Optimización de la descarga de computación para la informática perimetral móvil asistida por UAV: un enfoque de gradiente de política determinista profundo
Documentos de referencia:
[1] Wang Y , Fang W , Ding Y , et al. Optimización de descarga de computación para computación de borde móvil asistida por UAV: un enfoque de gradiente de política determinista profundo [J] Redes inalámbricas, 2021: 1-16.doi: https://doi.org/10.1007/s11276-021-02632-zCode
:
fangvv/UAV-DDPG
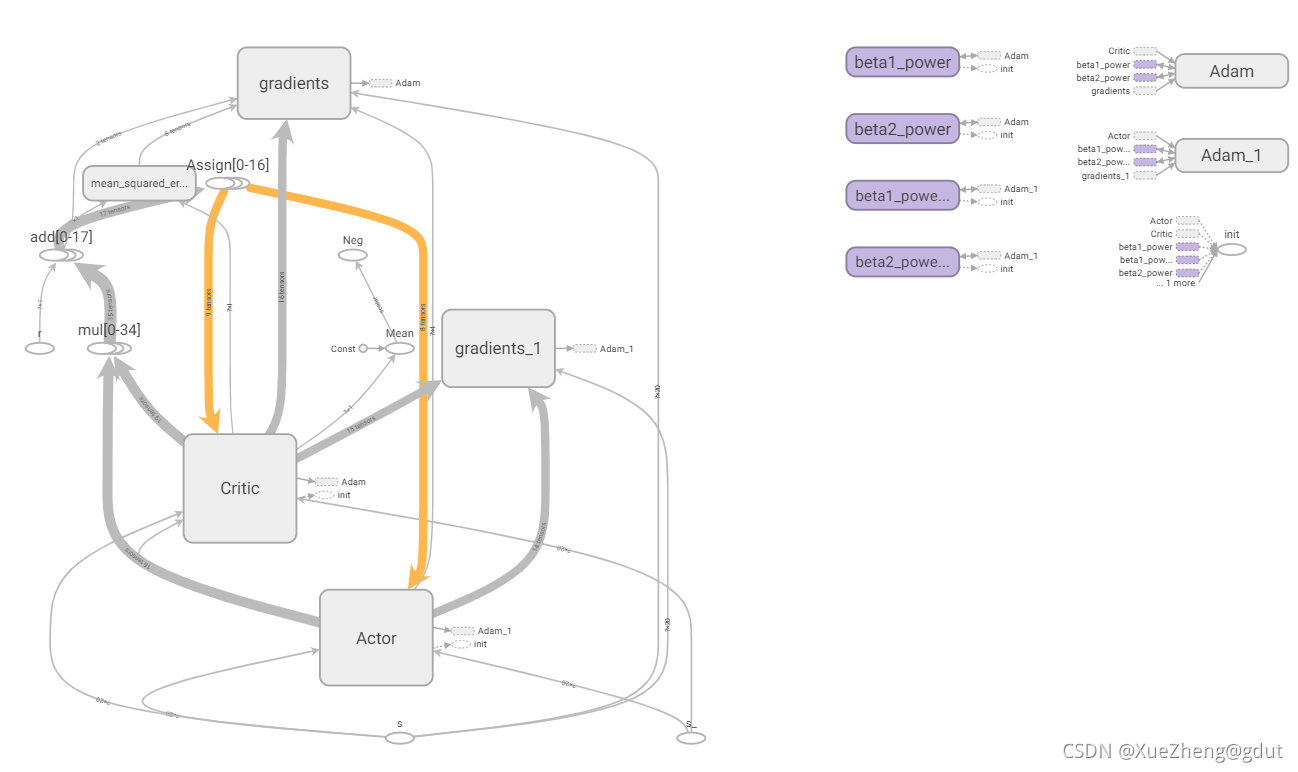
Combinando documentos y códigos fuente abiertos para explicar el algoritmo DDPG en detalle, aquí está el código para funcionar bien (el código aquí también es cambiado de acuerdo con Internet, el algoritmo DDPG ya está arreglado, y la innovación solo se puede hacer en términos de modelado. La clase de entorno debe ser escrita por usted mismo, y el algoritmo DDPG se puede aplicar directamente). Use tensorboard para exportar el tensor gráfico de flujo Esta es una muy buena herramienta de visualización que ayuda a aclarar el código, el diagrama de tensorboard del código es el siguiente, y lo siguiente se explicará en detalle en función de este diagrama. (Requiere conocimientos teóricos de aprendizaje por refuerzo y una cierta comprensión de tensorflow y python. El blog anterior tiene una ruta de aprendizaje del sistema de aprendizaje por refuerzo gratuito. Será más amigable leer este blog después de aprender)
contribuir
Teniendo en cuenta el estado del canal variable en el tiempo en el sistema MEC asistido por UAV de intervalo de tiempo, optimice conjuntamente la programación del usuario, el movimiento del UAV y la asignación de recursos, formule el problema de descarga de computación no convexa como un problema de proceso de decisión de Markov (MDP) y minimice el retardo de tiempo inicial.
