En los últimos años se han logrado avances en el campo de la inteligencia artificial, que ha tenido un gran impacto en diversos campos de la economía y la sociedad. El aprendizaje automático, que combina estadística, ciencia de datos e informática, es una de las principales direcciones de la inteligencia artificial. inteligencia, y también se está desarrollando rápidamente Integrarse en la investigación econométrica. A primera vista, el aprendizaje automático suele utilizar grandes datos, mientras que la econometría suele utilizar muestras más pequeñas, pero esta distinción se está volviendo cada vez más borrosa y el aprendizaje automático se ha vuelto cada vez más prominente en el campo de la economía, especialmente en la intersección de la economía y otras disciplinas. El lenguaje R es el lenguaje informático principal utilizado para el modelado estadístico, es muy conveniente para el aprendizaje automático y la curva de aprendizaje es más suave que Python, por lo que es una de las primeras opciones para el aprendizaje automático.
En este contenido, comenzaremos con las necesidades reales de la redacción de tesis y primero presentaremos brevemente las teorías básicas y los métodos de investigación de la economía, para que pueda comprender el método de selección de temas y el marco de redacción de la tesis. Luego, concéntrese en la recopilación y limpieza de datos, la evaluación integral de modelos, el análisis y visualización de datos, el efecto espacial de los datos, la inferencia causal, etc., para que pueda dominar la tecnología del uso del lenguaje R para la investigación económica a la velocidad más rápida. Al mismo tiempo, también introducirá el software auxiliar que se utiliza a menudo en la redacción de tesis, a fin de reducir la dificultad de la redacción de tesis tanto como sea posible.
Bases teóricas e introducción al software.
1.1 Principios básicos de la economía
contenido principal:
Paradigma del pensamiento económico, asignación de recursos, eficiencia y equidad (en el campo de la economía clásica).
Gregory Mankiw, los diez principios de la economía en pocas palabras
Por ejemplo, el Principio de Ventaja Comparativa de David Ricardo.
Por ejemplo, oportunidades y costos. Curva de precios positiva en forma de U, MC (costo marginal) ACT (costo total promedio)

La gente racional supone que la regulación del mercado puede ser la solución óptima.
El efecto anclaje de Dan Ariely en Freaky Behavior
1.2 La idea básica de probabilidad y estadística.
1.2.1 Conceptos comunes en probabilidad y estadística
El nacimiento de la probabilidad, el problema del té con leche.
distribución normal.


intervalo de confianza

valor p
1.2.2 Evaluación (evaluación de índice único y evaluación de índice compuesto)
Evaluación de índice único: como el PIB
Evaluación del índice compuesto
Evaluación del sistema de índices

1.2.3 Inferencia causal
Generación de conceptos: la inferencia causal es el proceso de describir la relación causal de acuerdo con las condiciones bajo las cuales ocurre un determinado resultado. La forma más efectiva de inferir la relación causal es realizar ensayos controlados aleatorios, pero este método requiere mucho tiempo y es costoso. e inexplicables y caracterizan diferencias individuales; por lo tanto, se considera la inferencia causal a partir de datos observacionales. Dichos marcos incluyen marcos de resultados latentes y modelos causales estructurales. Los métodos de inferencia causal de los modelos causales estructurales se revisan a continuación.


Nivel de evidencia, caso único, casos múltiples, ensayos controlados aleatorios, análisis mecanismo por mecanismo basado en evidencia
1.3 Aprendizaje automático para evaluación e inferencia causal (Introducción a los algoritmos)
1.3.1 KNN y Kmedias
El método KNN (K-Nearest Neighbor), el método K-vecino más cercano, fue propuesto por primera vez por Cover y Hart en 1968. Es un método relativamente maduro en teoría y uno de los algoritmos de aprendizaje automático más simples. La idea de este método es muy simple e intuitiva: si la mayoría de las K muestras más similares en el espacio de características (es decir, los vecinos más cercanos en el espacio de características) de una muestra pertenecen a una determinada categoría, entonces la muestra también pertenece a esta categoría. En la decisión de clasificación, este método solo determina la categoría de la muestra a dividir según la categoría de la o varias muestras más cercanas.

K significa
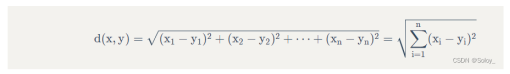

1.3.2 Delfos y AHP
Delphi es la traducción china de Delphi. En la década de 1950, la Rand Corporation de los Estados Unidos cooperó con la Douglas Corporation para desarrollar un método eficaz y confiable para recopilar opiniones de expertos, llamado "Delphi". Después de eso, este método se utilizó ampliamente en los negocios, el ejército, la educación, la atención médica y otros campos. La aplicación del método Delphi en medicina comenzó con la investigación sobre el trabajo de enfermería, y ha demostrado su superioridad y aplicabilidad en el proceso de uso, y ha sido favorecido por cada vez más investigadores.
AHP (Proceso de Jerarquía Analítica) es un método práctico de toma de decisiones multiprograma o multiobjetivo propuesto por el investigador de operaciones estadounidense Profesor TL Saaty en la década de 1970. Es un método de análisis de toma de decisiones que combina análisis cualitativo y cuantitativo . A menudo se aplica a problemas de toma de decisiones complejos no estructurados de múltiples objetivos, múltiples criterios, múltiples elementos y múltiples niveles , especialmente problemas de toma de decisiones estratégicas, y tiene una gama muy amplia de practicabilidad.


