Hibernar
113. ¿Por qué utilizar hibernación?
-
El código de la base de datos de acceso JDBC está encapsulado, lo que simplifica enormemente el código tedioso y repetitivo de la capa de acceso a datos.
-
Hibernate es un marco de persistencia convencional basado en JDBC y una excelente implementación de ORM. Simplificó enormemente la codificación de la capa DAO
-
Hibernate utiliza el mecanismo de reflexión de Java en lugar del programa de mejora del código de bytes para lograr transparencia.
-
El rendimiento de hibernación es muy bueno porque es un marco ligero. La flexibilidad del mapeo es excelente. Admite una variedad de bases de datos relacionales, desde relaciones complejas de uno a uno hasta de muchos a muchos.
114. ¿Qué es el marco ORM?
Mapeo relacional de objetos (ORM), el método de desarrollo orientado a objetos es el método de desarrollo principal en el entorno de desarrollo de aplicaciones empresariales actual, y la base de datos relacional es el sistema de almacenamiento de datos principal para el almacenamiento permanente de datos en el entorno de aplicaciones empresariales. Los datos de objetos y relacionales son dos manifestaciones de las entidades comerciales, que se representan como objetos en la memoria y como datos relacionales en las bases de datos. Existen asociaciones y relaciones de herencia entre objetos en la memoria, mientras que en una base de datos, los datos relacionales no pueden expresar directamente asociaciones de muchos a muchos y relaciones de herencia. Por lo tanto, el sistema de mapeo relacional de objetos (ORM) generalmente existe en forma de middleware, que principalmente realiza el mapeo de objetos de programa con datos de bases de datos relacionales.
115. ¿Cómo ver la instrucción SQL impresa en la consola en hibernación?
Referencia: Ver la declaración SQL impresa en la consola en hibernación
116. ¿Cuántos métodos de consulta tiene Hibernate?
-
consulta hql
-
consulta sql
-
Consulta condicional
hql查询,sql查询,条件查询
HQL: Hibernate Query Language. 面向对象的写法:
Query query = session.createQuery("from Customer where name = ?");
query.setParameter(0, "苍老师");
Query.list();
QBC: Query By Criteria.(条件查询)
Criteria criteria = session.createCriteria(Customer.class);
criteria.add(Restrictions.eq("name", "花姐"));
List<Customer> list = criteria.list();
SQL:
SQLQuery query = session.createSQLQuery("select * from customer");
List<Object[]> list = query.list();
SQLQuery query = session.createSQLQuery("select * from customer");
query.addEntity(Customer.class);
List<Customer> list = query.list();
Hql: 具体分类
1、 属性查询 2、 参数查询、命名参数查询 3、 关联查询 4、 分页查询 5、 统计函数
HQL和SQL的区别
HQL是面向对象查询操作的,SQL是结构化查询语言 是面向数据库表结构的
117. ¿Se pueden definir las clases de entidad de hibernación como finales?
La clase de entidad de Hibernate se puede definir como una clase final, pero este enfoque no es bueno. Debido a que Hibernate usará el modo proxy para mejorar el rendimiento en el caso de una asociación retrasada, si define la clase de entidad como una clase final, debido a que Java no permite que la clase final se extienda, Hibernate ya no puede usar el proxy, por lo que limitará el uso de métodos que pueden mejorar el rendimiento. Sin embargo, si su clase persistente implementa una interfaz y declara todos los métodos públicos definidos en la clase de entidad en la interfaz, es su turno de evitar las consecuencias adversas mencionadas anteriormente.
118. ¿Cuál es la diferencia entre usar Integer e int para mapear en hibernación?
En Hibernate, si el OID se define como un tipo Integer, entonces Hibernate puede determinar si un objeto es temporal en función de si su valor es nulo. Si el OID se define como un tipo int, también es necesario establecer su no guardado en el archivo de mapeo hbm. El atributo de valor es 0.
119. ¿Cómo funciona la hibernación?
Cómo funciona la hibernación:
- A través de Configuration config = new Configuration (). Configure (); // Leer y analizar el archivo de configuración hibernate.cfg.xml
- Lea y analice la información de mapeo por <mapping resource = "com / xx / User.hbm.xml" /> en hibernate.cfg.xml
- A través de SessionFactory sf = config.buildSessionFactory (); // Crear SessionFactory
- Sesión sesión = sf.openSession (); // 打开 Sesión
- Transaction tx = session.beginTransaction (); // Crear e iniciar la transacción Transation
- datos de operación de operación persistente, operación persistente
- tx.commit (); // Confirmar transacción
- Cerrar la sesión
- Cerrar SesstionFactory
120. ¿La diferencia entre get () y load ()?
-
Cuando load () no usa otras propiedades del objeto, no hay carga diferida de SQL
-
Cuando get () no usa otras propiedades del objeto, SQL también se genera y se carga inmediatamente
121. Cuéntame sobre el mecanismo de almacenamiento en caché de Hibernate.
La caché en Hibernate se divide en una caché de primer nivel y una caché de segundo nivel.
