
Una característica clave de la inteligencia humana es que los humanos pueden aprender a realizar nuevas tareas razonando usando solo unos pocos ejemplos. La ampliación de los modelos de lenguaje desbloquea una gama de nuevas aplicaciones y paradigmas en el aprendizaje automático, incluida la capacidad de realizar tareas de razonamiento desafiantes a través del aprendizaje contextual. Sin embargo, los modelos de lenguaje aún son sensibles a la forma en que se dan las pistas, lo que sugiere que no están infiriendo de manera sólida. Por ejemplo, los modelos de lenguaje a menudo requieren tareas de redacción o ingeniería de sugerencias pesadas como instrucciones, y exhiben comportamientos inesperados, como que el rendimiento de la tarea no se ve afectado incluso cuando se muestran etiquetas incorrectas.
En "El ajuste simbólico mejora el aprendizaje contextual en los modelos de lenguaje", proponemos un procedimiento de ajuste fino simple, que llamamos ajuste simbólico, que mejora el aprendizaje contextual al enfatizar las asignaciones de etiquetas de entrada. Experimentamos con el ajuste de signos en el modelo Flan-PaLM y observamos beneficios para varios entornos.
- La afinación simbólica mejora el rendimiento en tareas de aprendizaje de contexto no visto y es más resistente a señales no especificadas, como señales sin instrucciones o sin etiquetas de lenguaje natural.
- Los modelos ajustados por signo son mucho más fuertes en tareas de razonamiento algorítmico.
- Finalmente, los modelos ajustados por signos muestran grandes mejoras en el seguimiento de las etiquetas invertidas presentadas en contexto, lo que significa que pueden usar mejor la información contextual para anular el conocimiento previo.
 |
|---|
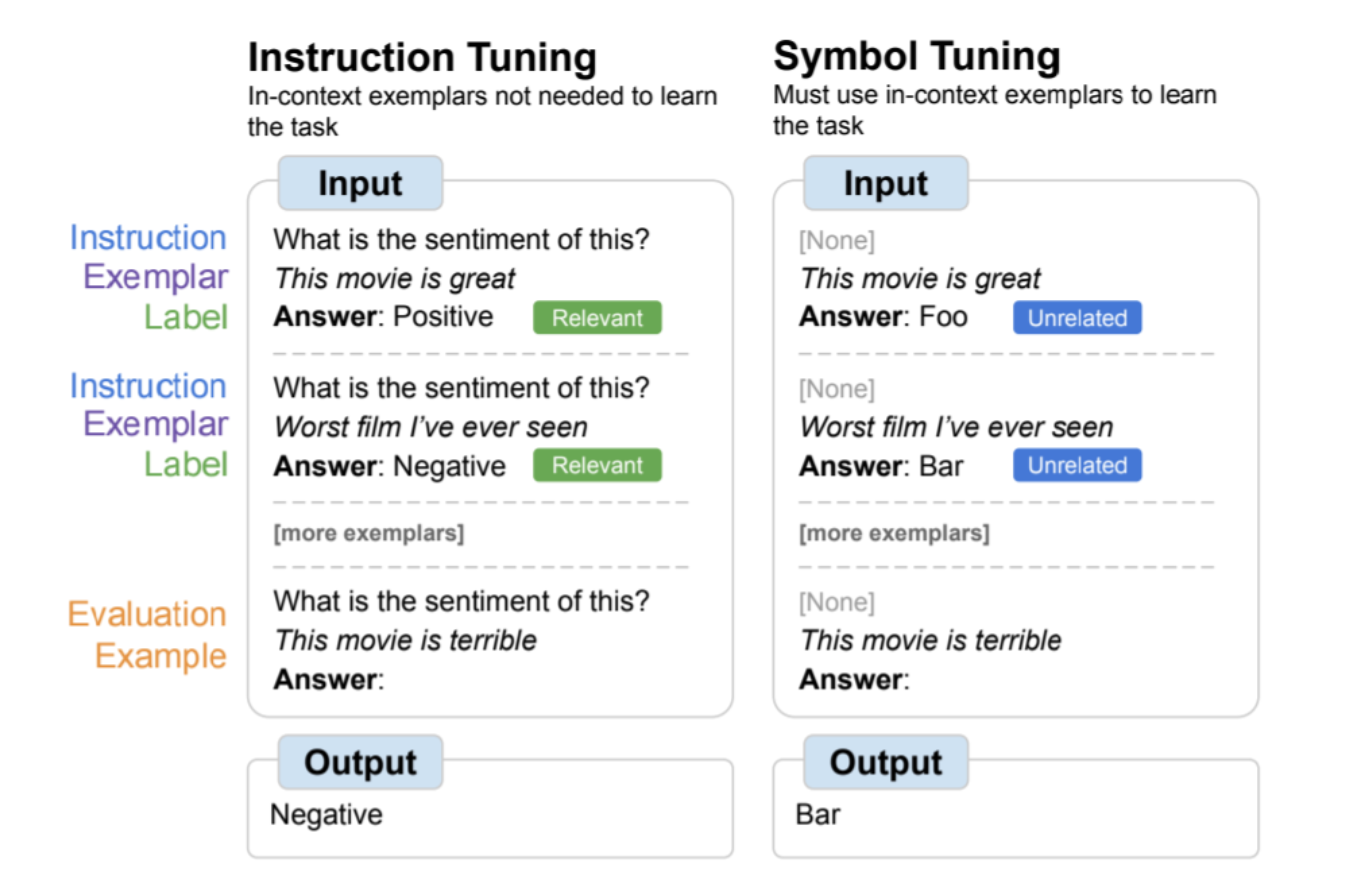
| Una descripción general de la optimización simbólica, donde los modelos se ajustan en la tarea de reemplazar las etiquetas del lenguaje natural con símbolos arbitrarios. El ajuste simbólico se basa en la intuición de que cuando las instrucciones y las etiquetas asociadas no están disponibles, el modelo debe usar ejemplos del contexto para aprender la tarea. |
