prefacio
- Este artículo se centra principalmente en
Hugging Faceel modelo de clasificación de imágenes en la plataforma, el ajuste fino de su propio conjunto de datos, el modelo preentrenado esGoogleelvit-base-patch16-224modelo y la página de introducción del modelo . - El código se ejecuta en la plataforma kaggle, utilizando la GPU gratuita de la plataforma, modelo P100, dirección del cuaderno , bienvenidos a todos
copy & edit. - Dirección del proyecto Github , documento
Hugging Facede ajuste fino del modelo
Instalación de dependencia
- Si se está ejecutando en el entorno local, solo necesita instalar 3 paquetes al mismo tiempo
transformers,datasets,evaluate, a saberpip install transformers datasets evaluate - En kaggle, debido a que
accelerateel paquete entra en conflicto con el entorno, debe instalarse desde la fuente del proyecto, a saber:
import IPython.display as display
! pip install -U git+https://github.com/huggingface/transformers.git
! pip install -U git+https://github.com/huggingface/accelerate.git
! pip install datasets
display.clear_output()
- Debido a que la instalación produce una gran cantidad de salida, utilice la salida
display.clear_output()limpia .jupyter notebook
procesamiento de datos
- Aquí se usa el conjunto de datos públicos de clasificación de imágenes en kaggle,
5 Flower Types Classification Datasety la estructura de datos es la siguiente:
- flower_images
- Lilly
- 000001.jpg
- 000002.jpg
- ......
- Lotus
- 001001.jpg
- 001002.jpg
- ......
- Orchid
- Sunflower
- Puede ver que flower_images es la carpeta principal, y Lilly, Lotus, Orchid y Sunflower son todos tipos de flores, y la cantidad de imágenes de cada tipo de flor es 1000
- La lectura de conjuntos de datos y la carga de imágenes de modelos de ajuste fino requieren el uso de funciones
datasetsen el paquete , la documentaciónload_datasetpara esta función
from datasets import load_dataset
from datasets import load_metric
# 加载本地数据集
dataset = load_dataset("imagefolder", data_dir="/kaggle/input/5-flower-types-classification-dataset/flower_images")
# 整合数据标签与下标
labels = dataset["train"].features["label"].names
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = i
id2label[i] = label
metric = load_metric("accuracy")
display.clear_output()
- Si desea ver la imagen, puede usar
imagepara acceder
example = dataset["train"][0]
example['image'].resize((224, 224))

- Determine el modelo que desea ajustar, cargue su archivo de configuración, seleccione aquí y consulte la documentación
vit-base-patch16-224de las clases y métodostransfromersen el paquete.AutoImageProcessorfrom_pretrained
from transformers import AutoImageProcessor
model_checkpoint = "google/vit-base-patch16-224"
batch_size = 64
image_processor = AutoImageProcessor.from_pretrained(model_checkpoint)
image_processor
vit-base-patch16-224Estandarizar conjuntos de datos de ajuste fino de acuerdo con los parámetros de estandarización de imágenes de modelos previamente entrenados sontorchvisionalgunas transformaciones comunes en la biblioteca, por lo que no entraré en detalles aquí. El punto clave es quepreprocess_trainlaspreprocess_valfunciones se usan para estandarizar el conjunto de entrenamiento y el conjunto de verificación respectivamente .
from torchvision.transforms import (
CenterCrop,
Compose,
Normalize,
RandomHorizontalFlip,
RandomResizedCrop,
Resize,
ToTensor,
)
normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
if "height" in image_processor.size:
size = (image_processor.size["height"], image_processor.size["width"])
crop_size = size
max_size = None
elif "shortest_edge" in image_processor.size:
size = image_processor.size["shortest_edge"]
crop_size = (size, size)
max_size = image_processor.size.get("longest_edge")
train_transforms = Compose(
[
RandomResizedCrop(crop_size),
RandomHorizontalFlip(),
ToTensor(),
normalize,
]
)
val_transforms = Compose(
[
Resize(size),
CenterCrop(crop_size),
ToTensor(),
normalize,
]
)
def preprocess_train(example_batch):
example_batch["pixel_values"] = [
train_transforms(image.convert("RGB")) for image in example_batch["image"]
]
return example_batch
def preprocess_val(example_batch):
example_batch["pixel_values"] = [val_transforms(image.convert("RGB")) for image in example_batch["image"]]
return example_batch
- Dividir el conjunto de datos y normalizar el conjunto de entrenamiento y el conjunto de validación respectivamente
# 划分训练集与测试集
splits = dataset["train"].train_test_split(test_size=0.1)
train_ds = splits['train']
val_ds = splits['test']
train_ds.set_transform(preprocess_train)
val_ds.set_transform(preprocess_val)
display.clear_output()
Afinando el modelo
- Cargue el modelo previamente entrenado usando las clases, métodos y documentos
transformersde referencia en el paqueteAutoModelForImageClassificationfrom_pretrained - Algo a tener en cuenta son
ignore_mismatched_sizeslos parámetros, si tiene la intención de ajustar un punto de control que ya se ha ajustado, por ejemplogoogle/vit-base-patch16-224(se ha ajustado en ImageNet-1k), entonces debe proporcionarfrom_pretrainedparámetros adicionales al método.ignore_mismatched_sizes=True. Esto garantizará que el cabezal de salida (con 1000 neuronas de salida) se deseche y se reemplace por un nuevo cabezal de clasificación inicializado aleatoriamente que incluye un número personalizado de neuronas de salida. No necesita especificar este parámetro en caso de que el modelo entrenado previamente no incluya el encabezado.
