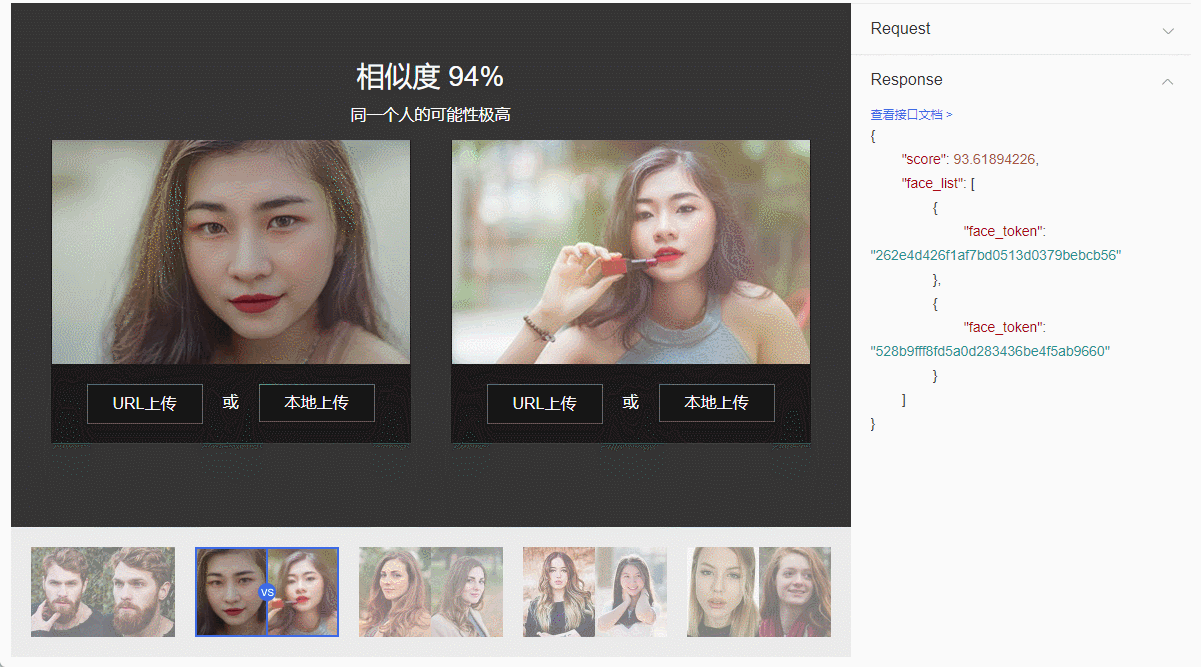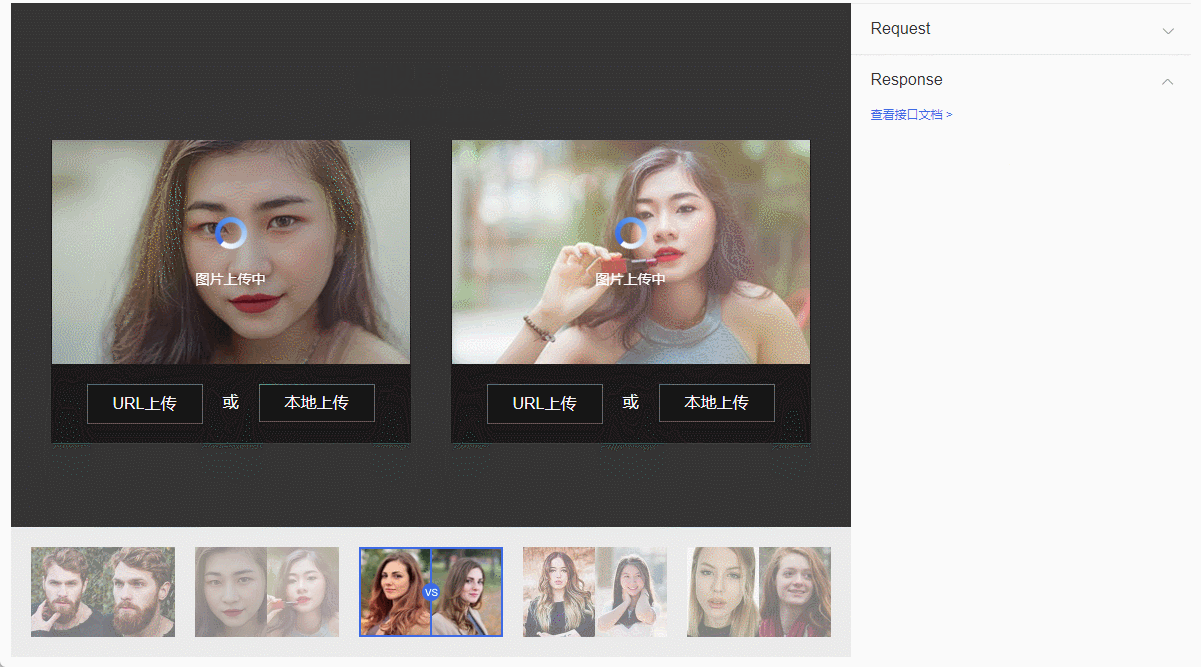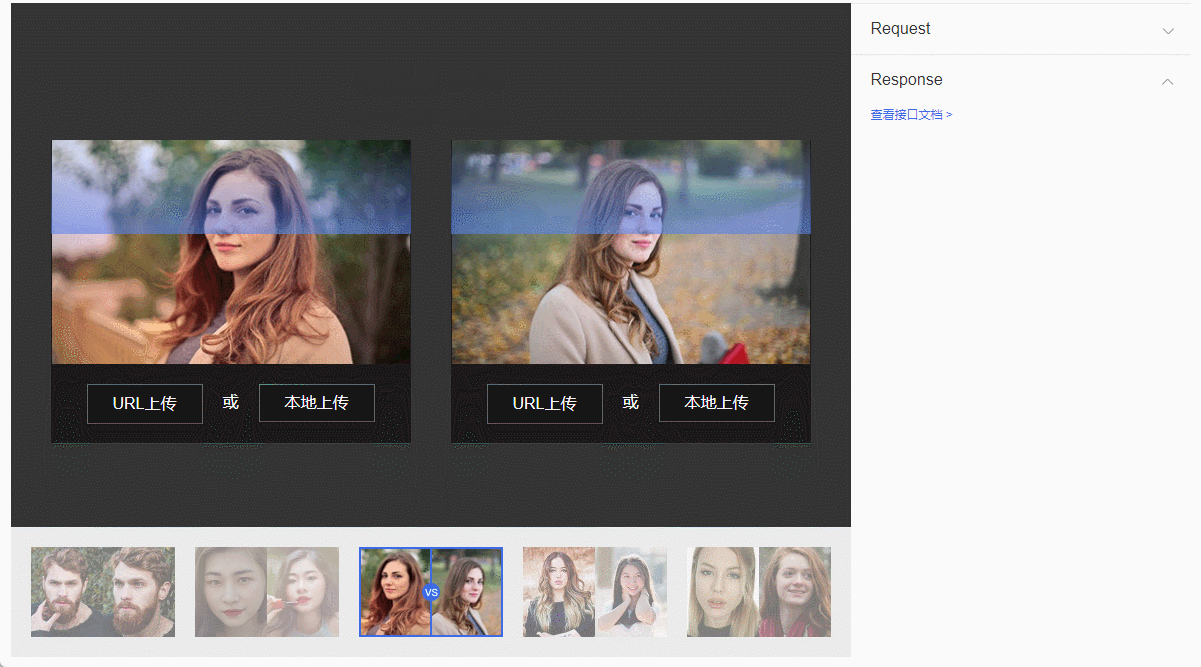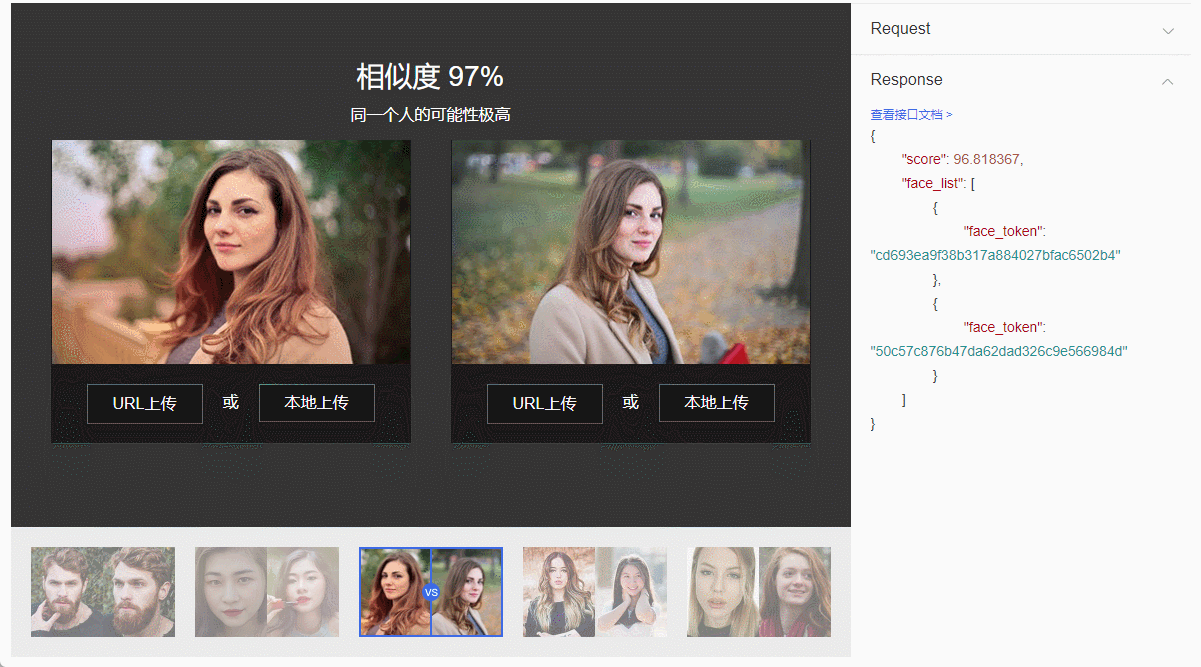
Tecnología de reconocimiento facial: del principio a la aplicación
introducción
La importancia y los campos de aplicación de la tecnología de reconocimiento facial.
