Redes de contexto piramidal guiadas por la atención para la detección de objetivos pequeños por infrarrojos
1. Las deficiencias del método infrarrojo de objetivos pequeños y los aspectos más destacados de este documento
MDvsFA y ACM
-
Ventajas
MDvsFAcGan divide el generador en dos subtareas de detección perdida y falsa alarma, y propone una red de confrontación generativa.
ACM se centra en la fusión de características. Obtiene un mapa de características a través de una estructura de codificador-decodificador, y luego usa una estructura asimétrica para fusionar la semántica de bajo nivel y la semántica de nivel profundo de acuerdo con las características de la información contenida para obtener una representación de características más eficiente.
Ambos abordan tareas de detección desde la perspectiva de la red de confrontación generativa y la fusión de características. -
Insuficiencia
En primer lugar, la operación de convolución superpuesta limita el dominio de percepción de la red y normalmente se requiere información global para determinar la posición del objetivo.
Por otro lado, algunos métodos se limitan a mediciones de escala única al adquirir información global, lo que también limita la precisión de detección de la red.
Además, las restricciones separadas sobre la semántica subyacente y la semántica profunda durante el proceso de fusión de características causarán el problema de la falta de coincidencia de características y reducirán la capacidad de representación de características de la red.
Algunos aspectos destacados de este artículo.
- Al adquirir una imagen, se propone un algoritmo de bloque de contexto guiado por la atención ( AGCB ), que divide el mapa de características en varios bloques pequeños , calcula la correlación local de las características y luego calcula la distancia entre los bloques pequeños a través de la atención del contexto global. ( GCA ) Correlación global, para obtener información global entre píxeles
- En términos de adquisición de características de múltiples escalas, proponemos el Módulo de pirámide contextual ( CPM ), que fusiona AGCB de múltiples escalas con mapas de características originales para una representación de características más precisa.
- Para la fusión de características, proponemos el Módulo de fusión asimétrica ( AFM ), que realiza un filtrado de características asimétricas después de la fusión para resolver la falta de coincidencia.
2. Análisis de la estructura de la red
Estructura general de la red AGPCNet
La siguiente figura es la Figura 2 del artículo original, que muestra la estructura de toda la red AGPCNet. Como se puede ver en la figura a continuación, el cuerpo principal de la red se compone de dos estructuras principales (CPM+AFM).El módulo CPM en la red se compone de múltiples módulos AGCB de diferentes escalas, y el AGCB contiene el módulo GCA. , es decir, hay un montón de pequeños AGCB y GCA integrados en el gran CPM. Mantenga el tamaño de la imagen de entrada en consonancia con el tamaño de la imagen de salida reduciendo y aumentando la resolución continuamente
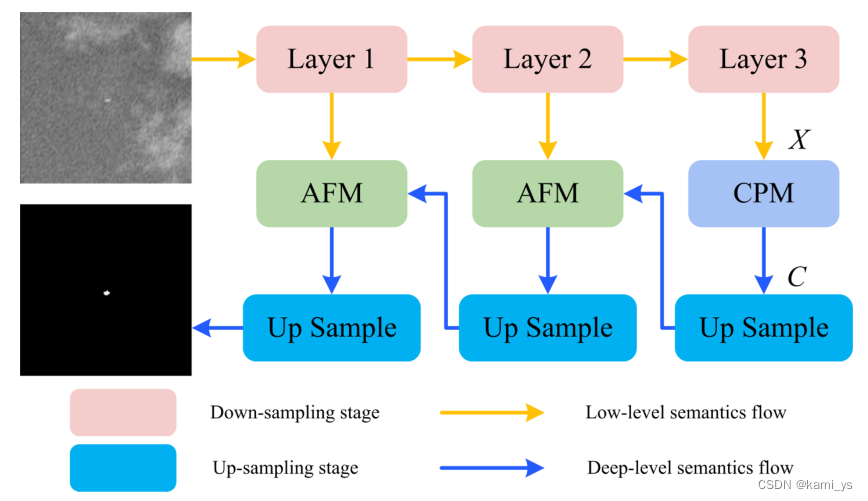
Como se puede ver en la figura anterior, AGPCNet se puede dividir en tres módulos: AGCB, CPM y AFM para el análisis.
