Directorio de artículos
- original
- 1. ¿Qué es un proceso?
- 2. ¿Qué es un hilo?
- 3. Qué es concurrencia y qué es paralelismo
- 4. ¿Por qué usar subprocesos múltiples?
- 5. ¿Qué problemas puede causar el uso de subprocesos múltiples?
- 6. Hable sobre el ciclo de vida y el estado de los hilos
- 7. ¿Por qué se ejecuta el método run() cuando se llama al método start()?¿Por qué no podemos llamar directamente al método run()?
- 8. ¿Qué es el cambio de contexto?
- 9. ¿Qué es el interbloqueo de subprocesos?
- 10. Por qué se produce un interbloqueo (4)
- 11. Cómo evitar el interbloqueo de subprocesos (3)
- 12. Cómo resolver el punto muerto
- 13. ¿Qué son los bloqueos justos y los bloqueos injustos?
- 14. ¿Qué es una cerradura reentrante?
- 15. ¿Qué son los candados pesimistas y los candados optimistas?
- 16. ¿Cómo elige bloqueos pesimistas y bloqueos optimistas?
- 17. ¿Qué es un bloqueo giratorio?
- 18. ¿Qué es un bloqueo exclusivo (escritura) y un bloqueo compartido (lectura)?
- 19. ¿Por qué usar un bloqueo de lectura y escritura?
- 20. Cuéntame sobre las diferencias y similitudes entre el método sleep() y el método wait().
- 21. Hable sobre la comprensión de la palabra clave sincronizada
- 22. ¿Por qué el sincronizado anterior era ineficiente?
- 23. ¿Qué se ha optimizado sincronizado después de JDK1.6?
- 24. ¿Cómo se usa la palabra clave sincronizada? (3)
- 25. ¿Se puede modificar el método de construcción con sincronizado?
- 26. Hable sobre el principio subyacente de sincronización
- 27. Hable sobre la diferencia entre sincronizado y ReentrantLock (5)
- 28. Hable sobre JMM (modelo de memoria Java)
- 29. ¿Qué significa volátil?
- 30. ¿Dónde has usado volátiles?
- 31. La diferencia entre sincronizado y volátil
- 32. Cómo solucionar el problema de no garantizar atomicidad
- 33. ¿Por qué agregar AtomicInteger puede resolver el problema de no garantizar la atomicidad?
- 34. El principio subyacente de CAS
- 35. ¿Cuáles son las desventajas de CAS (3)
- 36. Preguntas ABA
- 37, hilo local
- 38. ¿Entiendes las fugas de memoria de ThreadLocal?
- 39. Los beneficios de usar el grupo de subprocesos
- 40. La diferencia entre implementar la interfaz Runnable y la interfaz Callable
- 41. Grupo de hilos
- 42. ¿Ha entendido AQS?
- 43. Componentes de AQS
original
Original: https://www.yuque.com/unityalvin/baguwen/xbg8ds
1. ¿Qué es un proceso?
Cada programa que se ejecuta en segundo plano es un proceso
2. ¿Qué es un hilo?
Un subproceso es la unidad más pequeña en la que un sistema operativo puede realizar la programación de operaciones. Está incluido en el proceso y es la unidad operativa real en el proceso.
3. Qué es concurrencia y qué es paralelismo
Paralelo significa que dos o más eventos ocurren al mismo tiempo, mientras que simultaneidad significa que dos o más eventos ocurren en el mismo intervalo de tiempo.
4. ¿Por qué usar subprocesos múltiples?
Desde el fondo de la computadora: un subproceso se puede comparar con un proceso liviano, que es la unidad más pequeña de ejecución del programa.El costo de cambiar y programar entre subprocesos es mucho menor que el de un proceso. Además, la era de las CPU multinúcleo significa que varios subprocesos pueden ejecutarse simultáneamente, lo que reduce la sobrecarga del cambio de contexto de subprocesos.