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
model = AutoModelForImageClassification.from_pretrained(model_checkpoint,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes = True)
display.clear_output()
- Los parámetros de entrenamiento de configuración
TrainingArgumentsestán controlados por una función, que tiene muchos parámetros, consulte la documentación
model_name = model_checkpoint.split("/")[-1]
args = TrainingArguments(
f"{
model_name}-finetuned-eurosat",
remove_unused_columns=False,
evaluation_strategy = "epoch",
save_strategy = "epoch",
save_total_limit = 5,
learning_rate=5e-5,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=1,
per_device_eval_batch_size=batch_size,
num_train_epochs=20,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",)
- Déjame explicarte algunos de los parámetros que aparecen arriba.
output_dir: directorio de salida para predicciones de modelos y puntos de controlremove_unused_columns: si eliminar automáticamente las columnas no utilizadas por los métodos de reenvío de modelosevaluation_strategy: La estrategia de evaluación empleada durante la formaciónsave_strategy: la estrategia de ahorro de puntos de control empleada durante el entrenamientosave_total_limit: limite el número total de puntos de control, elimine los puntos de control más antiguoslearning_rate:AdamWLa tasa de aprendizaje inicial del optimizadorper_device_train_batch_sizebatch: Tamaño del núcleo GPU/TPU/CPU durante el entrenamientogradient_accumulation_steps: número de pasos de actualización para acumular gradientes antes de realizar el pase de actualización/hacia atrásper_device_eval_batch_sizebatch: Tamaño del núcleo GPU/TPU/CPU durante la evaluaciónnum_train_epochs: número total de épocas de entrenamiento a ejecutarwarmup_ratio: la relación del número total de pasos de entrenamiento utilizados para la tasa de aprendizaje de 0 a calentamiento lineallogging_steps: Registre el número de intervalos de pasosload_best_model_at_end: si cargar el mejor modelo encontrado durante el entrenamiento al final del entrenamientometric_for_best_model: especifica la métrica utilizada para comparar dos modelos diferentes
- Formular la función de índice de evaluación
import numpy as np
import torch
def compute_metrics(eval_pred):
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
labels = torch.tensor([example["label"] for example in examples])
return {
"pixel_values": pixel_values, "labels": labels}
- Pasar la configuración de entrenamiento, listo para comenzar a afinar el modelo,
Trainerfunción, documento de referencia
trainer = Trainer(model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=image_processor,
compute_metrics=compute_metrics,
data_collator=collate_fn,)
- Del mismo modo, permítanme explicar algunos de los parámetros anteriores
model: el modelo para entrenar, evaluar o usar para la predicciónargs: Ajustar los parámetros de entrenamientotrain_dataset: el conjunto de datos utilizado para el entrenamientoeval_dataset: el conjunto de datos utilizado para la evaluacióntokenizer: tokenizador para preprocesamiento de datoscompute_metrics: la función que se utilizará para calcular la métrica en el momento de la evaluacióndata_collator: función para formar un lote a partir de una lista de elementos detrain_datasetoeval_dataset
- Inicie el entrenamiento y guarde los pesos del modelo, los cambios en los indicadores de entrenamiento del modelo y los indicadores finales del modelo después de completar el entrenamiento.