motivación
El ajuste de instrucciones es un método de ajuste fino común que se ha demostrado que mejora el rendimiento y permite que los modelos sigan mejor los ejemplos contextuales. Sin embargo, una desventaja es que el modelo no está obligado a aprender a usar estos ejemplos, ya que las tareas se definen de forma redundante en los ejemplos de evaluación a través de instrucciones y etiquetas de lenguaje natural. Por ejemplo, en el lado izquierdo de la figura anterior, aunque los ejemplos pueden ayudar al modelo a comprender la tarea (análisis de sentimiento), no son estrictamente necesarios, porque el modelo puede ignorar los ejemplos y solo leer las instrucciones que indican cuál es la tarea.
En el ajuste simbólico, el modelo se ajusta con precisión en los ejemplos en los que se eliminan las instrucciones y las etiquetas del lenguaje natural se reemplazan con etiquetas no relacionadas semánticamente (por ejemplo, "Foo", "Bar", etc.). En este escenario, la tarea no es clara sin mirar los ejemplos en contexto. Por ejemplo, en el lado derecho de la imagen de arriba, se requieren múltiples ejemplos contextuales para aclarar la tarea. Dado que la optimización simbólica le enseña al modelo a razonar sobre ejemplos en contexto, los modelos optimizados simbólicamente tienen un mejor rendimiento en tareas que requieren razonamiento entre ejemplos en contexto y sus etiquetas.
 |
|---|
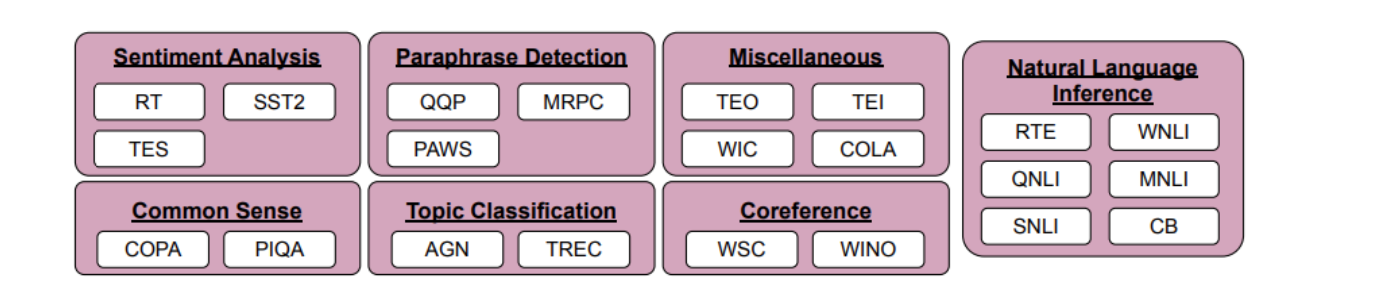
| Conjuntos de datos y tipos de tareas para la optimización simbólica. |
proceso de ajuste de signos
Seleccionamos 22 conjuntos de datos de procesamiento de lenguaje natural (NLP) disponibles públicamente para el proceso de ajuste de símbolos. Estas tareas han sido ampliamente utilizadas en el pasado, solo elegimos tareas de tipo clasificación porque nuestro método requiere etiquetas discretas. Luego reasignamos las etiquetas a etiquetas aleatorias de un conjunto de ~30K etiquetas arbitrarias elegidas de una de tres categorías: números enteros, combinaciones de caracteres y palabras.