La tecnología de reconocimiento facial es de gran importancia y tiene una amplia gama de aplicaciones en la sociedad actual. No sólo desempeña un papel clave en el campo del comercio y la seguridad, sino que también aporta muchas innovaciones y comodidades a diversas industrias.
En el campo comercial, la tecnología de reconocimiento facial se utiliza en investigaciones de mercado y análisis de clientes para ayudar a las empresas a comprender las preferencias y comportamientos de los consumidores, mejorando así los productos y servicios y aumentando la satisfacción y lealtad del cliente. Además, también se utiliza en el sistema de pago de la industria minorista, que realiza pagos convenientes con el gesto de deslizar el rostro y simplifica la experiencia de compra.
En el ámbito de la seguridad, la tecnología de reconocimiento facial es muy utilizada en sistemas de vigilancia y control de acceso. Puede identificar y autenticar personas, garantizando que solo el personal autorizado pueda ingresar a áreas específicas, aumentando la seguridad y la protección. En términos de aplicación de la ley y seguridad pública, el reconocimiento facial puede ayudar a rastrear a sospechosos de delitos y fortalecer el orden social.
Además, la tecnología de reconocimiento facial también tiene aplicaciones en el campo de la atención sanitaria, como por ejemplo para el diagnóstico de enfermedades y la formulación de planes de tratamiento. Puede analizar los rasgos faciales del paciente para ayudar a los médicos a realizar un diagnóstico más preciso y un tratamiento personalizado.
Aunque la tecnología de reconocimiento facial ofrece un gran potencial en muchos campos, también es necesario considerar cuestiones éticas y de privacidad para garantizar su uso legal y transparente a fin de equilibrar la innovación tecnológica y el valor social.
Principios básicos del reconocimiento facial
Adquisición y preprocesamiento de imágenes
La adquisición y el preprocesamiento de imágenes son pasos importantes en la tecnología de reconocimiento facial. En la etapa de adquisición de imágenes, se utilizan cámaras u otros dispositivos para capturar imágenes de rostros. El preprocesamiento es una serie de operaciones realizadas en imágenes adquiridas para optimizar la calidad y precisión de la imagen. Los siguientes son los pasos generales de adquisición y preprocesamiento de imágenes:
- Adquisición de imágenes: utilice equipos adecuados (como cámaras, cámaras de teléfonos móviles, etc.) para adquirir imágenes de rostros. Se debe prestar atención a las condiciones de luz y a los ángulos de disparo durante la adquisición para garantizar que la calidad de la imagen sea lo suficientemente buena para el procesamiento y análisis posteriores.
- Evaluación de la calidad de la imagen: después de la adquisición, es posible que sea necesario realizar una evaluación de la calidad de la imagen para filtrar las imágenes de baja calidad y reducir el ruido y los errores en el procesamiento posterior.
- Detección de rostros: utilice el algoritmo de detección de rostros para localizar automáticamente el área del rostro en la imagen. Esta es la base del reconocimiento, asegurando que el procesamiento posterior solo se centre en el área de la cara.
- Alineación de rostros: las imágenes de rostros pueden cambiar debido a diferentes ángulos y posturas de disparo. En el proceso de preprocesamiento, el método comúnmente utilizado es alinear las caras de modo que las posiciones de puntos característicos como ojos, narices y bocas en la imagen sean consistentes, reduciendo así la dificultad del reconocimiento posterior.
