1. El concepto de función de pérdida
Loss Function (Función de pérdida) es una fórmula utilizada para evaluar la brecha entre los resultados previstos y los resultados reales , indicando la dirección para la optimización del modelo. En el proceso de optimización del modelo, generalmente se expresa como: o
A diferencia de la función de costo (Cost Function) para todo el conjunto de entrenamiento , la función de pérdida suele ser solo para una sola muestra de entrenamiento . Se puede resumir como Una función de pérdida es parte de una función de costo . (la función de pérdida es parte de la función de costo)
2. Funciones de pérdida comunes y sus explicaciones detalladas
1. Pérdida de error cuadrático medio
La función de pérdida del error cuadrático medio (MSE) se usa generalmente para tareas de regresión , también conocida como pérdida L2
Al utilizar la función de pérdida del error cuadrático medio, se puede considerar que el error entre la salida del modelo y el valor real obedece a una distribución gaussiana
2. Pérdida de error absoluta media
Pérdida de error absoluta media (MAE), también conocida como pérdida L1
Cuando se utiliza la función de pérdida de error absoluta media, se puede considerar que el error entre la salida del modelo y el valor real obedece a la distribución de Laplace
3.Pérdida de Huber
También conocido como Smooth L1 Loss , la derivada de L1 Loss en el punto 0 no es única, lo que puede afectar la convergencia; mientras que Smooth L1 Loss usa una función cuadrada cerca del punto 0 para suavizarla.
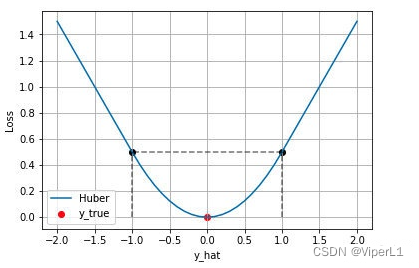
La diferencia entre MAE y MSE
①La velocidad de convergencia de L2 Loss es más rápida que la de L1 Loss, y L2 Loss se usa generalmente en la mayoría de los casos
②El crecimiento de L1 Loss es relativamente lento (crecimiento lineal con error, no crecimiento cuadrático), es decir, no es sensible a valores atípicos; para problemas de regresión de predicción de borde (como RCNN más rápido), los cambios de gradiente son más pequeños y es mas dificil correr volar
4. Función de pérdida de entropía cruzada
La pérdida de entropía cruzada, generalmente aplicada a problemas de clasificación , se puede dividir en clasificación binaria y clasificación múltiple
4.1 Dos clasificaciones
Para la clasificación binaria, generalmente usamos la función sigmoidea para comprimir el modelo a (0,1), y la salida del modelo es una probabilidad.Para una entrada dada , las probabilidades de ser un ejemplo positivo y un ejemplo negativo son:
La combinación de estas dos fórmulas da:
Suponiendo que los puntos de datos son independientes entre sí, la distribución de probabilidad se puede expresar como:
Tomando el logaritmo de la probabilidad y agregando un signo negativo para minimizar la probabilidad logarítmica negativa, se puede obtener la forma de la función de pérdida cruzada
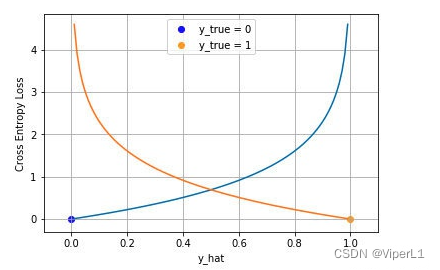
4.2 Multicategoría
La idea de la clasificación múltiple es similar a la clasificación binaria, el valor un vector one-hot, la función utilizada para la compresión se cambia a softmax , el rango de salida de todas las dimensiones se comprime a (0,1) y la suma es 1, que se puede expresar como:
Tomando el logaritmo de la probabilidad y agregando un signo negativo para minimizar la probabilidad logarítmica negativa, se puede obtener la forma de la función de pérdida cruzada
4.3 Pérdida Focal
Focal Loss se basa en la función de pérdida de entropía cruzada y se utiliza para resolver los siguientes problemas en la función de pérdida de entropía cruzada tradicional:
① Demasiadas muestras negativas (ejemplo negativo) hacen que se sobrescriba la pérdida de la muestra positiva (ejemplo positivo)
②Hay demasiadas muestras fáciles (ejemplo fácil) que hacen que domine la dirección de convergencia de un determinado lote
La pérdida focal se puede expresar como:
donde y γ se utilizan para resolver el problema del desequilibrio de muestra positivo y negativo y el desequilibrio de muestra fácil y difícil respectivamente
Tomando la clasificación binaria como ejemplo, amplíela
4.3.1 un
Se utiliza para resolver el problema de desequilibrio entre muestras positivas y negativas ; clasificar diferentes valores de peso para muestras positivas y negativas α [0,1]
El valor de α a menudo debe ajustarse de acuerdo con la conclusión (0,25 en el documento Faster RCNN)
4.3.2c
Se utiliza para resolver el problema de las muestras difíciles y fáciles desequilibradas ; deje que cada muestra se multiplique , porque la puntuación de las muestras simples
generalmente es cercana a 1, entonces su
valor será menor, lo que puede suprimir el peso de las muestras simples
3. Implementación de Pérdida Focal
Tomando YOLO V4 como ejemplo, la función de pérdida de YOLO V4 consta de tres partes: loc ( pérdida de regresión ), conf ( pérdida de confianza objetivo ) y cls ( pérdida de categoría ), entre las cuales la pérdida de confianza objetivo debe distinguirse entre positiva y muestras negativas. Se puede manejar de la siguiente manera.
① Probabilidad de extracción p
conf = torch.sigmoid(prediction[..., 4])② Equilibre las muestras positivas y negativas, configure el parámetro α
torch.where(obj_mask, torch.ones_like(conf) * self.alpha, torch.ones_like(conf) * (1 - self.alpha))
③ Equilibrar muestras difíciles y fáciles, establecer parámetros γ
torch.where(obj_mask, torch.ones_like(conf) - conf, conf) ** self.gamma
④ Vuelva a multiplicar la pérdida de entropía cruzada
ratio = torch.where(obj_mask, torch.ones_like(conf) * self.alpha, torch.ones_like(conf) * (1 - self.alpha)) * torch.where(obj_mask, torch.ones_like(conf) - conf, conf) ** self.gamma
loss_conf = torch.mean((self.BCELoss(conf, obj_mask.type_as(conf)) * ratio)[noobj_mask.bool() | obj_mask])