Teniendo en cuenta el modelo MDP, la complejidad del estado del sistema es muy alta y la toma de decisiones de descarga computacional debe admitir un espacio de acción continuo. El algoritmo DDPG se usa para resolver este problema, la red Actor se usa para realizar acciones y la red Critic se utiliza para aproximar la función de valor de acción Q para puntuar acciones y la mejor estrategia óptima.
Marco DDPG

Código detallado
Defina la clase DDPG, inicialícela y la sesión es una declaración para que Tensorflow controle y ejecute el archivo de salida. Ejecute session.run() para obtener el resultado del cálculo que desea saber o la parte que desea calcular. use session.run later () para inicializar la variable. placeholder es un marcador de posición en Tensorflow. Almacena variables temporalmente. Puede entenderse como un caparazón vacío, y el valor se pasa para el cálculo. Si no se pasa, el caparazón vacío no realiza ningún cálculo.
def __init__(self, a_dim, s_dim, a_bound):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32) # memory里存放当前和下一个state,动作和奖励
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's') # 输入
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
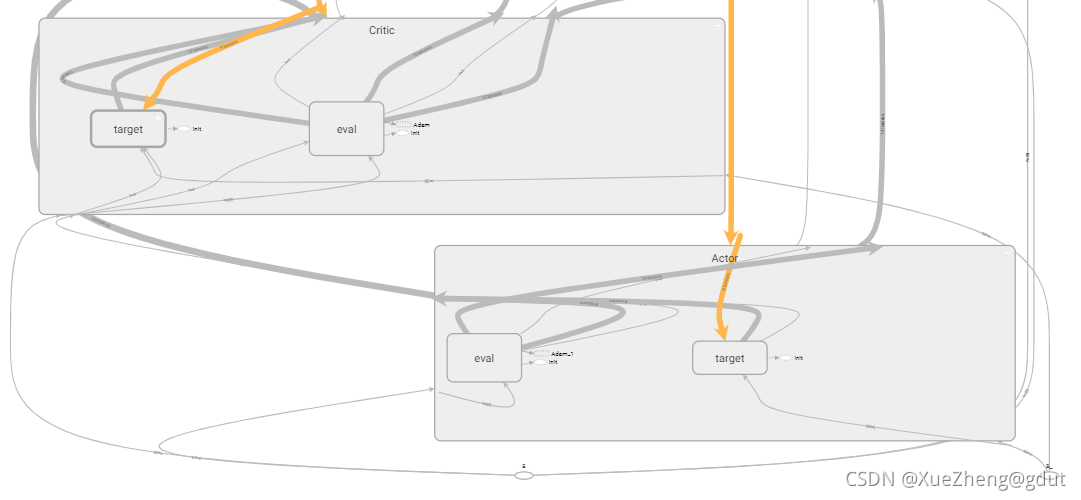
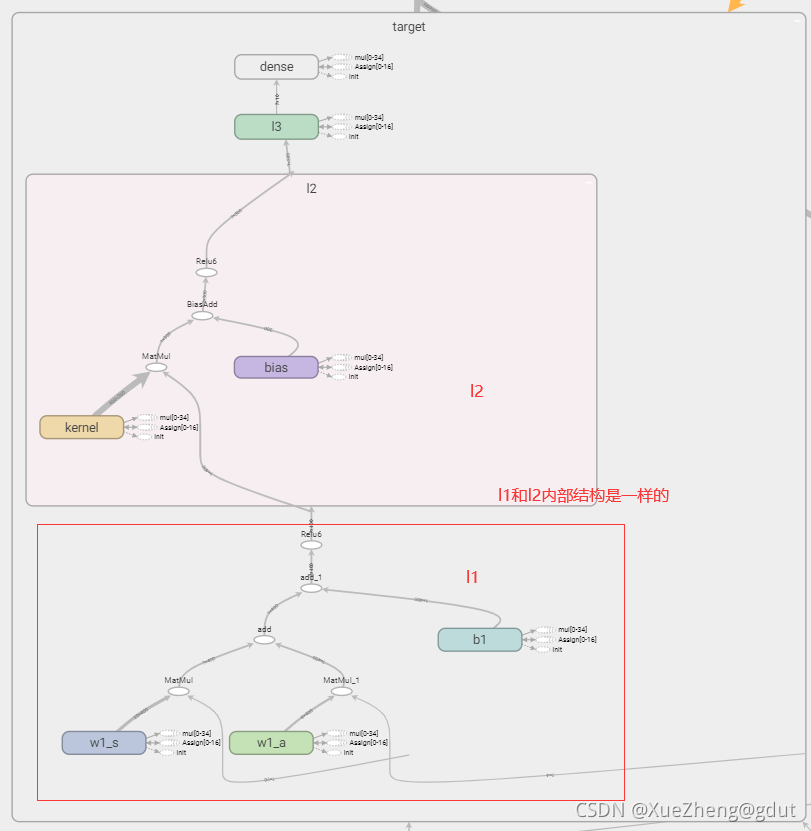
tf.variable_scope Comprensión personal, principalmente para compartir variables, diferentes nombres pueden compartir la misma variable, DDPG tiene un total de cuatro redes neuronales, la estructura de las dos redes neuronales en Actor es la misma y las dos redes neuronales en Critic La estructura de la red neuronal es el mismo, pero los parámetros son diferentes.Después de escribir la estructura de una red neuronal, estas variables se pueden compartir nombrándolas de manera diferente. Como se puede ver en el siguiente código, Actor tiene dos redes, una es la red principal eval y la otra es el objetivo de la red objetivo, la red eval genera directamente la acción a y la red objetivo genera la acción a_, ambas son construido usando la función _build_a, y se nombran de manera diferente Implementar el uso compartido de variables. Lo mismo es cierto para la red Critic, que son las redes eval y target respectivamente, y la salida es dos valores Q, q, q_. Desde el tensorboard, puede ver que hay dos redes debajo del actor y critic. Echemos un vistazo más de cerca a cómo construir una red de actores y una red de críticos. trainable=True o False se usa principalmente para especificar si se agregan las variables en la red neuronal al atlas de tensorboard.