- Mejora de la imagen: mejore la imagen, como eliminación de ruido, mejora del contraste, ecualización de histograma, etc., para mejorar la calidad de la imagen y realzar los rasgos faciales.
- Extracción de características: después del preprocesamiento, el algoritmo de extracción de características se puede utilizar para convertir las características de la cara en la imagen en una representación vectorial matemática, lo cual es conveniente para la identificación y comparación posteriores.

Extracción y representación de características

La extracción y representación de características se refiere al proceso de convertir los rasgos faciales de una imagen en una representación vectorial matemática. En este paso, se utilizan diferentes algoritmos y técnicas para extraer las características clave del rostro, de modo que estas características puedan representar el rostro de manera efectiva, facilitando así el reconocimiento y la comparación posteriores. Los métodos de extracción de características comúnmente utilizados incluyen, entre otros:
- Análisis de componentes principales (PCA): encuentre las características principales que mejor representan los datos originales reduciendo la dimensionalidad de los datos.
- Análisis discriminante lineal (LDA): mientras reduce la dimensionalidad, optimice la distancia dentro de la clase y entre clases para mejorar la discriminación de características.
- Patrón binario local (LBP): captura información de textura local codificando píxeles en una imagen.
- Factorización matricial no negativa (NMF): descompone los datos en patrones y coeficientes subyacentes no negativos para la extracción y representación de características.
Estos métodos pueden convertir imágenes de rostros en vectores con dimensiones fijas, que contienen información importante sobre las características de los rostros. Estos vectores se pueden utilizar en aplicaciones como reconocimiento facial, detección de rostros y análisis de expresiones faciales para proporcionar una representación de datos más concisa y eficiente para tareas posteriores.
Coincidencia y comparación de datos.
La coincidencia y comparación de datos es una tarea clave. Los métodos comúnmente utilizados incluyen, entre otros:
- Distancia euclidiana: Calcule la distancia euclidiana entre vectores, cuanto más cerca de 0, mayor será la similitud.
- Similitud del coseno: Calculando el coseno del ángulo entre vectores, podemos medir su similitud.
- Coeficiente de correlación de Pearson: se utiliza para medir la correlación entre dos variables y es adecuado para el caso de correlación entre características.
- Distancia de Hamming: se utiliza principalmente para comparar la diferencia entre dos cadenas de igual longitud y es adecuada para el caso en que el vector de características es binario.
Según los tipos de datos específicos y los escenarios de aplicación, elegir un método de comparación adecuado puede mejorar la precisión y la eficiencia de la coincidencia. El resultado de la comparación se puede utilizar para determinar si dos datos son iguales o similares, y luego se puede aplicar en campos como reconocimiento facial, reconocimiento de huellas dactilares y coincidencia de similitud de texto.
Métodos tradicionales de reconocimiento facial
Análisis de Componentes Principales (PCA)
El análisis de componentes principales (PCA) es una técnica de reducción de dimensionalidad comúnmente utilizada para convertir datos de alta dimensión en datos de baja dimensión conservando al mismo tiempo la información de características más importante. El objetivo de PCA es encontrar los componentes principales más informativos en los datos originales para comprimirlos y simplificarlos. Los pasos de PCA son los siguientes:
- Estandarización de datos: estandarice los datos originales para que cada dimensión tenga la misma importancia y evite afectar los resultados del análisis debido a diferencias dimensionales en diferentes dimensiones.
- Calcule la matriz de covarianza: Calcule la matriz de covarianza para los datos estandarizados, que refleja la correlación entre cada dimensión de los datos.
- Calcular valores propios y vectores propios: Al descomponer los valores propios de la matriz de covarianza, se obtienen los valores propios y los vectores propios correspondientes. Los vectores propios son los componentes principales de los datos y los valores propios representan la importancia de cada componente principal.
- Seleccionar componentes principales: seleccione los k componentes principales principales más importantes de acuerdo con el tamaño de los valores propios, donde k es la dimensión después de la reducción de dimensión.
- Datos de proyección: proyecte los datos originales en los k componentes principales seleccionados para obtener la representación de datos dimensionalmente reducida.
PCA se utiliza ampliamente en muchos campos, como el procesamiento de imágenes, la compresión de datos, la extracción de características, etc. PCA puede convertir datos de alta dimensión en representaciones de baja dimensión, reducir la dimensión de los datos y al mismo tiempo conservar las características principales de los datos, lo que ayuda a mejorar la eficiencia y precisión del procesamiento de datos.
