcular este indicador, visualicémoslo, entonces el autor continúa dando las siguientes cuatro imágenes:
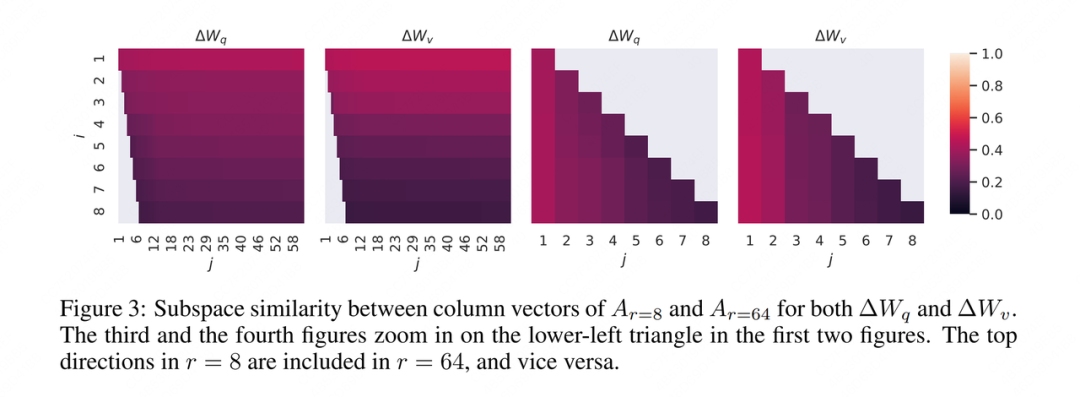
No sé cómo te sentiste cuando viste esta imagen por primera vez, de todos modos, no lo entendí (oye, siento que ya había escuchado esto antes). Así que aquí está mi (irresponsable) interpretación de nuevo.
En primer lugar, el autor ha realizado una descomposición de bajo rango en lo anterior, por lo que las imágenes 1 y 3 y las imágenes 2 y 4 son respectivamente un grupo, elijamos las imágenes 1 y 3 para ver.
En segundo lugar, el propósito del experimento del autor es ver cuánta información del espacio de rango bajo está contenida en el espacio de rango alto, para explicar por qué el efecto de la suma es básicamente el mismo .
Entonces, la lógica del autor al calcular la distancia de Grassmann y dibujar el gráfico es:
-
Sí, en ese momento quería calcular la similitud con , para poder saber cuánta información unidimensional más abundante contenía .
-
Sí, en ese momento quería calcular la similitud con , para poder saber cuánta información bidimensional más abundante contenía .
-
Por analogía, porque lo que quiero verificar es el grado de inclusión del espacio de rango grande () al espacio de rango pequeño (), entonces solo dibujo la parte, y el resto no se dibujan. Es por eso que hay un espacio en blanco en la esquina inferior izquierda de la Figura 1.
-
Esa parte, es decir, la medida en que el espacio de rango pequeño incluye la dimensión superior en el espacio de rango grande, aunque no lo dibujé en la Figura 1, puedo dibujarlo por separado en la Figura 3. Entonces, la Figura 3 es en realidad el relleno de la parte que falta en la esquina inferior izquierda de la Figura 1.
Ok, ahora que esto está explicado, veamos la leyenda en detalle. Cuanto más claro es el color, mayor es la similitud . En la Figura 1, no es difícil encontrar que el color de esta línea es el más claro, y el color se oscurece gradualmente con el aumento de . Esto muestra que en el espacio de rango pequeño, las características dimensionales con mayor contenido de información tienen un mayor grado de intersección con el espacio de rango grande, por lo que también son la razón principal por la que el rendimiento del espacio de rango pequeño puede ser igual a la del espacio de rango grande .Dijo validez de "rango bajo".
Viendo la conclusión de este cuadro, quizás te surja una duda: ¿No significa que se toman las 8 dimensiones con más información, sino que se toman las 64 dimensiones con más información? ¡Entonces sus primeras 8 dimensiones deberían ser las mismas! Entonces, con el aumento de , ¿no debería la coincidencia espacial hacerse más y más grande? ¿Cómo es el resultado del gráfico cada vez más pequeño?
Esto se debe a que el fenómeno de "tomar las 8 dimensiones con la mayor cantidad de información y tomar las 64 dimensiones con la mayor cantidad de información" es nuestro ideal, pero no es el caso cuando el modelo se aprende realmente. El modelo aprenderá de la dimensión más informativa tanto como sea posible, pero no hay garantía de cuánto tomará. El objetivo superior r debe aprenderse al final . Solo se puede decir que cuando r es relativamente pequeño, el Es más probable que el modelo esté cerca de la parte superior real r; cuando r es relativamente grande, el modelo aprende información valiosa y algo de ruido , y este experimento solo demuestra este punto.
Si entendemos esto, podemos interpretar mejor el siguiente experimento: ¿ cómo establecer la r de diferentes capas del modelo?
5.2.3 Configuración del valor r para diferentes capas
Vimos anteriormente que LoRA actúa sobre y , por lo que para estas dos matrices diferentes, ¿hay alguna diferencia en la configuración de valores?