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
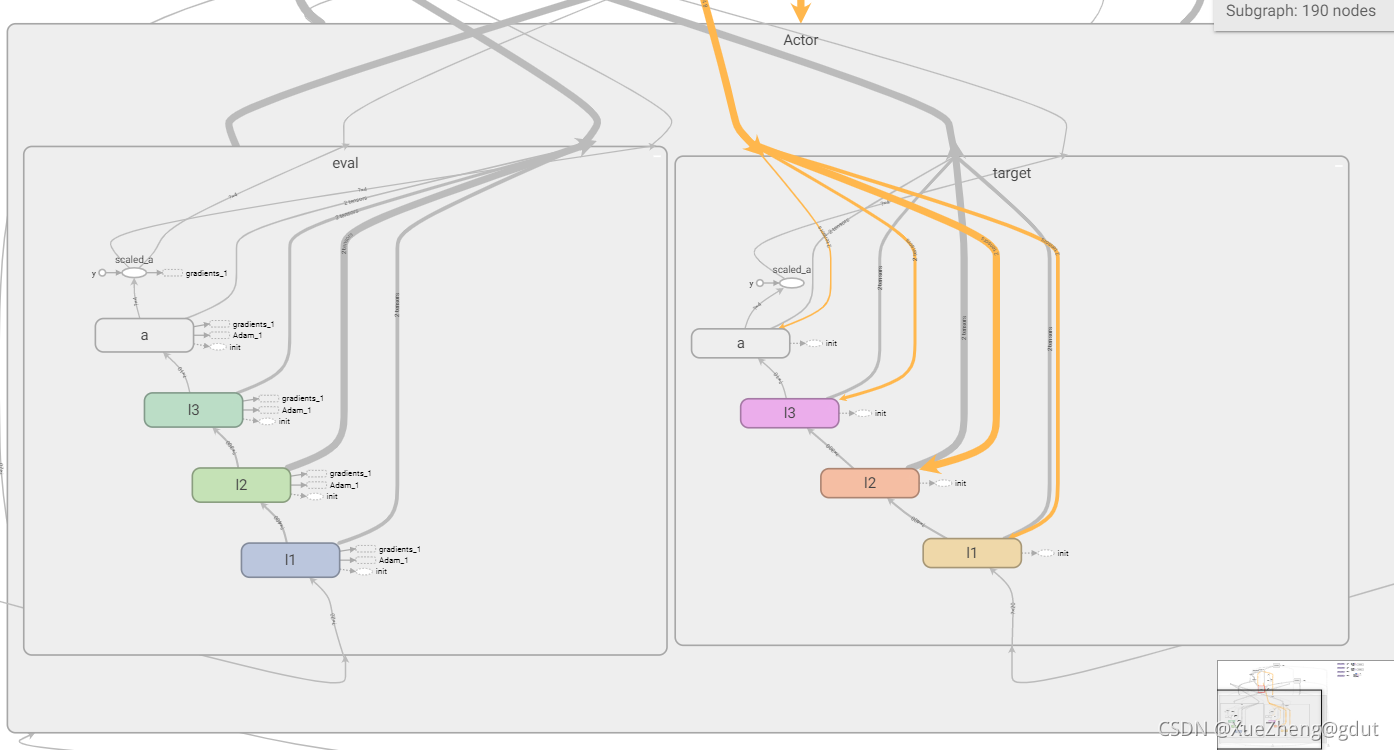
Actor
Después de que la red de actores ingresa principalmente el estado s, genera directamente la acción a. tf.layers.dense( input, units=k ) generará automáticamente un kernel de matriz de peso y compensará internamente el sesgo del elemento. Las dimensiones específicas de cada variable son las siguientes: Para una entrada de tensor bidimensional con un tamaño de [m, n ], tf.layers.dense() generará: un kernel de matriz de peso de tamaño [n, k] y un sesgo de elemento compensado de tamaño [m, k]. El proceso de cálculo interno es y = entrada * núcleo + sesgo, y la dimensión del valor de salida y es [m, k].
Usando la función de capa totalmente conectada encapsulada por tensorflow, el estado de entrada, la primera capa de neuronas 400 (llamada l1), la segunda capa 300 (llamada l2), la tercera capa 10 (llamada l3), la capa de salida 4 (a_dim= 4 llamado a ). Se construyen dos redes con la misma estructura del actor, y el tensorboard se muestra en la figura.