Desde la perspectiva de las tendencias contemporáneas de desarrollo de Internet: El sistema actual requiere millones o incluso decenas de millones de concurrencia, y la programación concurrente de subprocesos múltiples es la base para desarrollar sistemas de alta concurrencia. Hacer un buen uso de los mecanismos de subprocesos múltiples puede mejorar en gran medida la concurrencia general del sistema, capacidad y rendimiento.
5. ¿Qué problemas puede causar el uso de subprocesos múltiples?
El propósito de usar subprocesos múltiples es mejorar la eficiencia de ejecución y la velocidad de ejecución del programa, pero esto no significa que los subprocesos múltiples sean omnipotentes. Se pueden encontrar muchos problemas en el proceso de uso de subprocesos múltiples, como: fugas de memoria, interbloqueos, inseguridad de subprocesos. etc.
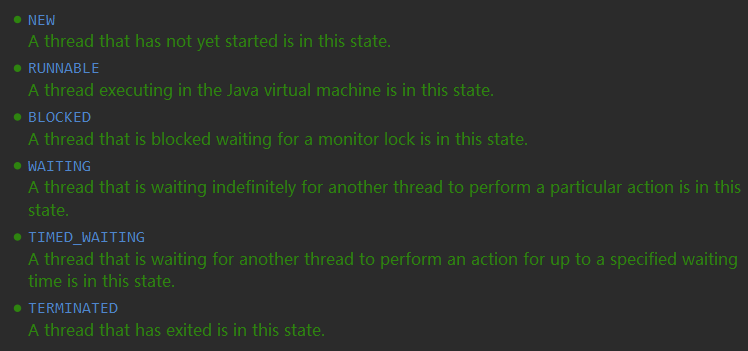
6. Hable sobre el ciclo de vida y el estado de los hilos
- Después de crear el hilo, estará en estado NUEVO (nuevo),
- Después de llamar al método start() para comenzar a ejecutarse, el subproceso entrará en el estado READY (listo).
- El subproceso que está listo entrará en el estado EN EJECUCIÓN (en ejecución) después de obtener el intervalo de tiempo de la CPU (intervalo de tiempo).
- Cuando el subproceso ejecuta el método wait(), el subproceso entrará en el estado ESPERANDO (esperando). Los subprocesos que ingresan al estado de espera deben depender de las notificaciones de otros subprocesos para volver al estado de ejecución.
- Mediante el método sleep(long millis) o el método wait(long millis), el subproceso se puede establecer en el estado TIME_WAITING (tiempo de espera de espera), que es equivalente a agregar un período de tiempo de espera al estado de espera. volver al estado listo
- Cuando un subproceso llama a un método de sincronización, si no se adquiere el bloqueo, el subproceso entrará en el estado BLOQUEADO (bloqueado).
- El subproceso entrará en el estado TERMINADO después de ejecutar el método run() de Runnable.
En la clase de enumeración Thread.State:
7. ¿Por qué se ejecuta el método run() cuando se llama al método start()?¿Por qué no podemos llamar directamente al método run()?
start() realizará el trabajo de preparación correspondiente del subproceso y luego ejecutará automáticamente el contenido del método run(), que es un verdadero trabajo de subprocesos múltiples.
La ejecución directa del método run() ejecutará el método run() como un método ordinario bajo el subproceso principal y no lo ejecutará en un determinado subproceso, por lo que este no es un trabajo de subprocesos múltiples.
8. ¿Qué es el cambio de contexto?
La tarea actual guardará su estado antes de cambiar a otra tarea después de ejecutar el intervalo de tiempo de la CPU, de modo que el estado de esta tarea se pueda cargar nuevamente cuando se vuelva a cambiar a esta tarea la próxima vez. El proceso de una tarea desde guardar hasta recargar es un cambio de contexto.
9. ¿Qué es el interbloqueo de subprocesos?
Interbloqueo se refiere a un fenómeno en el que dos o más subprocesos esperan el uno al otro debido a la competencia por los recursos durante el proceso de ejecución, lo que provocará que varios subprocesos se bloqueen al mismo tiempo y el programa no se pueda finalizar normalmente.
