recolectar
que es coleccion
Una colección es un contenedor para almacenar datos y solo puede almacenar tipos de referencia, por lo que una colección es muy adecuada para almacenar objetos. Y la colección tiene una longitud variable, por lo que es adecuado usar la colección cuando el número de objetos es incierto.
Características de la colección
1. Las colecciones solo pueden almacenar tipos de datos de referencia. Las colecciones se utilizan para almacenar objetos.
2. Se pueden usar matrices si se determina el número de objetos, y se pueden usar colecciones si el número de objetos es incierto. Porque las colecciones son de longitud variable.
La diferencia entre colecciones y arreglos
1. Los arreglos son de longitud fija, las colecciones son de longitud variable.
2. Los arreglos pueden almacenar tipos de datos básicos así como tipos de datos de referencia, las colecciones solo pueden almacenar tipos de datos de referencia.
3. Los elementos almacenados en la matriz deben ser del mismo tipo de datos, los objetos almacenados en la colección pueden ser de diferentes tipos de datos.
Beneficios de usar el marco de colecciones
- Reduce el trabajo de desarrollo, proporciona casi todos los tipos comunes de colecciones y métodos útiles para iterar y manipular datos, por lo que podemos centrarnos más en la lógica comercial en lugar de diseñar nuestra API de colección.
- Mejorar la calidad del código, el uso de clases de colección central bien probadas puede mejorar la calidad de nuestros programas, mejorar la solidez y la usabilidad del código.
- Reutilización e interoperabilidad
- Reduzca los costos de mantenimiento Al usar las clases de colección que vienen con el JDK, puede reducir los costos de mantenimiento del código
Sao Dai entiende: De hecho, las ventajas anteriores se deben al hecho de que si usamos la colección que viene con jdk, nuestra codificación será más estandarizada, como la colección ArrayList, que es una colección unificada y estandarizada que viene con jdk. , por lo que el método de esta colección, específicamente El uso es el mismo sin importar dónde, pero si cada uno de nosotros diseña su propia colección, en primer lugar, tomará mucho tiempo, y en segundo lugar, los nombres de método de las colecciones diseñadas por cada persona puede ser diferente, por lo que puede usarlo usted mismo, si otros también Si usa esto, debe ver cuál es la función de su nombre de método. Si él también escribe una colección como la suya y define un nombre de método diferente, será muy desordenado, así que use el que viene con jdk La colección será unificada y estandarizada, no tan desordenada como la anterior
¿Cuáles son las clases de colección comúnmente utilizadas?

La interfaz de mapa y la interfaz de colección son las interfaces principales de todos los marcos de colección:
Las subinterfaces de la colección Collection tienen tres subinterfaces: Set, List y Queue
Las clases de implementación de la interfaz Set incluyen principalmente: HashSet, TreeSet, LinkedHashSet, etc.
Las clases de implementación de la interfaz List incluyen principalmente: ArrayList, LinkedList, Stack y Vector, etc.
Las clases de implementación de la interfaz Queue incluyen principalmente: BlockingQueue, Deque, etc.
Las clases de implementación de la interfaz Map incluyen principalmente: HashMap, TreeMap, Hashtable, ConcurrentHashMap, etc.
Entendimiento de Sao Dai: tenga en cuenta que no hay TreeList
La estructura de datos subyacente del marco de recopilación
Colección colección tiene principalmente dos interfaces: Lista y Conjunto
1, lista
ArrayList : ArrayList se implementa en función de una matriz y su estructura de datos subyacente es una matriz mutable. Al insertar elementos, si la matriz está llena, debe expandirse. La forma de expandirse es crear una nueva matriz, copiar los elementos de la matriz original en la nueva matriz y luego insertar los nuevos elementos en la nueva matriz.
LinkedList : LinkedList se implementa en función de una lista vinculada y su estructura de datos subyacente es una lista doblemente vinculada. Al insertar un elemento, solo necesita modificar el puntero correspondiente en la lista vinculada, y no necesita copiar y expandir la matriz como ArrayList.
Vector : Vector es una clase de implementación de lista segura para subprocesos. Su estructura de datos subyacente es similar a ArrayList, y también es una matriz mutable. La diferencia es que los métodos de Vector están todos sincronizados, por lo que se puede garantizar la seguridad de los subprocesos.
Stack : Stack se implementa en función de Vector, que es una estructura de datos de último en entrar, primero en salir (LIFO) que admite operaciones push y pop.
Sao Dai entiende: Vector y Stack son clases seguras para subprocesos
2, conjunto
HashSet (desordenado, único) : basado en HashMap, el constructor predeterminado es construir un HashMap con una capacidad inicial de 16 y un factor de carga de 0,75. Un objeto HashMap se encapsula para almacenar todos los elementos de la colección.Todos los elementos de la colección colocados en el HashSet en realidad se guardan con la clave del HashMap, y el valor del HashMap almacena un PRESENTE, que es un objeto Object estático.
LinkedHashSet: LinkedHashSet hereda HashSet, y su interior es a través de LinkedHashMap
conseguir. Es un poco similar al LinkedHashMap que dijimos antes, que se implementa internamente en base a Hashmap, pero todavía hay una pequeña diferencia.
TreeSet (ordenado, único): árbol rojo-negro (árbol binario ordenado equilibrado)
3, mapa
HashMap: antes de JDK1.8, HashMap se compone de matriz + lista vinculada. La matriz es el cuerpo principal de HashMap, y la lista vinculada existe principalmente para resolver conflictos hash ("método zip" para resolver conflictos). Después de JDK1.8, los conflictos hash se resuelven Cuando la longitud de la lista enlazada es mayor que el umbral (8 por defecto), la lista enlazada se convierte en un árbol rojo-negro para reducir el tiempo de búsqueda
LinkedHashMap: LinkedHashMap se hereda de HashMap, por lo que su capa inferior todavía se basa en la estructura hash de cremallera, que se compone de matrices y listas vinculadas o árboles rojo-negro. Además, sobre la base de la estructura anterior, LinkedHashMap agrega una lista doblemente enlazada para mantener el orden de inserción de los pares clave-valor. Al mismo tiempo, al realizar las operaciones correspondientes en la lista enlazada, se realiza la lógica relacionada con la secuencia de acceso.
HashTable : compuesta por matriz + lista vinculada, la matriz es el cuerpo principal de HashMap, y la lista vinculada existe principalmente para resolver conflictos hash
TreeMap : árbol rojo-negro (árbol binario ordenado con equilibrio automático)
ConcurrentHashMap: una implementación de tabla hash segura para subprocesos en Java, cuya estructura de datos subyacente es una tabla hash de bloqueo segmentada. Específicamente, divide toda la tabla hash en varios segmentos, cada segmento es una tabla hash independiente y cada segmento tiene su propio bloqueo, por lo que se puede lograr el acceso simultáneo de subprocesos múltiples, lo que mejora el rendimiento de la concurrencia.
El tamaño de cada segmento se puede configurar por parámetros, el valor predeterminado es 16. En ConcurrentHashMap, cada elemento se almacena en un objeto de entrada, que contiene clave, valor y un puntero a la siguiente entrada. Cada segmento contiene una matriz de Entrada, y cada elemento de la matriz es el nodo principal de una lista vinculada, y cada lista vinculada almacena elementos con el mismo valor hash.
Al realizar operaciones como insertar, buscar y eliminar, primero debe encontrar el segmento correspondiente de acuerdo con el valor hash de la clave y luego realizar operaciones en este segmento. Dado que cada segmento tiene su propio bloqueo, diferentes subprocesos pueden acceder a diferentes segmentos al mismo tiempo, lo que mejora el rendimiento de la concurrencia.
En resumen, ConcurrentHashMap es una implementación de tabla hash segura para subprocesos en Java. Utiliza una tabla hash de bloqueo segmentada como estructura de datos subyacente, que puede lograr un acceso simultáneo eficiente de subprocesos múltiples.
¿Qué clases de colección son seguras para subprocesos? ¿Qué clases de colección no son seguras para subprocesos?
¿Qué clases de colección son seguras para subprocesos?
- Vector: siempre que se trate de una operación crítica, la palabra clave sincronizada se agrega delante del método para garantizar la seguridad del subproceso
- Hashtable: se usa la palabra clave sincronizada, por lo que es seguro para subprocesos en comparación con Hashmap.
- ConcurrentHashMap: utiliza tecnología de segmentación de bloqueo para garantizar la seguridad lineal, es una colección eficiente pero segura para subprocesos.
- Stack: Stack, que también es seguro para subprocesos, hereda de Vector.
¿Qué clases de colección no son seguras para subprocesos?
- mapa hash
- Lista de arreglo
- Lista enlazada
- HashSet
- ÁrbolConjunto
- ÁrbolMapa
Razones de la inseguridad del subproceso
- Hashmap : durante la operación de colocación de HashMap, si el elemento insertado supera la capacidad (determinada por el factor de carga), se activará la operación de expansión, que es el cambio de tamaño, que volverá a convertir el contenido de la matriz original en la nueva expansión. matriz. En un entorno de subprocesos múltiples, otros elementos también realizan operaciones de colocación al mismo tiempo. Si el valor hash es el mismo, puede representarse mediante una lista vinculada debajo de la misma matriz al mismo tiempo, lo que da como resultado una matriz cerrada. bucle, lo que resulta en un bucle infinito al obtener, por lo que HashMap es un subproceso inseguro.
- Arraylist : cuando se agrega el objeto List, cuando se ejecuta Arrays.copyOf, se devuelve un nuevo objeto de matriz. Cuando los subprocesos A, B... ingresan al método de crecimiento al mismo tiempo, varios subprocesos ejecutarán el método Arrays.copyOf y devolverán múltiples objetos elementData diferentes. Si A regresa primero y B regresa después, entonces List.elementData ==A. elementData, si B también regresa al mismo tiempo, entonces List.elementData ==B.elementData, por lo que el subproceso B sobrescribe los datos del subproceso A, lo que hace que se pierdan los datos del subproceso A.
- LinkedList : similar al problema de seguridad de subprocesos de Arraylist, el problema de seguridad de subprocesos es causado por múltiples subprocesos que escriben o leen y escriben el mismo recurso al mismo tiempo.
- HashSet : la estructura de almacenamiento de datos subyacente adopta Hashmap, por lo que el problema de seguridad de subprocesos que generará Hashmap también ocurrirá en HashSet.
¿El mecanismo de falla rápida de la colección Java "falla rápido"?
¿Qué es el mecanismo de fallo rápido "fail-fast"?
El mecanismo de falla rápida, es decir, el mecanismo de falla rápida, es un mecanismo de detección de errores en la colección java (Colección).
Cuando varios subprocesos operan en el contenido de la misma colección, puede parecer que mientras un subproceso está iterando la colección, otro subproceso modifica el contenido de la colección, lo que generará un evento rápido y generará una ConcurrentModificationException Anormal, subproceso único También pueden ocurrir eventos de falla rápida.
Por ejemplo: cuando un subproceso A atraviesa una colección a través de un iterador, si el contenido de la colección es cambiado por otros subprocesos, entonces cuando el subproceso A accede a la colección, se lanzará una ConcurrentModificationException y se generará un evento de falla rápida. Pero debe tenerse en cuenta que el mecanismo de falla rápida no garantiza que se lanzará una excepción bajo la modificación asincrónica, solo hace todo lo posible para lanzarla, por lo que este mecanismo generalmente solo se usa para detectar errores.
La escena de aparición de fail-fast
El mecanismo de falla rápida puede aparecer en nuestras colecciones comunes de Java, como ArrayList y HashMap. La falla rápida es posible en entornos de subprocesos múltiples y de un solo subproceso.
a prueba de fallas en un entorno de un solo subproceso
public static void main(String[] args) {
List<String> list = new ArrayList<>();
for (int i = 0 ; i < 10 ; i++ ) {
list.add(i + "");
}
Iterator<String> iterator = list.iterator();
int i = 0 ;
while(iterator.hasNext()) {
if (i == 3) {
list.remove(3);
}
System.out.println(iterator.next());
i ++;
}
}Este fragmento de código define una colección de Arraylist y utiliza iteradores para recorrerla. Durante el proceso de recorrido, se elimina deliberadamente un elemento en un determinado paso de la iteración. En este momento, se producirá una falla rápida.

public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
for (int i = 0 ; i < 10 ; i ++ ) {
map.put(i+"", i+"");
}
Iterator<Entry<String, String>> it = map.entrySet().iterator();
int i = 0;
while (it.hasNext()) {
if (i == 3) {
map.remove(3+"");
}
Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
i++;
}
}Este fragmento de código define un objeto hashmap y almacena pares clave-valor de 10. Durante el proceso de recorrido iterativo, se elimina un elemento utilizando el método de eliminación del mapa, lo que genera una ConcurrentModificationException.

En un entorno de subprocesos múltiples
public class FailFastTest {
public static List<String> list = new ArrayList<>();
private static class MyThread1 extends Thread {
@Override
public void run() {
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String s = iterator.next();
System.out.println(this.getName() + ":" + s);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
super.run();
}
}
private static class MyThread2 extends Thread {
int i = 0;
@Override
public void run() {
while (i < 10) {
System.out.println("thread2:" + i);
if (i == 2) {
list.remove(i);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
i ++;
}
}
}
public static void main(String[] args) {
for(int i = 0 ; i < 10;i++){
list.add(i+"");
}
MyThread1 thread1 = new MyThread1();
MyThread2 thread2 = new MyThread2();
thread1.setName("thread1");
thread2.setName("thread2");
thread1.start();
thread2.start();
}
}Inicie dos subprocesos, un subproceso 1 itera la lista y el otro subproceso 2 elimina un elemento durante el proceso de iteración del subproceso 1, y el resultado también arroja java.util.ConcurrentModificationException

Lo anterior mencionado en el caso de una falla rápida causada por el cambio de estructura de la colección causado por la eliminación.Si la estructura de la colección cambia debido a la adición, también ocurrirá una falla rápida, por lo que no daré un ejemplo aquí.
Análisis del principio de implementación
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}Se puede ver que este método es la clave para juzgar si lanzar ConcurrentModificationException.
En este código, cuando modCount != ExpectedModCount, se lanzará la excepción. Pero al principio, el valor inicial de addedModCount es igual a modCount por defecto, ¿por qué aparece modCount != ExpectedModCount?
Es obvio que el valor ModCount esperado no se ha modificado en ninguna parte, excepto por el valor inicial modCount en todo el proceso de iteración, y es imposible cambiarlo, por lo que solo puede cambiar modCount. A continuación, echemos un vistazo a cuándo "modCount no es igual al ModCount esperado" a través del código fuente y veamos cómo se modifica modCount a través del código fuente de ArrayList.
package java.util;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
...
// list中容量变化时,对应的同步函数
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
// 添加元素到队列最后
public boolean add(E e) {
// 修改modCount
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 添加元素到指定的位置
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
// 修改modCount
ensureCapacity(size+1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
// 添加集合
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
// 修改modCount
ensureCapacity(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
// 删除指定位置的元素
public E remove(int index) {
RangeCheck(index);
// 修改modCount
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
// 快速删除指定位置的元素
private void fastRemove(int index) {
// 修改modCount
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
}
// 清空集合
public void clear() {
// 修改modCount
modCount++;
// Let gc do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
...
}Descubrimos que, ya sea add(), remove() o clear(), siempre que implique modificar la cantidad de elementos en la colección, el valor de modCount cambiará.
A continuación, analicemos sistemáticamente cómo se genera la falla rápida. Proceder de la siguiente:
1. Cree una nueva ArrayList llamada arrayList.
2. Agregue contenido a arrayList.
3. Cree un nuevo "hilo a" y lea repetidamente el valor de arrayList a través de Iterator en "hilo a".
4. Cree un nuevo "subproceso b" y elimine un "nodo A" en el arrayList en "subproceso b".
5. En este momento ocurrirán eventos interesantes.
- En algún momento, "thread a" crea un iterador de arrayList. En este punto, el "nodo A" todavía existe en arrayList, cuando se crea arrayList, se esperaModCount = modCount (asumiendo que su valor en este momento es N).
- En cierto punto en el proceso de "subproceso a" atravesando arrayList, se ejecuta "subproceso b" y "subproceso b" elimina "nodo A" en arrayList. Cuando "thread b" ejecuta remove() para eliminar, "modCount++" se ejecuta en remove(), ¡y modCount se convierte en N+1 en este momento!
- El subproceso a" luego atraviesa, cuando ejecuta la función next(), llama a checkForComodification() para comparar el tamaño de "expectedModCount" y "modCount"; y "expectedModCount=N", "modCount=N+1", entonces, throw Se lanza una ConcurrentModificationException y se genera un evento fail-fast.
¡Hasta ahora, hemos entendido completamente cómo se genera la falla rápida!
Resumen de los principios de implementación
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}Hay un método checkForComodification.Cuando varios subprocesos operan en la misma colección, el contenido de la colección es cambiado por otros subprocesos durante el proceso de acceso de un subproceso a la colección (otros subprocesos llaman a estos métodos a través de agregar, eliminar, borrar, etc.) modCount se incrementará automáticamente, es decir, modCount++), cambiando el valor de modCount, cuando modCount != ExpectedModCount (al principio, el valor inicial de addedModCount es igual a modCount por defecto), luego se lanzará una excepción ConcurrentModificationException, y se generará un evento de falla rápida.
Solución:
1. Durante el proceso transversal, se agrega sincronizado a todos los lugares que implican cambiar el valor de modCount.
1. Use CopyOnWriteArrayList para reemplazar ArrayList
¿Cómo asegurarse de que una colección no se puede modificar?
Puede usar el método Collections.unmodifiableCollection(Collection c) para crear una colección de solo lectura
En conjunto, cualquier operación que mute la colección generará una Java.lang.UnsupportedOperationException.
List list = new ArrayList<>();
list. add("x");
Collection clist = Collections. unmodifiableCollection(list);
clist. add("y"); // 运行时此行报错
System. out. println(list. size());¿La lista, el conjunto y el mapa heredan de la interfaz de la colección? ¿Cuál es la diferencia entre Lista, Conjunto y Mapa? ¿Cuáles son las características de cada una de las tres interfaces de List, Map y Set al acceder a los elementos?
1. ¿Se heredan List, Set y Map de la interfaz Collection?
Los contenedores de Java se dividen en dos categorías: Colección y Mapa. Las subinterfaces de Colección incluyen tres subinterfaces: Conjunto, Lista y Cola. Comúnmente usamos Set y List, y la interfaz Map no es una subinterfaz de la colección. Colección colección tiene principalmente dos interfaces: Lista y Conjunto
2. La diferencia entre Lista, Conjunto y Mapa
Lista : un contenedor ordenado (el orden en que se almacenan los elementos en la colección es el mismo que el orden en que se extraen), los elementos se pueden repetir, se pueden insertar varios elementos nulos y los elementos tienen índices.
Las clases de implementación comúnmente utilizadas de la interfaz List son ArrayList, LinkedList y Vector.
Conjunto : un contenedor no ordenado (el orden de almacenamiento y retiro puede ser inconsistente), que no puede almacenar elementos duplicados, solo permite almacenar un elemento nulo y se debe garantizar la unicidad de los elementos.
Las clases de implementación comunes de la interfaz Set son HashSet, LinkedHashSet y TreeSet.
Mapa: una colección de pares clave-valor que almacena el mapeo entre claves, valores y valores. La clave es desordenada y única, el valor no requiere orden y permite la duplicación. El mapa no se hereda de la interfaz de la colección. Al recuperar elementos de la colección de mapas, siempre que se proporcione el objeto clave, se devolverá el objeto de valor correspondiente.
Clases de implementación comunes de Map: HashMap, TreeMap, HashTable, LinkedHashMap, ConcurrentHashMap
3. ¿Cuáles son las características de cada una de las tres interfaces de List, Map y Set al acceder a los elementos?
Cuando se almacenan las tres interfaces de Lista, Mapa y Conjunto
- Lista almacena elementos con un índice específico (almacenamiento ordenado), y puede haber elementos repetidos
- Los elementos almacenados en Set están desordenados y no son repetibles (utilice el método equals() del objeto para distinguir si los elementos se repiten)
- Map guarda el mapeo de pares clave-valor. La relación de mapeo puede ser uno a uno (clave-valor) o muchos a uno. Cabe señalar que las claves están desordenadas y no se pueden repetir, y los valores se puede repetir.
Cuando se eliminan las tres interfaces de List, Map y Set
- La lista saca elementos para bucle, bucle foreach, iterador iterador iteración
- Conjunto saca elementos foreach loop, iterador iterador iteración
- Mapa saca elementos foreach loop, iterador iterador iteración
¿Cuáles son las formas de recorrer la colección de mapas?
Hay varias formas de recorrer la colección de mapas:
1. Utilice el iterador Iterator para recorrer la colección Map. Obtenga la colección Set devuelta por el método entrySet() de Map, luego obtenga el iterador Iterator a través del método iterator() de la colección Set y finalmente use el ciclo while para recorrer los elementos en la colección Map. El código de ejemplo es el siguiente:
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
System.out.println(entry.getKey() + " : " + entry.getValue());
}
2. Utilice el bucle for-each para recorrer la colección Map. Obteniendo la colección Set devuelta por el método entrySet() de Map y luego recorriendo los elementos de la colección Set a través del bucle for-each. El código de ejemplo es el siguiente:
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
3. Recorrer las claves o valores de la colección Map. Obtenga la colección Set devuelta por el método keySet() de Map, o la colección Collection devuelta por el método values() y, a continuación, recorra los elementos de la colección Set o Collection a través del bucle for-each. El código de ejemplo es el siguiente:
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
for (String key : map.keySet()) {
System.out.println(key + " : " + map.get(key));
}
for (Integer value : map.values()) {
System.out.println(value);
}
En resumen, hay muchas formas de recorrer la colección de mapas y debe elegir la forma adecuada según sus necesidades y escenarios específicos.
¿La diferencia entre comparable y comparador?
¿La diferencia entre comparable y comparador?
- La interfaz comparable es en realidad del paquete java.lang, que tiene un método compareTo(Object obj) para ordenar, y la interfaz de comparación es en realidad del paquete java.util, que tiene un método compare(Object obj1, Object obj2) para clasificación
- Comparable es una interfaz de clasificación. Si una clase implementa la interfaz Comparable, significa que "esta clase admite la clasificación". El Comparator es un comparador, que implementa esta interfaz a través de una clase para ordenar como comparador.
- Comparable es equivalente a "comparador interno", y Comparador es equivalente a "comparador externo".
respectivas ventajas y desventajas
- Comparable es simple de usar, siempre que el objeto que implementa la interfaz Comparable se convierta directamente en un objeto comparable, pero el código fuente debe modificarse.
- La ventaja de usar Comparator es que no necesita modificar el código fuente, sino implementar un comparador por separado. Cuando se necesita comparar un objeto personalizado, puede comparar el tamaño pasando el comparador y el objeto juntos, y en el Comparador Los usuarios pueden implementar una lógica compleja y de uso general por sí mismos, de modo que pueda coincidir con algunos objetos relativamente simples, lo que puede ahorrar mucho trabajo repetitivo.
Introducción y ejemplos de comparable y comparador
Comparable
Comparable es una interfaz de clasificación. Si una clase implementa la interfaz Comparable, significa que la clase admite la clasificación. Las listas o matrices de objetos de clases que implementan la interfaz Comparable se pueden ordenar automáticamente mediante Collections.sort o Arrays.sort. Además, los objetos que implementan esta interfaz se pueden usar como claves en un mapa ordenado o como colecciones en un conjunto ordenado sin especificar un comparador. La interfaz se define de la siguiente manera:
package java.lang;
import java.util.*;
public interface Comparable<T>
{
public int compareTo(T o);
}Esta interfaz tiene un solo método, compareTo, que compara el orden de este objeto con el objeto especificado y devuelve un entero negativo, cero o un entero positivo si el objeto es menor, igual o mayor que el objeto especificado.
Ahora que hay dos objetos de la clase Person, ¿cómo comparamos el tamaño de los dos? Podemos hacer esto haciendo que Person implemente la interfaz Comparable:
public class Person implements Comparable<Person>
{
String name;
int age;
public Person(String name, int age)
{
super();
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
@Override
public int compareTo(Person p)
{
return this.age-p.getAge();
}
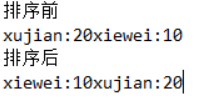
public static void main(String[] args)
{
Person[] people=new Person[]{new Person("xujian", 20),new Person("xiewei", 10)};
System.out.println("排序前");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
Arrays.sort(people);
System.out.println("\n排序后");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
}
}Resultados de la