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 400, activation=tf.nn.relu6, name='l1', trainable=trainable)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound[1], name='scaled_a')
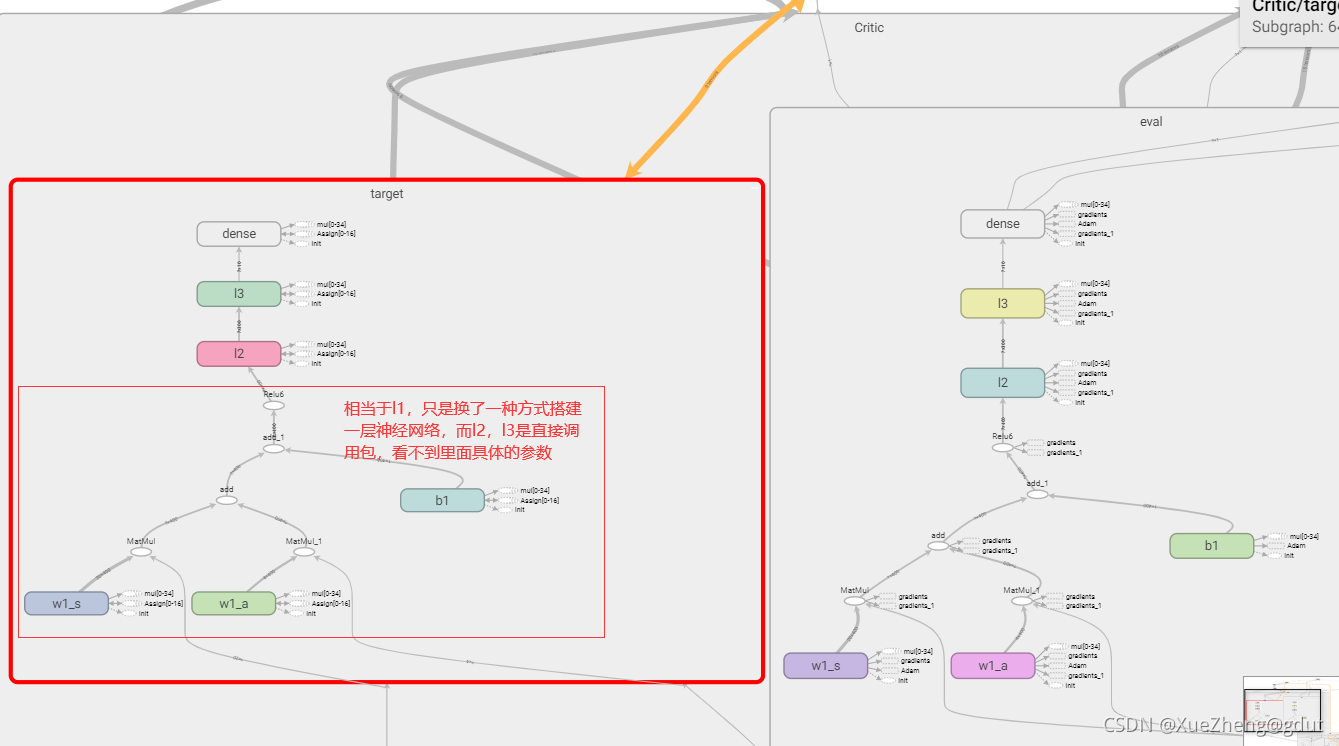
Crítico
La siguiente es la red Critic, que puntúa la acción a y genera el valor Q. Esto es un poco diferente del método anterior para construir una red neuronal, porque la función Q necesita ingresar el estado s y la acción a, por lo que s corresponde a un peso, a corresponde a un peso, y hay un sesgo como un todo, y luego pasar a través de una función de activación es equivalente a Una capa de red neuronal, w1_s, w1_a y b1 son los parámetros de la red neuronal, que deben guardarse y actualizarse, por lo que se configuran como entrenables, de modo que la entrada a la primera capa de neuronas es 400 y la segunda capa es 300 (llamada l2), la tercera capa es 10 (llamada l3) y la salida es la puntuación de la acción, escalar. El principio de la red neuronal, a través de la función de activación (función no lineal) después de la suma lineal. Se construyen las dos redes de Critic con la misma estructura y el tensorboard se muestra en la figura.