10. Por qué se produce un interbloqueo (4)
Un interbloqueo debe cumplir las siguientes cuatro condiciones:
- Condición mutuamente excluyente: el recurso solo está ocupado por un subproceso en cualquier momento.
- Condiciones de solicitud y retención: Cuando un proceso se bloquea debido a la solicitud de recursos, retendrá los recursos obtenidos.
- Condición de no privación: los recursos obtenidos por un subproceso no pueden ser privados por la fuerza por otros subprocesos antes de que se agoten, y los recursos se liberan solo después de que se agotan.
- Condición de espera circular: Se forma una relación de recurso de espera circular de cabeza a cola entre varios procesos.
11. Cómo evitar el interbloqueo de subprocesos (3)
- Solicitud de destrucción y condiciones de retención: aplica para todos los recursos a la vez.
- Destruir la condición de no privación: cuando un subproceso que ocupa algunos recursos solicita otros recursos, si la aplicación no se puede obtener, puede liberar activamente los recursos que ocupa.
- Destrucción de condiciones circulares de espera: prevenir solicitando recursos en secuencia. Solicite recursos en un orden determinado y libere recursos en orden inverso.
12. Cómo resolver el punto muerto
- Primero use el comando jps para ubicar el número de hilo
- Luego usa jstack para encontrar el interbloqueo
13. ¿Qué son los bloqueos justos y los bloqueos injustos?
● Bloqueo justo significa que múltiples subprocesos adquieren bloqueos en el orden en que los solicitan, similar a la cola, por orden de llegada, como: ReentrantLock establecido en verdadero ● Bloqueo injusto significa que en el caso de alta concurrencia,
es Es posible que los subprocesos posteriores sean más probables que los anteriores. Los subprocesos adquieren bloqueos primero, y el orden en que varios subprocesos adquieren bloqueos no sigue el orden en que solicitan bloqueos, lo que puede causar inversión de prioridad o inanición, como por ejemplo: sincronizado, ReentrantLock con un valor predeterminado de falso
14. ¿Qué es una cerradura reentrante?
● Un bloqueo reentrante también se denomina bloqueo recursivo, en referencia al mismo subproceso. Después de que la función externa adquiere el bloqueo, la función recursiva interna aún puede adquirir el código del bloqueo.
● ReentrantLock / sincronizado es un bloqueo de reentrada típico, la función más importante del bloqueo de reentrada es evitar el punto muerto
15. ¿Qué son los candados pesimistas y los candados optimistas?
- Bloqueo optimista: el bloqueo optimista es muy optimista cuando opera datos, pensando que otros no modificarán datos al mismo tiempo. Por lo tanto, el bloqueo optimista no bloqueará, sino que solo juzgará si otros han modificado los datos durante la actualización: si otros han modificado los datos, abandone la operación; de lo contrario, realice la operación.
- Bloqueo pesimista: el bloqueo pesimista es más pesimista al operar datos, pensando que otros modificarán los datos al mismo tiempo. Por lo tanto, los datos se bloquean directamente al operar los datos, y el bloqueo no se liberará hasta que se complete la operación; durante el período de bloqueo, otras personas no pueden modificar los datos.
16. ¿Cómo elige bloqueos pesimistas y bloqueos optimistas?
En el entorno actual de alta simultaneidad, alto rendimiento y alta disponibilidad, los bloqueos optimistas generalmente se usan con más frecuencia, porque los bloqueos optimistas en realidad no están bloqueados y la eficiencia es alta. Aunque la granularidad del bloqueo no se comprende bien, puede causar fallas de actualización, pero también se compara con el bloqueo pesimista y depender de los bloqueos de la base de datos, es menos eficiente y mejor.
17. ¿Qué es un bloqueo giratorio?
Significa que el subproceso que intenta adquirir el bloqueo no se bloqueará inmediatamente, sino que adquirirá el bloqueo de manera cíclica. La ventaja de esto es reducir el consumo de cambio de contexto del subproceso. La desventaja es que el bucle consumirá CPU.
