Estudio en papel - VideoGPT: Generación de Video usando VQ-VAE y Transformadores
Enlace original: https://arxiv.org/abs/2104.10157
1. Ideas de diseño
Los diferentes tipos de modelos generativos tienen ventajas y desventajas en las siguientes dimensiones: velocidad de muestreo, diversidad de muestras, calidad de muestras, estabilidad de optimización, requisitos computacionales, dificultad de evaluación, etc.
Estos modelos, además de los modelos de coincidencia de puntajes, pueden clasificarse ampliamente en modelos basados en la probabilidad (PixelCNN, iGPT, NVAE, VQ-VAE, Glow) y modelos generativos adversarios (GAN). Entonces, ¿qué tipo de modelo es adecuado para tareas de investigación y generación de videos?
Primero, elija entre dos amplias categorías de modelos. El entrenamiento del modelo basado en la probabilidad es más conveniente porque el objetivo es fácil de entender, fácil de optimizar en diferentes tamaños de lote y también es muy fácil de evaluar en comparación con el discriminador de GAN. Teniendo en cuenta que modelar la tarea de video ya es un gran desafío debido a la naturaleza de los datos, el modelo basado en verosimilitud para nuestra tarea tiene menos dificultades en el proceso de optimización y evaluación, por lo que puede enfocarse en la mejora de la estructura.
En segundo lugar, entre muchos modelos basados en la probabilidad, elegimos el modelo autorregresivo solo porque funciona bien en datos discretos, tiene un rendimiento excelente en la calidad de la muestra y es más multiplicador en los métodos de entrenamiento y arquitecturas de modelos, que se pueden usar en Transformer Las últimas mejoras a .
En los modelos autorregresivos, considere la siguiente pregunta: ¿es mejor modelar un modelo autorregresivo en un espacio latente reducido sin redundancia espaciotemporal, o entrenarlo en todos los fotogramas y todos los píxeles en el dominio espaciotemporal? Teniendo en cuenta la redundancia espacio-temporal del video natural, el autor eligió el primero para eliminar la redundancia al multiplicar el código de entrada de alta dimensión por un código de reducción de ruido sin ruido. Por ejemplo, con una reducción de resolución de 4 veces en el espacio y el tiempo, la resolución total es una reducción de resolución de 64 veces, por lo que el modelo generativo puede verter cálculos sobre información cada vez más útil. Por ejemplo, en VQ-VAE, incluso un decodificador incompleto puede convertir vectores latentes en muestras suficientemente reales. Y el modelado en el espacio latente también mejora la velocidad computacional.
Las tres razones anteriores impulsaron la creación de VideoGPT, que es un modelo generativo basado en la probabilidad, y el objeto generado es un video natural. Hay dos estructuras en el cuerpo principal de VideoGPT: VQ-VAE y GPT.
El codificador automático en VQ-VAE utiliza convolución 3d y mecanismo de atención axial (autoatención axial) para aprender la representación discreta de su espacio latente de reducción de resolución del video.
Mientras que las arquitecturas similares a GPT (con fuertes antecedentes autorregresivos) pueden usar codificaciones posicionales espaciotemporales para modelar autorregresivamente vectores latentes discretos (obtenidos por VQ-VAE).
El vector latente obtenido por el proceso anterior se restaura al video original a escala de píxeles a través del decodificador de VQ-VAE
En el experimento de ablación de seguimiento, el autor estudió las ventajas de los bloques de atención axial, el tamaño del espacio latente VQ-VAE, la entrada de libros de códigos y la influencia de la capacidad (tamaño del modelo) del autorregresivo previo.
2. Implementación específica
La estructura general de VideoGPT se muestra en la siguiente figura:
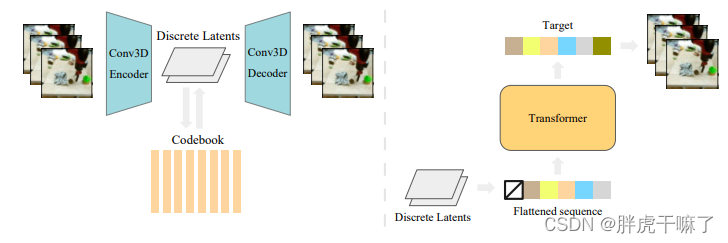
el modelo se divide en dos partes para su explicación:
2.1 Aprendizaje de códigos latentes - VQ-VAE
Para aprender códigos latentes discretos, VQ-VAE primero se entrena en datos de video. El codificador utiliza convolución 3D para reducir la resolución en la dimensión espacio-temporal, seguido de un módulo de atención residual, cuya estructura se muestra a continuación, utilizando mecanismos de atención axial y norma de capa en el módulo.
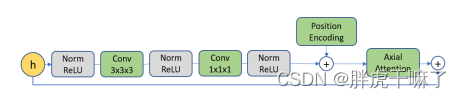
La estructura del decodificador es la inversa del codificador, primero a través del módulo de atención residual y luego a través de la convolución transpuesta 3d, sobremuestreando en la dimensión espacio-temporal. Las codificaciones posicionales son incrustaciones temporales y espaciales aprendidas que se pueden compartir entre el codificador y el decodificador en todas las capas de atención axial.