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 400
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)

Hasta ahora, se han construido las cuatro estructuras de redes neuronales.
Los parámetros importantes de la red neuronal son el peso y el sesgo de cada capa. No construimos la red neuronal de una manera muy primitiva, sino que llamamos directamente a tf.layers.dense para construirla. Los parámetros específicos de cada capa no están claros. , pero tensorflow proporciona un muy El conveniente tf.get_collection extrae todas las variables de una colección. Es una lista. Hay cuatro redes en total. De esta manera, todos los parámetros de las cuatro redes se pueden extraer para actualizar.
# networks parameters
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
Grupo de repeticiones de experiencia
Dado que la entrada de la red neuronal a menudo no se ingresa una por una, sino en forma de pequeños lotes, es necesario recopilar una cierta cantidad de experiencia y colocarla en el grupo de reproducción de experiencia. red, y el entrenamiento llega a un cierto número de veces. Detener el entrenamiento. Llame a s, a, r, s_ una pieza de experiencia y guárdela en el grupo de experiencia hasta alcanzar la capacidad máxima.
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
# transition = np.hstack((s, [a], [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
Actualización de parámetros de red neuronal
Las dos redes principales Actor_eval y Critic_eval en Actor y Critic se actualizan a través de TError y gradiente de política respectivamente.

Calcule TError para actualizar los parámetros de red de Critic_eval, y los parámetros de red de Actor_eval se derivan de los parámetros de actor_eval a través de la función Q. Aquí, Q en realidad deriva a y luego deriva mu. {\theta^Q}
es el ce_params aquí, y {\theta^\mu} es el ae_params. q_objetivo corresponde a y_i.
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
Hay un total de cuatro redes neuronales. Los parámetros de la red principal se actualizan a partir de lo anterior, y las dos redes de destino también deben actualizarse. Se adopta el método de actualización suave (promedio móvil), y cada actualización es un poco bit. ¿Por qué usar dos redes neuronales en Actor y Critic respectivamente? Una red neuronal es principalmente para evitar el problema de la sobreestimación, por lo que los parámetros deben configurarse de manera diferente. El método de actualización dura es retrasar los parámetros de la red principal y copiarlos a la red de destino, mientras que la actualización suave equivale a actualizar un poco cada vez. Su fórmula y código correspondiente son los siguientes.
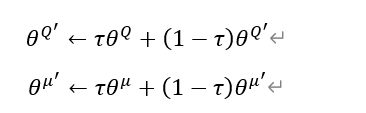
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
¿La fórmula aquí puede actualizar los parámetros de las dos redes de destino a la vez? ¿Por qué aquí self.at_params + self.ct_params aquí es +? Para ser honesto, no lo entiendo muy bien, ¿para que se puedan actualizar tanto at_params como ct_params? Alguien que sepa puede explicar en detalle? Pero después de buscar esto, parece que esta es la forma correcta de escribir. Este también es un código molesto para usar directamente.
guardar experiencia
En este punto, el marco completo de DDPG está básicamente construido, y el resto es para almacenar datos en el grupo de experiencia. Una vez que el almacenamiento está lleno, puede comenzar a entrenar la red neuronal construida. Acceda a la experiencia (s, a, r, s_), seleccione aleatoriamente un estado s, en este momento necesita generar una acción a través de la red neuronal, por lo que se establece la función elegir_acción, aquí se llama a la red neuronal para generar la acción a, esta acción suele estar representada por el ruido Explorar, y luego el entorno recompensa r de acuerdo con la acción a y actualiza el siguiente estado s_, de modo que se obtiene una experiencia. Al guardar, juzgará si el almacenamiento está lleno o si tiene ciertos requisitos para las acciones de salida, etc., consulte el código a continuación. En este momento, la red neuronal no se puede entrenar.