Análisis discriminante lineal (LDA)
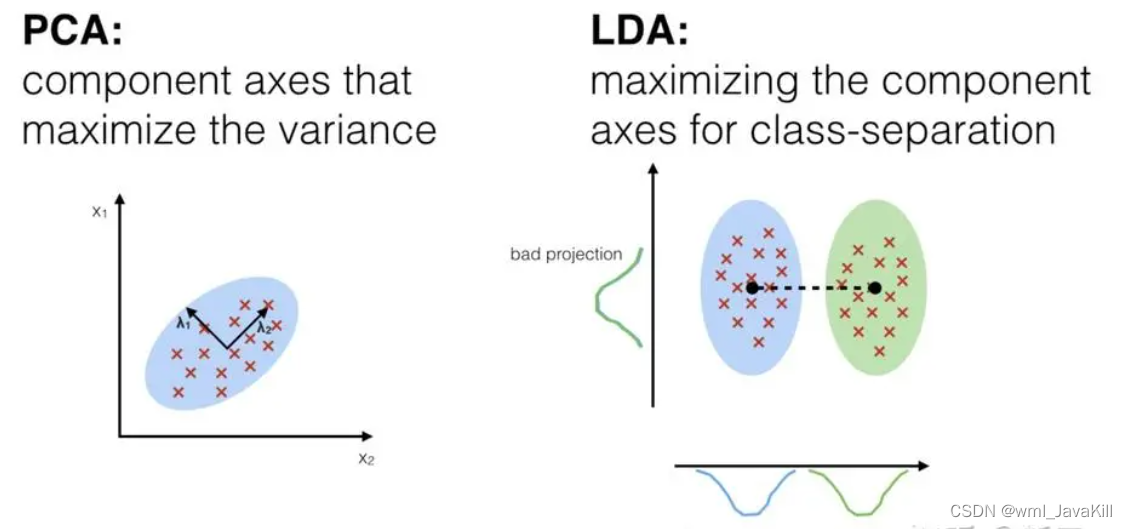
El análisis discriminante lineal (LDA) es un método común de reconocimiento de patrones y reducción de dimensionalidad de datos, que se utiliza principalmente para encontrar la dirección de proyección óptima en tareas de clasificación, de modo que diferentes categorías de datos tengan una mejor separabilidad después de la proyección. Los pasos de LDA son los siguientes:
- Calcule la matriz de dispersión intraclase: calcule la matriz de covarianza para los datos dentro de cada clase y luego agregue estas matrices de covarianza para obtener la matriz de dispersión intraclase.
- Calcule la matriz de dispersión entre clases: calcule el vector medio de cada categoría, calcule la matriz de covarianza entre las categorías y luego agregue estas matrices de covarianza para obtener la matriz de dispersión entre clases.
- Calcule el problema de valores propios generalizado: al resolver el problema de valores propios generalizado (la relación entre la matriz de dispersión intraclase y la matriz de dispersión entre clases), se obtienen el valor propio y el vector propio de la dirección de proyección.
- Seleccione los componentes principales: seleccione los vectores propios k superiores más importantes como dirección de proyección de acuerdo con el tamaño de los valores propios, donde k es la dimensión después de la reducción de dimensión.
- Datos de proyección: proyecte los datos originales en los k vectores de características seleccionados para obtener la representación de datos dimensionalmente reducida.
El objetivo de LDA es maximizar la diferencia entre clases y minimizar la diferencia dentro de las clases, para lograr mejores resultados de clasificación. LDA tiene una amplia gama de aplicaciones en muchas tareas de reconocimiento de patrones y aprendizaje automático, especialmente para escenarios de aprendizaje supervisado.
Aplicación de la transformada Wavelet en el reconocimiento facial

La aplicación de la transformada wavelet en el reconocimiento facial se puede demostrar de las siguientes maneras
- Extracción de características: la transformada Wavelet puede descomponer la imagen de la cara en subimágenes de diferentes escalas y frecuencias. Al realizar una transformación wavelet en estas subimágenes, podemos extraer las características locales de la imagen, como la textura, los bordes y otra información. Estas características se pueden utilizar para entrenar modelos o compararlas con rasgos faciales en la base de datos.
- Alineación de rostros: dado que diferentes rostros pueden tener diferentes poses, escalas y ángulos, es necesario alinearlos antes del reconocimiento facial. La transformada Wavelet puede ajustar la escala y el ángulo de la imagen para que la cara tenga una posición y un tamaño consistentes en el espacio. Esta operación de alineación puede mejorar la precisión del reconocimiento facial.