comparador
Comparator es una interfaz de comparación. Si necesitamos controlar el orden de una determinada clase, y la clase en sí no admite la clasificación (es decir, no implementa la interfaz Comparable), entonces podemos crear un "comparador de esta clase". para ordenar. dispositivo" solo necesita implementar la interfaz Comparator. En otras palabras, podemos crear un nuevo comparador implementando Comparator y luego ordenar las clases a través de este comparador. La interfaz se define de la siguiente manera:
package java.util;
public interface Comparator<T>
{
int compare(T o1, T o2);
boolean equals(Object obj);
}Aviso
1. Si una clase quiere implementar la interfaz Comparator: debe implementar la función compare(T o1, To2), pero no necesita implementar la función equals(Object obj).
2. int compare(T o1, T o2) es "comparar el tamaño de o1 y o2". Devuelve "negativo", lo que significa que "o1 es menor que o2"; devuelve "cero", lo que significa que "o1 es igual a o2"; devuelve "positivo", lo que significa que "o1 es mayor que o2".
Ahora bien, si la clase Person anterior no implementa la interfaz Comparable, ¿cómo comparar el tamaño? Podemos crear una nueva clase y dejar que implemente la interfaz Comparator para construir un "comparador".
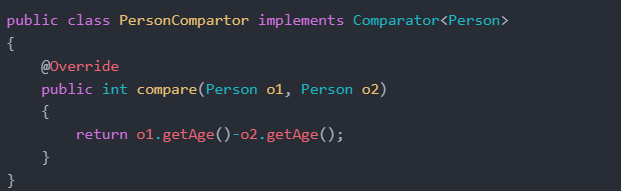
public class PersonCompartor implements Comparator<Person>
{
@Override
public int compare(Person o1, Person o2)
{
return o1.getAge()-o2.getAge();
}
}
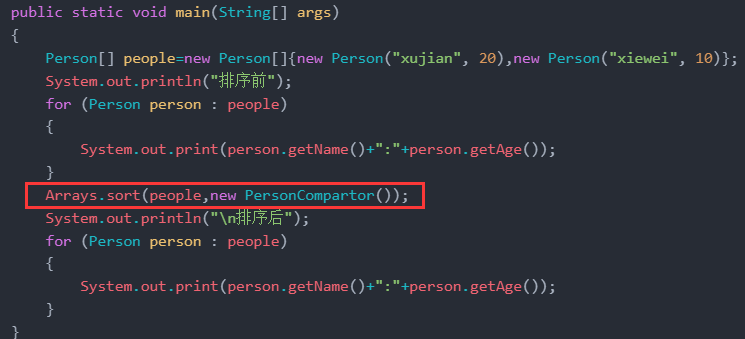
public class Person
{
String name;
int age;
public Person(String name, int age)
{
super();
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public static void main(String[] args)
{
Person[] people=new Person[]{new Person("xujian", 20),new Person("xiewei", 10)};
System.out.println("排序前");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
Arrays.sort(people,new PersonCompartor());
System.out.println("\n排序后");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
}
}Resultados de la
¿Cuál es la diferencia entre Collectiony Collections?
Colección y Colecciones son dos conceptos diferentes en el marco de colección de Java.
1. La colección es una interfaz en el marco de colección de Java. Es la interfaz raíz de todas las clases de colección y proporciona algunos métodos comunes, como agregar, eliminar, atravesar, etc.
2. Colecciones es una clase de herramienta en el marco de colección de Java, que proporciona una serie de métodos estáticos para operaciones en colecciones, como ordenar, buscar, reemplazar, copiar, invertir, etc.
En resumen, Collection es una interfaz que representa las características y comportamientos básicos de las clases de colección, y Collections es una clase de herramienta que proporciona métodos para operar colecciones.
¿Cuáles son los métodos comúnmente utilizados de colecciones?
Colecciones es una clase de herramienta en el marco de colección de Java, que proporciona una serie de métodos de operación de colección de uso común, que incluyen ordenar, buscar, reemplazar, copiar, invertir, etc. Los métodos de cobranza comúnmente utilizados incluyen:
1. sort(List<T> list): ordena la colección List y las reglas de clasificación son de orden natural (de menor a mayor).
2. sort(List<T> list, Comparator<? super T> c): ordena la colección List y comparator especifica las reglas de clasificación.
3. binarySearch(List<? extends Comparable<? super T>> list, T key): busca el elemento especificado en la colección List ordenada y devuelve el valor de índice del elemento.
4. binarySearch(List<? extends T> list, T key, Comparator<? super T> c): busca el elemento especificado en la colección List ordenada, devuelve el valor de índice del elemento y la regla de búsqueda se especifica mediante el Comparador.
5. reverse(List<?> list): Invierte los elementos en la colección List.
6. barajar (lista <?> lista): baraja aleatoriamente el orden de los elementos en la colección de la lista.
7. swap(List<?> list, int i, int j): Intercambia dos elementos en la posición especificada en la colección List.
8. fill(List<? super T> list, T obj): reemplaza todos los elementos de la colección List con el elemento especificado.
9. copy(List<? super T> dest, List<? extends T> src): copia los elementos de la colección src a la colección dest.
10. max(Collection<? extends T> coll): Devuelve el elemento más grande de la colección Collection.
11. min(Collection<? extends T> coll): Devuelve el elemento más pequeño de la colección Collection.
iterador iterador
¿Qué es iterador iterador?
Iterator (Iterador) es una interfaz en el marco de colección de Java , que se utiliza para atravesar los elementos de la colección. Los iteradores proporcionan un método de recorrido general que puede atravesar cualquier tipo de colección, incluidas listas, conjuntos, mapas, etc. Puede realizar el recorrido unidireccional de la colección, es decir, solo puede atravesar de adelante hacia atrás, no hacia atrás. Durante el recorrido, los elementos de la colección se pueden eliminar, pero los elementos de la colección no se pueden modificar.
¿Cómo usar el iterador?
(1) Iterator() requiere que el contenedor devuelva un iterador. El iterador estará listo para devolver el primer elemento de la secuencia.
(2) Use next() para obtener el siguiente elemento en la secuencia
(3) Use hasNext() para verificar si hay más elementos en la secuencia.
(4) Use remove() para eliminar el objeto devuelto por el último método Iterator.next().
List list = new ArrayList<>();
Iterator iterator = list.iterator();//list集合实现了Iterable接口
while (iterator.hasNext()) {
String string = iterator.next();
//do something
}¿Cuáles son las ventajas de Iterator?
Iterator (Iterator) es una interfaz importante en el marco de colección de Java, que tiene las siguientes ventajas:
1. Versatilidad fuerte: el iterador proporciona un método de recorrido general, que puede recorrer cualquier tipo de colección, incluyendo Lista, Conjunto, Mapa, etc.
2. Facilidad de uso: es muy simple usar un iterador para recorrer una colección. Solo necesita llamar al método Iterator, como hasNext(), next(), remove(), etc., para completar el recorrido.
3. Seguro y confiable: el uso de iteradores para atravesar colecciones puede garantizar la seguridad de los subprocesos y evitar problemas de acceso simultáneo en entornos de subprocesos múltiples.
4. Compatibilidad con operaciones de eliminación: use iteradores para recorrer la colección y eliminar fácilmente elementos de la colección sin tener en cuenta el cambio de índice después de eliminar los elementos.
5. Rendimiento eficiente: el rendimiento del uso de iteradores para atravesar colecciones es muy eficiente, especialmente para colecciones grandes, lo que puede evitar el problema de cargar todos los elementos a la vez.
¿Cuáles son las características de Iterator?
Iterator es una interfaz en el marco de colección de Java, que se utiliza para recorrer los elementos de la colección. Sus características son las siguientes:
1. Puede recorrer cualquier tipo de colección, incluida Lista, Conjunto, Mapa, etc.
2. Se puede realizar un recorrido unidireccional de la colección, es decir, solo se puede recorrer de adelante hacia atrás, no hacia atrás.
3. Los elementos de la colección se pueden eliminar durante el proceso transversal, pero los elementos de la colección no se pueden modificar; de lo contrario, se lanzará una excepción ConcurrentModificationEception.
4. Los genéricos se pueden utilizar para evitar el problema de la conversión de tipo.
5. El iterador debe existir adjunto a un objeto de colección, y el propio iterador no tiene la función de cargar objetos de datos.
¿Cómo eliminar elementos en la Colección mientras se atraviesa?
La única forma correcta de eliminar una colección mientras se atraviesa es usar el método Iterator.remove(), de la siguiente manera:
List list = new ArrayList<>();
Iterator<Integer> it = list.iterator();
//正确的移除方法
while(it.hasNext()){
//设置移除元素的条件
it.remove();
}
//一种最常见的错误代码如下
for(Integer i : list){
list.remove(i);//报 ConcurrentModificationException 异常
}Sao Dai entiende: es decir, solo se puede eliminar a través del método de eliminación de la instancia del iterador, pero no a través del método de eliminación de la colección en sí. Si se usa el método de eliminación de la colección en sí, el mecanismo de falla rápida será desencadenado para generar una excepción ConcurrentModificationException, porque un subproceso no puede modificar la colección mientras otro subproceso lo atraviesa.
¿Cuál es la diferencia entre Iterator y ListIterator?
Tanto Iterator como ListIterator son interfaces en el marco de la colección de Java, que se utilizan para atravesar los elementos de la colección. Sus principales diferencias son las siguientes:
1. Diferentes direcciones de recorrido: Iterator solo puede recorrer los elementos de la colección hacia adelante, mientras que ListIterator puede recorrer los elementos de la colección hacia adelante o hacia atrás.
2. La compatibilidad con las operaciones de elementos es diferente: Iterator solo puede recorrer los elementos de la colección y no puede realizar operaciones como agregar y modificar, mientras que ListIterator puede agregar, modificar y eliminar elementos de la colección durante el proceso de recorrido.
3. Diferentes métodos de soporte: ListIterator tiene más métodos que Iterator, como previous(), hasPrevious(), add(), set(), etc., que se utilizan para avanzar, agregar elementos, modificar elementos, etc. durante el proceso transversal.
4. Los tipos de colecciones admitidas son diferentes: Iterator puede atravesar cualquier tipo de colección, incluidos List, Set, Map, etc., mientras que ListIterator solo puede atravesar colecciones de tipo List.
Sao Dai entiende: si necesita recorrer la colección List y admitir operaciones de elementos, debe usar ListIterator; si solo necesita recorrer los elementos de la colección, puede usar Iterator.
¿Cuáles son las diferentes formas de iterar sobre una lista? ¿Cuál es el principio de implementación de cada método?
Hay varias formas diferentes de iterar sobre una colección de listas:
1. para recorrido de bucle
Use el bucle for para recorrer la colección List y puede usar el subíndice para acceder a los elementos de la colección. El principio de realización es recorrer la colección List a través de la variable de control de bucle y acceder a los elementos de la colección a través del subíndice.
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
for (int i = 0; i < list.size(); i++) {
String element = list.get(i);
System.out.println(element);
}
Explique el principio
El principio de implementación del bucle for que atraviesa la colección List es atravesar la colección List a través de la variable de control de bucle y acceder a los elementos de la colección a través de subíndices.
La sintaxis del bucle for es la siguiente:
for (初始化表达式; 布尔表达式; 更新表达式) {
// 循环体
}
Donde, la expresión de inicialización se usa para inicializar la variable de control de bucle, la expresión booleana se usa para juzgar si el bucle continúa ejecutándose y la expresión de actualización se usa para actualizar el valor de la variable de control de bucle.
Cuando el ciclo for atraviesa la colección List, la expresión de inicialización generalmente inicializa la variable de control de ciclo a 0, la expresión booleana generalmente juzga si la variable de control de ciclo es más pequeña que la longitud de la colección List y la expresión de actualización generalmente agrega 1 a la variable de control de bucle. En el cuerpo del bucle, se puede acceder a los elementos de la colección List a través de subíndices para realizar la función de atravesar la colección List.
2. recorrido del bucle foreach
Use el bucle foreach para recorrer la colección List, puede acceder directamente a los elementos de la colección. El principio de implementación del recorrido de bucle foreach es recorrer cada elemento de la colección List, obtener automáticamente el valor del elemento y asignarlo a la variable de bucle, y luego ejecutar la instrucción en el cuerpo del bucle.
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
for (String element : list) {
System.out.println(element);
}Explique el principio
Específicamente, el ciclo foreach primero obtiene el iterador de la colección List y luego usa el iterador para recorrer cada elemento de la colección. Durante el proceso transversal, la variable de bucle obtendrá automáticamente el valor del elemento y lo asignará a la variable de bucle. Luego, ejecute las declaraciones en el cuerpo del bucle para completar la operación transversal en la colección List.
En comparación con el bucle for que recorre la colección List, la sintaxis del bucle foreach que recorre la colección List es más concisa. No necesita usar explícitamente el subíndice para acceder a los elementos de la colección y puede acceder directamente a la variable del elemento. Por lo tanto, el bucle foreach es más fácil de entender y usar, y es una de las formas comunes de recorrer la colección List.
3. Recorrido del iterador
Use el iterador para recorrer la colección List, puede recorrer cualquier tipo de colección, incluida List, Set, Map, etc. El principio de realización es recorrer los elementos de la colección obteniendo el iterador de la colección List y usando los métodos hasNext() y next().
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}4. Recorrido de ListIterator
Use ListIterator para recorrer la colección List, puede recorrer los elementos de la colección hacia adelante o hacia atrás y admitir operaciones de elementos. El principio de implementación es recorrer los elementos de la colección obteniendo el ListIterator de la colección List y usando métodos como hasNext(), next(), hasPrevious(), previous(), add() y set().
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
ListIterator<String> iterator = list.listIterator();
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}¿Cuáles son los escenarios de uso de varios métodos transversales de recopilación?
Varios métodos transversales de colecciones son aplicables a varios escenarios, de la siguiente manera:
1. For loop traversal: es adecuado para ocasiones en las que es necesario acceder a los elementos de la colección de acuerdo con el subíndice del elemento (como la colección List), por ejemplo, cuando los elementos de la colección deben modificarse o eliminado
2. Recorrido de bucle Foreach: es adecuado para ocasiones en las que solo es necesario acceder a los elementos de la colección y no es necesario acceder de acuerdo con el subíndice del elemento, por ejemplo, cuando solo es necesario leer los elementos de la colección. .
3. Recorrido del iterador: es adecuado para ocasiones en las que es necesario modificar o eliminar los elementos de la colección, porque cuando se utiliza el iterador para recorrer la colección, los elementos de la colección se pueden eliminar a través del método remove() del iterador
4. Recorrido de expresiones lambda: es adecuado para ocasiones que requieren un procesamiento funcional de los elementos de la colección, como filtrado, mapeo, clasificación y otras operaciones en los elementos de la colección.
¿Análisis de rendimiento de varios métodos transversales de la colección?
Al recorrer una colección, los diferentes métodos de recorrido tienen diferentes rendimientos, y la clasificación de rendimiento específica depende de varios factores, como el tipo, el tamaño y el tipo de elemento de la colección. La siguiente es la clasificación de rendimiento de varios métodos transversales en general:
1. For loop traversal: el rendimiento es el mejor, porque el uso de subíndices para acceder a los elementos de la colección es más rápido.
2. Recorrido del iterador: el rendimiento es el segundo, porque el iterador puede acceder directamente a los elementos de la colección, evitando la sobrecarga de calcular subíndices cada vez.
3. Recorrido del bucle Foreach: el rendimiento es deficiente, porque al usar el bucle foreach para recorrer la colección, primero debe obtener el iterador y luego usarlo para recorrer los elementos de la colección. En comparación con el uso directo de subíndices para acceder a la colección. elementos de la colección, la velocidad es más lenta.
4. Recorrido de expresiones lambda: el rendimiento es deficiente porque las expresiones lambda deben compilarse en objetos de función y se requiere un procesamiento funcional al recorrer la colección, que es más lento que acceder directamente a los elementos de la colección.
5. Recorrido de Stream API: el rendimiento es el peor, porque Stream API requiere múltiples operaciones, como filtrado, mapeo, clasificación, etc. Cada operación necesita crear un nuevo objeto, que es más lento que acceder directamente a los elementos de la colección. .
Cabe señalar que las clasificaciones de rendimiento anteriores son solo de referencia, y el rendimiento real puede verse afectado por varios factores, como el tamaño de la colección, el tipo de elemento, la cantidad de recorridos, etc. Por lo tanto, en el desarrollo real, es necesario seleccionar el método transversal óptimo de acuerdo con la situación específica. Al mismo tiempo, las herramientas de análisis de rendimiento también se pueden utilizar para evaluar el rendimiento de diferentes métodos transversales.
Lista de arreglo
Hable sobre las ventajas y desventajas de ArrayList
ArrayList es una implementación de matriz dinámica de uso común en Java, que tiene las siguientes ventajas y desventajas:
ventaja:
1. Velocidad de acceso aleatorio rápida: la capa inferior de ArrayList se implementa mediante una matriz, y se puede acceder directamente a los elementos de la matriz a través de subíndices, por lo que la velocidad de acceso aleatorio es rápida.
2. Velocidad de recorrido más rápida: ArrayList admite el recorrido rápido, porque su capa inferior es una matriz, que puede usar la memoria caché de la CPU para mejorar la velocidad de recorrido.
3. Puede almacenar tipos de datos básicos: ArrayList puede almacenar tipos de datos básicos y tipos de objetos, y se puede colocar y abrir automáticamente.
defecto:
1. El rendimiento de las operaciones de inserción y eliminación es deficiente: dado que la capa inferior de ArrayList está implementada por una matriz, al insertar y eliminar elementos, es necesario mover otros elementos, lo que genera un rendimiento deficiente.
2. No admite el acceso simultáneo de varios subprocesos: ArrayList no es seguro para subprocesos. Si varios subprocesos modifican ArrayList al mismo tiempo, puede causar inconsistencias en los datos o lanzar ConcurrentModificationException.
3. Desperdicio de espacio de memoria: ArrayList necesita especificar la capacidad inicial cuando se crea. Si la capacidad es insuficiente, debe expandirse y el espacio de memoria debe reasignarse durante la expansión, lo que puede conducir al desperdicio de espacio de memoria. .
Sao Dai entiende: ArrayList es adecuado para escenarios con más operaciones de modificación y acceso aleatorio, pero LinkedList puede ser más adecuado para escenarios con más operaciones de inserción y eliminación. Al mismo tiempo, en el escenario de acceso simultáneo de subprocesos múltiples, puede usar una implementación de lista segura para subprocesos, como Vector o CopyOnWriteArrayList.
¿Cómo realizar la conversión entre matriz y Lista?
Array to List: use Arrays.asList(array) para convertir.
List to array: usa el método toArray() que viene con List.
// List 转数组
List list = new ArrayList();
list.add("123");
list.add("456");
list.toArray();
// 数组转 List
listString[] array = new String[]{"123","456"};
Arrays.asList(array);¿Cuál es la diferencia entre ArrayList y LinkedList?
Tanto ArrayList como LinkedList son implementaciones de listas de uso común en Java, y sus diferencias se reflejan principalmente en los siguientes aspectos:
1. Los métodos de implementación subyacentes son diferentes: el ArrayList subyacente se implementa usando una matriz, mientras que el LinkedList subyacente se implementa usando una lista doblemente enlazada.
2. El acceso aleatorio y el rendimiento transversal son diferentes: ArrayList admite acceso aleatorio rápido y transversal porque la capa inferior está implementada por una matriz y puede usar la memoria caché de la CPU para mejorar la velocidad de acceso; la velocidad transversal de LinkedList es más lenta porque necesita atravesar cada nodo desde el nodo principal y no puede aprovechar la memoria caché de la CPU para mejorar la velocidad de acceso.
3. El rendimiento de las operaciones de inserción y eliminación es diferente: debido a que la capa inferior de ArrayList está implementada por una matriz, es necesario mover otros elementos al insertar y eliminar elementos, lo que resulta en un bajo rendimiento, mientras que el rendimiento de las operaciones de inserción y eliminación de LinkedList es mejor, porque solo los elementos relevantes necesitan ser modificados.punteros a nodos vecinos.
4. Ocupación de espacio de memoria diferente: LinkedList ocupa más memoria que ArrayList, porque los nodos LinkedList almacenan dos referencias además de almacenar datos, una que apunta al elemento anterior y otra que apunta al siguiente elemento. ArrayList se implementa mediante una matriz, y cada elemento solo necesita almacenar los datos, por lo que el espacio de memoria ocupado es relativamente pequeño. Cada nodo de LinkedList necesita almacenar dos punteros adicionales, por lo que al almacenar una gran cantidad de elementos, puede causar una gran huella de memoria. El ArrayList debe especificar la capacidad inicial cuando se crea. Si la capacidad es insuficiente, debe expandirse y el espacio de memoria debe reasignarse durante la expansión, lo que puede provocar el desperdicio de espacio de memoria.
Sao Dai entiende: ArrayList es adecuado para escenarios con más operaciones de modificación y acceso aleatorio, pero LinkedList puede ser más adecuado para escenarios con más operaciones de inserción y eliminación.
Lista doblemente enlazada
Una lista doblemente enlazada también se denomina lista doblemente enlazada, que es un tipo de lista enlazada.Cada nodo de datos tiene dos punteros, que apuntan al sucesor directo y al predecesor directo respectivamente. Por lo tanto, comenzando desde cualquier nodo en la lista doblemente enlazada, puede acceder fácilmente a su nodo predecesor y nodo sucesor.
¿Cuál es la diferencia entre ArrayList y Vector?
Ambas clases implementan la interfaz List (la interfaz List hereda la interfaz Collection) y ambas son colecciones ordenadas.
1. Seguridad de subprocesos: Vector utiliza Synchronized para lograr la sincronización de subprocesos, que es segura para subprocesos, mientras que ArrayList no lo es.
2. Rendimiento: ArrayList es mejor que Vector en términos de rendimiento. Todos los métodos de la clase Vector son síncronos. Dos subprocesos pueden acceder de forma segura a un objeto Vector, pero si un subproceso accede al Vector, el código dedicará mucho tiempo a las operaciones de sincronización.
3. Expansión: cuando se necesita expandir ArrayList, creará una nueva matriz y copiará los elementos de la matriz original a la nueva matriz. El tamaño de la nueva matriz es 1,5 veces mayor que la matriz original. Cuando Vector se expande, se creará una nueva matriz y los elementos de la matriz original se copiarán en la nueva matriz, y el tamaño de la nueva matriz será el doble del tamaño de la matriz original. Por lo tanto, la expansión de Vector consume más memoria que ArrayList, pero en términos relativos, el rendimiento de Vector es más estable porque sus tiempos de expansión son relativamente pequeños.
Sao Dai entiende: Vector es seguro para subprocesos, pero ArrayList no es seguro para subprocesos. Si necesita usar ArrayList en un entorno de subprocesos múltiples, debe realizar la sincronización.
Al insertar datos, ¿cuál es más rápido, ArrayList, LinkedList o Vector?
Al insertar datos, LinkedList es relativamente rápido porque su capa inferior es una estructura de lista enlazada. Insertar un elemento solo necesita modificar el puntero del nodo adyacente, y la complejidad de tiempo es O (1). La capa inferior de ArrayList y Vector es una estructura de matriz, la inserción de un elemento necesita mover el siguiente elemento un bit hacia atrás y la complejidad de tiempo es O(n), donde n es la longitud de la matriz. Por lo tanto, LinkedList funciona mejor que ArrayList y Vector al insertar datos. Debido a que los métodos en Vector se modifican con sincronizados, Vector es un contenedor seguro para subprocesos y su rendimiento es peor que el de ArrayList.
La velocidad de inserción es de clasificación rápida a lenta: LinkedList>ArrayList>Vector
¿Cómo usar ArrayList en un escenario de subprocesos múltiples?
ArrayList no es seguro para subprocesos. Si se encuentra con un escenario de varios subprocesos, puede usar el métodosynchronedList de Collections para convertirlo en uno seguro para subprocesos antes de usarlo.
List<String> list = new ArrayList<>();
List<String> synchronizedList = Collections.synchronizedList(list);
synchronizedList.add("aaa");
synchronizedList.add("bbb");
for(int i =0; i < synchronizedList.size(); i++){
System.out.println(synchronizedList.get(i));
}¿Por qué elementData de ArrayList está decorado con transitorios?
¿Por qué elementData de ArrayList está decorado con transitorios?
En ArrayList, elementData se modifica en transitorio para ahorrar espacio. El mecanismo de expansión automática de ArrayList, la matriz elementData es equivalente al contenedor. Cuando el contenedor es insuficiente, la capacidad se expandirá, pero la capacidad del contenedor suele ser mayor que o igual al número de elementos almacenados en el ArrayList. . Entonces, el diseñador de ArrayList diseñó elementData como transitorio para que esta matriz no se serializara, y luego la serializó manualmente en el método writeObject, y solo serializó aquellos elementos que realmente estaban almacenados, no toda la matriz elementData.
Por ejemplo, ahora que en realidad hay 8 elementos, la capacidad de la matriz elementData puede ser 8x1,5 = 12. Si la matriz elementData se serializa directamente, se desperdiciará el espacio de 4 elementos, especialmente cuando la cantidad de elementos es muy alta. grande Este tipo de residuos es muy antieconómico.
Definición de serialización y deserialización
La serialización de Java se refiere al proceso de convertir objetos de Java en secuencias de bytes.
La deserialización de Java hace referencia al proceso de restauración de una secuencia de bytes en un objeto de Java.
palabra clave transitoria
Las variables miembro modificadas por transitorios no se serializarán.
análisis de código
Los arreglos en ArrayList se definen de la siguiente manera:
objeto transitorio privado [] elementData;
Mire la definición de ArrayList nuevamente:
clase pública ArrayList<E>extiende AbstractList<E>implementsList<E>, RandomAccess, Cloneable, java.io.Serializable
Puede ver que ArrayList implementa la interfaz Serializable, lo que significa que ArrayList admite la serialización.
El papel del transitorio es esperar que la matriz elementData no se serialice.
Anule la implementación de writeObject:
private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException{
int expectedModCount = modCount;
s.defaultWriteObject();
s.writeInt(elementData.length);
for(int i=0; i<size; i++)
s.writeObject(elementData[i]);
if(modCount != expectedModCount){
thrownewConcurrentModificationException();
}
}Entendimiento de Sao Dai: a partir del código fuente, se puede observar que i<size se usa en lugar de i<elementData.length cuando se realiza un bucle, lo que indica que solo los elementos realmente almacenados son necesarios para la serialización, no la matriz completa.
¿Cuál es la diferencia entre Array (matriz) y ArrayList?
- Array puede almacenar tipos de datos básicos y tipos de referencia, y ArrayList solo puede almacenar tipos de referencia.
- Array se especifica con un tamaño fijo, mientras que el tamaño de ArrayList se expande automáticamente.
- No hay tantos métodos integrados en Array como en ArrayList, como addAll, removeAll, iteración y otros métodos solo en ArrayList.
- Los elementos almacenados en la matriz Array deben ser del mismo tipo de datos; los objetos almacenados en ArrayList pueden ser de diferentes tipos de datos.
¿Qué es CopyOnWriteArrayList y para qué escenarios de aplicación se puede utilizar? ¿Cuáles son los pros y los contras?
¿Qué es CopyOnWrite?
Un contenedor CopyOnWrite es un contenedor de copia en escritura. El entendimiento popular es que cuando agregamos elementos a un contenedor, no lo agregamos directamente al contenedor actual, sino que primero copiamos el contenedor actual para crear un nuevo contenedor y luego agregamos elementos al nuevo contenedor. señalar la referencia del contenedor original al nuevo contenedor. La ventaja de esto es que podemos realizar lecturas simultáneas en el contenedor CopyOnWrite sin bloquear, porque el contenedor actual no agregará ningún elemento. Entonces, el contenedor CopyOnWrite también es una idea de separación de lectura y escritura, lectura y escritura de diferentes contenedores.
¿Qué es CopyOnWriteArrayList?
CopyOnWriteArrayList es una colección segura para subprocesos. Su implementación es crear una nueva matriz durante la operación de escritura, copiar los elementos de la matriz original a la nueva matriz, luego realizar la operación de escritura en la nueva matriz y finalmente reemplazar la nueva matriz con matriz original.
La operación de lectura se realiza directamente en la matriz original, por lo que no es necesario sincronizar la operación de lectura y se puede realizar la separación de lectura y escritura. Dado que se crea una nueva matriz para cada operación de escritura, CopyOnWriteArrayList es relativamente lento para las operaciones de escritura, pero muy eficaz para las operaciones de lectura.
Cabe señalar que el iterador de CopyOnWriteArrayList es débilmente coherente, es decir, durante el proceso de iteración, si otros subprocesos modifican la Lista, el iterador no generará ConcurrentModificationException, pero no hay garantía de que el iterador pueda atravesar todos los elementos. El escenario de uso de CopyOnWriteArrayList es adecuado para escenarios con más lecturas y menos escrituras.
Entendimiento de Sao Dai: ¿Por qué no se puede garantizar que el iterador pueda atravesar todos los elementos? Por ejemplo, tengo una colección con diez elementos y he recorrido cinco de ellos. En este momento, agregué un nuevo elemento entre los primeros cinco elementos, pero como ya he recorrido hasta el quinto, solo ir hacia atrás ¡Continúe recorriendo, y los cambios antes de recorrer no se pueden recorrer!
¿Cuáles son las ventajas de CopyOnWriteArrayList?
Las ventajas de CopyOnWriteArrayList incluyen principalmente los siguientes puntos:
1. Seguridad de subprocesos: CopyOnWriteArrayList es una implementación segura de subprocesos de List, que se puede usar en un entorno de subprocesos múltiples sin procesamiento de sincronización adicional.
2. Separación de lectura y escritura: la operación de lectura y la operación de escritura de CopyOnWriteArrayList están separadas, y la operación de lectura se realiza directamente en la matriz original sin procesamiento de sincronización, por lo que el rendimiento de la operación de lectura es muy alto.
3. Iterador débilmente consistente: el iterador de CopyOnWriteArrayList es débilmente consistente y se puede modificar durante la iteración sin lanzar ConcurrentModificationException.
4. Aplicable a escenarios con más lecturas y menos escrituras: dado que cada operación de escritura necesita crear una nueva matriz, es adecuada para escenarios con más lecturas y menos escrituras. Si las operaciones de escritura son frecuentes, el rendimiento puede disminuir.
Cabe señalar que la operación de escritura de CopyOnWriteArrayList es relativamente lenta, porque cada operación de escritura necesita crear una nueva matriz, por lo que es adecuada para escenarios con más lecturas y menos escrituras. Si la frecuencia de las operaciones de lectura y escritura es igual, o si la operación de escritura es más frecuente, puede provocar una degradación del rendimiento. Además, debido a que cada operación de escritura creará una nueva matriz, ocupará más espacio de memoria, que debe seleccionarse de acuerdo con escenarios y requisitos específicos.
¿Cuáles son las desventajas de CopyOnWriteArrayList?
Las desventajas de CopyOnWriteArrayList incluyen principalmente los siguientes puntos:
1. Alto uso de memoria: debido a que cada operación de escritura creará una nueva matriz, ocupará más espacio de memoria.
2. El rendimiento de las operaciones de escritura es bajo: dado que se debe crear una nueva matriz para cada operación de escritura, el rendimiento de las operaciones de escritura es bajo y es adecuado para escenarios con más lecturas y menos escrituras.
3. Problema de consistencia de datos: dado que el iterador de CopyOnWriteArrayList es débilmente consistente, es decir, durante el proceso de iteración, si otros subprocesos modifican la Lista, el iterador no arrojará ConcurrentModificationException, pero no se garantiza que la iteración pueda iterar sobre todos los elementos.
4. No apto para escenarios con altos requisitos de tiempo real: dado que se debe crear una nueva matriz para cada operación de escritura, no es adecuado para escenarios con altos requisitos de tiempo real, lo que puede causar retrasos en las operaciones de escritura.
¿Cómo garantiza CopyOnWriteArrayList la seguridad de los subprocesos al escribir?
CopyOnWriteArrayList utiliza la estrategia "Copy-On-Write" para garantizar la seguridad de subprocesos al escribir. Cuando un subproceso necesita realizar una operación de escritura, CopyOnWriteArrayList primero creará una nueva matriz y luego copiará los elementos de la matriz original a la nueva matriz. Dado que solo el subproceso actual puede acceder a la nueva matriz cuando se crea, no se requiere sincronización. Al escribir en la nueva matriz, otros subprocesos aún pueden acceder a la matriz original y no se verán afectados por la escritura del subproceso actual. Cuando se completa la operación de escritura, CopyOnWriteArrayList reemplaza la nueva matriz con la matriz original, lo que garantiza la seguridad de subprocesos de la operación de escritura.
Colocar
La diferencia entre lista y conjunto
Tanto List como Set son interfaces en el marco de colección de Java, y sus principales diferencias radican en los siguientes aspectos:
1. El orden de los elementos: los elementos de la Lista están dispuestos en el orden de inserción y se puede acceder a los elementos de acuerdo con el índice, mientras que los elementos del Conjunto están desordenados y no se puede acceder a los elementos de acuerdo con el índice .
2. La unicidad de los elementos: los elementos de la Lista se pueden repetir y se pueden insertar múltiples elementos nulos. Los elementos del Conjunto no se pueden repetir, cada elemento solo puede aparecer una vez, y solo se permite almacenar un elemento nulo, y se debe garantizar la unicidad del elemento
3. Método de implementación: los métodos de implementación comunes de List incluyen ArrayList, LinkedList, etc., y los métodos de implementación comunes de Set incluyen HashSet, TreeSet, LinkedHashSet, etc.
4. Escenarios de aplicación: List es adecuado para escenarios que necesitan acceder a elementos en el orden de inserción, como mantener una lista ordenada, y Set es adecuado para escenarios que necesitan garantizar la unicidad de los elementos, como deduplicación, búsqueda, etc. .
Entendimiento de Sao Dai: si necesita acceder a los elementos en el orden de inserción, puede elegir Lista; si necesita garantizar la unicidad de los elementos, puede elegir Establecer.
Cuénteme sobre el principio de implementación de HashSet.
La capa inferior de HashSet es en realidad HashMap. El constructor predeterminado es construir un HashMap con una capacidad inicial de 16 y un factor de carga de 0,75. Un objeto HashMap se encapsula para almacenar todos los elementos de la colección.Todos los elementos de la colección colocados en el HashSet en realidad se guardan con la clave del HashMap, y el valor del HashMap almacena un PRESENTE, que es un objeto Object estático.
¿Cómo comprueba HashSet si hay duplicados? ¿Cómo garantiza HashSet que los datos no sean repetibles?
Al agregar un objeto al HashSet (la capa inferior es para almacenar este objeto en la clave del HashMap), se llamará al método hashCode para obtener un valor hash y luego verificar si hay un conflicto hash. conflicto de hash, se inserta directamente, si hay un conflicto de hash, llame al método equals para juzgar mejor, si los valores devueltos de los dos hashCode() son iguales, y la comparación de equals también devuelve verdadero (lo que indica que el el objeto agregado es un duplicado), luego deje de agregar este elemento duplicado, lo que también satisface la característica de que los elementos en el Conjunto no se repiten. Si se produce un conflicto de hash pero el resultado devuelto por el método equals es falso, entonces aplique hash al objeto recién agregado en otra ubicación. De esta forma, reducimos mucho el número de iguales, lo que mejora mucho la velocidad de ejecución. Si no usa la función hashcode, debe recorrer todos los elementos del conjunto y llamar al método equals uno por uno para comparar si son iguales. Obviamente, esto requiere muchas llamadas al método equals
Entendimiento de Sao Dai: los resultados de ejecución del método hashCode de diferentes objetos pueden ser los mismos, que es el llamado conflicto hash, pero el resultado devuelto después de llamar a equals en diferentes objetos debe ser falso, solo los valores de retorno de hashCode () de dos objetos idénticos son iguales, la comparación por iguales también devuelve verdadero
Disposiciones relevantes de hashCode() y equals()
hashCode() y equals() son dos métodos definidos en la clase Object, que se usan ampliamente en Java para juzgar si los objetos son iguales. Al usar estos dos métodos, debe prestar atención a las siguientes regulaciones:
1. Si dos objetos son iguales (el método equals() devuelve verdadero), entonces sus valores hashCode() deben ser iguales. Esto se debe a que la implementación del método hashCode() generalmente se basa en el contenido de los objetos, y si dos objetos son iguales, su contenido también debe ser igual y, por lo tanto, sus valores de hashCode() también deben ser iguales.
2. Si los valores hashCode() de dos objetos son iguales, no necesariamente son iguales (el método equals() devuelve verdadero). Esto se debe a que el método hashCode() puede tener colisiones de hash, es decir, diferentes objetos pueden producir el mismo valor de hashCode(). Por lo tanto, cuando los valores de hashCode() son iguales, también debe llamar al método equals() para comparar y determinar si son iguales.
3. Si una clase reescribe el método equals(), también debe reescribir el método hashCode() para garantizar la exactitud de las disposiciones anteriores. Esto se debe a que el método hashCode() en la clase Object se calcula en función de la dirección del objeto. Si no se vuelve a escribir el método hashCode(), puede causar que objetos iguales tengan diferentes valores de hashCode(), violando así la primera regla .
4. Si una clase reescribe el método hashCode(), también debe reescribir el método equals() para garantizar la exactitud de las disposiciones anteriores. Esto se debe a que el método hashCode() puede tener una colisión hash, y si el método equals() no se reescribe, puede causar que objetos desiguales tengan el mismo valor hashCode(), violando así la segunda regla.
Cabe señalar que la implementación de hashCode() y equals() debe garantizar la eficiencia y la corrección, y no debe ser demasiado complicada ni llevar mucho tiempo. Además, los valores de retorno del método hashCode() deben distribuirse de la manera más uniforme posible para mejorar el rendimiento de la tabla hash.
La diferencia entre HashSet y HashMap
Tanto HashSet como HashMap son clases de implementación en el marco de la colección Java, y sus principales diferencias radican en los siguientes aspectos:
1. Método de almacenamiento: HashSet almacena un conjunto de elementos únicos y desordenados, mientras que HashMap almacena un conjunto de pares clave-valor.
2. Implementación de la capa inferior: la capa inferior de HashSet se implementa en función de HashMap. Usa HashMap para almacenar elementos, pero usa el valor del elemento como clave, y el valor correspondiente a la clave es un objeto Object fijo; mientras que HashMap se implementa mediante una tabla hash.
3. La unicidad de los elementos: los elementos en HashSet son únicos, y cada elemento solo puede aparecer una vez, mientras que las claves en HashMap son únicas, pero los valores pueden repetirse.
4. Método de acceso: no se puede acceder a los elementos en HashSet por índice, sino solo por iterador, mientras que a los elementos en HashMap se puede acceder por clave.
Debe elegir el tipo de colección adecuado según sus necesidades específicas. Si necesita almacenar un conjunto de elementos únicos y desordenados, puede elegir HashSet; si necesita almacenar un conjunto de pares clave-valor, puede elegir HashMap. Si necesita almacenar pares clave-valor y garantizar la unicidad de la clave al mismo tiempo, puede elegir LinkedHashMap.
¿Cómo comparan TreeMap y TreeSet los elementos al ordenarlos? ¿Cómo compara los elementos el método sort() en la clase de herramienta Colecciones?
¿Cómo comparan TreeMap y TreeSet los elementos al ordenarlos?
TreeSet requiere que la clase del objeto almacenado implemente la interfaz Comparable, que proporciona el método compareTo() para comparar elementos. Cuando se inserta un elemento, se volverá a llamar a este método para comparar el tamaño del elemento.
TreeMap requiere que las claves de mapeo de pares clave-valor almacenadas implementen la interfaz Comparable para que los elementos se puedan ordenar de acuerdo con las claves.
Entendimiento de Sao Dai: los elementos se comparan implementando la interfaz Comparable, que proporciona compareTo() para comparar elementos
método, que se llama al insertar un elemento para comparar el tamaño del elemento
¿Cómo compara los elementos el método sort() en la clase de herramienta Colecciones?
El método de clasificación de la clase de herramientas Colecciones tiene dos formas sobrecargadas,
- Se requiere que los objetos almacenados en el contenedor para ser ordenados implementen la interfaz Comparable, que proporciona el método compareTo() para comparar elementos. Al insertar elementos, se llamará a este método para comparar el tamaño de los elementos.
- Los elementos de la colección se pueden pasar en objetos que no implementan la interfaz Comparable, pero se requiere el segundo parámetro, que es un subtipo de la interfaz Comparator (debe anular el método de comparación para lograr la comparación de elementos), es decir, necesita definir un comparador, y luego la comparación del método sort () en realidad llama al método de comparación de este comparador para comparar
el segundo ejemplo
Cola
¿Qué es BlockingQueue?
¿Qué es BlockingQueue?
BlockingQueue es una interfaz en la programación concurrente de Java. Hereda de la interfaz Queue y representa una cola que admite el bloqueo y se utiliza para transferir datos entre varios subprocesos. Cuando la cola está llena, los subprocesos en cola se bloquearán hasta que la cola esté llena; cuando la cola esté vacía, los subprocesos eliminados se bloquearán hasta que haya elementos en la cola.
BlockingQueue es una cola segura para subprocesos, que se utiliza en un entorno de subprocesos múltiples y tiene características seguras para subprocesos.
La implementación de BlockingQueue suele utilizar mecanismos de sincronización, como bloqueos, variables de condición, etc., para garantizar un acceso seguro entre varios subprocesos. En un entorno de subprocesos múltiples, varios subprocesos pueden leer y escribir en BlockingQueue al mismo tiempo, sin problemas de seguridad de subprocesos, como la competencia de datos.
Por ejemplo, cuando se usa ArrayBlockingQueue, los métodos put() y take() primero deben adquirir el bloqueo y luego esperar en la variable de condición o activar otros subprocesos para garantizar la seguridad del subproceso. Al usar LinkedBlockingQueue, diferentes subprocesos pueden leer y escribir en la cola al mismo tiempo, ya que usa dos bloqueos, uno para la operación de puesta en cola y otro para la operación de eliminación de cola, para evitar problemas de competencia y de interbloqueo.
Cabe señalar que, aunque BlockingQueue es una cola segura para subprocesos, aún debe prestar atención a algunos detalles en el uso real, como el tamaño de la capacidad de la cola, el tamaño del grupo de subprocesos, etc., para evitar problemas de rendimiento o problemas de interbloqueo causados por uso
La interfaz BlockingQueue proporciona una variedad de métodos de bloqueo, incluidos put(), take(), offer(), poll(), etc., que se pueden usar para implementar modelos de productor-consumidor, grupos de subprocesos y otros escenarios concurrentes.
Las principales características de la interfaz BlockingQueue son: cuando la cola está vacía, el método take() bloqueará y esperará la llegada de los elementos; cuando la cola esté llena, el método put() bloqueará y esperará a que la cola sea gratis. Este mecanismo de bloqueo de espera puede evitar la competencia y los problemas de interbloqueo entre varios subprocesos y mejorar la solidez y la confiabilidad del programa.
BlockingQueue proporciona principalmente cuatro tipos de métodos, como se muestra en la siguiente tabla:
| método |
Lanzar una excepción |
devolver un valor específico |
bloquear |
bloquear por un tiempo específico |
| poner en cola |
añadir (e) |
oferta |
poner (e) |
oferta(e, tiempo, unidad) |
| sacar de la cola |
eliminar() |
encuesta() |
llevar() |
encuesta (tiempo, unidad) |
| Obtener el primer elemento de la cola |
elemento() |
ojeada() |
no apoyo |
no apoyo |
Además de lanzar una excepción y devolver un valor específico , el método es el mismo que la definición de la interfaz Queue, BlockingQueue también proporciona dos tipos de métodos de bloqueo: uno es bloquear cuando no hay espacio/elemento en la cola hasta que haya espacio. /elemento; el otro está en Intento de poner en cola/salir en un momento específico, y el tiempo de espera se puede personalizar.
clase de implementación principal
Las clases de implementación comunes de la interfaz BlockingQueue incluyen ArrayBlockingQueue, LinkedBlockingQueue, SynchronousQueue, etc. Entre ellos, ArrayBlockingQueue y LinkedBlockingQueue son colas de bloqueo implementadas en base a matrices y listas enlazadas. SynchronousQueue es una cola de bloqueo especial que no almacena elementos, sino que solo sincroniza entre productores y consumidores.
| Clase de implementación |
Función |
| ArrayBlockingQueue |
Una cola de bloqueo basada en matrices utiliza una matriz para almacenar datos y necesita especificar su longitud, por lo que es una cola limitada |
| LinkedBlockingQueue |
Una cola de bloqueo basada en una lista vinculada , que utiliza una lista vinculada para almacenar datos, es una cola ilimitada por defecto ; también puede establecer el número máximo de elementos a través de la capacidad en el método de construcción, por lo que también se puede usar como una cola limitada . cola |
| SynchronousQueue |
Una cola sin almacenamiento en búfer, los datos generados por el productor serán adquiridos directamente por el consumidor y consumidos inmediatamente |
| PriorityBlockingQueue |
Cola de bloqueo basada en prioridad , la capa inferior se basa en la implementación de matriz, es una cola ilimitada |
| DelayQueue |
Cola de retraso , los elementos que contiene solo se pueden sacar de la cola después del tiempo de retraso especificado |
Entre ellos, ArrayBlockingQueue y LinkedBlockingQueue se usan más comúnmente en el desarrollo diario.
¿Cuál es la diferencia entre poll() y remove() en Queue?
En la interfaz Queue, tanto poll() como remove() son métodos que se utilizan para obtener y eliminar el elemento que está al principio de la cola, pero su comportamiento es ligeramente diferente.
1. Método poll(): obtiene y elimina un elemento de la cabeza de la cola y devuelve un valor nulo si la cola está vacía.
2. Método remove(): obtenga y elimine un elemento de la cabeza de la cola y lance NoSuchElementException si la cola está vacía.
En términos simples, el método poll() devuelve un valor nulo cuando la cola está vacía y el método remove() lanza una excepción cuando la cola está vacía.
Por lo tanto, al usar la interfaz Queue, si no está seguro de si la cola está vacía, puede usar el método poll() para obtener y eliminar el elemento principal de la cola. Si la cola está vacía, devuelva nulo; si no lo está Asegúrese de que la cola no esté vacía, puede usar el método remove () para obtener y eliminar el elemento principal de la cola y lanzar una excepción si la cola está vacía.
Debe tenerse en cuenta que cuando se usa el método remove(), si la cola está vacía, se lanzará una excepción NoSuchElementException, por lo que se requieren instrucciones de manejo de excepciones o de captura para evitar bloqueos del programa.
mapa hash
HashMap encuentra la posición del cubo
jdk1.7
En JDK 1.7, el método de cálculo de la posición del depósito de HashMap es diferente al de JDK 1.8. Específicamente, el método de cálculo de la posición del depósito de HashMap en JDK 1.7 es el siguiente:
1. Primero calcule el valor hash `h` de la clave, utilizando el método `key.hashCode()`.
2. La posición del cucharón `i` se calcula mediante la siguiente fórmula: i = (n - 1) & h
Entre ellos, `n` representa la longitud de la matriz `tabla`. Dado que en JDK 1.7, la longitud de `table` no es necesariamente una potencia de 2, es necesario usar `n - 1` para garantizar que el valor de `i` esté dentro del rango de subíndices de `table`.
3. Si ya hay un elemento en la posición del depósito `i`, entonces se usará el método `equals()` de la clave para comparar si la clave es igual. Si las claves son iguales, el valor correspondiente a la clave se reemplaza por el nuevo valor; si las claves no son iguales, el par clave-valor se inserta al final de la lista enlazada.
Cabe señalar que en JDK 1.7, el mecanismo de expansión de HashMap es diferente al de JDK 1.8. Específicamente, cuando la cantidad de elementos en HashMap excede el producto del factor de carga y la capacidad, HashMap duplicará la capacidad y redistribuirá todos los elementos en nuevos cubos. Este enfoque puede hacer que se asignen varias claves al mismo depósito durante la expansión, lo que reduce el rendimiento de HashMap.
jdk1.8
HashMap se divide en tres procesos para encontrar la posición del cubo
- Encuentra el código hash de la clave
- Llame a la función hash para obtener el valor hash y realice la operación XOR en los 16 bits superiores y los 16 bits inferiores del código hash.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);// >>> 是无符号右移符号位
}- Use (longitud- 1) & hash para Y el valor hash y longitud-1 para encontrar la posición del cubo (el valor hash es el valor obtenido por la función hash anterior, y la longitud es la longitud de la matriz de la tabla)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);Sao Dai entiende: no es obtener el valor hash para saber dónde está almacenado el elemento en la matriz, sino obtener la posición de la matriz después de (longitud-1) y hash, que es para reducir los conflictos hash
Cuénteme sobre el principio de implementación de HashMap.
JDK1.7
La columna vertebral de HashMap es una matriz de entrada. La entrada es la unidad básica de HashMap, y cada entrada contiene un par clave-valor clave-valor. (De hecho, el llamado Map es en realidad una colección que guarda la relación de mapeo entre dos objetos), donde Key y Value pueden ser nulos. Estos pares clave-valor (Entrada) están dispersos y almacenados en una matriz, y el valor inicial de cada elemento de la matriz HashMap es Nulo.