Para responder a este punto, el autor diseñó otro experimento: para tres matrices, establezca dos semillas aleatorias diferentes para cada matriz, ejecute dos matrices de rango bajo diferentes y calcule la distancia de Grassmann de estas dos matrices de rango bajo. El resultado es como sigue:
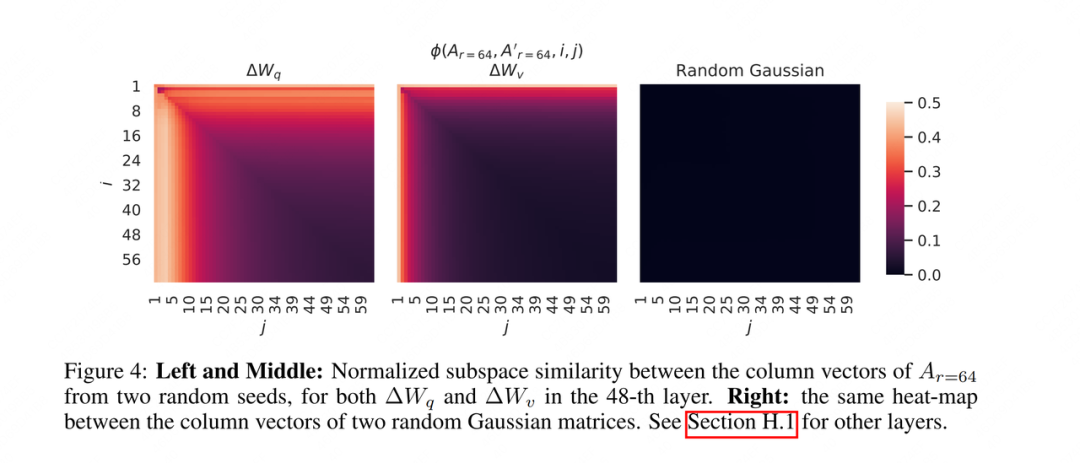
Como explicamos antes, los dos grupos no aprendieron a la perfección la información de 64 dimensiones superior más objetiva, sino "información parcialmente válida + algo de ruido". Basado en esto, no es difícil imaginar que ambos grupos puedan aprender La información es probable ser información útil. Por lo tanto, también calculamos la similitud de estos dos grupos. En la figura de la izquierda, podemos ver que los 10 principales tienen el color más claro, y la información dentro de este puede ser información más efectiva. Dependiendo de los resultados de dicho análisis, también podemos usar diferentes rangos para diferentes partes del modelo.
5.2.4 Pesos previos al entrenamiento VS pesos de ajuste fino
Dijimos antes que los pesos previos al entrenamiento son un conocimiento antiguo y que los pesos de ajuste fino son un conocimiento nuevo. Entonces, normalmente, debería haber algunas partes a las que no se les ha prestado atención. Por lo tanto, también necesitamos demostrar si la matriz de bajo rango que hemos entrenado cumple con este punto. Los resultados experimentales diseñados por el autor son los siguientes:

Entre ellos, significa que el resultado aproximado por la matriz de bajo rango después del entrenamiento no es la existencia objetiva mencionada anteriormente.
Interpretemos este experimento:
-
Primero mire la fila inferior de la tabla y calcule las normas para los pesos previos al entrenamiento y los pesos incrementales respectivamente. Podemos entender aproximadamente este indicador como la cantidad total de información contenida en él.
-
A continuación, encontramos el índice.Aquí tenemos 6 conjuntos de valores: los primeros 3 son del resultado de la descomposición de valores singulares de la matriz de tiempo, y los últimos tres se deducen por analogía. Por lo tanto, significa: proyectar los pesos previos al entrenamiento en los espacios de características aproximados de rango bajo de los tres, y calcular la cantidad de información en el espacio de características correspondiente después de la proyección. Si es más similar al espacio de características correspondiente, el valor será mayor.
Solo mirar el concepto no es un poco confuso, busquemos un indicador específico para interpretarlo:
-
Primero mire el grupo de 61.95 y 21.67. 61,95 representa la cantidad de información que tiene el propio peso previo al entrenamiento, y 21,67 representa la cantidad de información proyectada en su propio espacio de rango bajo (la proyección al espacio de rango bajo inevitablemente resultará en la pérdida de información).
-
Veamos el grupo de 0.32 y 0.02. 0,32 indica la cantidad de información después de que el peso previo al entrenamiento se proyecta en el espacio de rango bajo del peso incremental, y 0,02 es lo mismo. Se puede ver que en comparación con los pesos aleatorios, los pesos incrementales que contienen nuevos conocimientos aún tienen cierta correlación con los pesos pre-entrenados.
-
Finalmente, veamos 6.91 y 0.32. Después de que los pesos previos al entrenamiento se proyectan en el espacio de rango bajo de los pesos incrementales, la cantidad de información disminuye de 61,95 a 0,32, lo que indica que todavía hay una diferencia significativa entre las distribuciones de los pesos previos al entrenamiento (conocimiento antiguo) y pesos incrementales (nuevos conocimientos). 6,91 representa la cantidad de información en el propio peso incremental. Por lo tanto, el valor de 21,95 = 6,91/0,32 solo puede representar el grado en que el peso incremental amplifica la información no enfatizada en el peso previo al entrenamiento. Cuanto menor sea el rango, más evidente será el grado de amplificación.
¡bien! Con respecto a la introducción del principio de LoRA, aprenderemos aquí juntos. Es posible que este artículo dedique mucho espacio a la introducción del experimento. Por un lado, a través del experimento, puede ayudarnos a comprender mejor el significado y el papel del rango bajo; por otro lado, personalmente creo que los resultados del experimento LoRA no son muy fáciles de leer, así que quiero dedicar un tiempo a investigarlo. Entonces, en el próximo artículo, interpretemos la implementación del código de LoRA nuevamente.

Comer gelatina sin escupir piel de gelatina
Largoplacismo, centrándose en la implementación de la ingeniería de IA (LLM/MLOps).
67 contenido original
sin publico
6. Referencia
1, https://arxiv.org/pdf/2106.09685.pdf
2, https://github.com/microsoft/LoRA
3, https://medium.com/@Shrishml/lora-low-rank-adaptation-from -el-primer-principio-7e1adec71541
4, https://blog.sciencenet.cn/blog-696950-699432.html
5, https://kexue.fm/archives/9590/comment-page-1