- Reconstrucción de imagen: la transformada Wavelet puede descomponer la imagen de la cara en diferentes componentes de frecuencia. Durante el proceso de reconstrucción, podemos preservar los componentes de frecuencia de interés mientras suprimimos el ruido y los componentes irrelevantes. Al procesar y analizar la imagen reconstruida, se pueden distinguir mejor los rasgos de los rostros humanos.
- Análisis de textura: la transformada Wavelet puede extraer la información de textura de imágenes faciales, como arrugas y manchas. Esta información de textura se puede utilizar para el análisis de texturas en tareas de reconocimiento facial, lo que ayuda a mejorar la precisión y solidez del reconocimiento facial.
La aplicación de la transformada wavelet en el reconocimiento facial se refleja principalmente en la extracción de características, alineación de rostros, reconstrucción de imágenes y análisis de texturas. Al utilizar las ventajas de la transformada wavelet, se puede mejorar el rendimiento y la solidez del sistema de reconocimiento facial y se pueden lograr resultados de reconocimiento facial más precisos y estables.
Aprendizaje profundo y reconocimiento facial
El aprendizaje profundo es un método de aprendizaje automático que aprende y representa características de datos complejas mediante la construcción de un modelo de red neuronal multicapa. En el campo del reconocimiento facial, el aprendizaje profundo ha logrado avances importantes y se ha convertido en una de las tecnologías de reconocimiento facial más avanzadas.
Fundamentos de las redes neuronales convolucionales (CNN)
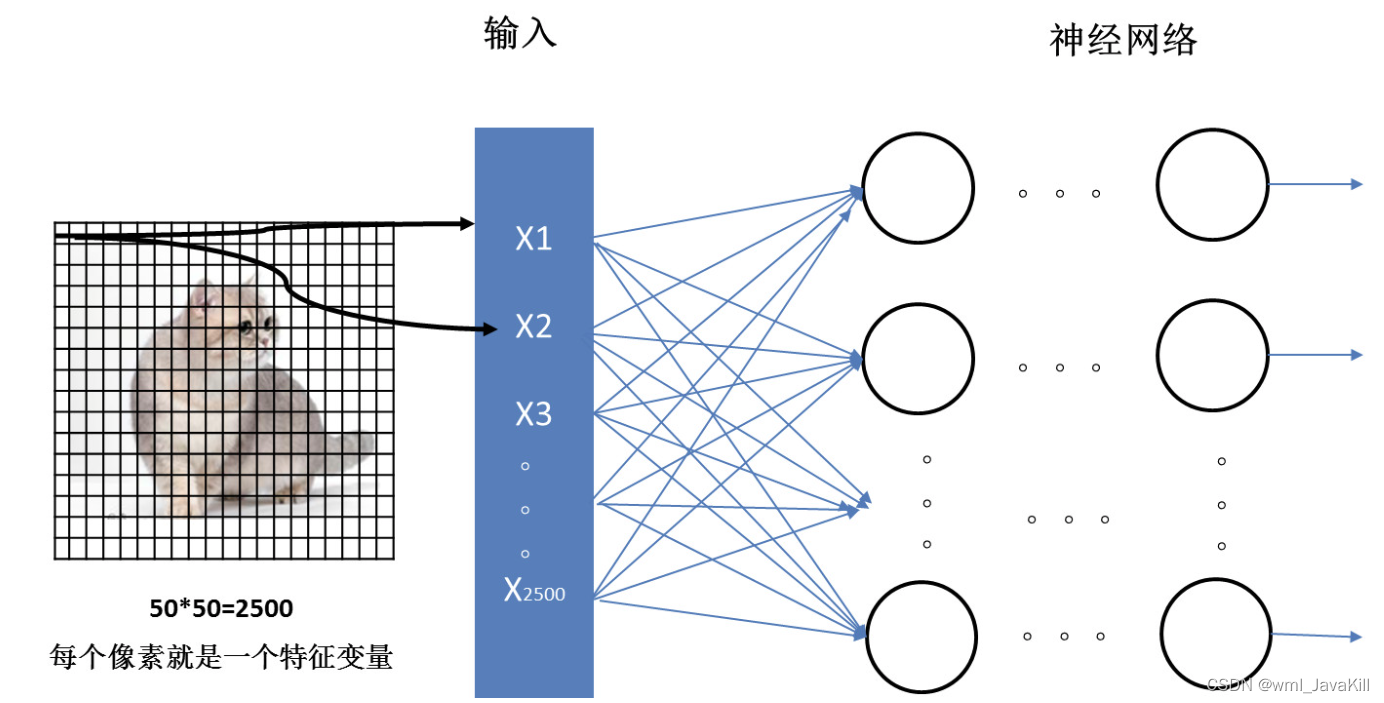
La red neuronal convolucional (CNN) es un modelo de aprendizaje profundo, especialmente adecuado para procesar datos con una estructura de cuadrícula, como imágenes y voz. Los siguientes son los principios básicos de CNN:
- Operación de convolución: la operación más importante en CNN es la operación de convolución. La operación de convolución realiza una percepción local de los datos de entrada a través de un filtro deslizante (también llamado núcleo de convolución), extrayendo así las características de los datos de entrada. El filtro se produce por puntos con los datos de entrada, lo que da como resultado un mapa de características (también conocido como característica convolucional). La operación de convolución no solo puede capturar características espaciales locales, sino también preservar la relación de posición espacial de las características.