Para nuestros experimentos, sintonizamos simbólicamente Flan-PaLM, una variante de PaLM sintonizada con instrucciones. Utilizamos tres tamaños diferentes de modelos Flan-PaLM: Flan-PaLM-8B, Flan-PaLM-62B y Flan-PaLM-540B. También probamos Flan-cont-PaLM-62B (Flan-PaLM-62B, tokens 1.3T en lugar de tokens 780B), que abreviamos como 62B-c.
 |
|---|
| Usamos un conjunto de ~300K símbolos arbitrarios de tres categorías (enteros, combinaciones de caracteres y palabras). Se utilizan unos 30 000 símbolos durante la sintonización y los símbolos restantes se utilizan para la evaluación. |
configuración del experimento
Queríamos evaluar la capacidad del modelo para realizar tareas invisibles, por lo que no pudimos evaluar las tareas utilizadas en el ajuste de señales (22 conjuntos de datos) o durante el ajuste de instrucciones (1,800 tareas). Por lo tanto, seleccionamos 11 conjuntos de datos de NLP que no se utilizaron en el proceso de ajuste.
aprendizaje contextual
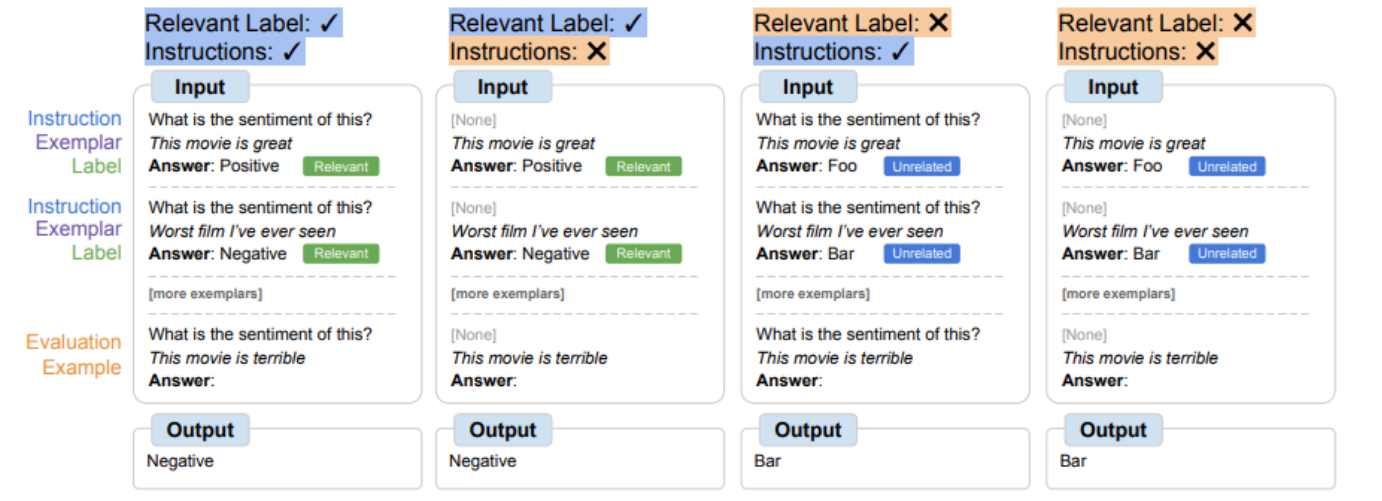
Durante el ajuste de símbolos, el modelo debe aprender a razonar usando ejemplos contextuales para realizar la tarea con éxito, ya que las señales se modifican para garantizar que la tarea no se pueda aprender simplemente de las etiquetas o instrucciones relevantes. Los modelos optimizados simbólicamente deberían funcionar mejor en entornos donde la tarea es ambigua y requiere razonamiento entre ejemplos contextuales y sus etiquetas. Para explorar estas configuraciones, definimos cuatro configuraciones de aprendizaje contextual que varían la cantidad de inferencia requerida para aprender la tarea entre entradas y etiquetas (según la disponibilidad de subtítulos/etiquetas relacionadas)
 |
|---|
| Según la disponibilidad de las instrucciones y las etiquetas de lenguaje natural asociadas, es posible que los modelos necesiten usar ejemplos contextuales para cantidades variables de inferencia. Cuando estas características no están disponibles, el modelo debe razonar usando los ejemplos contextuales dados para realizar la tarea con éxito. |
Los ajustes de símbolos mejoran el rendimiento en todas las configuraciones en 62B y superior, con pequeñas mejoras (+0,8 % a +4,2 %) para configuraciones con etiquetas de lenguaje natural asociadas y mejoras sustanciales para configuraciones sin etiquetas de lenguaje natural asociadas (+5,5 % a +15,5 %). Sorprendentemente, Flan-PaLM-8B sintonizado por signos superó a FlanPaLM-62B, y Flan-PaLM-62B sintonizado por signos superó a Flan-PaLM-540B cuando las etiquetas relevantes no estaban disponibles. Esta diferencia en el rendimiento sugiere que el ajuste de signo puede permitir que modelos más pequeños y más grandes realicen estas tareas (ahorrando efectivamente cálculos de inferencia 10x).