En cuanto a la atención axial de VQ-VAE, el código se muestra a continuación:
(1) Cabe señalar que VQ-VAE se divide en codificador y decodificador, y las dos partes son simétricas.
class VQVAE(pl.LightningModule):
def __init__(self, args):
super().__init__()
self.args = args
# codebooks 中embedding的维度
self.embedding_dim = args.embedding_dim
# codebook中code 的数目
self.n_codes = args.n_codes
# n_hiddens: 残差块儿中隐藏特征的数目
# n_res_layers: 残差块儿的数目
# downsample: T, H, W三个维度下采样倍数
self.encoder = Encoder(args.n_hiddens, args.n_res_layers, args.downsample)
self.decoder = Decoder(args.n_hiddens, args.n_res_layers, args.downsample)
(2) Tomando el codificador como ejemplo, el número de capas residuales n_res_layers es 4, por lo que su parte self.res_stack tiene 4 capas
class Encoder(nn.Module):
def __init__(self, n_hiddens, n_res_layers, downsample):
super().__init__()
n_times_downsample = np.array([int(math.log2(d)) for d in downsample])
self.convs = nn.ModuleList()
max_ds = n_times_downsample.max()
for i in range(max_ds):
in_channels = 3 if i == 0 else n_hiddens
stride = tuple([2 if d > 0 else 1 for d in n_times_downsample])
conv = SamePadConv3d(in_channels, n_hiddens, 4, stride=stride)
self.convs.append(conv)
n_times_downsample -= 1
self.conv_last = SamePadConv3d(in_channels, n_hiddens, kernel_size=3)
self.res_stack = nn.Sequential(
*[AttentionResidualBlock(n_hiddens)
for _ in range(n_res_layers)],
nn.BatchNorm3d(n_hiddens),
nn.ReLU()
)
(3) Para cada capa de AttentionResidualBlock, es decir, el módulo de atención residual mencionado en la figura anterior, cada extremo del módulo corresponde a un AxialBlock, y cada AxialBlock corresponde a un mecanismo de atención multicabezal en tres dimensiones de tiempo y espacio
class AxialBlock(nn.Module):
def __init__(self, n_hiddens, n_head):
super().__init__()
kwargs = dict(shape=(0,) * 3, dim_q=n_hiddens,
dim_kv=n_hiddens, n_head=n_head,
n_layer=1, causal=False, attn_type='axial')
self.attn_w = MultiHeadAttention(attn_kwargs=dict(axial_dim=-2),
**kwargs)
self.attn_h = MultiHeadAttention(attn_kwargs=dict(axial_dim=-3),
**kwargs)
self.attn_t = MultiHeadAttention(attn_kwargs=dict(axial_dim=-4),
**kwargs)
(4) Para cada atención multicabezal, su parte de atención corresponde a un mecanismo AxialAttention
class AxialAttention(nn.Module):
def __init__(self, n_dim, axial_dim):
super().__init__()
# encoder 里4个attentionResidualBlock,对应4组axial-attention,每组3个
# decoder 结构上与encoder对称,故也有4个attrntionResidualBlock
# print(n_dim, axial_dim)
# 如下内容,共8组,应该是共8个attention block
# 3 -2
# 3 -3
# 3 -4
if axial_dim < 0:
axial_dim = 2 + n_dim + 1 + axial_dim
else:
axial_dim += 2 # account for batch, head, dim
self.axial_dim = axial_dim
def forward(self, q, k, v, decode_step, decode_idx):
q = shift_dim(q, self.axial_dim, -2).flatten(end_dim=-3)
k = shift_dim(k, self.axial_dim, -2).flatten(end_dim=-3)
v = shift_dim(v, self.axial_dim, -2)
old_shape = list(v.shape)
v = v.flatten(end_dim=-3)
# scaled dot-product attention,计算分类结果
out = scaled_dot_product_attention(q, k, v, training=self.training)
out = out.view(*old_shape)
out = shift_dim(out, -2, self.axial_dim)
return out
eso es todo
2.2 Aprendiendo lo previo
La segunda etapa del modelo consiste en aprender un previo basado en el código latente de la primera etapa de VQ-VAE. La red anterior sigue la estructura de Image-GPT, y el abandono se agrega detrás de la capa de avance y el bloque de atención para lograr la regularización.
El proceso anterior se entrena bajo la condición de restricción incondicional. Las muestras condicionales se pueden generar entrenando un previo condicional. Hay dos métodos de restricción condicional:
- Atención cruzada: como una limitación del cuadro de video, en el proceso de entrenamiento de la red anterior, primero alimentamos el cuadro condicional en el resnet 3d y luego usamos la atención cruzada en la salida del resnet.
- Normas condicionales: de manera similar al método de restricción utilizado en las GAN, parametrizamos la ganancia y el sesgo en la capa de normalización de capas del transformador como una función de radiación del vector condicional. Este método es adecuado para modelos que restringen acciones y categorías.