El propósito de este artículo es explicar Flash Attention en detalle. ¿Por qué explicar Flash Attention? Dado que FlashAttention es un algoritmo para reordenar el cálculo de la atención, puede acelerar el cálculo de la atención y reducir el uso de memoria sin ninguna aproximación. Por lo tanto, es una muy buena solución para acelerar el modelo LLM actual. Este artículo presenta la versión clásica V1 y la última V2 tiene otras optimizaciones que no presentaremos aquí por el momento. Debido a que se afirma que la versión V1 de FlashAttention es de 5 a 10 veces más rápida, estudiemos cómo se implementa.
introducir
El título del artículo es:
“FlashAttention: Atención exacta rápida y eficiente en memoria con IO-Awareness”
Eficiencia de la memoria En comparación con la atención normal (la longitud de la secuencia es cuadrática, O(N²)), FlashAttention es subcuadrática/lineal N (O(N)). Y no es una aproximación de los mecanismos de atención (por ejemplo, métodos de aproximación matricial dispersa o de rango bajo): su resultado es el mismo que el de los mecanismos de atención "tradicionales". En comparación con la atención ordinaria, la atención de FlashAttention se "percibe".
Aprovecha el conocimiento de la jerarquía de memoria del hardware subyacente (por ejemplo, GPU, pero otros aceleradores de IA también deberían funcionar; estoy usando GPU aquí como ejemplo). Algunos métodos [aproximados] reducen los requisitos computacionales a una longitud de secuencia lineal o casi lineal, pero muchos de ellos se centran en reducir los FLOP ignorando la sobrecarga del acceso a la memoria (IO).
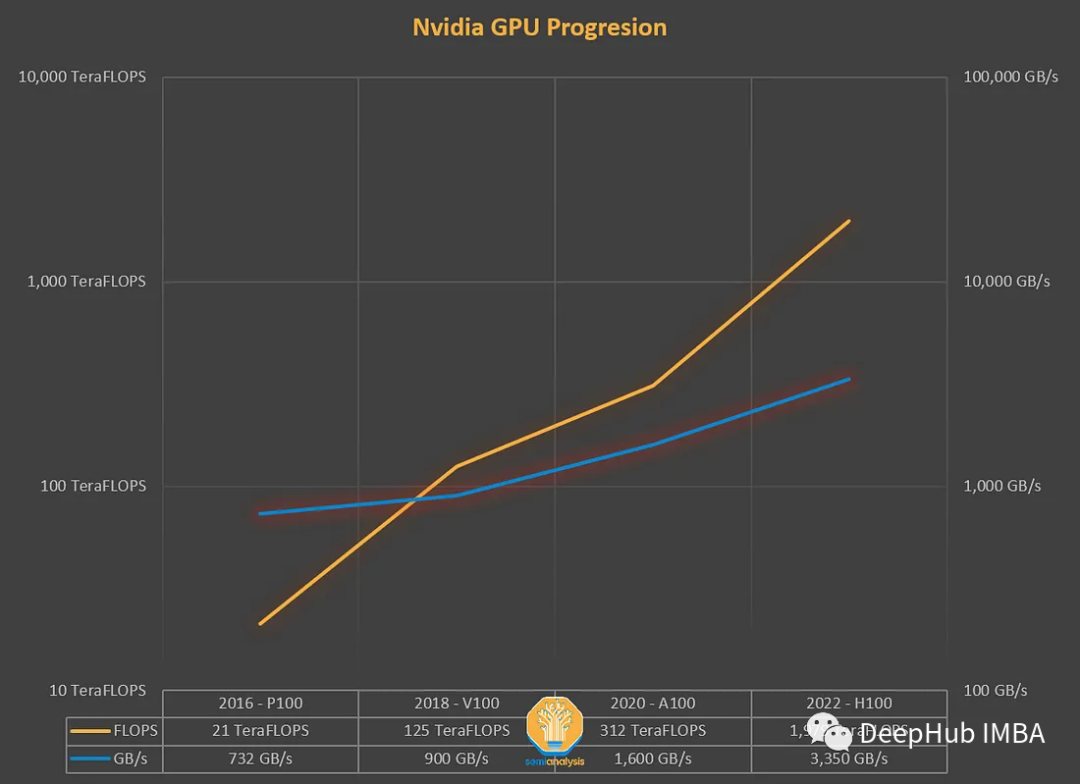
Después de años de desarrollo, los FLOPS de las GPU han crecido más rápido que el rendimiento de la memoria (TB/s). Los cuellos de botella de la memoria deben tomarse en serio. Los FLOPS y el rendimiento de la memoria deben combinarse estrechamente. Debido a la brecha en el hardware, debemos equilibrar el trabajo a nivel de software.