La caché de primer nivel es la caché de nivel de sesión, es válida dentro del alcance de la transacción y la caché integrada no se puede desinstalar. La caché de segundo nivel es la caché de nivel SesionFactory, que es válida desde el inicio de la aplicación hasta el final de la aplicación. Es opcional, no hay caché de segundo nivel de forma predeterminada y debe activarse manualmente. Después de guardar la base de datos, la caché guardará una copia en la memoria y, si la base de datos se actualiza, se actualizará de forma sincrónica.
¿Qué tipo de datos son adecuados para almacenar en la caché de segundo nivel?
- Hora de la última respuesta para publicaciones de datos que rara vez se modifican
- Ubicaciones de comercio electrónico de datos consultados con frecuencia
- Datos poco importantes, lo que permite datos concurrentes ocasionales
- Datos a los que no se accederá simultáneamente
- Datos constantes
Extensión: la caché de segundo nivel de hibernate no admite la caché distribuida de forma predeterminada. Use cachés centrales como memcahe y redis para reemplazar el caché secundario.
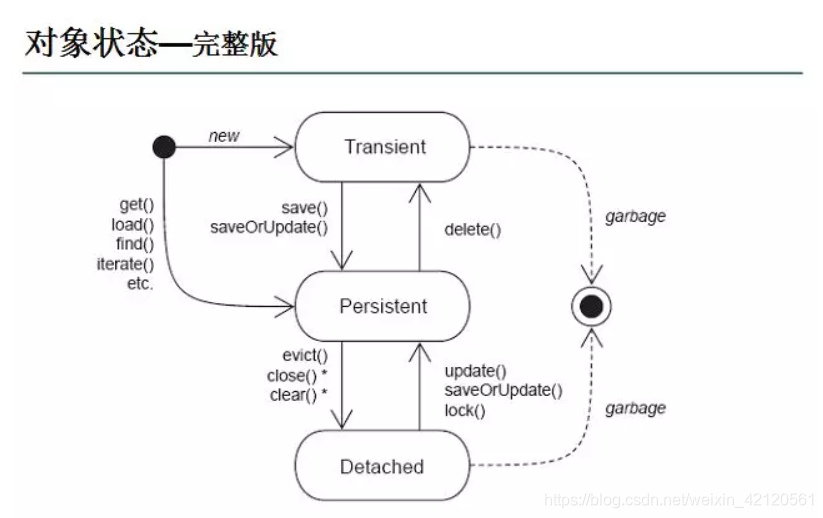
122. ¿Cuáles son los estados de los objetos en hibernación?
Hay tres estados de objetos en hibernación:
-
Transitorio (transitorio): el objeto acaba de salir, la identificación aún no se ha establecido y se han establecido otros valores.
-
Persistente (persistente): llame a save (), saveOrUpdate (), se vuelve persistente con id.
-
Independiente: cuando finaliza la sesión close (), se convierte en Separada.
123. ¿Cuál es la diferencia entre getCurrentSession y openSession en hibernate?
openSession se puede ver literalmente, es para abrir un nuevo objeto de sesión, y cada uso es para abrir una nueva sesión, si usa varias veces, la sesión obtenida no es el mismo objeto, y necesita llamar a cerrar después de usar Método para cerrar La sesión.
getCurrentSession, literalmente, es obtener un objeto de sesión en el contexto actual. Cuando se usa este método por primera vez, se genera automáticamente un objeto de sesión, y cuando se usa varias veces seguidas, la sesión obtenida es el mismo objeto Esta es una de las diferencias con openSession. En pocas palabras, getCurrentSession es: si hay uno que se ha usado, use el anterior, si no, cree uno nuevo.
Nota: En el desarrollo real, getCurrentSession a menudo se usa más, porque generalmente se procesa la misma transacción (es decir, el caso de usar una base de datos), por lo que, en general, openSession se usa menos o openSession es un conjunto de interfaces más antiguo.
124. ¿La clase de entidad hibernate tiene que tener un constructor sin parámetros? ¿Por qué?
Debe ser porque el marco de hibernación llama a este constructor predeterminado para construir un objeto de instancia, es decir, el método newInstance de la clase Class. Este método crea un objeto de instancia llamando al constructor predeterminado.
Otro recordatorio, si no proporciona ningún método de construcción, la máquina virtual proporcionará automáticamente el método de construcción predeterminado (constructor sin parámetros), pero si proporciona otros métodos de construcción con parámetros, la máquina virtual ya no le proporcionará el método de construcción predeterminado. . En este momento, debe escribir manualmente el constructor sin parámetros en el código, de lo contrario, new Xxxx () informará un error, por lo que el constructor predeterminado no es necesario, solo es necesario cuando hay varios constructores, aquí "Debe" significa "debe escribirse manualmente".