Sao Dai entiende: HashMap no puede garantizar el orden del mapeo, y no se puede garantizar que el orden de los datos después de la inserción permanezca sin cambios (por ejemplo, la operación de expansión antes de 1.8 hará que el orden cambie)
Entry es una clase interna estática en HashMap.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
} La estructura general de HashMap es la siguiente
Entendimiento de Sao Dai: en términos simples, HashMap se compone de matriz + lista vinculada. La matriz es el cuerpo principal de HashMap, y la lista vinculada existe principalmente para resolver conflictos de hash. null), luego buscar, agregar y otras operaciones son muy rápidas , y solo se requiere un direccionamiento; si la matriz ubicada contiene una lista enlazada, para la operación de adición, su complejidad de tiempo es O(n), primero recorra la lista enlazada, si existe, se sobrescribirá, de lo contrario, es agregado; para la operación de búsqueda, todavía es necesario recorrer la lista enlazada y luego usar el método de igualdad del objeto clave para comparar y buscar uno por uno. Por lo tanto, teniendo en cuenta el rendimiento, cuantas menos listas enlazadas haya en HashMap, mejor será el rendimiento.
JDK1.8
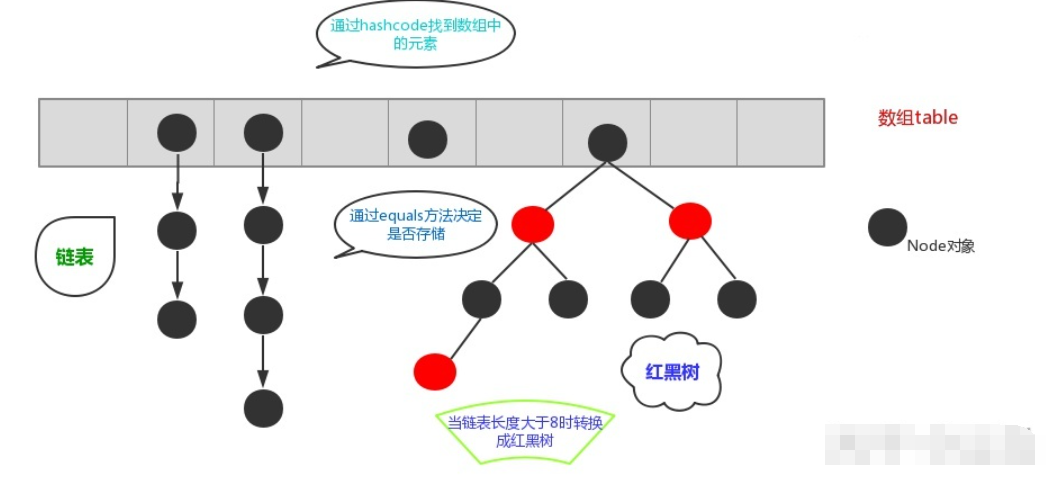
El principio subyacente de HashMap en JDK 1.8 se implementa utilizando la estructura de matriz + lista enlazada + árbol rojo-negro, que incluye principalmente los siguientes aspectos:
1. Matriz: HashMap mantiene internamente una matriz para almacenar pares clave-valor. La longitud de la matriz es fija y debe ser una potencia de 2.
2. Lista enlazada: cada elemento de la matriz es el nodo principal de una lista enlazada, que se utiliza para almacenar pares clave-valor con el mismo valor hash. Cuando la longitud de la lista vinculada supera los 8 (TREEIFY_THRESHOLD - umbral), la lista vinculada se convertirá automáticamente en un árbol rojo-negro para mejorar la eficiencia de la búsqueda.
3. Árbol rojo-negro: cuando la longitud de la lista vinculada supera un cierto umbral, HashMap convertirá la lista vinculada en un árbol rojo-negro para mejorar la eficiencia de la búsqueda. El árbol rojo-negro es un árbol de búsqueda binaria autoequilibrado, y la complejidad temporal de su búsqueda, inserción, eliminación y otras operaciones es O(log n).
4. Expansión: Cuando el número de elementos en el HashMap supere el 75% de la longitud del arreglo, el HashMap realizará una operación de expansión, es decir, se duplicará la longitud del arreglo y la posición de cada elemento en el se recalculará la nueva matriz. La operación de expansión hará que la posición de todos los elementos cambie, por lo que es necesario volver a calcular la posición de cada elemento en la nueva matriz, y este proceso requiere mucho tiempo.
5. Función hash: HashMap utilizará el método hashCode() del objeto clave para calcular el valor hash de la clave y luego calculará la posición del par clave-valor en la matriz en función del valor hash.
6. Seguridad de subprocesos: HashMap en JDK 1.8 no es seguro para subprocesos. Si varios subprocesos escriben en HashMap al mismo tiempo, puede ocurrir una pérdida de datos o un bucle infinito. Si necesita usar HashMap en un entorno de subprocesos múltiples, puede usar ConcurrentHashMap.
¿Qué es el cubo de hashmap?
Los cubos en HashMap se refieren a elementos de matriz que almacenan pares clave-valor, también conocidos como cubos hash o nodos de tablas hash.
Dentro de HashMap, los pares clave-valor se almacenan en una matriz, que se denomina tabla hash. Cada elemento de la matriz es un depósito, que puede almacenar uno o más pares clave-valor. Cuando se agrega un par clave-valor en HashMap a la tabla hash, calculará en qué depósito se debe almacenar el par clave-valor de acuerdo con el valor hash de la clave. Si ya hay uno o más pares clave-valor en el depósito, el nuevo par clave-valor se agregará al depósito y se convertirá en un elemento del depósito.
Para resolver el problema de colisión de hash, cada depósito de HashMap puede almacenar no solo un par clave-valor, sino también varios pares clave-valor. Cuando varios pares clave-valor tienen el mismo valor hash, se agregarán al mismo depósito y se convertirán en una lista vinculada o un árbol rojo-negro en este depósito. HashMap determinará qué estructura de datos usar para almacenar pares clave-valor en función de la longitud de la lista vinculada o la cantidad de nodos en el árbol rojo-negro, mejorando así la eficiencia de la búsqueda.
Por lo tanto, el depósito es la unidad básica para almacenar pares clave-valor en HashMap y es el núcleo para realizar la estructura de datos interna de HashMap.
El entendimiento de Sao Dai: en pocas palabras, el llamado cubo se refiere a los elementos de la matriz de entrada, y cada entrada es un cubo
¿Cuáles son las diferencias entre la implementación subyacente de HashMap en JDK1.7 y JDK1.8?
HashMap es una estructura de datos muy utilizada en Java. Se puede utilizar para almacenar pares clave-valor y puede encontrar rápidamente el valor correspondiente según la clave. En JDK 1.7 y JDK 1.8, la implementación subyacente de HashMap tiene las siguientes diferencias:
1. Las matrices subyacentes se inicializan de manera diferente. En JDK 1.7, la matriz subyacente se inicializaba cuando se insertaba un elemento por primera vez, mientras que en JDK 1.8, la matriz subyacente se inicializaba cuando se creaba el objeto HashMap.
2. El mecanismo de expansión es diferente. En JDK 1.7, cuando el número de elementos supere el 75% de la capacidad, HashMap realizará una operación de expansión de capacidad, es decir, se duplicará la capacidad y se recalculará la posición de todos los elementos. Esta estrategia de expansión puede dar lugar a una gran cantidad de elementos en el mismo grupo, lo que da como resultado una lista de enlaces demasiado larga y una eficiencia de consulta reducida. En JDK 1.8, cuando la longitud de la lista enlazada en un depósito es mayor o igual a 8, se evaluará si la capacidad del HashMap actual es mayor o igual a 64. Si es inferior a 64, duplicará la capacidad; si es superior o igual a 64, convertirá la lista enlazada en un árbol rojo-negro para mejorar la eficiencia de las consultas.
3. El método de cálculo de la función hash es diferente. En JDK 1.7, la función hash de HashMap usa directamente el método hashCode() del objeto clave para calcular el valor hash de la clave y luego calcula la posición del par clave-valor en la matriz en función del valor hash. Este método de cálculo puede generar conflictos hash, es decir, diferentes objetos clave calculan el mismo valor hash, lo que da como resultado que los elementos se almacenen en el mismo depósito, la lista vinculada es demasiado larga y se reduce la eficiencia de la consulta. En JDK 1.8, la función hash de HashMap está optimizada. Primero llama al método hashCode() del objeto clave para calcular el valor hash de la clave, y luego aplica XOR a los 16 bits superiores y los 16 bits inferiores del valor hash para obtener un valor hash de tipo int. Este método de cálculo puede evitar conflictos causados por confiar únicamente en datos de orden bajo para calcular el hash. El resultado del cálculo está determinado por la combinación de bits altos y bajos, lo que hace que la distribución de elementos sea más uniforme.
4. En JDK 1.8, cuando ocurre un conflicto hash, se usa el método de inserción de cola, es decir, se inserta un nuevo nodo al final de la lista enlazada. De esta forma, se puede mantener el orden de los nodos en la lista enlazada, de modo que el orden de recorrido de la lista enlazada sea consistente con el orden de inserción, mejorando así la eficiencia de la consulta. Al expandirse, 1.8 mantendrá el orden de la lista enlazada original, es decir, reorganizará los nodos de la lista enlazada según el orden de inserción, en lugar de invertir el orden de la lista enlazada. En JDK 1.7, cuando ocurre una colisión de hash, se utiliza el método de inserción de cabecera, es decir, se inserta un nuevo nodo en la cabecera de la lista enlazada. Esto puede garantizar que, al atravesar la lista vinculada, se recorra primero el nodo insertado más recientemente, lo que mejora la eficiencia de la consulta. Al expandirse, 1.7 invertirá el orden de la lista enlazada, es decir, reorganizará los nodos en la lista enlazada en orden inverso.
5. En JDK 1.8, HashMap detectará si necesita expandirse después de insertar el elemento, es decir, inserte el elemento primero y luego verifique si necesita expandirse. En JDK 1.7, HashMap detectará si se requiere expansión antes de insertar elementos, es decir, primero detectará si se requiere expansión y luego insertará elementos. El objetivo de esto es evitar operaciones de expansión frecuentes al insertar elementos, mejorando así la eficiencia de la inserción de elementos.
¿El proceso específico del método put de HashMap?
diagrama de flujo de ejecución del método putVal