Dependiendo de la relación entre computación y acceso a la memoria, las operaciones se pueden clasificar en los dos tipos siguientes:
- Restricciones computacionales: multiplicación de matrices
- Restricciones de memoria: operaciones de elementos (activación, eliminación, enmascaramiento), operaciones de fusión (softmax, norma de capa, suma, etc.)
En el acelerador de IA (GPU) actual, está limitado por el tamaño de la memoria. Porque "consiste principalmente en operaciones de elementos", o más precisamente, la densidad aritmética de atención no es muy alta.
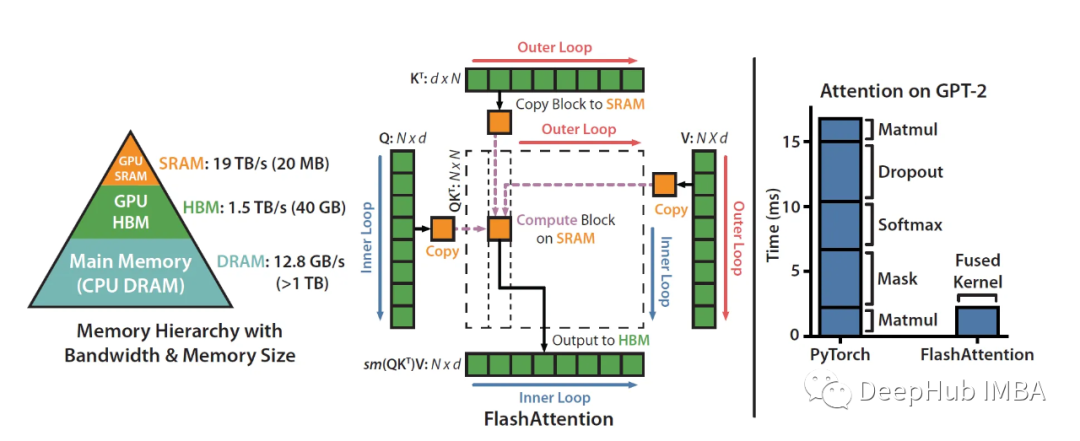
Veamos esta imagen:
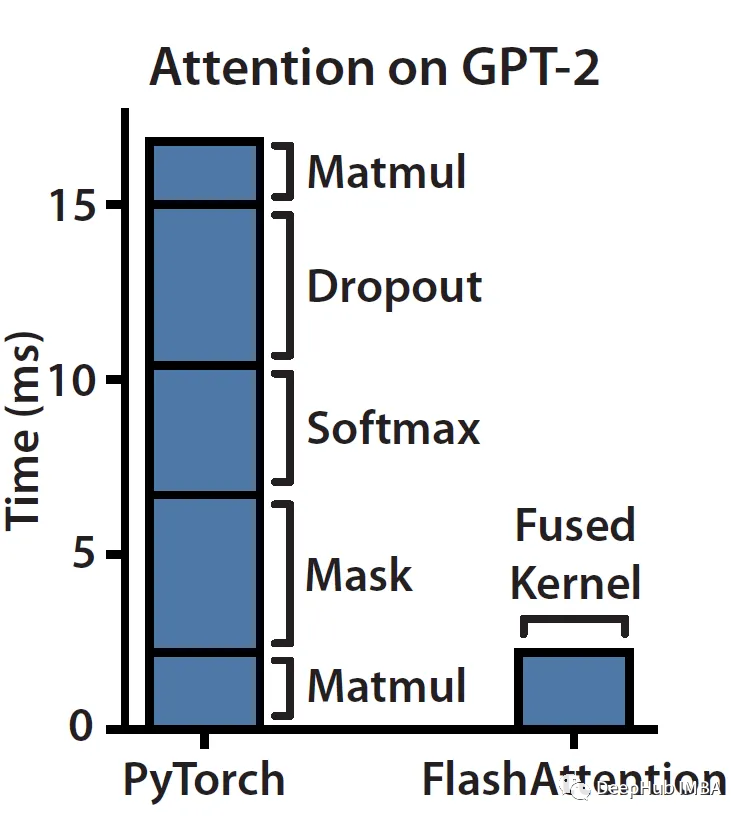
Como puede ver, el enmascaramiento, el softmax y el abandono son operaciones que consumen mucho tiempo, no la multiplicación de matrices (aunque la mayoría de los FLOPS están en matmul). La memoria no es un artefacto único, es de naturaleza jerárquica y la regla general es: cuanto más rápida es la memoria, más cara es y menor es su capacidad.
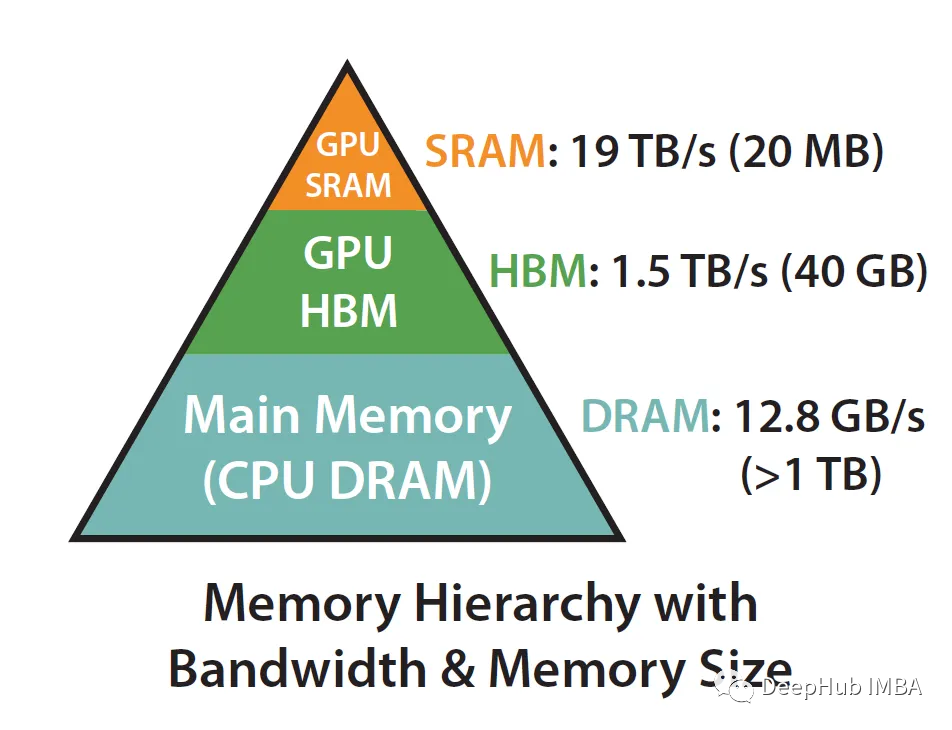
Lo que dijimos anteriormente de que la atención de FlashAttention es "consciente" se reduce a utilizar SRAM mucho más rápido que HBM (High Bandwidth Memory) para garantizar una menor comunicación entre los dos.
Tome A100 como ejemplo:
La GPU A100 tiene entre 40 y 80 GB de memoria de alto ancho de banda (HBM), con un ancho de banda de 1,5 a 2,0 TB/s, mientras que cada uno de los 108 procesadores de flujo tiene 192 KB de SRAM y el ancho de banda se estima en alrededor de 19 TB/s. .
Se puede ver que el tamaño es mucho más pequeño, pero la velocidad aumenta 10 veces, por lo que cómo usar SRAM de manera eficiente es la clave para acelerar. Veamos el cálculo detrás de la implementación de la atención estándar:

La implementación del estándar muestra poco respeto por el funcionamiento del HW. Básicamente trata las operaciones de carga/almacenamiento de HBM como costo 0 (no es "consciente de io").
Primero consideramos cómo hacer que esta implementación sea más eficiente (en términos de tiempo y memoria). La forma más sencilla es eliminar las lecturas/escrituras redundantes de HBM.
¿Qué tal escribir S nuevamente en HBM solo para (re)cargarlo para calcular softmax? Luego podemos mantenerlo en SRAM, realizar todos los pasos intermedios y luego escribir el resultado final nuevamente en HBM.
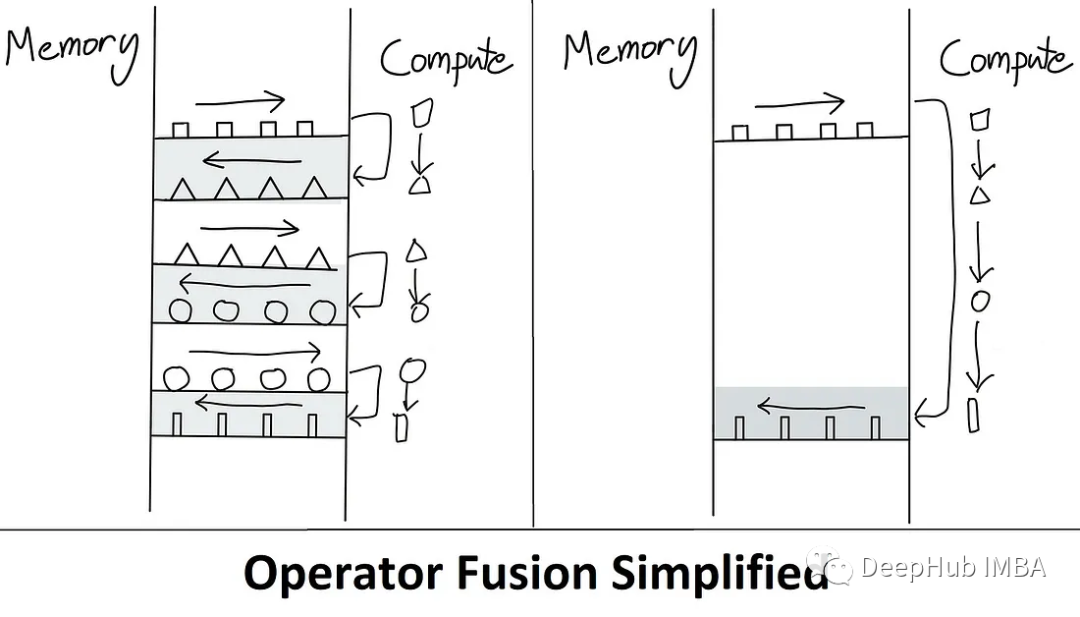
Un kernel es básicamente una forma elegante de decir "operaciones de GPU" (consulte nuestra publicación anterior sobre Introducción a CUDA, que es simplemente una función). Fusion permite fusionar múltiples operaciones. Así que solo cargue una vez desde HBM, ejecute la operación fusionada y escriba el resultado. Hacerlo reduce los gastos generales de comunicación.
También hay un término técnico aquí que es "materialización" (materialización / materialización). Se refiere al hecho de que, en la implementación de atención estándar anterior, se ha asignado la matriz NxN completa (S, P). A continuación veremos cómo reducir directamente la complejidad de la memoria de O (N²) a O (N).
La atención inmediata se reduce básicamente a dos puntos principales:
Mosaico (usado durante el pase hacia adelante y hacia atrás): básicamente, mosaico de la matriz NxN softmax/scores en trozos.
Recálculo (solo usado en el pase hacia atrás)
El algoritmo es como sigue:

Mencionamos muchos sustantivos arriba, que quizás aún no comprendas. No importa, comencemos a explicar el algoritmo línea por línea.
Algoritmo de atención flash
El principal obstáculo para el método Tiling es softmax. Porque softmax necesita acoplar todas las columnas de puntuación.
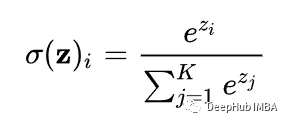
¿Ves el denominador? Ese es el problema.
Calcular cuánta atención tiene un i-ésimo token particular en la secuencia de entrada a otros tokens en la secuencia requiere que todas estas puntuaciones (indicadas aquí por z_j) estén disponibles en SRAM.
Pero la capacidad de SRAM es limitada. N (longitud de la secuencia) puede ser 1000 o incluso 100000 tokens. Entonces el N² explota muy rápidamente. Entonces, el artículo usa un truco: divide el cálculo de softmax en bloques más pequeños y aún así obtienes exactamente el mismo resultado al final.
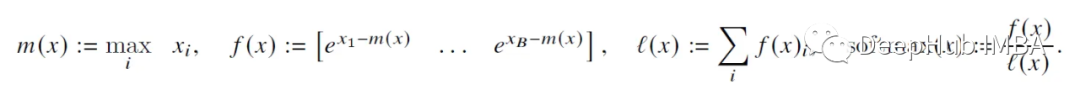
Podemos simplemente tomar las puntuaciones B anteriores (x_1 a x_B) y calcular softmax para ellas. Luego, a través de iteraciones, "convergen" hacia el resultado correcto. Combinando estos números softmax por bloque de una manera inteligente, de modo que el resultado final sea realmente correcto. Métodos como se muestra a continuación:

Básicamente, para calcular el softmax de las puntuaciones pertenecientes a los primeros 2 bloques (de tamaño B), hay que realizar un seguimiento de 2 estadísticas para cada bloque: m(x) (puntuación máxima) y l(x) (suma de puntuaciones de experiencia). Luego se pueden combinar perfectamente utilizando coeficientes de normalización.
A continuación se muestran principalmente algunas operaciones algebraicas básicas. Al expandir los términos f(x) y l(x) y multiplicarlos por e^x, algunos términos se cancelarán entre sí, por lo que no los escribiré aquí. Esta lógica continúa recursivamente hasta el último bloque (N/B), lo que da como resultado una salida softmax N-dimensionalmente correcta.
Para detallar este algoritmo, supongamos un lote de tamaño 1 (es decir, una única secuencia) y un único cabezal de atención, que luego se ampliará (mediante una simple paralelización entre GPU; hablaremos de esto más adelante). Ignoramos el abandono y el enmascaramiento por ahora, porque los agregaremos más adelante.

Empezamos a calcular:
Inicialización: La capacidad de HBM se mide en GB (por ejemplo, RTX 3090 tiene 24 GB de VRAM/HBM, A100 tiene 40-80 GB, etc.), por lo que asignar Q, K y V no es un problema.
paso 1
Calcule el tamaño del bloque de fila/columna. ¿Por qué ceil(M / 4 d)? Debido a que los vectores de consulta, clave y valor son d-dimensionales, también debemos combinarlos en el vector d-dimensional de salida. Entonces, este tamaño básicamente nos permite maximizar la capacidad de SRAM con qkv y 0 vectores.
Por ejemplo, supongamos M = 1000, d = 5. Entonces el tamaño del bloque es (1000/4*5)=50. Por lo tanto, cargue 50 bloques de vectores q, k, v, o a la vez, lo que puede reducir la cantidad de lecturas/escrituras entre HBM/SRAM.
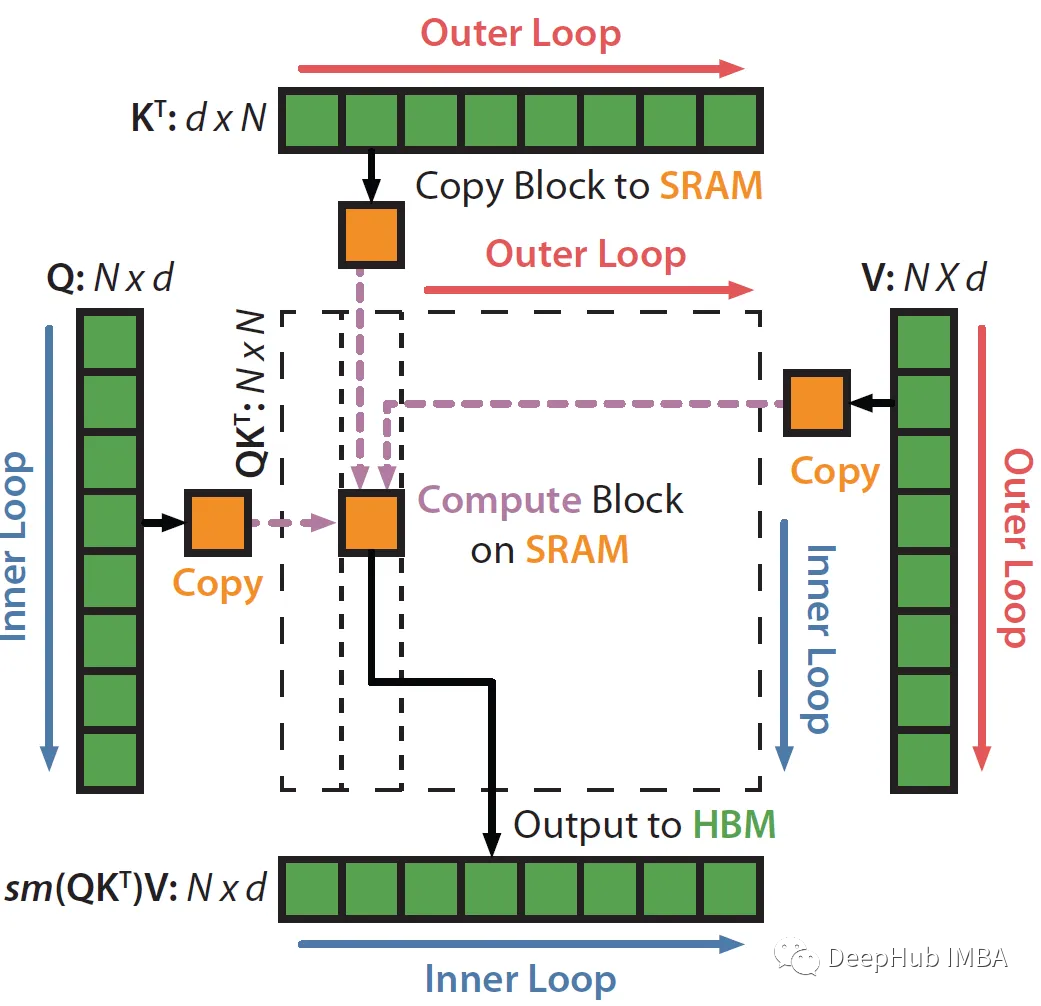
Para B_r, tampoco estoy muy seguro de por qué están usando d para realizar la operación mínima. Si alguien lo sabe, ¡comente y avise!
Paso 2:
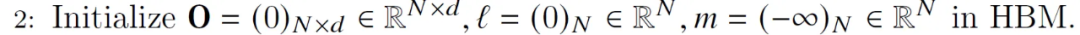
Inicialice la matriz de salida O con todos ceros. Actuará como un acumulador; de manera similar, su propósito es mantener el denominador acumulativo del softmax (la suma de las puntuaciones de exp). M (que contiene la puntuación máxima fila por fila) se inicializa en -inf porque le aplicaremos el operador Max, por lo que cualquiera que sea el máximo del primer bloque, definitivamente es mayor que -inf.
Paso 3:
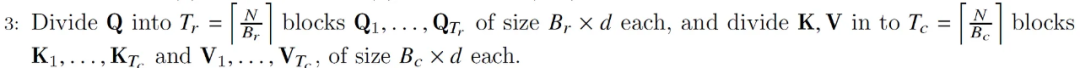
El tamaño del bloque en el paso 1 divide Q, K y V en bloques.
Etapa 4:

Divida O, l, m en bloques (mismo tamaño de bloque que Q).
Paso 5:
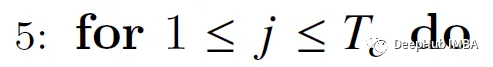
Comience a recorrer columnas, es decir, a través de vectores clave/valor (bucle externo en el diagrama anterior).
Paso 6:
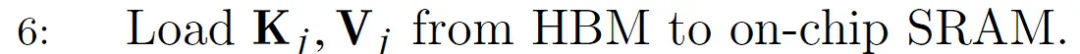
Cargue los bloques K_j y V_j de HBM a SRAM. En este momento todavía tenemos el 50% de SRAM libre (dedicada a Q y O). Entonces SRAM es así:

Paso 7:
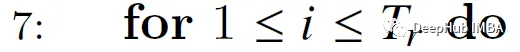
Inicie el bucle interno a través de filas, es decir, a través del vector de consulta.
Paso 8:

Cargue los bloques Q_i (B_r xd) y O_i (B_r xd) y l_i (B_r) y m_i (B_r) en la SRAM.
Aquí debe asegurarse de que l_i y m_i se puedan cargar en SRAM (incluidas todas las variables intermedias). Esto puede ser conocimiento de CUDA. No estoy seguro de cómo calcularlo, así que si tiene información relevante, deje un mensaje.
Paso 9:

Calcule el producto escalar entre Q_i (B_r xd) y la transpuesta K_j (dx B_c) para obtener la puntuación (B_r x B_c). no "materializa" toda la matriz nxns(puntuación).
Suponiendo que el índice del bucle externo es j (j = 3), el índice del bucle interno es i (i = 2), N es 25 y el tamaño del bloque es 5, el siguiente es el resultado recién calculado (asumiendo una indexación basada en 1) :

Es decir, las puntuaciones de atención para las fichas 6 a 10 de las fichas 11 a 15 en la secuencia de entrada. Un punto importante aquí es que estas son puntuaciones exactas, nunca cambian.
Paso 10:

Calcule m_i_j, l*i_j y P~*i_j utilizando las puntuaciones calculadas en el paso anterior. M ~_i_j se calcula fila por fila, encontrando el elemento más grande de cada fila anterior.
Entonces P~_i_j se obtiene aplicando operaciones elemento a elemento:
Normalizar: tome el máximo de fila y réstelo de la puntuación de la fila, luego EXP
l~_i_j es la suma fila por fila de la matriz P.
Paso 11:

Calcule m_new_i y l_new_i. También es muy sencillo reutilizar el diagrama anterior:
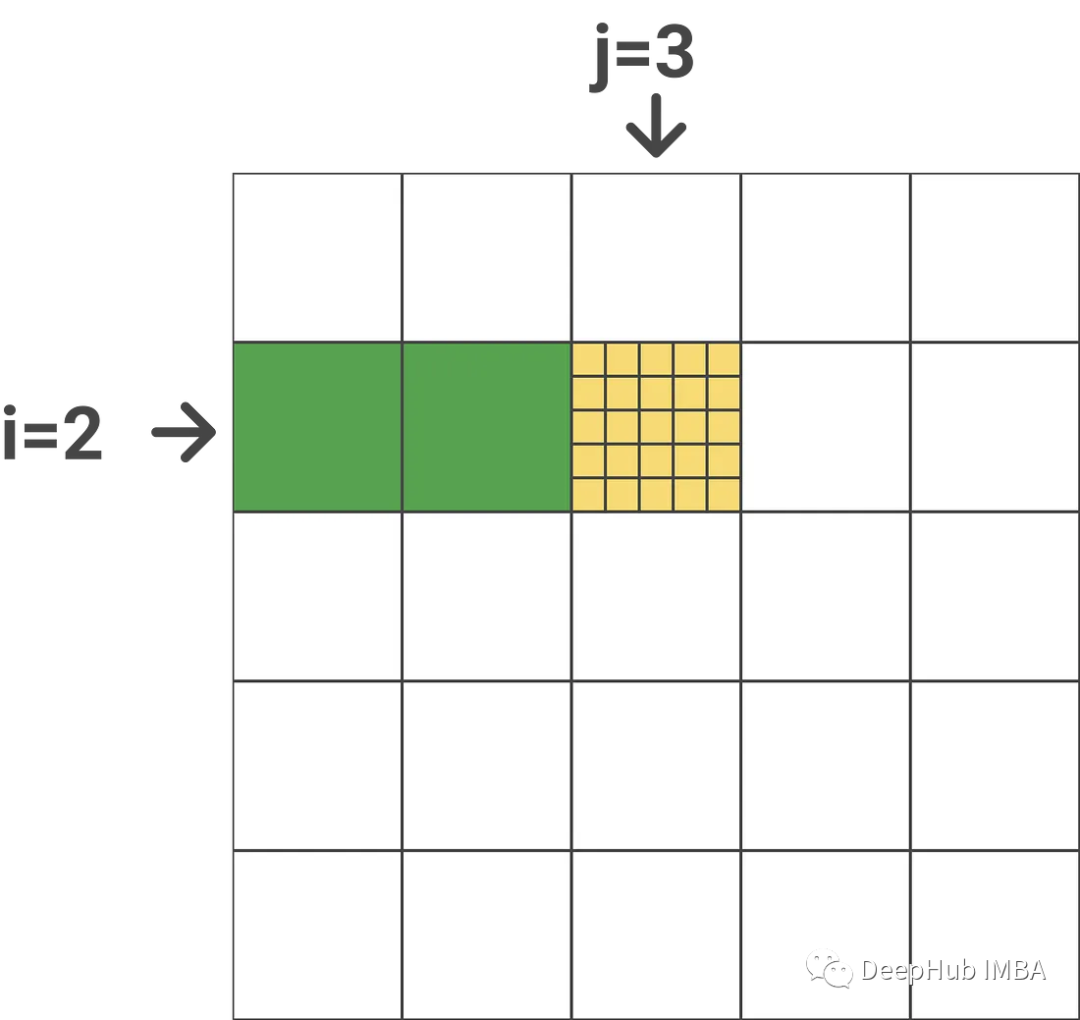
M_i contiene los máximos fila por fila de todos los bloques anteriores (j=1 y j=2, indicados en verde). M_i_j contiene el valor máximo fila por fila (indicado en amarillo) para el bloque actual. Para obtener m_new_i solo necesitamos tomar un valor máximo entre m_i_j y m_i, y l_new_i es similar.
Paso 12 (el más importante):