def choose_action(self, s):
temp = self.sess.run(self.a, {
self.S: s[np.newaxis, :]})
return temp[0]
# Add exploration noise
a = ddpg.choose_action(s_normal.state_normal(s))
a = np.clip(np.random.normal(a, var), *a_bound) # 高斯噪声add randomness to action selection for exploration
s_, r, is_terminal, step_redo, offloading_ratio_change, reset_dist = env.step(a)
if step_redo:
continue
if reset_dist:
a[2] = -1
if offloading_ratio_change:
a[3] = -1
ddpg.store_transition(s_normal.state_normal(s), a, r, s_normal.state_normal(s_)) # 训练奖励缩小10倍
tren
Después de juzgar que el grupo de experiencia está lleno, comience a entrenar la red neuronal y actualice los parámetros. Aquí, puede llamar directamente a la función de aprendizaje para iniciar el proceso de entrenamiento y actualizar los parámetros.
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
Después de construir el gráfico de flujo, use sess.run para ejecutar, primero realice una actualización suave (actualización de parámetros de red de destino), extraiga aleatoriamente la experiencia BATCH_SIZE del grupo de experiencias y use sess.run para actualizar los parámetros de red principales (atrain, ctrain) .
def learn(self):
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {
self.S: bs})
self.sess.run(self.ctrain, {
self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
El código de la clase DDPG se explica aquí y el código de la clase DDPG se publica aquí.
############################### DDPG ####################################
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32) # memory里存放当前和下一个state,动作和奖励
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's') # 输入
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
self.sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", self.sess.graph)
def choose_action(self, s):
temp = self.sess.run(self.a, {
self.S: s[np.newaxis, :]})
return temp[0]
def learn(self):
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {
self.S: bs})
self.sess.run(self.ctrain, {
self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
# transition = np.hstack((s, [a], [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 400, activation=tf.nn.relu6, name='l1', trainable=trainable)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound[1], name='scaled_a')
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 400
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
Excepto por las siguientes oraciones, inicialice todas las variables y genere el gráfico de tensorboard.
self.sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", self.sess.graph)
Código de entrenamiento:
############################### training ####################################
np.random.seed(1)
tf.set_random_seed(1)
env = UAVEnv()
MAX_EP_STEPS = env.slot_num
s_dim = env.state_dim
a_dim = env.action_dim
a_bound = env.action_bound # [-1,1]
ddpg = DDPG(a_dim, s_dim, a_bound)
# var = 1 # control exploration
var = 0.01 # control exploration
t1 = time.time()
ep_reward_list = []
s_normal = StateNormalization()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
j = 0
while j < MAX_EP_STEPS:
# Add exploration noise
a = ddpg.choose_action(s_normal.state_normal(s))
a = np.clip(np.random.normal(a, var), *a_bound) # 高斯噪声add randomness to action selection for exploration
s_, r, is_terminal, step_redo, offloading_ratio_change, reset_dist = env.step(a)
if step_redo:
continue
if reset_dist:
a[2] = -1
if offloading_ratio_change:
a[3] = -1
ddpg.store_transition(s_normal.state_normal(s), a, r, s_normal.state_normal(s_)) # 训练奖励缩小10倍
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if j == MAX_EP_STEPS - 1 or is_terminal:
print('Episode:', i, ' Steps: %2d' % j, ' Reward: %7.2f' % ep_reward, 'Explore: %.3f' % var)
ep_reward_list = np.append(ep_reward_list, ep_reward)
# file_name = 'output_ddpg_' + str(self.bandwidth_nums) + 'MHz.txt'
file_name = 'output.txt'
with open(file_name, 'a') as file_obj:
file_obj.write("\n======== This episode is done ========") # 本episode结束
break
j = j + 1
# # Evaluate episode
# if (i + 1) % 50 == 0:
# eval_policy(ddpg, env)
print('Running time: ', time.time() - t1)
plt.plot(ep_reward_list)
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.show()