① Determine si la tabla de matriz está vacía o longitud = 0, si es así, ejecute resize () para expandir;
② Calcule el valor hash de acuerdo con la clave de valor clave para obtener el índice de matriz insertado i, si table[i]==null, cree directamente un nuevo nodo para agregar, gire a ⑥, si table[i] no está vacío, gire a ③;
③ Determine si el primer elemento de la tabla [i] es el mismo que la clave, si es el mismo, sobrescriba directamente el valor, de lo contrario, pase a ④, lo mismo aquí se refiere a hashCode y es igual;
④ Determine si table[i] es un treeNode, es decir, si table[i] es un árbol rojo-negro, si es un árbol rojo-negro, inserte directamente pares clave-valor en el árbol, de lo contrario, pase a ⑤ ;
⑤ Recorriendo la tabla[i], juzgando si la longitud de la lista enlazada es mayor que 8, si es mayor que 8, convierta la lista enlazada en un árbol rojo-negro y realice una operación de inserción en el árbol rojo-negro , de lo contrario, realice una operación de inserción de la lista enlazada; si se encuentra que la clave ya existe durante el proceso transversal, simplemente sobrescriba el valor directamente;
⑥. Después de que la inserción sea exitosa, juzgue si el número real de pares clave-valor supera el umbral de capacidad máxima. Si lo supera, amplíe la capacidad.
¿Cómo se realiza la operación de expansión de HashMap?
Mecanismo de expansión JDK1.7
Cuando el número de elementos en HashMap excede el tamaño de la matriz (la longitud total de la matriz, no el tamaño del número en la matriz)*loadFactor (es decir, HashMap.Size > Capacity * LoadFactor, LoadFactor es la carga factor), la matriz se expandirá y el valor predeterminado de loadFactor El valor es 0.75, que es un valor de compromiso. Es decir, por defecto, el tamaño de la matriz es 16, por lo que cuando el número de elementos en el HashMap excede 16*0.75=12 (este valor es el valor umbral en el código, también llamado valor crítico), expanda el tamaño de la matriz es 2*16=32, es decir, se duplica y luego vuelve a calcular la posición de cada elemento en la matriz. La capacidad inicial por defecto de HashMap es 16, y el factor de carga es 0,75, cuando personalizamos una capacidad inicial a través de la construcción parametrizada de HashMap, el valor dado debe ser una potencia de 2 valores;
De acuerdo con la regla del factor de carga, en ese momento, hashMap realizará una operación de expansión; el proceso de expansión se puede dividir en dos pasos:
- cambiar el tamaño: cree una nueva matriz vacía de entrada con el doble de la longitud de la matriz original
- transferencia: los elementos de la matriz anterior se migran a la nueva matriz
La expansión en HashMap es llamar al método resize()
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果当前的数组长度已经达到最大值,则不在进行调整
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//根据传入参数的长度定义新的数组
Entry[] newTable = new Entry[newCapacity];
//按照新的规则,将旧数组中的元素转移到新数组中
transfer(newTable);
table = newTable;
//更新临界值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}Como puede ver en el código, si la longitud de la tabla original ha alcanzado el límite superior, ya no se expandirá. Si no se alcanza, se expandirá al doble del tamaño de la matriz original
La función del método de transferencia es poner el Nodo de la tabla original en la nueva tabla.jdk1.7 usa el método de inserción de cabecera, es decir, el orden de la lista enlazada en la nueva tabla es opuesto al de la lista anterior, y el subproceso HashMap no es seguro. En algunos casos, este método de inserción de cabeza puede resultar en nodos de anillo.
//旧数组中元素往新数组中迁移
void transfer(Entry[] newTable) {
//旧数组
Entry[] src = table;
//新数组长度
int newCapacity = newTable.length;
//遍历旧数组
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);//放在新数组中的index位置
e.next = newTable[i];//实现链表结构,新加入的放在链头,之前的的数据放在链尾
newTable[i] = e;
e = next;
} while (e != null);
}
}
}El bucle while describe el proceso de interpolación de la cabeza
Expansión JDK1.8
HashMap desencadena condiciones de expansión
- El factor de carga predeterminado de hashMap es 0,75, es decir, si la cantidad de elementos en el hashmap supera el 75 % de la capacidad total, se activará la expansión.
- En JDK 1.8, cuando la longitud de la lista enlazada en un depósito es mayor o igual a 8, juzgará si la capacidad del HashMap actual es mayor o igual a 64. Si es inferior a 64, duplicará la capacidad; si es superior o igual a 64, convertirá la lista enlazada en un árbol rojo-negro para mejorar la eficiencia de las consultas.
El HashMap de jdk1.8 encuentra la posición del cubo
HashMap se divide en tres procesos para encontrar la posición del cubo
- Encuentra el código hash de la clave
- Llame a la función hash para obtener el valor hash y realice la operación XOR en los 16 bits superiores y los 16 bits inferiores del código hash.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- Use (longitud- 1) & hash para Y el valor hash y longitud-1 para encontrar la posición del cubo (el valor hash es el valor obtenido por la función hash anterior, y la longitud es la longitud de la matriz de la tabla)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);Nota: No es la ubicación del elemento almacenado en la matriz lo que se obtiene al obtener el valor hash, pero la ubicación de la matriz solo se puede obtener después de (longitud-1) & hash, que es para reducir los conflictos de hash.
Ya sea JDK7 o JDK8, la expansión de HashMap es el doble de la capacidad original cada vez, es decir, se generará una nueva matriz de tabla nueva. La expansión de JDK1.8 y 1.7 es realmente similar, solo coloque todos los elementos en el original array en el nuevo Es solo que el método para encontrar la posición del cubo para el elemento es diferente.
En JDK7, la posición del cubo se vuelve a calcular de acuerdo con los tres pasos escritos anteriormente, pero el valor del tercer paso es la longitud de la nueva matriz -1, es decir, newCap-1.
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;//插入新值Pero en JDK8, no es con newCap, sino directamente con oldCap, es decir, el valor hash se combina con la longitud de la matriz anterior (oldCap).
if ((e.hash & oldCap) == 0) {
newTab[j] = loHead;
}else{
newTab[j + oldCap] = hiHead;
}- Si el resultado de AND con oldCap es 0, significa que la posición del depósito del elemento actual permanece sin cambios.
- Si el resultado es 1, entonces la posición del cubo es la posición original + la longitud original de la matriz (oldCap)
Entendimiento de Sao Dai: Cabe señalar que aunque JDK 8 recalcula la posición de los elementos en la nueva matriz, la forma de hacer AND con la longitud de la matriz anterior es diferente de la operación de módulo en JDK 7, pero su esencia es la misma. es todo para garantizar que las posiciones de los elementos en la nueva matriz se puedan distribuir uniformemente para evitar colisiones de hash.
¿Por qué el factor de carga de HashMap es 0.75?
El factor de carga es un valor proporcional, que representa la relación entre el número de elementos en HashMap y la capacidad. Cuanto mayor sea el factor de carga y menor el factor de relleno, más espacio desperdiciado se puede reducir, pero la probabilidad de colisiones de hash aumentará. Cuanto menor sea el factor de carga y mayor el factor de relleno, es más probable que reduzca la probabilidad de colisiones de hash, pero aumentará el desperdicio de espacio.
En JDK 1.8, el factor de carga predeterminado para HashMap es 0,75. Este valor se obtiene a través de experimentos y optimización. Cuando el factor de carga es 0,75, la tasa de utilización del espacio de HashMap es relativamente alta y la probabilidad de colisión de hash es relativamente baja, lo que puede lograr un mejor rendimiento. Si el factor de carga se configura demasiado pequeño, HashMap realizará operaciones frecuentes de expansión de capacidad y reducirá el rendimiento; si el factor de carga se configura demasiado grande, aumentará la probabilidad de colisiones de hash y reducirá el rendimiento.
Cabe señalar que en aplicaciones prácticas, la elección del factor de carga debe determinarse de acuerdo con condiciones específicas. Si hay pocas colisiones hash en la aplicación, el factor de carga se puede aumentar adecuadamente para reducir el desperdicio de espacio; si hay muchas colisiones hash, el factor de carga se puede reducir adecuadamente para mejorar el rendimiento.
¿Cómo resuelve HashMap los conflictos de hash?
Resuma brevemente qué métodos utiliza HashMap para resolver conflictos de hash de manera efectiva
- Use el método de dirección de cadena (usando una tabla hash) para vincular datos con el mismo valor hash;
- Use 2 funciones de perturbación (funciones hash) para reducir la probabilidad de colisiones hash y hacer que la distribución de datos sea más uniforme;
- La introducción del árbol rojo-negro reduce aún más la complejidad temporal del recorrido, lo que lo hace más rápido;
¿Qué es un hash?
Hash, generalmente traducido como "hash", también transcrito directamente como "hash", que consiste en transformar una entrada de cualquier longitud en una salida de longitud fija a través de un algoritmo hash, y la salida es el valor hash (valor hash); esto la conversión es una asignación comprimida, es decir, el espacio del valor hash suele ser mucho más pequeño que el espacio de la entrada, y se pueden convertir diferentes entradas en la misma salida, por lo que es imposible determinar de forma única el valor de entrada a partir del hash valor. En pocas palabras, es una función para comprimir un mensaje de cualquier longitud en un resumen de mensaje de longitud fija.
Todas las funciones hash tienen la siguiente propiedad básica:
Si los valores hash calculados según la misma función hash son diferentes, los valores de entrada también deben ser diferentes. Sin embargo, si los valores hash calculados por la misma función hash son los mismos, los valores de entrada no son necesariamente los mismos.
¿Qué son las colisiones hash?
Cuando dos valores de entrada diferentes calculan el mismo valor hash de acuerdo con la misma función hash, lo llamamos colisión (colisión hash).
Estructura de datos HashMap
En Java, hay dos estructuras de datos relativamente simples para almacenar datos: matrices y listas enlazadas.
Las características de la matriz son: fácil de direccionar, difícil de insertar y borrar;
Las características de la lista enlazada son: difícil de direccionar, pero fácil de insertar y borrar;
Entonces combinamos arreglos y listas enlazadas para aprovechar sus respectivas ventajas, y usamos un método llamado método de dirección de cadena para resolver conflictos hash:
De esta forma, podemos organizar objetos con el mismo valor hash en una lista enlazada y colocarlos debajo del depósito correspondiente al valor hash, pero en comparación con el tipo int devuelto por hashCode, la capacidad inicial de nuestro HashMap es DEFAULT_INITIAL_CAPACITY = 1 < < 4 (es decir, 2 a la cuarta potencia 16) es mucho más pequeño que el rango del tipo int, por lo que si simplemente usamos el resto del hashCode para obtener el contenedor correspondiente, esto aumentará en gran medida la probabilidad de colisiones hash, y en en el peor de los casos, el HashMap se convierte en una lista con un solo enlace (es decir, siempre hay conflictos y finalmente se convierte en una lista con un solo enlace), por lo que aún necesitamos optimizar el hashCode
función hash
El problema mencionado anteriormente se debe principalmente a que si usa el hashCode para tomar el resto, entonces es equivalente a que solo los bits bajos del hashCode participen en el cálculo, y los bits altos no tienen efecto, por lo que nuestra idea es dejar que el alto Los bits del valor hashCode también participan en el cálculo, para reducir aún más la probabilidad de colisión de hash y hacer que la distribución de datos sea más uniforme. Llamamos a tal operación perturbación. La función hash() en JDK 1.8 es la siguiente:
static final int hashCode(Object key){
int h;
//与自己右移16位进行异或运算(高低位异或)
return (key==null)? 0 : (h==key.hashCode()) ^ (h>>>16)//
}Esto es más conciso que en JDK 1.7, en comparación con operaciones de 4 bits, 5 operaciones XOR (9 perturbaciones) en 1.7, en 1.8, solo operación de 1 bit y 1 operación XOR (2 perturbaciones);
JDK1.8 agrega árbol rojo-negro
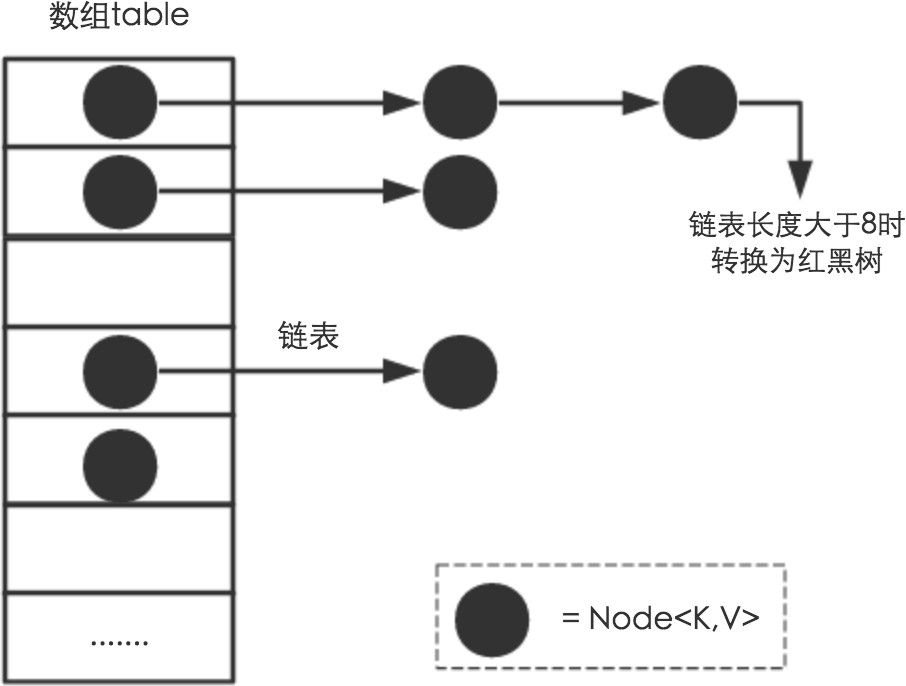
A través del método de dirección de la cadena anterior (usando la tabla hash) y la función de perturbación, logramos que nuestra distribución de datos sea más uniforme y reducimos las colisiones hash. Sin embargo, cuando hay una gran cantidad de datos en nuestro HashMap, agregamos la lista vinculada correspondiente bajo un determinado cubo nuestro tiene n elementos, entonces la complejidad del tiempo de recorrido es O(n).Para resolver este problema, JDK1.8 agrega una estructura de datos de árbol rojo-negro en HashMap, lo que reduce aún más la complejidad del recorrido a O(logn) ;
Resuma brevemente qué métodos utiliza HashMap para resolver conflictos de hash de manera efectiva
- Use el método de dirección de cadena (usando una tabla hash) para vincular datos con el mismo valor hash;
- Use 2 funciones de perturbación (funciones hash) para reducir la probabilidad de colisiones hash y hacer que la distribución de datos sea más uniforme;
- La introducción del árbol rojo-negro reduce aún más la complejidad temporal del recorrido, lo que lo hace más rápido;
Por lo general, cuatro soluciones a los conflictos hash
- Método de cadena de direcciones: cada unidad de la tabla hash se utiliza como nodo principal de la lista enlazada, y todos los elementos cuya dirección hash es i forman una lista enlazada de sinónimos. Es decir, cuando ocurre un conflicto, la palabra clave se vincula al final de la lista vinculada con la unidad como nodo principal.
- Método de direccionamiento abierto: cuando se produce un conflicto, busque la siguiente dirección hash vacía. Siempre que la tabla hash sea lo suficientemente grande, siempre se puede encontrar una dirección hash vacía.
- Método de repetición: cuando se produce un conflicto, otras funciones vuelven a calcular el valor hash.
- Establezca un área de desbordamiento común: divida la tabla hash en una tabla básica y una tabla de desbordamiento, y cuando ocurra un conflicto, coloque los elementos en conflicto en la tabla de desbordamiento.
¿Se puede usar cualquier clase como clave de un Mapa?
En Java, se puede usar cualquier clase como clave del mapa, siempre que la clase implemente correctamente los métodos `hashCode()` y `equals()`. El método `hashCode()` se usa para calcular el código hash del objeto, y el método `equals()` se usa para determinar si dos objetos son iguales.
Al usar una clase personalizada como clave del mapa, debe asegurarse de que la clase implemente correctamente los métodos `hashCode()` y `equals()`. Si estos dos métodos no se implementan correctamente, es posible que los elementos del HashMap no se almacenen ni recuperen correctamente, e incluso pueden causar problemas, como un bucle infinito en el HashMap.
Al implementar los métodos `hashCode()` y `equals()`, se deben seguir los siguientes principios:
- Si dos objetos son iguales, sus códigos hash deben ser iguales.
- Si dos objetos tienen códigos hash iguales, no necesariamente son iguales.
- El método `equals()` debe satisfacer reflexividad, simetría, transitividad y consistencia.
Cabe señalar que si se utiliza un objeto mutable como clave del Mapa, cuando el objeto cambie, su código hash también cambiará. Esto puede provocar que el objeto no se recupere correctamente del HashMap. Por lo tanto, generalmente se recomienda utilizar objetos inmutables como clave del Mapa.
¿Por qué las clases contenedoras como String e Integer en HashMap son adecuadas como clave?
Las características de las clases de empaquetado, como String y Integer, pueden garantizar la inmutabilidad y la precisión del cálculo de los valores Hash, y pueden reducir de manera efectiva la probabilidad de colisiones Hash.
1. Son todos de tipo final, es decir, de inmutabilidad, para asegurar la inmutabilidad de la clave, y no habrá caso de obtener valores hash diferentes
2. Los métodos equals(), hashCode() y otros han sido reescritos internamente, cumpliendo con las especificaciones internas de HashMap, y no es fácil que ocurra el error de cálculo del valor Hash;
¿Qué debo hacer si uso un objeto personalizado como clave de HashMap?
Los métodos hashCode() y equals() deben reescribirse al mismo tiempo. El propósito de reescribir estos dos métodos al mismo tiempo es garantizar que cuando se usa un objeto personalizado como clave de HashMap, la clave es única. que estos dos métodos no se reescriben ahora, luego guarde Ingrese dos objetos idénticos personalizados, primero llame al método hashCode() de Object, porque el método hashCode() de Object compara dos objetos con diferentes direcciones de referencia, por lo que el resultado del hashCode de los dos objetos idénticos personalizados Si es diferente, se juzgará como dos objetos diferentes, y se almacenarán en HashMap como la clave, lo que no se ajusta a la unicidad de la clave. De hecho, la razón es la misma como el conjunto a continuación
¿Por qué se debe anular el método hashCode cuando se anula la igualdad?
Si solo se reescribe el método equals, entonces, de forma predeterminada, suponiendo que dos objetos personalizados con el mismo contenido están almacenados en el Conjunto, cuando el Conjunto realiza operaciones de deduplicación, primero determinará si el código hash de los dos objetos es el mismo. El método hashCode no se reescribe, por lo que el método hashCode en Object se ejecutará directamente, y el método hashCode en Object compara dos objetos con diferentes direcciones de referencia, por lo que los dos valores Hash obtenidos son diferentes, por lo que el método equals no lo hará. se ejecutará, y los dos objetos se considerarán no iguales, por lo que se insertarán dos objetos idénticos en la colección Set (lo mismo aquí se refiere al mismo contenido).
Sin embargo, si el método hashCode también se reescribe cuando se reescribe el método equals, entonces el método hashCode reescrito se ejecutará cuando se ejecute el juicio. En este momento, la comparación es si el hashCode de todos los atributos de los dos objetos es el mismo. , entonces llame a hashCode El resultado devuelto es verdadero, luego llame al método equals y descubra que los dos objetos son realmente iguales, por lo que devuelve verdadero, por lo que la colección Set no almacenará dos datos idénticos, por lo que la ejecución de todo el programa es normal .
Resumir
Los dos métodos hashCode y equals se usan para juzgar conjuntamente si dos objetos son iguales. La razón para usar este método es mejorar la velocidad de inserción y consulta del programa. Si hashCode no se reescribe cuando se reescribe equals, resultará en algunos escenarios, por ejemplo, cuando dos objetos personalizados iguales se almacenan en la colección Set, se producirán excepciones de ejecución del programa. Para garantizar la ejecución normal del programa, necesitamos reescribir los iguales juntos. El método hashCode servirá.
¿Por qué HashMap no utiliza directamente el valor hash procesado por hashCode() como subíndice de la tabla?
En teoría, puede usar el valor hash procesado por `hashCode()` directamente como el subíndice de la matriz `table`, pero este enfoque puede causar conflictos hash, es decir, diferentes claves pueden producir el mismo valor hash, causando que asignarse a la misma posición de subíndice de `tabla`, lo que afectará el rendimiento de HashMap.
Para resolver este problema, HashMap utiliza una solución llamada "método cremallera". Específicamente, cada depósito en HashMap es una lista vinculada. Cuando se asignan varias claves al mismo depósito, se almacenarán en la lista vinculada correspondiente al depósito. Al buscar, HashMap primero encontrará el depósito correspondiente de acuerdo con el valor hash de la clave y luego buscará el par clave-valor en la lista vinculada correspondiente al depósito.
Por supuesto, si la lista enlazada es demasiado larga, afectará el rendimiento de HashMap. Por lo tanto, en JDK 8, cuando la longitud de la lista enlazada supera un cierto umbral (8 por defecto), HashMap convertirá la lista enlazada en un árbol rojo-negro para mejorar la eficiencia de la búsqueda. Este enfoque puede garantizar el rendimiento de HashMap en la mayoría de los casos.
¿Por qué la longitud de HashMap es una potencia de 2?
Porque esto puede hacer que la operación de cálculo de la posición del cucharón sea más eficiente.
Específicamente, si la longitud del HashMap es una potencia de 2, se pueden usar operaciones de bits en lugar de operaciones de división al calcular las posiciones de los cubos, lo que aumenta la velocidad de cálculo.
Todos sabemos que para encontrar la posición de KEY en qué ranura de la tabla hash, necesitamos calcular hash (KEY)% de longitud de matriz
Para lograr un acceso eficiente, HashMap debe minimizar las colisiones y distribuir los datos de manera uniforme. Cómo distribuir los datos de manera uniforme en este momento depende principalmente del algoritmo para almacenar datos en la lista enlazada. Este algoritmo es hash (CLAVE) y (longitud - 1) . & es una operación AND bit a bit, que es una operación de bit, y la eficiencia de la operación de bit en la computadora es muy alta, el cálculo de % es mucho más lento que &, por lo que no se utiliza la operación de %. resultado del cálculo de & es igual al resultado de %, es necesario poner longitud menos 1.
hash(CLAVE) & (longitud - 1)=hash(CLAVE) %longitud
Dado que los dos valores hash calculados son los mismos, por supuesto, es más eficiente usar &
Hice un pequeño experimento:
Suponga ahora la longitud de la matriz: 2^14 = 16384
El valor hash de la clave String = "zZ1!" es 115398910
public static void main(String[] args) {
String key = "zZ1!.";
System.out.println(key.hashCode());// 115398910
}hash & (longitud - 1) = 115398910 & 16383 = 6398 (puede usar la computadora para verificar si es correcto) El binario de 6398 es 0001100011111110
hash % longitud = 115398910 % 16384 = 6398
Esto puede aumentar considerablemente la velocidad de cálculo, porque la operación AND bit a bit es mucho más rápida que la operación de módulo.
Además, las matrices de potencia de dos manejan mejor las colisiones de hash. Cuando se utiliza una lista vinculada para resolver conflictos de hash, si la longitud de la matriz es una potencia de 2, entonces la longitud de la lista vinculada de cada depósito es de solo 8 elementos como máximo, lo que puede garantizar la eficiencia de búsqueda de la lista vinculada. Si la longitud de la matriz no es una potencia de 2, es posible que la cantidad de cubos no se distribuya de manera uniforme, lo que da como resultado una larga lista enlazada de algunos cubos, lo que afecta la eficiencia de la búsqueda.
Por lo tanto, para mejorar el rendimiento de HashMap, generalmente se recomienda establecer la longitud en una potencia de 2.
Sao Dai entiende: si la longitud de la matriz es una potencia de 2, la longitud de la lista enlazada de cada depósito es de solo 8 elementos como máximo, porque la implementación de HashMap en JDK 1.8 utiliza una estrategia llamada "basada en árboles", cuando un cubo Cuando la longitud de la lista vinculada supera los 8 elementos, la lista vinculada se convertirá en un árbol rojo-negro para mejorar la eficiencia de la búsqueda.
El requisito previo para la operación de árbol es que la longitud de la lista vinculada en el depósito supere el umbral (el valor predeterminado es 8), y si la longitud de la matriz es una potencia de 2, entonces para cualquier valor hash, la operación AND bit a bit entre it y la longitud de la matriz El resultado debe ser menor que la longitud de la matriz. Por ejemplo, si la longitud de la matriz es 16, entonces su AND bit a bit con 15 debe dar como resultado un valor entre 0 y 15 para cualquier valor hash.
Por lo tanto, si la longitud de la matriz es una potencia de 2, entonces para cualquier valor hash, el resultado de la operación AND bit a bit con la longitud de la matriz debe ser menor que la longitud de la matriz, es decir, debe ser utilizado como el subíndice del cubo. Y debido a que la longitud de la matriz es una potencia de 2, la cantidad de cubos también es una potencia de 2, por lo que se puede garantizar que la cantidad de cubos y la longitud de la matriz sean consistentes, asegurando así que la longitud de la La lista enlazada de cada cubo es de solo 8 elementos como máximo.
Cabe señalar que esta situación es solo para la implementación de HashMap en JDK 1.8.Si usa otras versiones de HashMap u otras implementaciones de tablas hash, es posible que no tenga esta propiedad.
Entonces, ¿por qué dos perturbaciones?
Respuesta: Esto es para aumentar la aleatoriedad de los bits bajos del valor hash para que la distribución sea más uniforme, mejorando así la aleatoriedad y la uniformidad de las posiciones de los subíndices del almacenamiento de matriz correspondiente y, finalmente, reduciendo los conflictos de hash. se han alcanzado los bits alto y bajo El propósito de participar simultáneamente en los cálculos;
¿Cuál es la diferencia entre HashMap y HashTable?
- Seguridad de subprocesos: HashMap no es seguro para subprocesos, y HashTable es seguro para subprocesos; los métodos internos de HashTable se modifican básicamente mediante sincronización. (Si desea garantizar la seguridad de subprocesos, utilice ConcurrentHashMap!);
- Eficiencia: debido a problemas de seguridad de subprocesos, HashMap es un poco más eficiente que HashTable. Además, HashTable es básicamente obsoleto, no lo use en su código;
- Compatibilidad con clave nula y valor nulo: en HashMap, nulo se puede usar como clave. Solo existe una clave de este tipo, y puede haber una o más claves cuyo valor correspondiente sea nulo. Pero siempre que haya un valor nulo en el valor de la clave put en HashTable, NullPointerException se lanzará directamente.
- Capacidad inicial y mecanismo de expansión: la capacidad inicial de HashTable es 11 y la capacidad inicial de HashMap es 16. Cuando la cantidad de elementos en HashTable supera 0,75 veces la capacidad, se expandirá automáticamente a 2 veces la capacidad original. Y cuando la cantidad de elementos en HashMap supere 0,75 veces la capacidad, se expandirá automáticamente a 2 veces la capacidad original, y la capacidad después de la expansión debe ser la potencia de 2.
- Estructura de datos subyacente: HashMap después de JDK1.8 ha sufrido cambios importantes en la resolución de conflictos hash.Cuando la longitud de la lista vinculada es mayor que el umbral (8 por defecto), la lista vinculada se convierte en un árbol rojo-negro para reducir la tiempo de busqueda Hashtable no tiene tal mecanismo.
Entendimiento de Sao Dai: como puede ver en los comentarios de clase de Hashtable, Hashtable es una clase reservada y no se recomienda su uso. Se recomienda usar HashMap en un entorno de subproceso único en su lugar, y usar ConcurrentHashMap en su lugar si es multiproceso. se requiere su uso.
¿Cómo decidir usar HashMap o TreeMap?
Al elegir HashMap o TreeMap, debe decidir de acuerdo con las necesidades y los escenarios específicos.
1. Eficiencia de búsqueda: si realiza principalmente operaciones de búsqueda y no requiere una alta eficiencia para las operaciones de inserción y eliminación, puede elegir TreeMap. Debido a que TreeMap se implementa internamente con un árbol rojo-negro, puede garantizar que los elementos estén en orden, que la eficiencia de búsqueda sea mayor que la de HashMap y que la complejidad del tiempo sea O (log n).
2. Eficiencia de inserción y eliminación: si realiza principalmente operaciones de inserción y eliminación, y la eficiencia de las operaciones de búsqueda no es alta, puede elegir HashMap. Debido a que HashMap se implementa internamente mediante una tabla hash, puede garantizar que la eficiencia de las operaciones de inserción y eliminación sea mayor que la de TreeMap y que la complejidad del tiempo sea O(1).
3. Uso de la memoria: si necesita operar con una gran cantidad de datos y el uso de la memoria es un problema, puede elegir HashMap. Debido a que HashMap se implementa internamente mediante una tabla hash, puede garantizar que los elementos se almacenen en una matriz y ocupa menos memoria que TreeMap.
4. Orden de los elementos: si necesita ordenar los elementos, debe elegir TreeMap. Debido a que TreeMap se implementa internamente con un árbol rojo y negro, se puede garantizar el orden de los elementos.
En resumen, si necesita realizar operaciones de búsqueda y tiene altos requisitos para el orden de los elementos, puede elegir TreeMap; si necesita realizar operaciones de inserción y eliminación y tiene altos requisitos para el uso de la memoria, puede elegir HashMap. Si necesita tener en cuenta tanto la eficiencia de búsqueda como la eficiencia de inserción y eliminación, puede usar LinkedHashMap, que se implementa en base a una tabla hash y una lista doblemente enlazada, que puede garantizar que los elementos estén en orden y la eficiencia de inserción y eliminación. operaciones de eliminación es mayor que la de TreeMap.
Estación de carga del conocimiento
- El valor de clave de TreeMap<K,V> es necesario para implementar java.lang.Comparable, por lo que TreeMap se ordena en orden ascendente por valor de clave de forma predeterminada al iterar; la implementación de TreeMap se basa en la estructura de árbol rojo-negro. Adecuado para atravesar llaves en orden natural o personalizado.
- El valor clave de HashMap<K,V> implementa hashCode(), la distribución es hash y uniforme, y no se admite la clasificación; la estructura de datos es principalmente un cubo (matriz), una lista vinculada o un árbol rojo-negro. Adecuado para insertar, eliminar y posicionar elementos en el Mapa.
¿Es seguro el subproceso HashMap? ¿por qué?
HashMap no es seguro para subprocesos.
La inseguridad del subproceso se refleja en JDK.1.7. En el caso de la expansión de subprocesos múltiples, pueden ocurrir bucles infinitos o pérdida de datos. La razón principal es que el método de inserción de encabezado utilizado en el método de expansión de transferencia invertirá el orden de la lista enlazada. ., que es la clave para provocar un bucle infinito. En JDK1.8, la expansión en el caso de subprocesos múltiples puede causar cobertura de datos. Por ejemplo, dos subprocesos A y B están realizando operaciones de colocación (la operación de colocación en HashMap en realidad está llamando al método putVal()) y los subíndices de inserción calculadas por las funciones hash de estos dos subprocesos son las mismas, cuando el subproceso A ejecuta una oración en el método putVal() para juzgar si hay una colisión hash (línea 15 del código fuente a continuación), se suspende debido al agotamiento del intervalo de tiempo (tenga en cuenta que el resultado del juicio del subproceso A en este momento es que no hay colisión hash, y el resultado del juicio se guarda, pero la siguiente oración de inserción del código del elemento no se ha ejecutado, por lo que se suspende en este tiempo), mientras que el subproceso Después de B obtiene el intervalo de tiempo, también llama al método putVal() para insertar elementos. Dado que los subíndices calculados por la función hash de los dos subprocesos son los mismos, y el subproceso A anterior se suspende porque el el segmento de tiempo se agota antes de que tenga tiempo de insertar elementos, por lo que este En ese momento, el resultado del juicio del subproceso B tampoco tiene colisión hash, e inserta el elemento directamente en el subíndice, completando la inserción normal, y luego el subproceso A obtiene el segmento de tiempo. Dado que el juicio de colisión hash se ha realizado antes, no procederá en este momento. Juicio, pero inserte directamente, lo que hace que los datos insertados por el subproceso B se sobrescriban por el subproceso A, por lo que HashMap no es seguro para subprocesos. .
razón:
- La inseguridad de subprocesos de HashMap en JDK1.7 se refleja en la expansión de subprocesos múltiples que conduce a bucles infinitos y pérdida de datos
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //线程A执行完这句后因为时间片耗尽就被挂起了
newTable[i] = e;
e = next;
}
}
}La expansión de HashMap se logra llamando al método de transferencia anterior. Después de la expansión, los elementos deben transferirse a la nueva matriz utilizando el método de inserción de encabezado. El método de inserción de encabezado invertirá el orden de la lista vinculada, que también es la clave punto de formar un bucle infinito.
El código anterior analiza principalmente las siguientes cuatro oraciones de código
//重新定义下标
Entry<K,V> next = e.next;
//下面三句就是头插法的实现
e.next = newTable[i];
newTable[i] = e;
e = next;La simulación de la expansión de la capacidad provoca un bucle infinito y pérdida de datos
Suponga que ahora hay dos subprocesos A y B que realizan operaciones de expansión en el siguiente HashMap al mismo tiempo:
El resultado después de la expansión normal es el siguiente:

Pero cuando el subproceso A termina de ejecutar la décima línea de código de la función de transferencia anterior, el intervalo de tiempo de la CPU se agota y el subproceso A se suspende. Es decir, como se muestra en la siguiente figura:
Análisis: En el subproceso A: e=3, next=7, e.next=null, puede ver que el primero en la lista enlazada en la Figura 1 es 3, y el siguiente es 7, entonces e=3 en el primera ejecución de la función de transferencia, next=7, originalmente de acuerdo con la situación en la Figura 1, debería ser e.next=7, pero el subproceso A ejecuta e.next = newTable[i], en la función de transferencia, y newTable[ i] se expandió recientemente, por lo que es nulo, por lo que después de ejecutar esta oración e.next = null
Después de suspender el subproceso A, el subproceso B se ejecuta normalmente después de obtener el intervalo de tiempo y completa la operación de expansión de cambio de tamaño. Los resultados son los siguientes:
Después de que el subproceso B complete la expansión, la nueva tabla y la tabla en la memoria principal son las últimas
Es decir, 7.next=3 y 3.next=null en la memoria principal (Aquí, me preguntaba por qué el subproceso B se expandió después de que el subproceso A obtuviera el segmento de tiempo. De hecho, el subproceso A no lo sabía en absoluto El subproceso B se ha expandido, y al subproceso A no le importa si se ha expandido o no. De todos modos, continúa ejecutando el código que no se ha ejecutado antes. Porque continúa expandiéndose en función de los datos almacenados en la memoria después del subproceso B. se expande, el subproceso A ocurrirá la siguiente pérdida de datos y bucle infinito)
Luego, el subproceso A obtiene el intervalo de tiempo de la CPU y continúa ejecutando newTable[i] = e y e = next; estas dos líneas de código, los datos del subproceso A antes de suspender son e=3, next=7, e.next=null , ejecute esto Después de dos oraciones, el resultado es newTable[3] = 3, e = 7, y la situación del subproceso A después de ejecutar esta ronda de bucle es la siguiente