18. ¿Qué es un bloqueo exclusivo (escritura) y un bloqueo compartido (lectura)?
Bloqueo exclusivo: significa que el bloqueo solo puede ser mantenido por un subproceso a la vez, tanto ReentrantLock como sincronizado son bloqueos exclusivos
Bloqueo compartido: significa que el bloqueo puede ser mantenido por múltiples subprocesos
19. ¿Por qué usar un bloqueo de lectura y escritura?
Para cumplir con los requisitos de simultaneidad, varios subprocesos deben poder leer una clase de recurso al mismo tiempo, pero si un subproceso quiere escribir un recurso compartido, ningún otro subproceso debe poder leer o escribir el recurso en este momento. .
20. Cuéntame sobre las diferencias y similitudes entre el método sleep() y el método wait().
● La principal diferencia entre los dos es que el método sleep() no libera el bloqueo, pero el método wait() lo libera.
● Ambos pueden suspender la ejecución de un subproceso.
● wait() generalmente se usa para la interacción/comunicación entre subprocesos, y sleep() generalmente se usa para suspender la ejecución.
● Después de llamar al método wait(), el subproceso no se reactivará automáticamente y otros subprocesos deben llamar al método notificar() o notificar a Todos() del mismo objeto. Después de ejecutar el método sleep(), el subproceso se activará automáticamente. O puede usar esperar (tiempo de espera prolongado) para activar el hilo automáticamente después del tiempo de espera.
21. Hable sobre la comprensión de la palabra clave sincronizada
La palabra clave sincronizada resuelve la sincronización del acceso a los recursos entre varios subprocesos y puede garantizar que solo un subproceso pueda ejecutar el método o el bloque de código modificado por él en cualquier momento.
En versiones anteriores de Java, sincronizado era un bloqueo de peso pesado, que era ineficiente.
22. ¿Por qué el sincronizado anterior era ineficiente?
La sincronización en la máquina virtual Java se implementa en función de la entrada y salida del objeto Monitor (también conocido como monitor o bloqueo del monitor), y el bloqueo del monitor (monitor) se implementa basándose en el bloqueo Mutex del sistema operativo subyacente. los subprocesos se asignan a los subprocesos nativos del sistema operativo. Si desea suspender o reactivar un subproceso, necesita la ayuda del sistema operativo para completarlo, y el sistema operativo debe cambiar del modo de usuario al modo kernel cuando cambia entre subprocesos. La transición entre estos estados lleva un tiempo relativamente largo. tiempo, y el costo del tiempo Relativamente alto.
Sin embargo, a partir de JDK1.6, los funcionarios de Java han optimizado en gran medida la sincronización desde el nivel de JVM, como los bloqueos giratorios, los bloqueos giratorios adaptables, la eliminación de bloqueos, el engrosamiento de bloqueos, los bloqueos sesgados, los bloqueos ligeros y otras tecnologías para reducir la sobrecarga de las operaciones de bloqueo.
23. ¿Qué se ha optimizado sincronizado después de JDK1.6?
-
En primer lugar, los bloqueos se reclasifican y los niveles de menor a mayor son: estado sin bloqueo -> estado de bloqueo sesgado -> estado de bloqueo ligero -> estado de bloqueo pesado,
-
Bloqueos sesgados
● Los bloqueos sesgados son para un subproceso.Después de que el subproceso adquiere el bloqueo, no habrá operaciones como el desbloqueo, lo que puede ahorrar una gran cantidad de gastos generales.
● El bloqueo de polarización está habilitado de forma predeterminada en JDK1.6 y superior, pero no se activa hasta unos segundos después de que se inicia el programa. Puede usarlo-XX:BiasedLockingStartupDelay=0para cerrar el retraso de inicio del bloqueo sesgado, o puede usarlo-XX:-UseBiasedLocking=falsepara cerrar el bloqueo sesgado. Después de cerrar, el programa entrará directamente en el estado de bloqueo ligero.