train_results = trainer.train()
# 保存模型
trainer.save_model()
trainer.log_metrics("train", train_results.metrics)
trainer.save_metrics("train", train_results.metrics)
trainer.save_state()
- Durante el proceso de formación, puede optar por usar
wandbla plataforma para monitorear el proceso de formación en tiempo real, pero necesita registrar una cuenta, obtener la información correspondienteapi, recomendarlo personalmente y, por supuesto, puedectrl+qoptar por salir. - Salida de entrenamiento:
Epoch Training Loss Validation Loss Accuracy
1 0.384800 0.252986 0.948000
2 0.174000 0.094400 0.968000
3 0.114500 0.070972 0.978000
4 0.106000 0.082389 0.972000
5 0.056300 0.056515 0.982000
6 0.044800 0.058216 0.976000
7 0.035700 0.060739 0.978000
8 0.068900 0.054247 0.980000
9 0.057300 0.058578 0.982000
10 0.067400 0.054045 0.980000
11 0.067100 0.051740 0.978000
12 0.039300 0.069241 0.976000
13 0.029000 0.056875 0.978000
14 0.027300 0.063307 0.978000
15 0.038200 0.056551 0.982000
16 0.016900 0.053960 0.984000
17 0.021500 0.049470 0.984000
18 0.031200 0.049519 0.984000
19 0.030500 0.051168 0.984000
20 0.041900 0.049122 0.984000
***** train metrics *****
epoch = 20.0
total_flos = 6494034741GF
train_loss = 0.1092
train_runtime = 0:44:01.61
train_samples_per_second = 34.062
train_steps_per_second = 0.538