Análisis: newTable[3] =3, e=7 (newTable[3] =3 aquí puede entenderse como un puntero, de hecho, newTable[3] es una matriz, entonces su valor apunta al nodo 3, e= 7 e Puede entenderse como un puntero, desde el original apuntando a 3 hasta apuntando a 7)
Luego continúe ejecutando el siguiente ciclo, en este momento e=7, al leer e.next de la memoria principal, se encuentra que 7.next=3 en la memoria principal, en este momento next=3, y ponga 7 en la forma de inserción de la cabeza en una nueva matriz y continuar ejecutando esta ronda de bucle
//此时e=7,内存中7.next=3、3.next=null,newTable[3] =3,e=7
//JMM中规定所有的变量都存储在主内存中每条线程都有自己的工作内存,
//线程的工作内存中保存了该线程所使用的变量的从主内存中拷贝的副本。
//线程对于变量的读、写都必须在工作内存中进行,而不能直接读、写主内存中的变量。
//同时,本线程的工作内存的变量也无法被其他线程直接访问,必须通过主内存完成。
Entry<K,V> next = e.next;------->next=7.next=3;
//下面三句就是头插法的实现
e.next = newTable[i];----------》e.next=3;//注意这里的e还是7,这句就是7的指针指向3
newTable[i] = e; --------------》newTable[3]=e=7;
e = next;----------------------》e=next=3;Nota: JMM estipula que todas las variables se almacenan en la memoria principal (Memoria principal), cada subproceso tiene su propia memoria de trabajo (Memoria de trabajo), y la memoria de trabajo del subproceso guarda las variables utilizadas por el subproceso de la memoria principal. copia de la copia en . Los subprocesos deben leer y escribir variables en la memoria de trabajo, pero no pueden leer y escribir directamente variables en la memoria principal. Al mismo tiempo, las variables en la memoria de trabajo de este subproceso no pueden ser accedidas directamente por otros subprocesos y deben completarse a través de la memoria principal.
Por lo tanto, después de ejecutar el subproceso B anterior, su memoria de trabajo almacena sus propios resultados de ejecución 7.next=3 y 3.next=null, luego se sincroniza la memoria principal y, finalmente, el subproceso A va a la memoria principal y lo copia en su propia memoria de trabajo
Después de ejecutar esta ronda de bucle, el resultado es el siguiente