Esta es la parte más difícil del algoritmo.
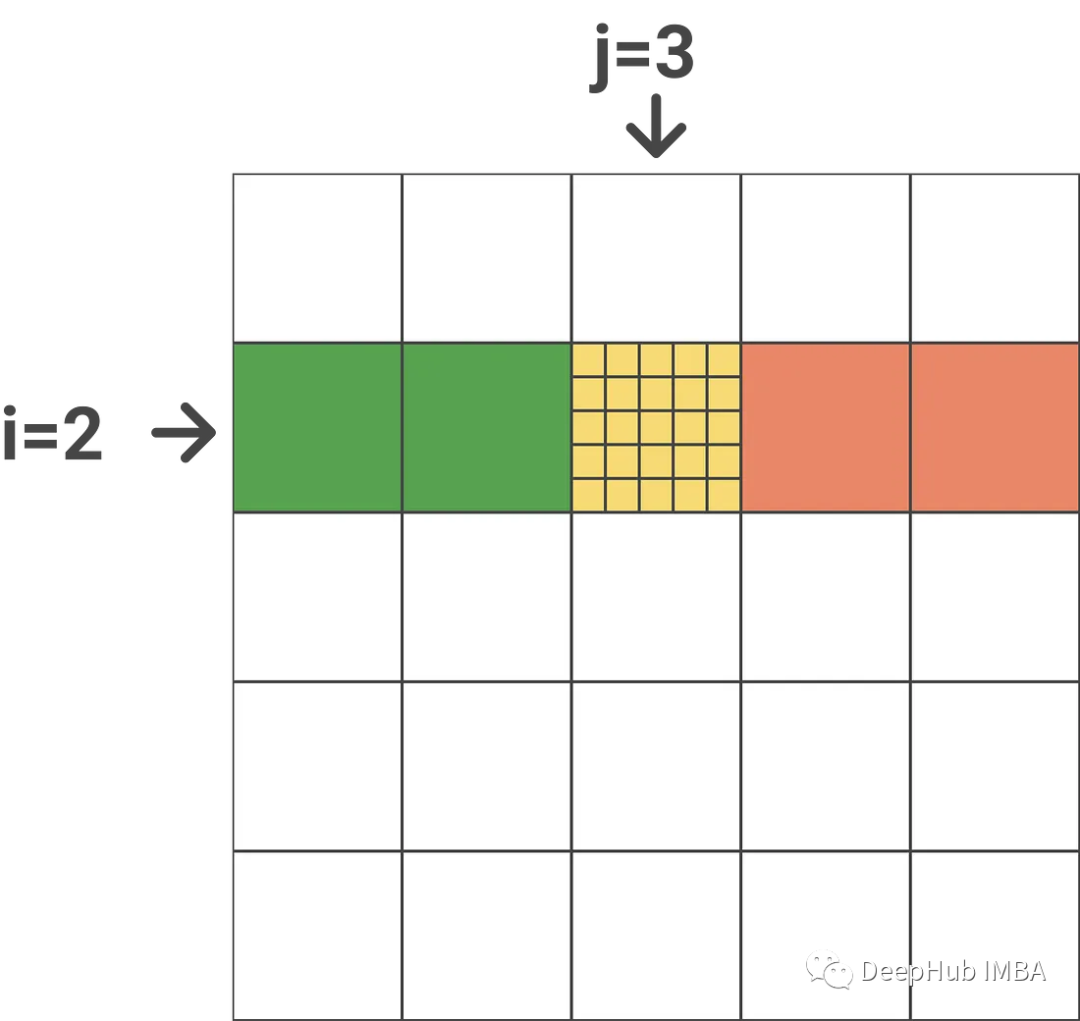
Nos permite realizar una multiplicación escalar por filas en forma matricial. Si tiene una columna de escalares s(N) y una matriz a(NxN), si hace diag(s)*a, básicamente está haciendo una multiplicación por elementos de la fila a con esos escalares.
Fórmula 1 (pegado aquí nuevamente por conveniencia):
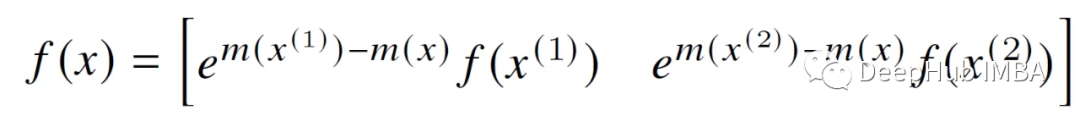
Lo que hace el primer elemento del paso 12 (subrayado en verde) es: actualiza la estimación softmax actual para el bloque anterior al bloque actual en el mismo bloque de fila. si j=1 (Este es el primer bloque de esta línea.
El primer término se multiplica por diag(l_i) para cancelar la misma constante que se dividió en la iteración anterior (esta constante está oculta en O_i).
No es necesario eliminar el segundo término de la expresión (subrayado amarillo), porque podemos ver que multiplicamos directamente la matriz P~_i_j con el bloque de vectores V (V_j).
El término e^x se utiliza para modificar la matriz P~_i_j & O_i eliminando m de la iteración anterior y actualizándola con la última estimación (m_new_i) que contiene el máximo fila por fila hasta el momento.
Aquí está mi análisis paso a paso (en realidad, solo toma 5 minutos, ¡espero que ayude!)

El punto es que estos términos e externos y los términos e en la matriz P/O se eliminan, por lo que siempre se obtiene la última estimación m_new_1.