- Función de activación: después de una capa convolucional, generalmente se aplica una función de activación para introducir no linealidades. La función de activación realiza una transformación no lineal elemento por elemento en la salida de la capa convolucional para aumentar la capacidad expresiva de la red. Las funciones de activación más utilizadas incluyen ReLU (Unidad lineal revisada), Sigmoide y Tanh, etc.
- Operación de agrupación: la operación de agrupación mejora la eficiencia computacional al reducir el tamaño y la cantidad de parámetros del mapa de características y modela la invariancia espacial de los datos de entrada hasta cierto punto. Una operación de agrupación común es la agrupación máxima, donde el valor máximo se selecciona como salida en cada región local. La operación de agrupación puede reducir la dimensión espacial del mapa de características y al mismo tiempo preservar información importante sobre las características.
- Estructura multicapa: CNN generalmente consta de múltiples capas convolucionales, capas de función de activación y capas de agrupación alternativamente. A través de convolución multinivel, transformación no lineal y operaciones de agrupación, la red puede aprender gradualmente representaciones de características más abstractas y de nivel superior. Las CNN profundas son más expresivas y pueden manejar tareas más complejas.
- Capa completamente conectada: después de múltiples capas de operaciones de convolución y agrupación, la última capa suele ser una capa completamente conectada. La capa completamente conectada aplana todos los mapas de características de la capa anterior en un vector unidimensional y genera el resultado final mediante la multiplicación de matrices y la función de activación. Las capas completamente conectadas pueden realizar combinaciones de alta dimensión y mapeo de características para clasificación, regresión u otras tareas.
- Algoritmo de retropropagación: el entrenamiento de CNN generalmente utiliza el algoritmo de retropropagación para actualizar los parámetros de la red. La retropropagación calcula el gradiente de la función de pérdida con respecto a los parámetros de cada capa y ajusta los parámetros a lo largo de la dirección del gradiente. De esta manera, CNN puede aprender una representación y un clasificador de características efectivos a través de un entrenamiento iterativo repetido en conjuntos de datos a gran escala.
Ventajas del aprendizaje profundo en la detección y el reconocimiento de rostros
El aprendizaje profundo tiene las siguientes ventajas en la detección y el reconocimiento de rostros
- Alta precisión: los modelos de aprendizaje profundo se pueden entrenar con conjuntos de datos a gran escala para aprender representaciones más precisas de los rasgos faciales. En comparación con los métodos tradicionales basados en funciones diseñadas manualmente, el aprendizaje profundo puede aprender automáticamente representaciones de funciones más ricas y abstractas, mejorando así la precisión de la detección y el reconocimiento de rostros.
- Robustez: el modelo de aprendizaje profundo tiene una gran robustez ante los cambios de iluminación, expresión, postura, etc. La red de aprendizaje profundo puede extraer rasgos faciales que son invariantes a estos cambios mediante operaciones de agrupación y transformación no lineal de varios niveles. Esto permite el aprendizaje profundo para lograr una detección y reconocimiento faciales precisos en diversos entornos complejos.
- Escalabilidad: los modelos de aprendizaje profundo pueden mejorar el rendimiento al aumentar la profundidad y el ancho de la red. Con el aumento de los recursos informáticos, se pueden construir redes de aprendizaje profundo más profundas y complejas para mejorar aún más la capacidad de detección y reconocimiento de rostros. Además, el aprendizaje profundo también admite tecnologías como el entrenamiento distribuido y la compresión de modelos, que pueden entrenarse e inferirse en un entorno informático eficiente y de datos a gran escala, y tiene buena escalabilidad.