● Adecuado para escenarios de sincronización con solo acceso a un hilo -
Bloqueo ligero
● Cuando hay dos subprocesos que compiten por el bloqueo, el bloqueo sesgado no será válido y el bloqueo se expandirá en este momento y se actualizará a un bloqueo ligero. no bloquear, lo que mejora la velocidad de respuesta del programa, pero si no se ha obtenido el hilo a competir, el bloqueo girará y consumirá CPU ●
Adecuado para escenarios con baja latencia, sincronización rápida y ejecución muy rápida -
Bloqueo pesado
● Durante el período de competencia de bloqueo, si no se adquiere el bloqueo, no girará, sino que bloqueará directamente el subproceso
● Adecuado para escenarios con alto rendimiento, sincronización rápida y velocidad de ejecución lenta
24. ¿Cómo se usa la palabra clave sincronizada? (3)
- Método de instancia modificado
○ actúa sobre la instancia de objeto actual para bloquear y obtiene el bloqueo de la instancia de objeto actual antes de ingresar el código de sincronización
○ método de vacío sincronizado () { // código comercial} - Modifique el método estático
○ Es decir, bloquee la clase actual, que actuará en todas las instancias de objetos de la clase, y obtenga el bloqueo de la clase actual antes de ingresar el código de sincronización.
○ método de vacío estático sincronizado () { // código comercial} - El bloque de código modificado especifica el objeto de bloqueo
○ Bloquea un objeto/clase determinado. Indica que se debe adquirir un bloqueo en el objeto dado antes de ingresar al código base sincronizado.
○ sincronizado (esto) { // código comercial}
25. ¿Se puede modificar el método de construcción con sincronizado?
No, debido a que el constructor en sí es seguro, no existe un constructor sincronizado.
26. Hable sobre el principio subyacente de sincronización
La implementación del bloque de instrucción de sincronización sincronizada utiliza las instrucciones monitorenter y monitorexit, donde la instrucción monitorenter apunta al principio del bloque de código de sincronización y la instrucción monitorexit apunta al final del bloque de código de sincronización.
El método modificado por sincronizado no tiene la instrucción monitorenter ni la instrucción monitorexit, sino que tiene el indicador ACC_SYNCHRONIZED, que indica que el método es un método síncrono.
Pero la esencia de ambos es obtener el monitor monitor.
27. Hable sobre la diferencia entre sincronizado y ReentrantLock (5)
composición original
● sincronizado es una palabra clave y pertenece al nivel de JVM
● ReentrantLock es una clase específica (java.util.concurrent.locks.lock) es un bloqueo en el nivel de API
Instrucciones
● Sincronizado no requiere que el usuario libere manualmente el bloqueo. Después de ejecutar el código sincronizado, el sistema liberará automáticamente la ocupación del bloqueo en el sitio. ● ReentrantLock requiere que el usuario libere manualmente el bloqueo. Si
el bloqueo no está activo liberado, puede ocurrir un interbloqueo Fenómeno, se requieren los métodos lock() y unlock() para cooperar con la sentencia try/finally
¿Es interrumpible?
● sincronizado no se puede interrumpir a menos que se lance una excepción o se complete la operación normal
● ReentrantLock se puede interrumpir, configure el método de tiempo de espera tryLock (tiempo de espera largo, Unidad de tiempo), LockInterruptably() se coloca en el bloque de código y el método interrupt() puede ser llamado
¿Es justo el bloqueo?
● bloqueo injusto sincronizado
● ReentrantLock Ambos están disponibles, el valor predeterminado es falso Bloqueo injusto, el constructor puede pasar verdadero/falso
Bloquear múltiples condiciones vinculantes (Condición)
● Sincronizado No
● ReentrantLock se usa para activar los subprocesos que deben activarse en grupos, y puede activarse con precisión, en lugar de activar uno al azar o activar todos los subprocesos como sincronizados
28. Hable sobre JMM (modelo de memoria Java)
Antes de JDK1.2, la implementación del modelo de memoria de Java lee variables de la memoria compartida y no requiere atención especial. Bajo el modelo de memoria Java actual, los subprocesos pueden guardar variables en la memoria local (como los registros de la máquina) en lugar de leer y escribir directamente en la memoria compartida. Esto puede hacer que un subproceso modifique el valor de una variable en la memoria compartida, mientras que otro subproceso continúa usando su copia de la variable compartida en la memoria local, lo que provocará inconsistencias en los datos.