Nota: Cuando e=3, 3.next=null Este es el resultado en la memoria principal después de que se ejecuta el subproceso B
Análisis: Lo único a lo que hay que prestar atención aquí es que cuando e.next = newTable[i] se ejecuta arriba, el resultado es e.next=3 y e es 7, no 3. Esta oración es para conectar 7 y 3, de 7 a 3. Aquí utilicé e.next=3 como base de datos para el próximo ciclo al principio, y luego sentí que debería ser la situación en el diagrama a continuación. De hecho, debería ser e.next=null como datos base cuando e=3
¡Esto está mal!
Última ronda siguiente = 3, e = 3, ejecute la siguiente ronda y puede encontrar que 3. siguiente = nulo, por lo que esta ronda de ronda será la última ronda de ronda.
//此时e=3,内存中next=3,newTable[3]=7,e=3,e.next=null
//任何一个线程的执行情况应该是放在内存中的,所以并发的时候才会出问题
//例如这个线程A去内存中拿的数据是线程B执行后的数据,已经不是线程A之前存的数据了
Entry<K,V> next = e.next;------->next=null;
//下面三句就是头插法的实现
e.next = newTable[i];----------》e.next=7;
newTable[i] = e; --------------》newTable[3]=3;
e = next;----------------------》e=3;Después de ejecutar esta ronda de bucle, el resultado es el siguiente
Cuando se encuentra next=null después de ejecutar el bucle anterior, no se realizará la siguiente ronda del bucle. En este punto, se completan las operaciones de expansión de los subprocesos A y B. Obviamente, después de la ejecución del subproceso A, aparece una estructura de anillo en el HashMap, y aparecerá un bucle infinito cuando se opere el HashMap en el futuro. Y de la figura anterior, podemos ver que el elemento 5 se perdió inexplicablemente durante la expansión, lo que provocó el problema de la pérdida de datos.
- La inseguridad del subproceso HashMap en JDK1.8 se refleja principalmente en la cobertura de datos
Si dos subprocesos A y B están realizando operaciones de colocación (la operación de colocación en HashMap en realidad está llamando al método putVal()), y los subíndices de inserción calculados por las funciones hash de estos dos subprocesos son los mismos, cuando el subproceso A Después de ejecutar una oración en el método putVal() que se usa para juzgar si hay una colisión hash (línea 15 del código fuente a continuación), se suspende debido al agotamiento del intervalo de tiempo (tenga en cuenta que el resultado del juicio del subproceso A no ocurrió en este momento) Colisión hash, el resultado del juicio se guarda, pero el siguiente código para insertar el elemento no se ha ejecutado y se suspende en este momento), y el subproceso B también llama al método putVal() para insertar el elemento después obteniendo el intervalo de tiempo, porque se calcula la función hash de los dos subprocesos Los subíndices de salida son los mismos, y el subproceso A anterior se suspende porque el intervalo de tiempo finaliza antes de que tenga tiempo de insertar el elemento, por lo que en este momento, el El resultado del juicio del subproceso B es que no hay colisión hash, y el elemento se inserta directamente en el subíndice, y se completa la inserción normal, y luego el subproceso A obtiene el segmento de tiempo. antes, por lo que el juicio no se realizará en este momento, pero la inserción se realiza directamente, lo que hace que los datos insertados por el subproceso B se sobrescriban por el subproceso A., por lo tanto, el subproceso no es seguro.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果当前map中无数据,执行resize方法。并且返回n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//判断有没有发生hash碰撞,没有就直接插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//否则的话,说明这上面有元素
else {
Node<K,V> e; K k;
//如果这个元素的key与要插入的一样,那么就替换一下,也完事。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//1.如果当前节点是TreeNode类型的数据,执行putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//还是遍历这条链子上的数据,跟jdk7没什么区别
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //true || --
e.value = value;
//3.
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断阈值,决定是否扩容
if (++size > threshold)
resize();
//4.
afterNodeInsertion(evict);
return null;
}Por lo general, hay 4 formas de resolver conflictos hash
1) El método de direccionamiento abierto, también conocido como método de detección lineal , comienza desde la posición donde ocurre el conflicto, encuentra una posición libre de la tabla hash en un orden determinado y luego almacena el elemento en conflicto en esta posición libre. ThreadLocal utiliza sondeo lineal para resolver conflictos de hash.
una situación como esta

Una clave = nombre se almacena en el índice 1 de la tabla hash. Cuando se agrega de nuevo key = hobby, el índice obtenido por el cálculo hash también es 1, lo que es un conflicto hash.
Usar el método de direccionamiento abierto es encontrar una ubicación libre hacia adelante para almacenar la clave en conflicto, es decir, si no hay datos almacenados en la posición correcta de la posición en conflicto, entonces se almacena la posición en conflicto, y si los datos son almacenado, todavía hay un conflicto Luego, continúe empujando una posición hacia la derecha hasta que los datos puedan almacenarse. Por ejemplo, después del conflicto anterior, debe colocarse en la posición del índice 2, y luego no hay datos en el en la posición del índice 2, por lo que se almacenará directamente. Si hay datos o conflicto, se colocará en la posición del índice 3, y así sucesivamente, hasta que los datos se almacenen en la tabla Hash
(2) Método de direccionamiento encadenado , que es un método muy común. Un entendimiento simple es almacenar claves con conflictos hash en una lista enlazada unidireccional. Por ejemplo, HashMap se implementa utilizando el método de direccionamiento encadenado.
una situación como esta

Las claves en conflicto se almacenan directamente en una lista enlazada unidireccional.
(3) Método de re-hash , es decir, cuando hay un conflicto en la clave calculada por una cierta función hash, se usa otra función hash para hacer hash de la clave, y la operación continúa hasta que no ocurre ningún conflicto. Este método aumentará el tiempo de cálculo y tendrá un gran impacto en el rendimiento.
(4) Para establecer un área de desbordamiento pública , la tabla hash se divide en dos partes: la tabla básica y la tabla de desbordamiento, y todos los elementos en conflicto se colocan en la tabla de desbordamiento.
Suplemento: en la versión JDK1.8, HashMap resuelve el problema del conflicto hash a través del método de direccionamiento en cadena + árbol rojo-negro. El árbol rojo-negro es para optimizar el problema del aumento de la complejidad del tiempo causado por una lista enlazada demasiado larga de la tabla Hash. Cuando la longitud de la lista enlazada es superior a 8 y la capacidad de la tabla hash es superior a 64, la adición de elementos a la lista enlazada activará la conversión.
HashMap no es seguro para subprocesos, ¿qué sucede si desea garantizar la seguridad de subprocesos? ¿Qué se puede usar?
(1) Usar HashTable (no recomendado)
mapa de mapa privado = new Hashtable<>()
Se encuentra en el código fuente de HashTable que todos sus métodos get/put son modificados por la palabra clave sincronizada (esta modificación de palabra clave significa que este método tiene un bloqueo de sincronización, que es equivalente a cuando cualquier subproceso se ejecuta en este método, primero verifique si hay hay otros subprocesos que usan este método), si hay uno, debe esperar a que el subproceso anterior termine de usarlo antes de que el subproceso actual pueda usarlo)
Debido a esto, la seguridad de subprocesos de Hash Table se basa en el bloqueo a nivel de método. Ocupan recursos compartidos, por lo que solo un subproceso puede operar get o put al mismo tiempo, y las operaciones get y put no se pueden ejecutar al mismo tiempo. , por lo que esta colección síncrona es muy ineficiente y generalmente no se recomienda usar esta colección.
(2) Usar SynchronizedMap (no recomendado)
mapa de mapa privado = Collections.synchronizedMap(newHashMap())
Esto es para usar directamente el método en la clase de herramienta para crear el objetosynchronedMap devuelto porsynchronizedMapCollections.synchronizedMap(newHashMap()) y envolver el objeto HashMap entrante.
La implementación de este método de sincronización también es relativamente simple. Se puede ver que la implementación de SynchronizedMap es agregar un bloqueo de objeto (HashTable agrega un bloqueo de sincronización y SynchronizedMap agrega un bloqueo de objeto). Cada vez que opera en HashMap, debe primero obtenga este objeto mutex Ingrese, por lo que el rendimiento no será mejor que HashTable, y no se recomienda usarlo.
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
...
}
//SynchronizedMap的put方法,实际调用的还是HashMap自己的put方法
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}(3) ConcurrentHashMap (recomendado)
Mapa de mapa privado = nuevo ConcurrentHashMap<>()
Esta estructura de implementación es la más compleja, pero también es el mapa seguro para subprocesos más eficiente y recomendado, y cada versión se implementa de una manera diferente. Jdk8 usó el bloqueo segmentado antes, dividido en 16 cubos, y solo bloqueó uno de los cubos a la vez, y jdk8 agregó un árbol rojo-negro y un algoritmo CAS para lograrlo.
ConcurrentHashMapConcurrentHashMap
¿Qué es ConcurrentHashMap? ¿Qué es el principio de realización?
En un entorno de subprocesos múltiples, los datos pueden perderse al usar HashMap para operaciones de colocación. Para evitar el peligro oculto de tales errores, se recomienda enfáticamente usar ConcurrentHashMap en lugar de HashMap.
HashTable es una clase segura para subprocesos. Utiliza sincronizado para bloquear toda la tabla Hash para lograr la seguridad de subprocesos, es decir, cada vez que se bloquea toda la tabla para permitir que el subproceso monopolice, es equivalente a todos los subprocesos compitiendo por un bloqueo al leer y escritura, lo que resulta en una eficiencia muy baja.
ConcurrentHashMap puede leer datos sin bloqueos, y su estructura interna le permite mantener la granularidad de los bloqueos lo más pequeña posible al escribir operaciones, lo que permite que varias operaciones de modificación se realicen al mismo tiempo.La clave es utilizar la tecnología de segmentación de bloqueos. Utiliza múltiples bloqueos para controlar las modificaciones a diferentes partes de la tabla hash. Para la implementación de la versión JDK1.7, ConcurrentHashMap utiliza internamente segmentos (Segment) para representar estas diferentes partes.Cada segmento es en realidad una pequeña Hashtable con su propio candado. Varias operaciones de modificación pueden realizarse simultáneamente siempre que ocurran en diferentes segmentos. La implementación de JDK1.8 reduce la granularidad de los bloqueos. La granularidad de los bloqueos de JDK1.7 se basa en Segment y contiene múltiples HashEntry, mientras que la granularidad de los bloqueos de JDK1.8 es HashEntry (el primer nodo).
Principio de realización
JDK1.7
El ConcurrentHashMap en JDK1.7 se compone de una estructura de matriz de segmento y una estructura de HashEntry de matriz de lista vinculada, es decir, ConcurrentHashMap divide la matriz de cubo hash en varios segmentos, y cada segmento se compone de n matrices de lista vinculada (HashEntry), es decir , a través de bloqueo de segmentación para lograr.
El proceso de ConcurrentHashMap para ubicar un elemento requiere dos operaciones Hash. El primer Hash ubica el segmento y el segundo Hash ubica el encabezado de la lista enlazada donde se encuentra el elemento. Por lo tanto, el efecto secundario de esta estructura es el proceso Hash. es más largo que el HashMap común, pero la ventaja es que al escribir operaciones, solo puede operar en el Segmento donde se encuentra el elemento, y no afectará a otros Segmentos. De esta manera, en el mejor de los casos, ConcurrentHashMap puede ser el más alto en Al mismo tiempo, se admiten operaciones de escritura del tamaño del segmento (sucede que estas operaciones de escritura se distribuyen de manera muy uniforme en todos los segmentos), por lo que, a través de esta estructura, la capacidad de concurrencia de ConcurrentHashMap se puede mejorar en gran medida.
Como se muestra en la figura a continuación, los datos primero se dividen en segmentos para su almacenamiento y luego se asigna un bloqueo a cada segmento de datos. Cuando un subproceso ocupa un bloqueo para acceder a un segmento de datos, los datos de otros segmentos también pueden ser accedido por otros segmentos El acceso de subprocesos realiza un acceso concurrente real.
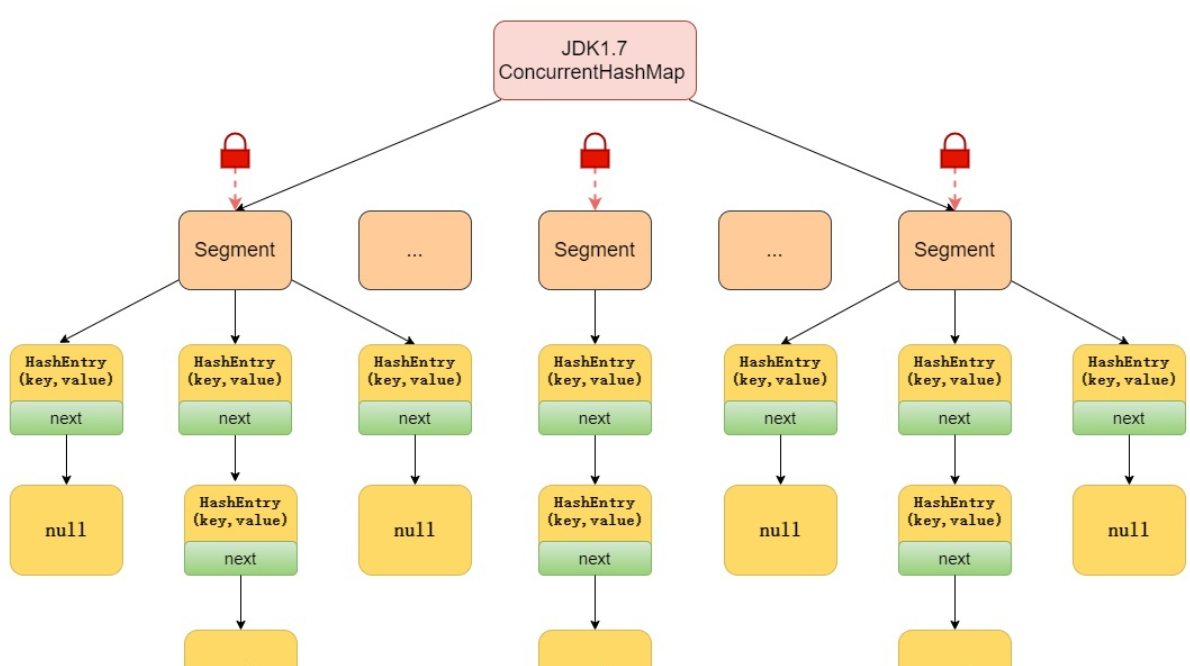
Segment es una clase interna de ConcurrentHashMap, los componentes principales son los siguientes:

Segment hereda ReentrantLock, por lo que Segment es un bloqueo reentrante que actúa como bloqueo. El segmento es 16 por defecto, es decir, la concurrencia es 16.
HashEntry, que almacena elementos, también es una clase interna estática y sus componentes principales son los siguientes:
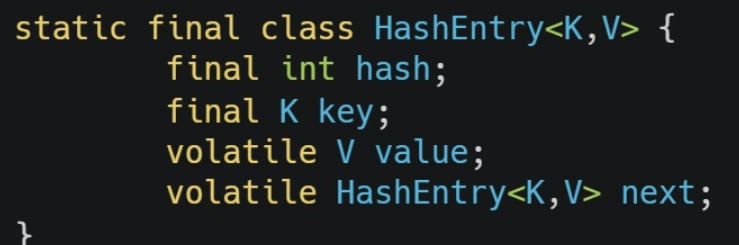
Entre ellos, el valor de los datos de HashEntry y el siguiente nodo se modifican con volatile para garantizar la visibilidad de la adquisición de datos en un entorno de subprocesos múltiples.
¿Por qué usar hash secundario?
La razón principal es construir un bloqueo separado para que la modificación del mapa no bloquee todo el contenedor y mejore la capacidad de concurrencia. Por supuesto, nada es absolutamente perfecto. El problema causado por el segundo hash es que todo el proceso de hash es más largo que el hash único del hashmap. Por lo tanto, si no es una situación concurrente, no use concurrentHashmap.
Antes de JAVA7, ConcurrentHashMap usaba principalmente el mecanismo de bloqueo de segmentación. Cuando operaba en un segmento, el segmento estaba bloqueado y no se permitían operaciones que no fueran de consulta. Sin embargo, después de JAVA8, se adoptó el algoritmo sin bloqueo CAS. Esta operación optimista se realiza antes de su finalización.Haga un juicio, y ejecútelo solo si cumple con los resultados esperados, proporcionando una buena optimización para operaciones concurrentes.
JDK1.8
En términos de estructura de datos, ConcurrentHashMap en JDK1.8 elige la misma matriz de nodos + lista vinculada + estructura de árbol rojo-negro que HashMap; en términos de implementación de bloqueo, se abandona el bloqueo de segmento de segmento original y se utiliza CAS + sincronizado para lograr Cerraduras granulares más detalladas.
El nivel de bloqueo se controla a nivel de elementos de matriz de cubo hash de grano más fino, es decir, solo se debe bloquear el nodo principal de la lista vinculada o el nodo raíz del árbol rojo-negro, y la lectura de otros los elementos de la matriz hash bucket no se verán afectados. Write, mejorando en gran medida la concurrencia.