- Aprendizaje multitarea: el modelo de aprendizaje profundo puede aprender simultáneamente múltiples tareas, como detección de rostros, posicionamiento de puntos clave de rostros y análisis de atributos de rostros. Al introducir señales de supervisión de múltiples tareas en la misma estructura de red, las representaciones de características se pueden compartir de manera efectiva, mejorando la capacidad de generalización y la eficiencia de aprendizaje del modelo. Este método de aprendizaje multitarea hace que el aprendizaje profundo sea más completo y eficiente en la detección y el reconocimiento de rostros.
El aprendizaje profundo tiene las ventajas de alta precisión, solidez, escalabilidad y aprendizaje multitarea en la detección y el reconocimiento de rostros. Estas ventajas hacen que el aprendizaje profundo sea el medio técnico más común y efectivo en el campo facial actual, y han logrado resultados de aplicación notables en reconocimiento facial, búsqueda facial, autenticación facial y otros escenarios.
La diferencia entre verificación facial y reconocimiento facial
La verificación facial y el reconocimiento facial son dos aplicaciones de tecnología facial diferentes y sus diferencias se reflejan principalmente en los siguientes aspectos:
- Definición: La verificación facial consiste en comparar la imagen facial ingresada con imágenes faciales conocidas para determinar si pertenecen a la misma persona. El reconocimiento facial consiste en comparar la imagen del rostro ingresada con múltiples rostros en una base de datos de rostros, encontrar el rostro más similar y juzgar su identidad.
- Escenarios de aplicación: la verificación facial se usa generalmente en escenarios donde es necesario confirmar la identidad de una persona, como desbloquear un teléfono móvil, pago electrónico, etc. Solo necesita verificar si la cara ingresada coincide. El reconocimiento facial es adecuado para escenarios en los que es necesario identificar o buscar a varias personas, como asistencia facial, sistemas de control de acceso, etc., y las identidades correspondientes deben identificarse en múltiples bases de datos.
- Escala de la base de datos: la verificación de rostros generalmente solo necesita hacer coincidir la cara de entrada con algunas (generalmente una) caras conocidas, y el tamaño de la base de datos requerido es pequeño. Y el reconocimiento facial necesita comparar una base de datos faciales a gran escala, que puede contener información facial de decenas de miles de personas.
- Requisitos de precisión y seguridad: dado que la verificación facial solo necesita juzgar si la cara de entrada coincide con una cara conocida, los requisitos de precisión y seguridad son relativamente bajos. El reconocimiento facial, por otro lado, debe buscarse y compararse en una base de datos a gran escala, lo que requiere mayor precisión y seguridad.
Código de referencia de reconocimiento facial basado en Python
Para implementar el reconocimiento facial basado en Python, puede usar las dos bibliotecas OpenCV y dlib para la detección de rostros y la extracción de características, y luego usar algoritmos de aprendizaje automático (como máquinas de vectores de soporte) para clasificar las características faciales.
import cv2
import dlib
# 加载人脸检测器和特征提取器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat') # 需要下载预训练模型
# 加载人脸识别模型
face_recognition_model = dlib.face_recognition_model_v1('dlib_face_recognition_resnet_model_v1.dat') # 需要下载预训练模型
# 加载已知人脸数据库
known_faces = [] # 存储已知人脸的特征向量
known_names = [] # 存储已知人脸的名称
def train_face_recognition():
# 读取已知人脸图像,进行特征提取
for image_path in known_images:
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
rects = detector(gray, 0)
if len(rects) == 1:
shape = predictor(gray, rects[0])
face_descriptor = face_recognition_model.compute_face_descriptor(gray, shape)
known_faces.append(face_descriptor)
known_names.append("known_name") # 替换为已知人脸的名称
def recognize_faces(image_path):
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
rects = detector(gray, 0)
for rect in rects:
shape = predictor(gray, rect)
face_descriptor = face_recognition_model.compute_face_descriptor(gray, shape)
# 比对人脸特征向量
distances = []
for known_face in known_faces:
distance = np.linalg.norm(np.array(face_descriptor) - np.array(known_face))
distances.append(distance)
min_distance = min(distances)
min_distance_index = distances.index(min_distance)
# 判断识别结果是否满足阈值
if min_distance < threshold:
recognized_name = known_names[min_distance_index]
cv2.rectangle(img, (rect.left(), rect.top()), (rect.right(), rect.bottom()), (0, 255, 0), 2)
cv2.putText(img, recognized_name, (rect.left(), rect.top() - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('Face Recognition', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
El código de muestra anterior necesita utilizar la biblioteca dlib y los modelos de preentrenamiento relacionados. Puede instalar la biblioteca dlib a través de pip y luego descargar los dos modelos de preentrenamiento shape_predictor_68_face_landmarks.dat y dlib_face_recognition_resnet_model_v1.dat del sitio web oficial de dlib.