wandbVisualización de indicadores de plataforma
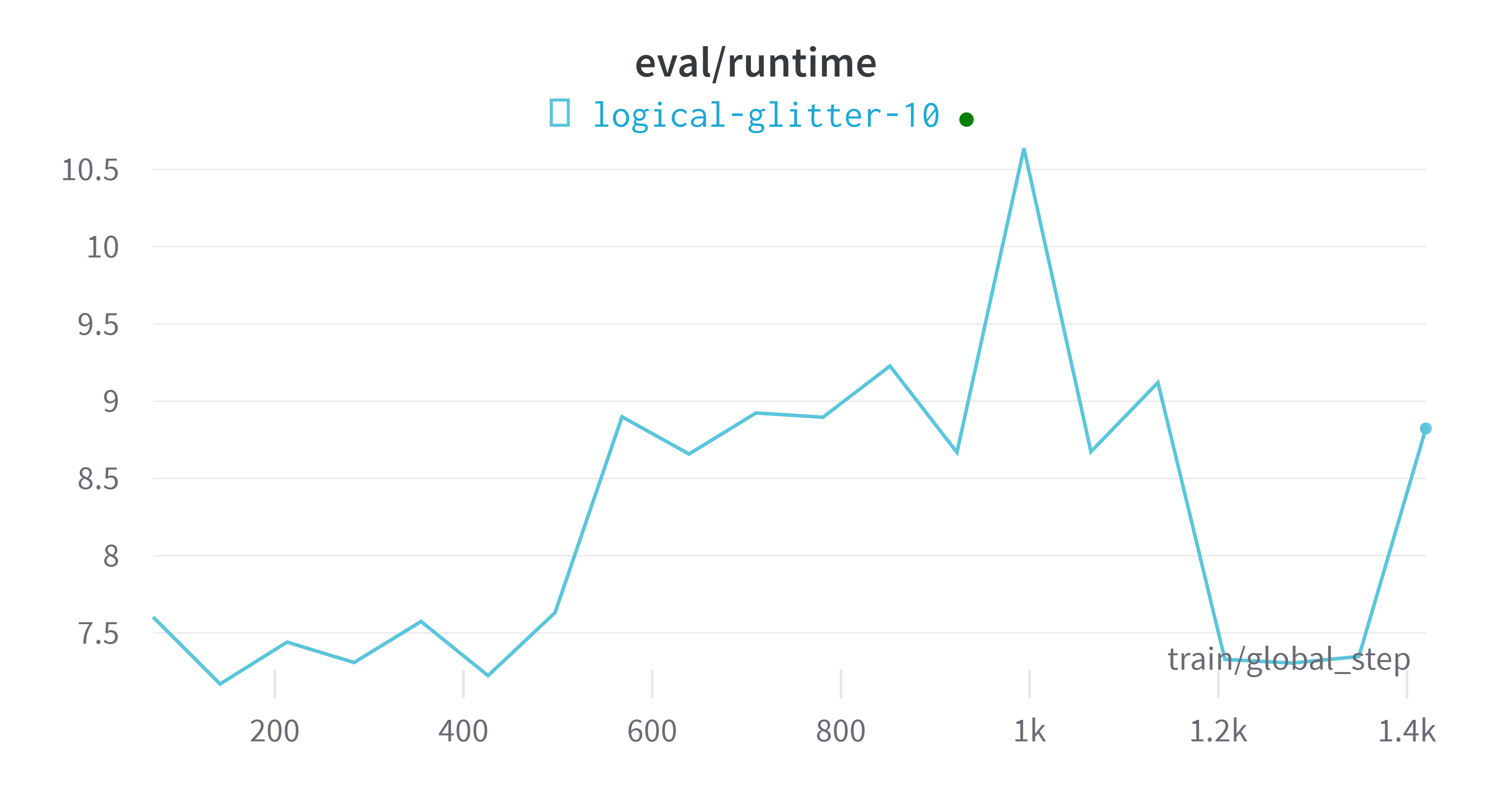
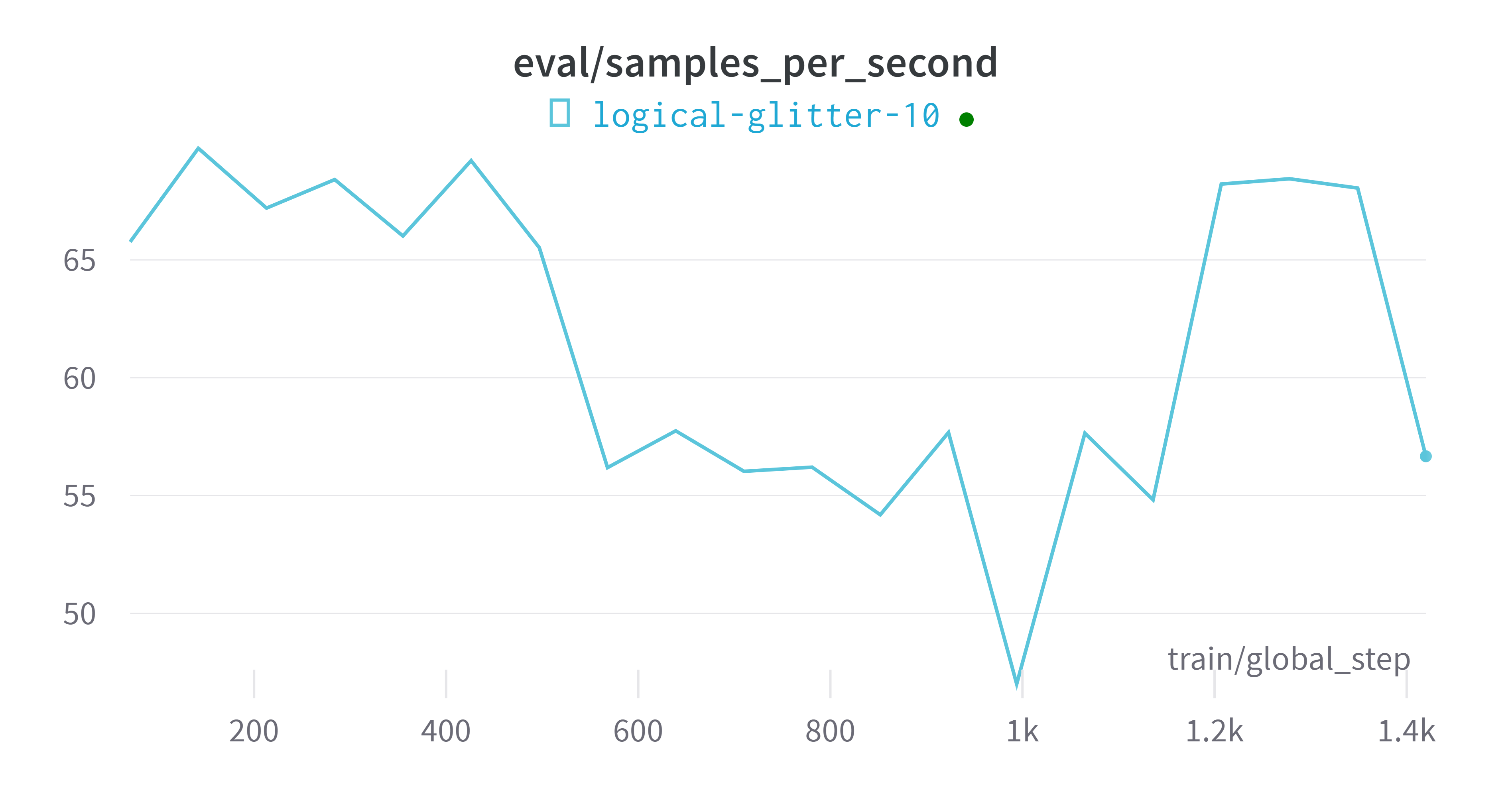
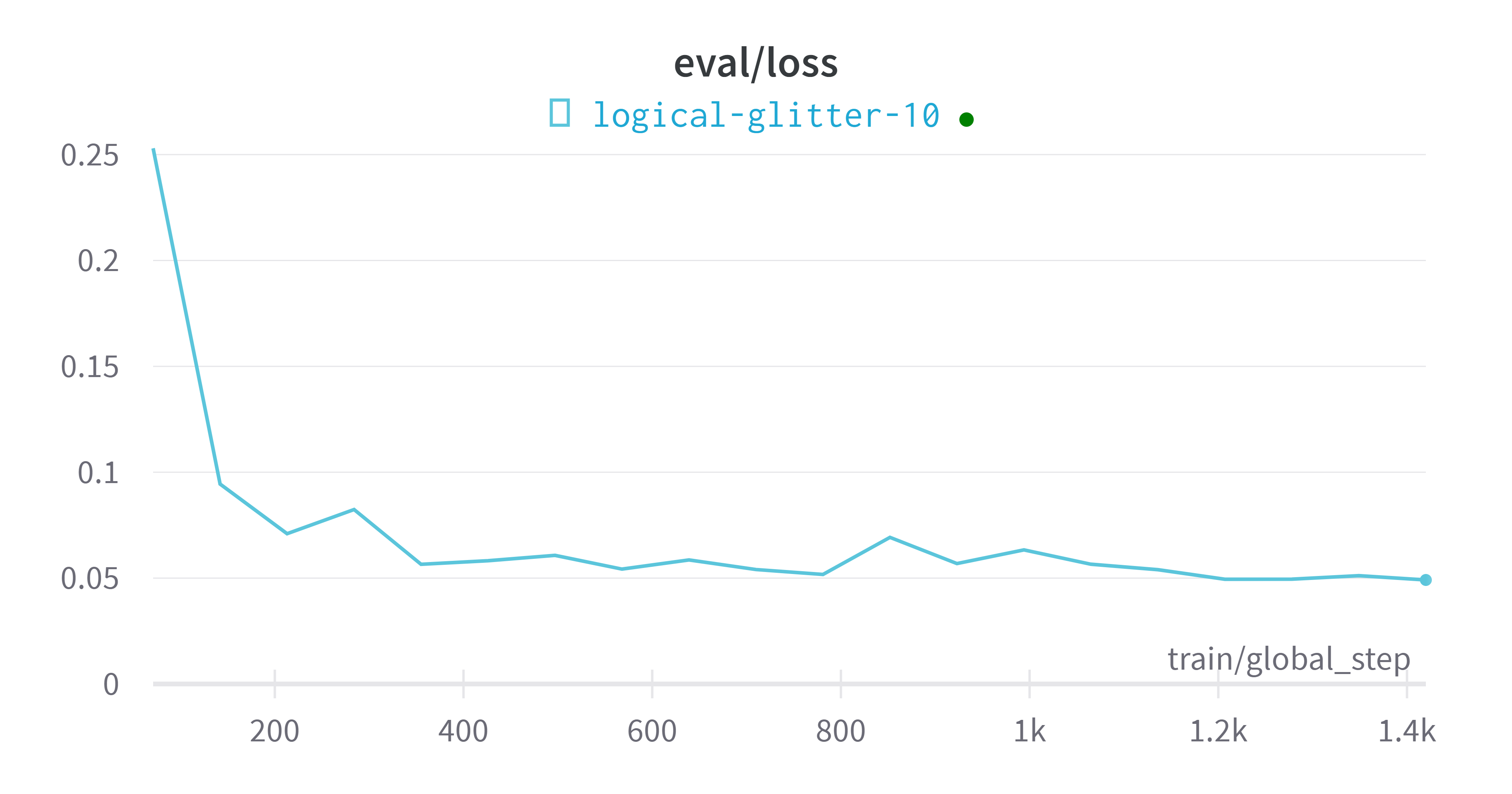
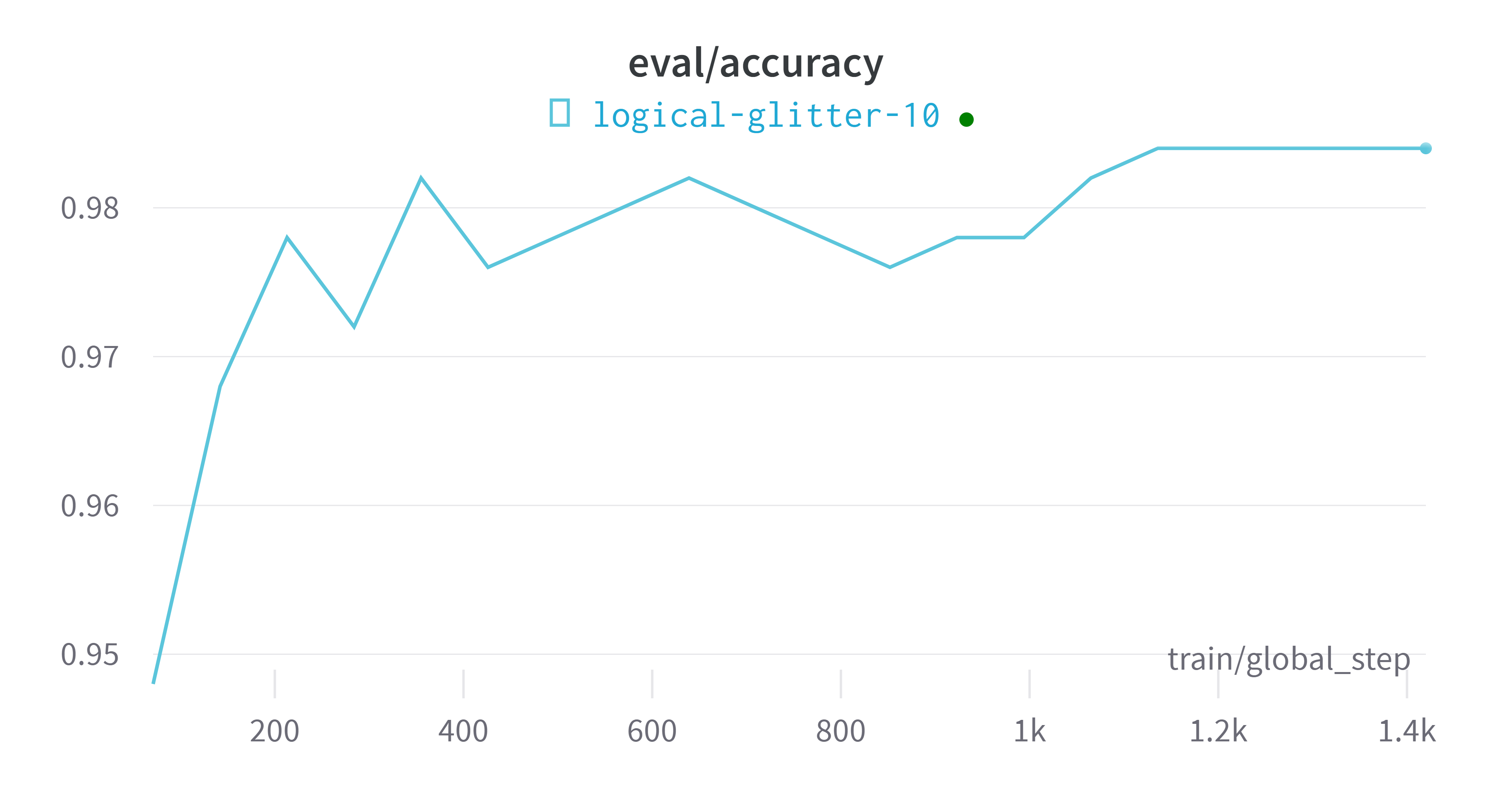
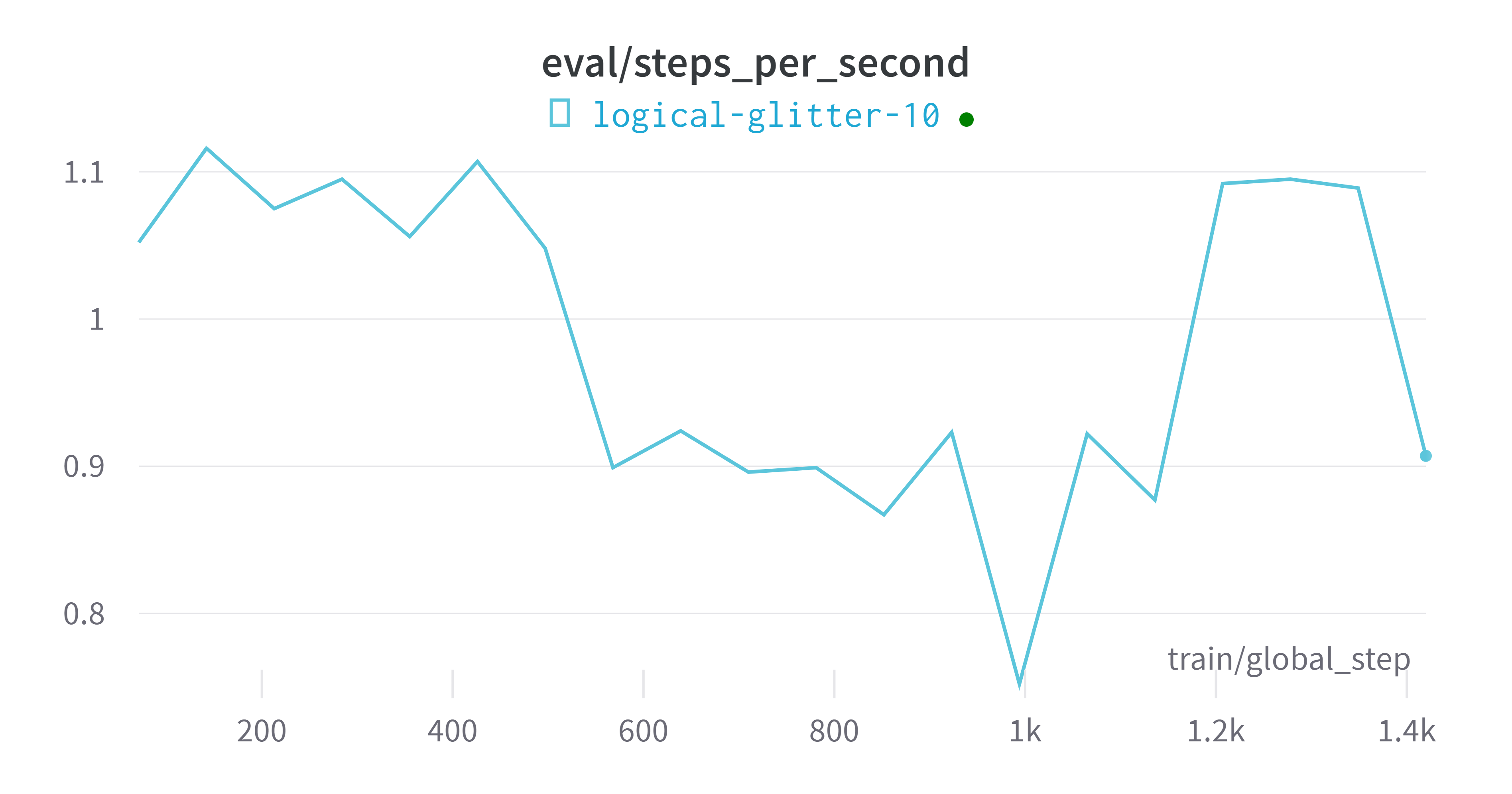
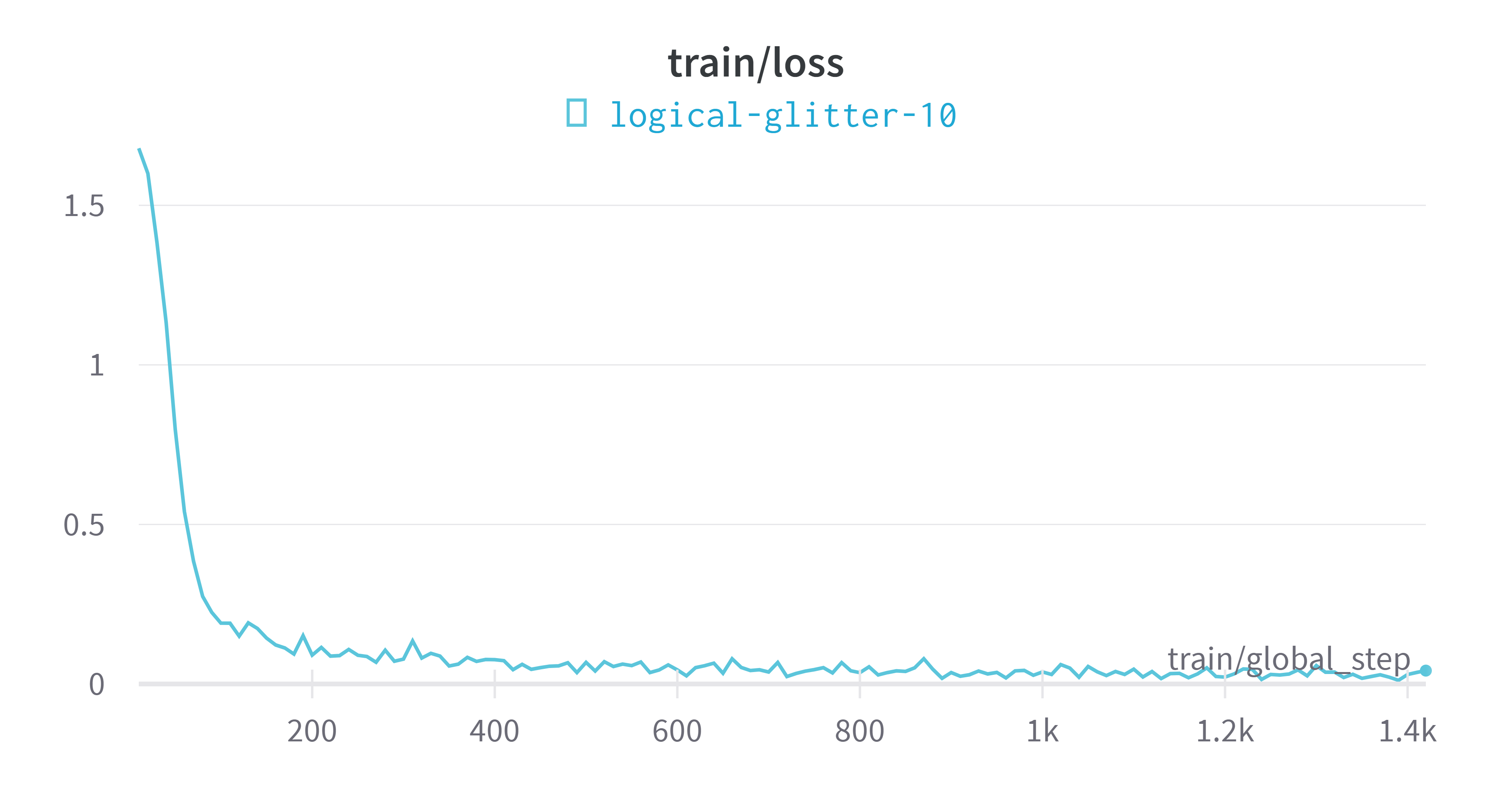