¿Cuál es el uso de la decoración final y volátil para las variables en ConcurrentHashMap?
En ConcurrentHashMap, el uso de final y volatile para modificar variables puede mejorar la seguridad y la visibilidad de los subprocesos. Las funciones específicas son las siguientes:
1. final: una variable modificada con final representa una variable inmutable, es decir, el valor de la variable no se puede modificar después de la inicialización. En ConcurrentHashMap, usar final para modificar la clave y las variables hash en la clase Node puede garantizar que no se modificarán después de la inicialización, lo que evita la competencia y los conflictos entre varios subprocesos. Las variables modificadas finales pueden garantizar que se pueda acceder a las variables y compartirlas sin sincronización
2. volatile: Una variable modificada con volatile significa que la variable es visible, es decir, la modificación de la variable será inmediatamente percibida por otros hilos. En ConcurrentHashMap, las variables count y modCount en la clase Segment están decoradas con volatile para garantizar que sus modificaciones sean visibles para otros subprocesos, evitando así conflictos entre subprocesos e inconsistencias de datos.
Cabe señalar que, aunque el uso de final y volatile para modificar variables puede mejorar la seguridad y la visibilidad de los subprocesos, no se puede garantizar por completo la seguridad y la corrección de los subprocesos. Al usar ConcurrentHashMap, también debe prestar atención a otros problemas de seguridad de subprocesos, como el uso de iteradores, la atomicidad de las operaciones compuestas, etc.
¿Por qué usar sincronizado en lugar de ReentrantLock en CocurrentHashMap de JDK1.8?
En JDK1.8, ConcurrentHashMap optimiza internamente la implementación de bloqueos y utiliza operaciones CAS y palabras clave sincronizadas para reemplazar el bloqueo reentrante original ReentrantLock. Las razones principales son las siguientes:
1. Optimización del rendimiento: el uso de la palabra clave sincronizada puede evitar la pérdida de rendimiento causada por la operación CAS en ReentrantLock, mejorando así el rendimiento de la concurrencia.
2. Mejorar el rendimiento: ConcurrentHashMap es una clase de implementación de tabla hash altamente concurrente que necesita admitir varios subprocesos para operaciones simultáneas de lectura y escritura. El uso de la palabra clave sincronizada puede reducir la competencia y los conflictos de bloqueo, mejorando así el rendimiento y el rendimiento simultáneo.
3. Simplificar el código: el uso de la palabra clave sincronizada puede evitar operaciones complejas que requieren bloqueo y desbloqueo manual en ReentrantLock, lo que simplifica la implementación del código. Esto puede reducir la complejidad del código y la posibilidad de errores, y mejorar la mantenibilidad y legibilidad del código.
Cabe señalar que aunque ConcurrentHashMap usa la palabra clave sincronizada para reemplazar ReentrantLock en JDK1.8, no está sincronizada en el sentido tradicional, sino que usa tecnología de segmentación de bloqueo para dividir toda la tabla hash en múltiples segmentos, cada segmento tiene un bloqueo independiente. que permite un acceso concurrente eficiente. Esta tecnología de segmentación de bloqueo puede evitar el problema de la granularidad de bloqueo demasiado grande o demasiado pequeña, mejorando así el rendimiento y la escalabilidad de la concurrencia.
Sao Dai entiende: el rendimiento del uso sincronizado es mejor en situaciones competitivas y no competitivas. Dado que la palabra clave sincronizada se puede actualizar automáticamente a bloqueos optimizados, como bloqueos ligeros y bloqueos giratorios, se evita la sobrecarga del bloqueo y la conmutación de subprocesos, lo que mejora el rendimiento de la simultaneidad. ReentrantLock, por otro lado, requiere bloqueo y desbloqueo manual, y operaciones complejas como operaciones CAS, lo que resulta en una pérdida de rendimiento.
¿Podemos usar CocurrentHashMap en lugar de Hashtable?
Sabemos que Hashtable está sincronizado, pero ConcurrentHashMap tiene un mejor rendimiento de sincronización porque solo bloquea parte del mapa según el nivel de sincronización. Por supuesto, ConcurrentHashMap puede reemplazar a HashTable, pero HashTable proporciona una seguridad de subprocesos más sólida. Todos se pueden usar en un entorno de subprocesos múltiples, pero cuando el tamaño de Hashtable aumenta a un cierto nivel, el rendimiento se reducirá drásticamente, ya que debe bloquearse durante mucho tiempo durante la iteración. Debido a que ConcurrentHashMap introduce la segmentación (segmentación), no importa qué tan grande se vuelva, solo una parte determinada del mapa debe bloquearse y otros subprocesos no necesitan esperar hasta que se complete la iteración para acceder al mapa. En resumen, durante la iteración, ConcurrentHashMap solo bloquea una determinada parte del mapa, mientras que Hashtable bloquea todo el mapa.
¿Hay ventajas y desventajas de ConcurrentHashMap?
ventaja
1. Alto rendimiento de simultaneidad: ConcurrentHashMap utiliza internamente la tecnología de segmentación de bloqueo para dividir toda la tabla hash en varios segmentos, y cada segmento tiene un bloqueo independiente, logrando así un acceso simultáneo eficiente. En el caso de acceso simultáneo por varios subprocesos, ConcurrentHashMap puede proporcionar un alto rendimiento y rendimiento simultáneos.
2. Seguridad de subprocesos: ConcurrentHashMap es una clase de implementación de tabla hash segura para subprocesos que puede admitir múltiples subprocesos para leer y escribir operaciones al mismo tiempo sin medidas de sincronización adicionales. En el caso de acceso simultáneo por varios subprocesos, ConcurrentHashMap puede garantizar la consistencia y corrección de los datos.
3. Escalabilidad: ConcurrentHashMap utiliza internamente la tecnología de segmentación de bloqueos, que puede ajustar la granularidad y la cantidad de bloqueos según las necesidades reales, para lograr la escalabilidad. En el caso de acceso simultáneo por varios subprocesos, ConcurrentHashMap puede ajustar dinámicamente el número y el tamaño de los bloqueos según la situación de simultaneidad real para proporcionar un mejor rendimiento de simultaneidad.
4. Iterador eficiente: el iterador dentro de ConcurrentHashMap es un iterador de falla rápida, que puede detectar la modificación de la tabla hash por otros subprocesos durante el proceso de iteración, evitando así errores e inconsistencias de datos. En el caso de acceso simultáneo por varios subprocesos, ConcurrentHashMap puede proporcionar operaciones de iterador eficientes para admitir el acceso y el cruce de datos.
5. Personalización: ConcurrentHashMap proporciona muchos parámetros personalizables y opciones de configuración, y parámetros como el tamaño de la tabla hash, el factor de carga y el nivel de concurrencia se pueden ajustar según las necesidades reales para lograr un mejor rendimiento y escalabilidad.
defecto
1. Uso de la memoria: ConcurrentHashMap necesita mantener múltiples segmentos y múltiples listas vinculadas para admitir operaciones de lectura y escritura altamente simultáneas, lo que resulta en un alto uso de la memoria. En el caso de una gran cantidad de datos, puede causar problemas como el desbordamiento de memoria.
2. Desorden: ConcurrentHashMap utiliza internamente una tabla hash para almacenar datos.La tabla hash se caracteriza por el desorden, por lo que no se puede garantizar el orden de los datos. Si es necesario acceder a los datos en un orden determinado, se requieren operaciones de clasificación adicionales.
3. Consistencia débil del iterador: El iterador dentro de ConcurrentHashMap es débilmente consistente, es decir, durante el proceso de iteración, si otros subprocesos modifican la tabla hash, el iterador generará una ConcurrentModificationException. Por lo tanto, al usar iteradores para acceder a ConcurrentHashMap, debe prestar atención a la seguridad de subprocesos y al manejo de excepciones.
4. Costo de expansión: ConcurrentHashMap debe expandirse internamente para admitir más almacenamiento de datos y un mayor rendimiento de simultaneidad. Sin embargo, la operación de expansión requiere operaciones complejas, como la migración de datos y la reconstrucción de la tabla hash, lo que puede provocar una degradación del rendimiento y un aumento de la latencia.
Diferencia de ConcurrentHashMap entre JDK 7 y 8
ConcurrentHashMap se ha mejorado y optimizado tanto en JDK 7 como en JDK 8. Las principales diferencias son las siguientes:
1. Estructura de datos: ConcurrentHashMap en JDK 7 utiliza internamente la tecnología de bloqueo de segmentos para lograr el acceso simultáneo.Cada segmento es una tabla hash independiente que se puede leer y escribir de forma independiente. ConcurrentHashMap en JDK 8 utiliza la operación CAS y la estructura de lista enlazada/árbol rojo-negro para lograr un acceso simultáneo, que puede admitir mejor datos de gran escala y alta simultaneidad.
2. Rendimiento concurrente: ConcurrentHashMap en JDK 8 ha mejorado el rendimiento de concurrencia, principalmente porque utiliza operaciones CAS y listas enlazadas/estructuras de árbol rojo-negro para lograr acceso concurrente, reduciendo la competencia de bloqueo y la sobrecarga, mejorando así el rendimiento de concurrencia. JDK1.7 utiliza el mecanismo de bloqueo de segmentación de Segment para lograr la seguridad de subprocesos, en el que Segment hereda de ReentrantLock. JDK1.8 utiliza CAS+sincronizado para garantizar la seguridad de los subprocesos.
3. Uso de memoria: ConcurrentHashMap en JDK 8 ha mejorado en términos de uso de memoria, principalmente porque usa una lista enlazada/estructura de árbol rojo-negro para almacenar datos, lo que puede hacer un mejor uso del espacio de memoria y reducir el uso de memoria.
4. Estrategia de expansión: ConcurrentHashMap en JDK 8 ha mejorado en términos de estrategia de expansión, principalmente porque utiliza una lista enlazada/estructura de árbol rojo-negro para almacenar datos, lo que puede admitir mejor la expansión simultánea, reducir la migración de datos y reconstruir la sobrecarga de la tabla hash .
5. Interfaz API: ConcurrentHashMap en JDK 8 agrega algunas interfaces API nuevas, como forEach, reduce, search, etc., que pueden atravesar y operar la tabla hash de manera más conveniente.
6. La granularidad del bloqueo: JDK1.7 es para bloquear el segmento que necesita realizar operaciones de datos, y JDK1.8 se ajusta para bloquear el nodo raíz del árbol rojo-negro o el nodo principal de la lista enlazada
¿Cuál es la concurrencia de ConcurrentHashMap en Java?
La concurrencia se puede entender como el número máximo de subprocesos que pueden actualizar ConccurentHashMap al mismo tiempo cuando el programa se ejecuta sin competencia de bloqueo. En JDK1.7, en realidad es el número de bloqueos de segmento en ConcurrentHashMap, es decir, la longitud de la matriz de Segment[], el valor predeterminado es 16 y este valor se puede establecer en el constructor.
Si establece el grado de concurrencia usted mismo, ConcurrentHashMap utilizará la potencia más pequeña de 2 mayor o igual que el valor como el grado de concurrencia real, es decir, si establece el valor en 17 (24<17<25), entonces el valor real grado de concurrencia es 32 (25).
Si la configuración de simultaneidad es demasiado pequeña, causará serios problemas de competencia de bloqueo; si la configuración de simultaneidad es demasiado alta, el acceso originalmente ubicado en el mismo segmento se extenderá a diferentes segmentos y la tasa de aciertos de la memoria caché de la CPU disminuirá, lo que hará que el rendimiento del programa degrada
En JDK1.8, se ha abandonado el concepto de segmento y se ha elegido la estructura de matriz de nodos + lista enlazada + árbol rojo-negro, y la concurrencia depende del tamaño de la matriz.
¿El iterador ConcurrentHashMap es de consistencia fuerte o de consistencia débil?
Los iteradores de ConcurrentHashMap son débilmente consistentes, no muy consistentes.
Un iterador débilmente consistente significa que el iterador puede ver la modificación de la tabla hash por otros subprocesos durante el proceso transversal, pero no se puede garantizar la consistencia y corrección de los resultados transversales. Si otros subprocesos modifican la tabla hash durante el recorrido, puede hacer que el iterador arroje una ConcurrentModificationException, o recorrer para duplicar o faltar elementos.
Esto se debe a que ConcurrentHashMap utiliza internamente la tecnología de bloqueo de segmentos para lograr el acceso simultáneo, y cada segmento tiene un bloqueo independiente, que se puede leer y escribir de forma independiente. Durante el recorrido, si otros hilos modifican el mismo segmento, puede hacer que el iterador atraviese elementos inconsistentes. Por lo tanto, el iterador de ConcurrentHashMap solo puede garantizar la consistencia final, no la consistencia fuerte.
Para evitar excepciones y errores del iterador, se pueden usar bloqueos u otras medidas de sincronización durante el recorrido. También puede usar las nuevas interfaces API de ConcurrentHashMap para cada uno, reducir, buscar, etc., que usan un método transversal más seguro y confiable para evitar mejor las excepciones y los errores del iterador.
¿Por qué ConcurrentHashMap no admite la clave o el valor es nulo?
Debido a que ConcurrentHashMap se usa para subprocesos múltiples, si ConcurrentHashMap.get (clave) se vuelve nulo, habrá ambigüedad, puede que no exista tal clave o puede haber tal clave pero el valor correspondiente es nulo
Entonces, ¿por qué HashMap no tiene esta ambigüedad?
Puede llamar al método containsKey para juzgar la ambigüedad. Si no hay clave, devolverá falso. Si hay esta clave pero el valor correspondiente es nulo, devolverá verdadero. Puede usar este método para distinguir la ambigüedad mencionada anteriormente. Tenga en cuenta que el método containsKey HashMap y There están ambos en ConcurrentHashMap. La razón por la que uno es ambiguo y el otro no es ambiguo es principalmente porque uno es de subproceso único y el otro es de subprocesos múltiples.
public boolean containsKey(Clave de objeto) {
return getNode(hash(key), key) != null;
}
Por qué ConcurrentHashMap no puede resolver el problema de la ambigüedad
Debido a que ConcurrentHashMap es seguro para subprocesos, generalmente se usa en un entorno concurrente. Después de obtener un valor nulo al comienzo del método get y luego llamar al método containsKey, no hay forma de garantizar que no haya otro subproceso que cause problemas. entre el método get y el método containsKey La clave que desea consultar se establece o elimina.
¿Cuál es la diferencia entre SynchronizedMap y ConcurrentHashMap?
Tanto SynchronizedMap como ConcurrentHashMap son clases de implementación de mapas seguras para subprocesos, pero existen las siguientes diferencias entre ellas:
1. Estructura de datos: SynchronizedMap se implementa en función de Hashtable, mientras que ConcurrentHashMap se implementa en función de Hashtable.
2. Rendimiento simultáneo: ConcurrentHashMap es mejor que SynchronizedMap en términos de rendimiento simultáneo, porque utiliza tecnología de bloqueo segmentado para lograr acceso simultáneo y puede realizar operaciones de lectura y escritura al mismo tiempo, mientras que SynchronizedMap necesita usar bloqueos de sincronización para garantizar la seguridad de subprocesos. Bajo rendimiento en entornos concurrentes.
3. Granularidad de bloqueo: ConcurrentHashMap tiene una granularidad de bloqueo más fina y puede admitir una mayor simultaneidad, mientras que SynchronizedMap tiene una granularidad de bloqueo más gruesa y solo puede admitir el acceso de un solo subproceso.
4. Estrategia de expansión: la estrategia de expansión de ConcurrentHashMap es mejor y se puede expandir sin afectar el rendimiento de la concurrencia, mientras que la estrategia de expansión de SynchronizedMap necesita usar bloqueos de sincronización para garantizar la seguridad de subprocesos, lo que puede afectar el rendimiento de la concurrencia.
5. Valor nulo: ConcurrentHashMap no admite que la clave o el valor sean nulos, mientras que SynchronizedMap permite que la clave o el valor sean nulos.
En resumen, aunque SynchronizedMap y ConcurrentHashMap son clases de implementación de mapas seguras para subprocesos, existen diferencias en el rendimiento de concurrencia, la granularidad de bloqueo, la estrategia de expansión y el valor nulo. Por lo tanto, en el desarrollo real, es necesario elegir la adecuada de acuerdo con el escenario de aplicación específico Clase de implementación. Si necesita admitir alta simultaneidad, datos a gran escala y valores nulos, se recomienda usar ConcurrentHashMap, y si la cantidad de datos es pequeña, puede usar SynchronizedMap.
La diferencia entre HashMap y ConcurrentHashMap
Tanto HashMap como ConcurrentHashMap son colecciones de mapas implementadas por tablas hash, pero existen las siguientes diferencias entre ellas:
1. Seguridad de subprocesos: HashMap no es seguro para subprocesos, mientras que ConcurrentHashMap sí lo es. ConcurrentHashMap usa tecnología de bloqueo segmentado para lograr acceso simultáneo y puede realizar operaciones de lectura y escritura al mismo tiempo, mientras que HashMap necesita usar bloqueos de sincronización para garantizar la seguridad de subprocesos, por lo que su rendimiento es deficiente en entornos de alta concurrencia.
2. Rendimiento concurrente: ConcurrentHashMap es mejor que HashMap en términos de rendimiento de concurrencia, ya que utiliza tecnología de bloqueo segmentado para lograr acceso concurrente y puede realizar operaciones de lectura y escritura al mismo tiempo, mientras que HashMap necesita usar bloqueos de sincronización para garantizar la seguridad de subprocesos. Bajo rendimiento en entornos concurrentes.
3. Granularidad de bloqueo: ConcurrentHashMap tiene una granularidad de bloqueo más fina y puede admitir una mayor simultaneidad, mientras que HashMap tiene una granularidad de bloqueo más gruesa y solo puede admitir el acceso mediante un solo subproceso.
4. Estrategia de expansión: la estrategia de expansión de ConcurrentHashMap es mejor y se puede expandir sin afectar el rendimiento concurrente, mientras que la estrategia de expansión de HashMap necesita usar bloqueos de sincronización para garantizar la seguridad de subprocesos, lo que puede afectar el rendimiento concurrente.
5. Valor nulo: ConcurrentHashMap no admite que la clave o el valor sean nulos, mientras que HashMap permite que la clave o el valor sean nulos.
En resumen, aunque tanto HashMap como ConcurrentHashMap son colecciones de mapas implementadas por tablas hash, existen diferencias en la seguridad de subprocesos, el rendimiento de simultaneidad, la granularidad de bloqueo, la estrategia de expansión y el valor nulo. Seleccione la clase de implementación adecuada para el escenario de la aplicación. Si necesita admitir datos de alta simultaneidad y a gran escala, se recomienda utilizar ConcurrentHashMap. Si la cantidad de datos es pequeña, puede utilizar HashMap.
¿La diferencia entre ConcurrentHashMap y Hashtable?
Tanto ConcurrentHashMap como Hashtable son clases de implementación de tablas hash seguras para subprocesos, pero existen las siguientes diferencias entre ellas:
1. Estructura de datos: ConcurrentHashMap se implementa en función de la tabla hash y Hashtable se implementa en función del método de sincronización.
2. Rendimiento concurrente: ConcurrentHashMap es mejor que Hashtable en términos de rendimiento de concurrencia, porque utiliza tecnología de bloqueo segmentado para lograr acceso concurrente y puede realizar operaciones de lectura y escritura al mismo tiempo, mientras que Hashtable necesita usar bloqueos de sincronización para garantizar la seguridad de subprocesos. Bajo rendimiento en entornos concurrentes.
3. Granularidad de bloqueo: ConcurrentHashMap tiene una granularidad de bloqueo más fina y puede admitir una mayor simultaneidad, mientras que Hashtable tiene una granularidad de bloqueo más gruesa y solo puede admitir el acceso mediante un solo subproceso.
4. Estrategia de expansión: la estrategia de expansión de ConcurrentHashMap es mejor y se puede expandir sin afectar el rendimiento de la concurrencia, mientras que la estrategia de expansión de Hashtable necesita usar bloqueos de sincronización para garantizar la seguridad de subprocesos, lo que puede afectar el rendimiento de la concurrencia.
5. Valor nulo: ConcurrentHashMap no admite clave o valor nulo, mientras que Hashtable permite clave o valor nulo.
6. Iterador: el iterador de ConcurrentHashMap es poco coherente y se puede modificar simultáneamente durante el proceso de iteración, mientras que el iterador de Hashtable es muy coherente y no permite la modificación simultánea durante el proceso de iteración.
En resumen, aunque ConcurrentHashMap y Hashtable son clases de implementación de tablas hash seguras para subprocesos, existen diferencias en la seguridad de subprocesos, el rendimiento de concurrencia, la granularidad de bloqueo, la estrategia de expansión, el valor nulo y el iterador, etc., por lo que en el desarrollo real es necesario seleccione la clase de implementación adecuada de acuerdo con el escenario de aplicación específico. Si necesita admitir alta simultaneidad, datos a gran escala y valores nulos, se recomienda usar ConcurrentHashMap, y si la cantidad de datos es pequeña, puede usar Hashtable.
Un gráfico de comparación de los dos: HashTable:

JDK1.7, mapa hash concurrente:
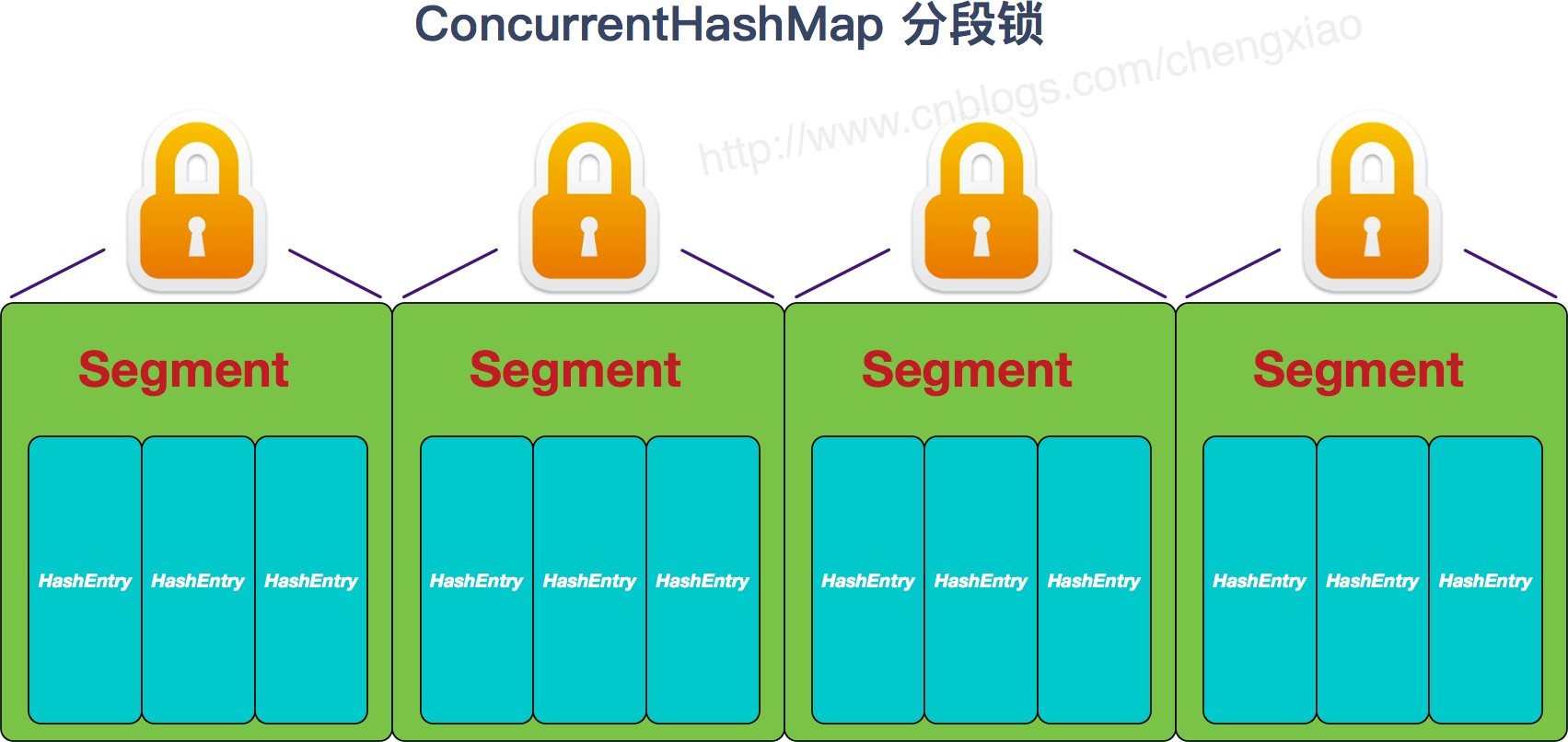
ConcurrentHashMap de JDK1.8 (TreeBin: nodo de árbol binario rojo y negro Nodo: nodo de lista enlazada):
ConcurrentHashMap combina las ventajas de HashMap y HashTable. HashMap no considera la sincronización y HashTable considera la sincronización. Pero HashTable bloquea toda la estructura cada vez que se ejecuta de forma síncrona. La forma en que se bloquea ConcurrentHashMap es ligeramente detallada.