¡La tercera iteración fue similar y obtuvo el resultado final correcto!
Recuerde: esta es sólo una estimación actual del O_i final. Solo después de recorrer todos los bloques rojos en la imagen de arriba podremos finalmente obtener el resultado exacto.
paso 13
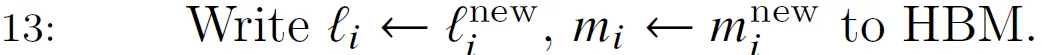
Escriba las últimas estadísticas acumuladas (l_i y m_i) en HBM. Tenga en cuenta que su dimensionalidad es B_r.
Pasos 13, 14, 15, 1
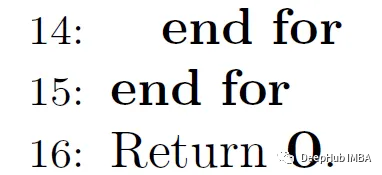
Al final de los bucles for anidados, O(Nxd) contendrá el resultado final: ¡un vector de pesos de atención para cada token de entrada!
resumen sencillo
El algoritmo se puede extender fácilmente a "FlashAttention con bloques dispersos", que es un algoritmo de atención escasa que es de 2 a 4 veces más rápido que FlashAttention y escala a longitudes de secuencia de 64 k. Al usar una matriz de máscara en forma de bloque, es posible para omitir algo de carga/almacenamiento en el bucle for anidado anterior, para que podamos guardar el coeficiente disperso proporcionalmente, como en la siguiente figura

Ahora analicemos brevemente la complejidad.
Análisis de complejidad
Espacio: Q, K, V, O (Nxd), l y m (N) están asignados en HBM. Es igual a 4 N d + 2*N. Quitar la constante y saber que d también es una constante y generalmente mucho más pequeña que N (por ejemplo, d={32,64,128}, N={1024,...,100k}), da el espacio O(N), lo que ayuda Escala hasta 64k de longitud de secuencia (más algunos otros "trucos" como ALiBi).
Tiempo: El análisis de la complejidad del tiempo no se realizará estrictamente aquí, pero usaremos una buena métrica: el número de accesos a HBM.
La explicación del documento es la siguiente:

¿Cómo obtuvieron este número? Analicemos los bucles for anidados:
Nuestro tamaño de bloque es M/4d. Esto significa que el vector se divide en N/(M/4d) bloques. Llevarlo a la potencia de 2 (ya que estás atravesando bloques de filas/columnas) te da O(N²d²/M²)
No podemos recuperar todo el bloque a la vez, y hacer un análisis de gran tamaño podría llevarnos a pensar que esto no es mucho mejor que la atención estándar, pero para números típicos esto resulta en una reducción de 9 veces en el número de accesos ( según la captura de pantalla en papel anterior).
Nuestro pseudoalgoritmo se centra en la atención de un solo cabezal, asumiendo un tamaño de lote de 1. Ahora comenzamos a expandirnos.
atención multidireccional
En realidad, no es tan difícil escalar a tamaño de lote > 1 y num_heads > 1.
Los algoritmos se procesan básicamente mediante un único bloque de subprocesos (término de programación CUDA). Este bloque de subprocesos se ejecuta en un único multiprocesador de transmisión (SM) (por ejemplo, hay 108 procesadores de este tipo en el A100). Para paralelizar los cálculos, solo es necesario ejecutar bloques de subprocesos de tamaño de lote * num_heads en paralelo en diferentes SM. Cuanto más cercano esté este número al número de SM disponibles en el sistema, mayor será la utilización (idealmente múltiple, ya que cada SM puede ejecutar múltiples bloques de subprocesos).
propagación hacia atrás
Para la ocupación de la memoria de la GPU, otro gran problema es la retropropagación. Al almacenar la salida O (Nxd) y las estadísticas normalizadas de softmax (N), podemos invertir directamente los bloques Q, K y V (Nxd) en SRAM. S(NxN) y P(NxN) ! manteniendo así la memoria en O(N). Esto es más profesional, podemos entender lo siguiente, así que consulte el documento original para obtener contenido detallado.
Código
Finalmente, veamos algunos de los problemas que pueden surgir al utilizar la atención flash. Debido a que implica el funcionamiento de la memoria de video, solo podemos profundizar en CUDA, pero CUDA es más complicado.
Esta es la fortaleza de proyectos como Triton de OpenAI (consulte su implementación de FlashAttention). Triton es básicamente un DSL (lenguaje específico de dominio), un nivel de abstracción entre CUDA y otros lenguajes específicos de dominio como TVM. Es posible escribir código Python súper optimizado (una vez compilado) sin tener que tratar directamente con CUDA. De esta manera, el código Python se puede implementar en cualquier acelerador (esta es la tarea de Triton).
Otra buena noticia es que Triton se integró recientemente con PyTorch 2.0.
Además, para algunos casos de uso, como secuencias de más de 1K, algunos métodos de atención aproximada (como Linformer) comienzan a ser más rápidos. Pero la implementación de la atención flash con pocos bloques supera a todos los demás métodos.
Resumir
¿Alguna vez te has preguntado por qué un estudiante de la Universidad de Stanford lanzó el algoritmo para este tipo de optimización de nivel inferior en lugar de un ingeniero de NVIDIA?
Creo que hay 2 posibles explicaciones:
1. FlashAttention es más fácil/solo se puede implementar en la última gpu (el código base original no es compatible con V100).
2. Por lo general, los "forasteros" son aquellos que miran los problemas con los ojos de los principiantes, pueden ver la raíz del problema y resolverlo desde los principios básicos.
Finalmente, aún nos queda hacer un resumen.
FlashAttention puede ahorrar un 15% en el entrenamiento BERT grande, aumentar la velocidad del entrenamiento GPT en 2/3 y sin modificar el código, este es un avance muy importante y propone uno nuevo para la dirección de investigación de LLM.
Dirección del papel:
https://avoid.overfit.cn/post/9d812b7a909e49e6ad4fb115cc25cdc1
Autor: Aleksa Gordic