Para resolver este problema, debe declarar la variable como volátil, lo que le indica a la JVM que esta variable es compartida e inestable, y se leerá en la memoria compartida cada vez que se use.
Por lo tanto, además de evitar el reordenamiento de las instrucciones JVM, la palabra clave volatile también tiene un papel importante para garantizar la visibilidad de las variables.
Más detallado: https://blog.csdn.net/m0_55155505/article/details/126134031#JMM_10
29. ¿Qué significa volátil?
Volatile es un mecanismo de sincronización ligero proporcionado por la máquina virtual de Java, que puede garantizar la visibilidad y el orden, pero no puede garantizar la atomicidad.
Tres propiedades importantes de la programación concurrente
- Atomicidad: Significa que una operación es ininterrumpida y debe ejecutarse completamente o no ejecutarse en absoluto.
- Visibilidad: cuando varios subprocesos acceden a la misma variable y un subproceso modifica el valor de la variable, otros subprocesos pueden ver inmediatamente el valor modificado.
- Orden: el orden en que se ejecuta el programa se ejecuta en el orden en que se ejecuta el código
30. ¿Dónde has usado volátiles?
Se ha usado en el modo singleton, y originalmente solo usaba la verificación de bloqueo de dos extremos (juicio antes y después del bloqueo), pero debido a la reorganización de las instrucciones, puede causar que cierto subproceso no sea nulo cuando la instancia se detecta por primera vez. tiempo, pero de hecho, la instancia no se ha inicializado en absoluto, así que use volatile para prohibir el reordenamiento de instrucciones
31. La diferencia entre sincronizado y volátil
¡La palabra clave sincronizada y la palabra clave volátil son dos existencias complementarias, no opuestas!
● La palabra clave volatile es una implementación ligera de la sincronización de subprocesos, por lo que el rendimiento de volatile definitivamente es mejor que el de la palabra clavesynchroned. Pero la palabra clave volátil solo se puede usar para variables y la palabra clave sincronizada puede modificar métodos y bloques de código.
● La palabra clave volátil puede garantizar la visibilidad de los datos, pero no puede garantizar la atomicidad de los datos. La palabra clave sincronizada garantiza ambos.
● La palabra clave volatile se usa principalmente para resolver la visibilidad de las variables entre varios subprocesos, mientras que la palabra clave sincronizada resuelve la sincronización del acceso a los recursos entre varios subprocesos.
32. Cómo solucionar el problema de no garantizar atomicidad
- sincronizado
- cerrar
- Entero atómico
33. ¿Por qué agregar AtomicInteger puede resolver el problema de no garantizar la atomicidad?
Porque tiene un método, getAndIncrement, que significa sumar 1 a un valor atómicamente
De esta manera, otros hilos deben esperar a que el hilo que lo opera termine de ejecutarse antes de poder operar sobre él, y finalmente resolver el problema de no garantizar la atomicidad.
La capa inferior de AtomicInteger es CAS
El nombre completo de CAS es Comparar e intercambiar "Comparación e intercambio". Es una primitiva concurrente de CPU. Su función es juzgar si el valor de una determinada ubicación en la memoria es el valor esperado. Si lo es, se cambiará. a un nuevo valor De lo contrario, continuará comparando hasta que los valores en la memoria principal y la memoria de trabajo sean consistentes, todo el proceso es atómico y no causará inconsistencias en los datos.