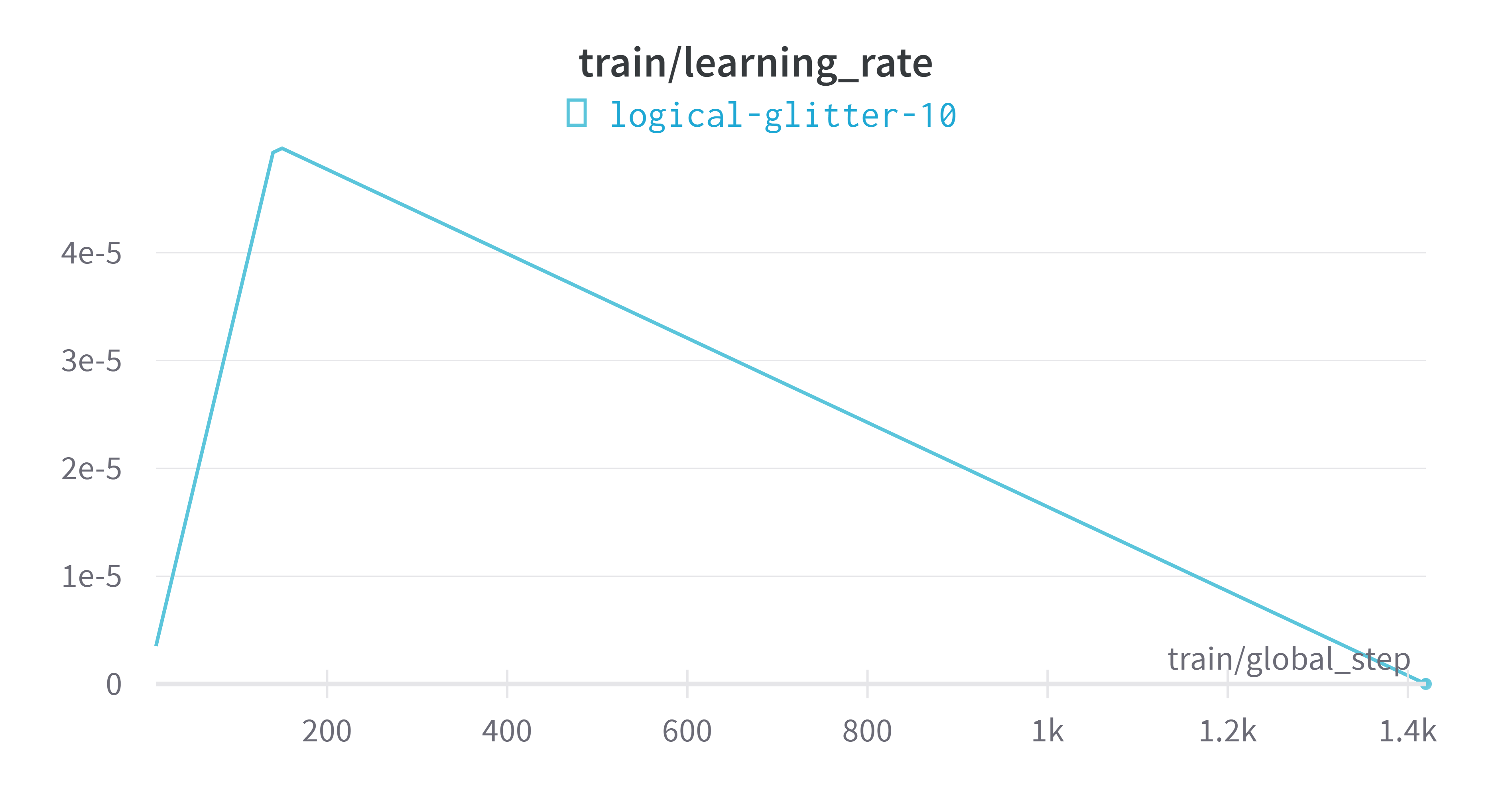
modelo de evaluación
metrics = trainer.evaluate()
# some nice to haves:
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
producción:
***** eval metrics *****
epoch = 20.0
eval_accuracy = 0.984
eval_loss = 0.054
eval_runtime = 0:00:11.18
eval_samples_per_second = 44.689
eval_steps_per_second = 0.715