 |
|---|
| Los modelos ajustados por signos de tamaño suficientemente grande son mejores para el aprendizaje contextual que las líneas de base, especialmente en entornos sin etiquetas asociadas. El rendimiento se muestra como la precisión promedio del modelo (%) en las 11 tareas. |
razonamiento algorítmico
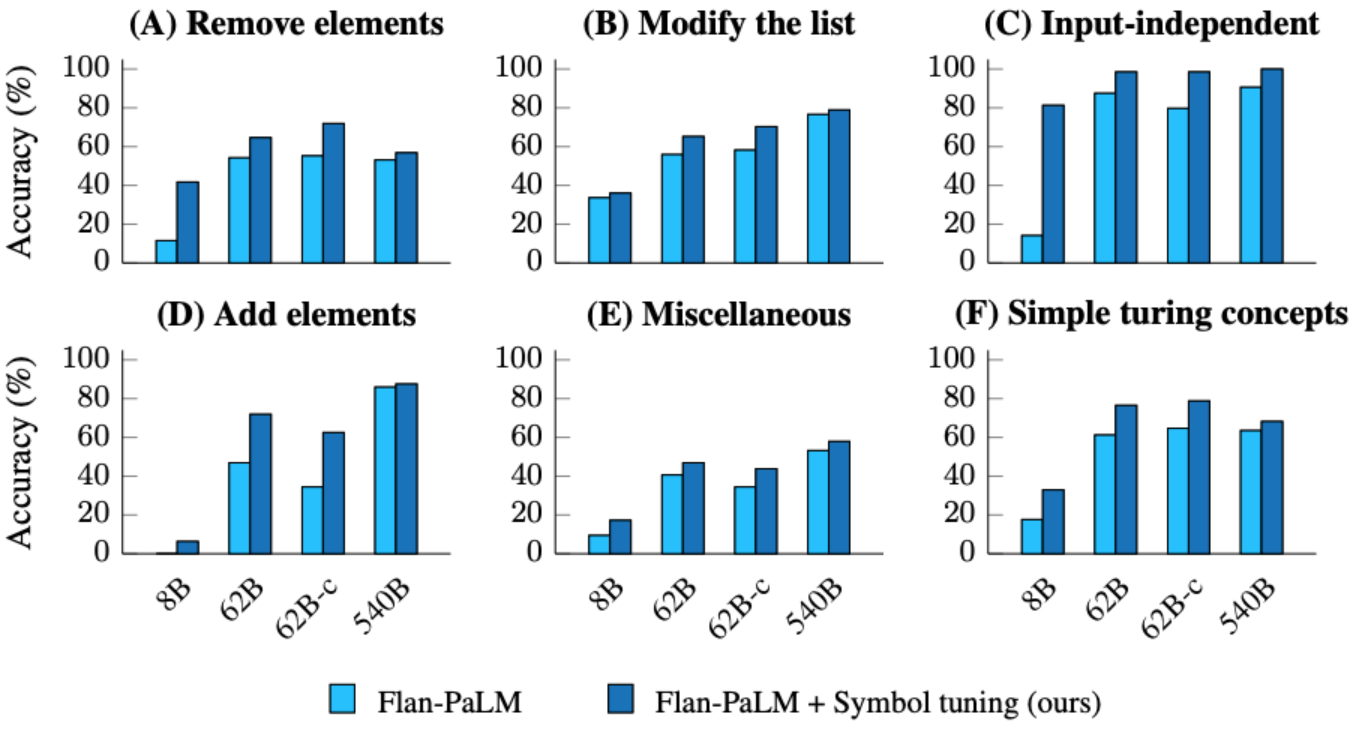
También llevamos a cabo experimentos sobre la tarea de inferencia algorítmica de BIG-Bench. Hay dos grupos principales de tareas: 1) funciones de lista: identificación de funciones de transición entre listas de entrada y salida que contienen números enteros no negativos (p. ej., eliminar el último elemento de una lista); 2) conceptos simples de Turing: razonamiento con cadenas binarias para comprender conceptos que asignan entradas a salidas (p. ej., intercambiar 0 y 1 en cadenas).