Por ejemplo:
- Hay un 5 en la memoria física principal, y hay dos subprocesos para operar en este momento
- Ambos hilos A y B hacen una copia de este valor de la memoria física principal
- Cuando el subproceso A lo tomó de la memoria física principal, era 5. Cuando estaba a punto de escribir en la memoria física principal, descubrió que el valor de la memoria física principal seguía siendo 5, lo que significa que nadie lo había tocado. En este momento, el valor se cambió con éxito a 2019
- Al mismo tiempo, el subproceso B también necesita escribir en la memoria física principal. Cuando juzga si el valor tomado es consistente con la memoria física principal, descubre que el valor de la memoria física principal se ha modificado y el El subproceso B no puede modificar el valor de la memoria física principal constante.
34. El principio subyacente de CAS
Clase insegura más giro
Unsafe existe en el paquete sun.misc y es la clase central de CAS
Dado que el método Java no puede acceder directamente a la capa subyacente, necesita acceder a ella a través de un método nativo. Todos los métodos de la clase Unsafe se modifican de forma nativa, y sus métodos internos pueden manipular directamente la memoria como punteros C y llamar a los recursos subyacentes del sistema operativo. La ejecución de las tareas correspondientes es equivalente a que Java llame directamente a la clase intermedia de los recursos del sistema operativo, por lo que la ejecución de CAS en Java depende del método de la clase Unsafe
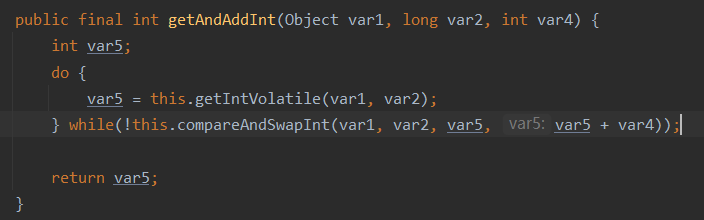
35. ¿Cuáles son las desventajas de CAS (3)
- Tiempo de ciclo largo y sobrecarga alta
Hay un tiempo de espera en el método getAndAddInt(). Si el CAS falla, seguirá intentándolo. Si el CAS falla durante mucho tiempo, traerá una gran sobrecarga a la CPU. - Solo podemos garantizar la operación atómica de una variable compartida.
Al realizar una operación en una variable compartida, podemos usar el método CAS para garantizar la atomicidad, pero cuando se opera en múltiples variables compartidas, el CAS circular no puede garantizar la atomicidad de la operación. En este momento, debe usar bloqueos para garantizar la atomicidad. - Habrá problemas de ABA
36. Preguntas ABA
Un requisito previo importante para la implementación del algoritmo CAS es sacar los datos en un momento determinado de la memoria y compararlos y reemplazarlos en el momento actual. Esta diferencia de tiempo provocará cambios en los datos.
Ejemplo:
-
Por ejemplo, un subproceso uno saca A de la ubicación de memoria V, en este momento otro subproceso dos también saca A de la memoria, y el subproceso dos realiza algunas operaciones para cambiar el valor a B,
-
Luego, el subproceso dos cambia los datos a A. En este momento, cuando el subproceso uno realiza la operación CAS, encuentra que todavía hay A en la memoria, y luego el subproceso uno opera con éxito.
-
Durante este período, el valor en la memoria ha cambiado, pero como al final se volvió a cambiar al valor original, CAS no se dio cuenta.
¿Cómo resolver ABA?
- Utilice el mecanismo del número de versión y compare el número de versión al mismo tiempo que modifica. Si el número de versión es consistente con el valor, modifíquelo, de lo contrario no se modificará.
37, hilo local
ThreadLocal permite que cada subproceso tenga su propia variable local. Cada subproceso que acceda a esta variable tendrá una copia local de esta variable. Pueden usar get() para obtener el valor predeterminado, o usar el método set() para establecer el valor Cambiar el valor de la copia guardada para el subproceso actual, evitando así problemas de seguridad del subproceso.
ThreadLocal El ThreadLocal subyacente
mantiene internamente una estructura de datos ThreadLocalMap similar a Map.
La clave de ThreadLocalMap es el objeto ThreadLocal, y el valor es el valor establecido llamando al método set del objeto ThreadLocal.El valor que ponemos en ThreadLocal es solo la encapsulación de ThreadLocalMap, pasando el valor de la variable.