1.3.3 Método de ponderación de entropía
Método de peso de entropía TOPSIS
El método de ponderación de entropía es un método para calcular el peso de cada índice en función del tamaño de la entropía de la información de los datos, que puede evaluar de manera integral objetivos de índices múltiples. El método TOPSIS puede optimizar aún más los resultados del método de ponderación de entropía, haciendo que los resultados de la evaluación sean más objetivos y razonables [23 ~ 25].
El primer paso es estandarizar los datos:


1.3.4 Algoritmo de bosque aleatorio
Existe una categoría grande en el aprendizaje automático llamada Ensemble Learning. La idea básica de Ensemble Learning es combinar múltiples clasificadores para lograr un clasificador integrado con mejor efecto de predicción. Se puede decir que el algoritmo integrado ha verificado un antiguo dicho chino, por un lado: Tres zapateros son mejores que Zhuge Liang.

1.3.5 Red neuronal
El aprendizaje de la red neuronal se divide en dos etapas: una es la etapa de avance multicapa, que calcula la entrada y salida reales de cada nodo de capa desde la capa de entrada a la vez; la segunda es la etapa de corrección inversa, es decir, de acuerdo con Para el error de salida, los pesos de la conexión se corrigen de manera inversa a lo largo del camino, para reducir el error [27].

1.4 Introducción al software común
Excel, R, Stata, Photoshop, Arcgis, SPSS, Geoda, Python, Notexpress, Endnote
Tema 2
Adquisición y recopilación de datos
2.1 Introducción a los tipos de datos
datos cuantitativos, datos categóricos,
Datos transversales, datos de series temporales, datos de panel
2.2 Adquisición de datos
Artículos, Oficina de Estadísticas, Anuario, Sitios web relacionados, Compra

Anuario estadístico
anotación de tesis
2.3 recopilación de datos
Conversión de formato común, llenado de valores faltantes
Métodos de evaluación de uso común y enseñanza detallada del software relacionado (detalles del caso)
3.1 Cálculo de las emisiones de carbono agrícolas
3.2 Cálculo de las emisiones de carbono derivadas del consumo de energía
3.3 Método de evaluación integral
La entrada de la fórmula y el funcionamiento real del método de ponderación de entropía.
3.4 Análisis y visualización de datos
Introducción a los métodos comunes de visualización de datos.
Diagramas de caja, histogramas, gráficos de líneas, gráficos geográficos, etc.
Tres leyes de la geografía y análisis de la autocorrelación espacial.
3.5 Modelado de regresión forestal aleatoria
3.5.1 Construcción del modelo y optimización de parámetros relacionados.
3.5.2 Evaluación del efecto del modelo
3.5.3 Análisis de los resultados del modelo
3.5.4 Factores impulsores y análisis del mecanismo del mecanismo (análisis de atribución, mecanismo impulsor)
3.6 Modelado de regresión de redes neuronales
El contenido es el mismo que el anterior.
Comparado con otros modelos
Puntos clave de redacción y explicación de casos.
4.1 Puntos generales de redacción
4.1.1 Un buen comienzo es la mitad de la batalla (Introducción)
La fuente del tema del artículo.
4.1.2 Método de redacción de la revisión de la literatura
4.1.3 Selección de métodos de investigación y edición de fórmulas
4.1.4 Análisis y visualización de datos (análisis)
4.1.5 Dos formas de escribir para la discusión (Discusión)
4.1.6 Redacción de conclusiones y resúmenes
4.1.7 Construcción de mentalidad, selección y envío de revistas.
4.2 Explicación del caso
4.2.1 Introducción a dos tipos comunes de artículos
Introducción a los tipos experimentales de artículos.
Introducción a los artículos de informática modelo.
4.2.2 Caso
Características espacio-temporales y predicción de tendencias de las emisiones de carbono agrícolas en la provincia de Shanxi de 2000 a 2020
Evaluación de las emisiones agrícolas de carbono de Xinjiang y análisis de los factores determinantes basado en un algoritmo de aprendizaje automático
Factores impulsores y efectos desacopladores de las emisiones de carbono en el noroeste de China
Diferencias regionales y evolución dinámica de la distribución del desarrollo agrícola de alta calidad en China