En las funciones de lista y las tareas simples del concepto de Turing, el ajuste de signos dio como resultado una mejora promedio del rendimiento del 18,2 % y el 15,3 %, respectivamente. Además, Flan-cont-PaLM-62B con ajuste de signos supera a Flan-PaLM-540B en promedio en tareas de función de lista, lo que equivale a una reducción de 10 veces en el cálculo de inferencia. Estas mejoras demuestran que el ajuste de signos mejora la capacidad del modelo para aprender tipos de tareas invisibles en contexto, ya que el ajuste de signos no incluye datos algorítmicos.
 |
|---|
| Los modelos ajustados por signo logran un mayor rendimiento en tareas de función de lista y tareas simples de concepto de Turing. (A–E): categorías de tareas de función de lista. (F): Tarea de concepto de Turing simple. |
voltear pestaña
En el experimento de etiqueta invertida, las etiquetas del contexto y los ejemplos de evaluación están invertidas, lo que significa que el conocimiento previo y el mapeo de la etiqueta de entrada son inconsistentes (por ejemplo, una oración que contiene una emoción positiva se etiqueta como "emoción negativa"), lo que nos permite investigar si el modelo puede anular el conocimiento previo. Estudios previos han demostrado que, si bien los modelos preentrenados (sin sintonización de instrucciones) pueden seguir hasta cierto punto las etiquetas invertidas presentadas en contexto, la sintonización de instrucciones reduce esta capacidad.
Vemos una tendencia similar para todos los tamaños de modelo: el modelo ajustado por signo sigue las etiquetas invertidas mejor que el modelo ajustado por instrucciones. Encontramos que después del ajuste de signo, la mejora promedio en todos los conjuntos de datos es de 26,5 % para Flan-PaLM-8B, 33,7 % para Flan-PaLM-62B y 34,0 % para Flan-PaLM-540B. Además, los modelos optimizados con símbolos logran un rendimiento promedio similar o mejor que los modelos solo preentrenados.
 |
|---|
| Los modelos optimizados para símbolos son mejores para seguir las etiquetas rotatorias presentadas en contexto que los modelos optimizados para instrucciones. |
en conclusión
Presentamos el ajuste simbólico, un nuevo método para ajustar modelos en la tarea de reasignar etiquetas de lenguaje natural a símbolos arbitrarios. El ajuste simbólico se basa en la intuición de que cuando un modelo no puede usar instrucciones o etiquetas relevantes para determinar la tarea presentada, debe hacerlo aprendiendo de ejemplos contextuales. Ajustamos cuatro modelos de lenguaje usando un procedimiento de ajuste simbólico, utilizando una combinación ajustada de 22 conjuntos de datos y aproximadamente 30 000 símbolos arbitrarios como etiquetas.
En primer lugar, mostramos que la afinación de signos puede mejorar el rendimiento en tareas de aprendizaje de contexto no visto, especialmente cuando las señales no contienen instrucciones o etiquetas relevantes. También encontramos que los modelos ajustados por signo se desempeñaron mucho mejor en las tareas de inferencia algorítmica, a pesar de la falta de datos numéricos o algorítmicos durante el ajuste de signo. Finalmente, en entornos de aprendizaje contextual donde la entrada tiene etiquetas de cambio, el ajuste de signos (para algunos conjuntos de datos) restaura la capacidad de seguir las etiquetas de cambio que se perdieron durante el ajuste de instrucciones.
trabajo futuro
Con el ajuste de signos, nuestro objetivo es mejorar el grado en que el modelo inspecciona y aprende las asignaciones de etiquetas de entrada durante el aprendizaje contextual. Esperamos que nuestros resultados fomenten nuevas mejoras en la capacidad de los modelos de lenguaje para razonar sobre símbolos presentados en contexto.