38. ¿Entiendes las fugas de memoria de ThreadLocal?
La clave utilizada en ThreadLocalMap es una referencia débil a ThreadLocal, mientras que el valor es una referencia fuerte. Por lo tanto, si ThreadLocal no está fuertemente referenciado externamente, la clave se limpiará durante la recolección de elementos no utilizados, pero el valor no se limpiará. De esta forma, una Entrada cuya clave sea nula aparecerá en el ThreadLocalMap. Si no tomamos ninguna medida, GC nunca recuperará el valor y es posible que se produzca una pérdida de memoria en este momento. Esta situación se ha considerado en la implementación de ThreadLocalMap, cuando se llame a los métodos set(), get() y remove(), se limpiarán los registros cuya clave sea nula. Es mejor llamar al método remove() manualmente después de usar el método ThreadLocal
39. Los beneficios de usar el grupo de subprocesos
Reutilización de hilos: reduce el consumo de recursos. Reduzca el costo de la creación y destrucción de subprocesos al reutilizar los subprocesos creados.
Controla el número máximo de concurrencia: mejora la velocidad de respuesta. Cuando llega una tarea, la tarea se puede ejecutar inmediatamente sin esperar a que se cree el subproceso.
Administrar subprocesos: mejore la capacidad de administración de subprocesos. Los subprocesos son recursos escasos. Si se crean sin límite, no solo consumirán recursos del sistema, sino que también reducirán la estabilidad del sistema. El uso del grupo de subprocesos se puede utilizar para la asignación, el ajuste y la supervisión unificados.
40. La diferencia entre implementar la interfaz Runnable y la interfaz Callable
- Debido a la concurrencia, la asincronía conduce al surgimiento de la interfaz Callable
- La razón principal es que Callable se puede usar para darse cuenta de que cuando se ejecutan varias tareas, si una tarea lleva mucho tiempo, se puede ejecutar en segundo plano. El subproceso principal completa otras tareas primero y finalmente espera el final de la tarea. tareas en segundo plano y luego las resume juntas.
41. Grupo de hilos
Resumido en otro artículo: https://blog.csdn.net/m0_55155505/article/details/125191350
42. ¿Ha entendido AQS?
El nombre completo de AQS (AbstractQueuedSynchronizer) es una clase bajo el paquete JUC. Es un marco para construir cerraduras y sincronizadores. El uso de AQS puede construir fácil y eficientemente una gran cantidad de sincronizadores ampliamente utilizados.
43. Componentes de AQS
Semáforo: semáforo, que tiene dos funciones principales, una es para la exclusión mutua de múltiples recursos compartidos, y la otra es para controlar el número de subprocesos concurrentes. Hay dos métodos principales
● adquirir(): adquirir, cuando un subproceso llama a la operación adquirir(), adquiere el semáforo con éxito (el semáforo menos 1) o espera hasta que un subproceso libera el semáforo o se agota el tiempo de espera.
● release(): release, que en realidad aumentará el valor del semáforo en 1 y luego activará el subproceso en espera.
CountDownLatch: un temporizador de cuenta regresiva, que permite que un subproceso espere hasta que finalice la cuenta regresiva antes de comenzar la ejecución. Hay dos métodos principales
- await(): cuando uno o más subprocesos llaman al método await(), esos subprocesos se bloquearán.
- countDown(): cuando otros subprocesos llaman al método countDown(), el contador disminuirá en 1. Cuando el valor del contador sea 0, el subproceso bloqueado por el método await() se despertará y luego continuará ejecutándose .
CyclicBarrier: Su función principal es bloquear un grupo de subprocesos cuando alcanzan una barrera (también llamada punto de sincronización).La barrera no se abrirá hasta que el último subproceso alcance la barrera, y todos los subprocesos bloqueados por la barrera seguirán funcionando. Los hilos son barreras ingresadas a través del método CyclicBarrier.await()