Bloque de contexto guiado por la atención – AGCB
AGCB es un módulo básico de la red. Su rama superior y su rama inferior representan respectivamente la asociación global y la asociación local de semántica.
asociación local
Divida el mapa de características de entrada X' en s×s parches de tamaño w×h, donde w = ceil( W s \frac{W}{s}sW),h = techo( H s \frac{H}{s}sH). Las dependencias de píxeles en un rango local se calculan a través de operaciones no locales y todos los parches comparten pesos. Posteriormente, los mapas de características de salida se reúnen para formar un nuevo mapa de características de correlación local P ∈ RW × H \R^{W×H}Rancho x alto _
El objetivo principal de esto es limitar el campo de percepción de la red a un rango local y usar las dependencias entre píxeles en el rango local para reunir píxeles que pertenecen a la misma categoría para calcular la posibilidad de que aparezca el objetivo. De esta forma, se puede obtener el resultado de la discriminación del área local y se puede excluir la influencia del ruido estructural dentro del parche sobre el objetivo. Al mismo tiempo, el cálculo de la correlación local también puede ahorrar recursos informáticos y acelerar la velocidad de entrenamiento e inferencia de la red.
asociación mundial
El mapa de características de entrada X' ∈ RW × H \R^{W×H}RW × H primero extrae las características de cada parche a través de la agrupación máxima adaptativa y obtiene características de tamaño s × s, donde cada píxel representa la característica de cada parche. La información contextual entre cada parche es luego analizada por bloques no locales. Posteriormente, con el fin de integrar la información entre canales y obtener un guiado de atención más preciso, las características se pasan por el módulo de atención de píxeles para obtener el mapa de guiado G∈ R s × s \R^{s×s}Rs × s
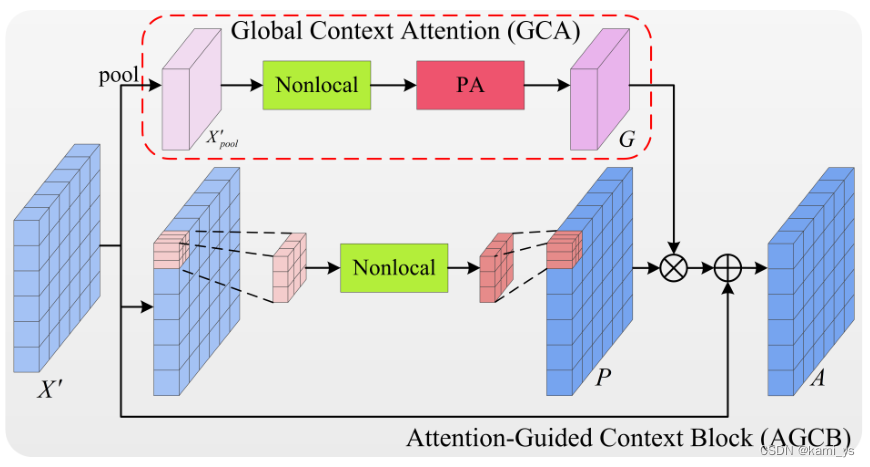
En el artículo, en la función de correlación local P ∈ RW × H \R^{W×H}RW × H más mapa guía G∈R s × s \R^{s×s}REl enfoque s × s da dos soluciones. El primero es GCA de parches, como se muestra en la Ecuación 4, que obtiene características s × s a través de la reducción de muestreo de agrupación máxima adaptativa, y utiliza la interpolación bilineal para aumentar la muestra de las características al mismo tamaño que la entrada X'. Luego, producto por puntos cada parche en G con cada parche en P. Finalmente, se junta el resultado de multiplicar cada parche con el parche correspondiente de G, y luego después de una capa convolucional con k=3 padding=1 stride=1 y una capa BN, se suma a X' para obtener el Output final A.
El otro es GCA por píxeles (Pixel-wise GCA) Como se muestra en la Ecuación 4, no usa la interpolación para aumentar la muestra a H × W, y multiplica directamente cada parche en P con el píxel en la posición correspondiente. Se representa por I(·).
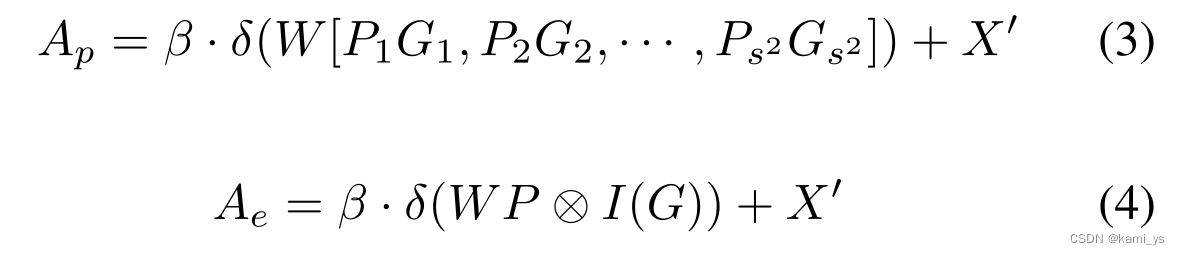
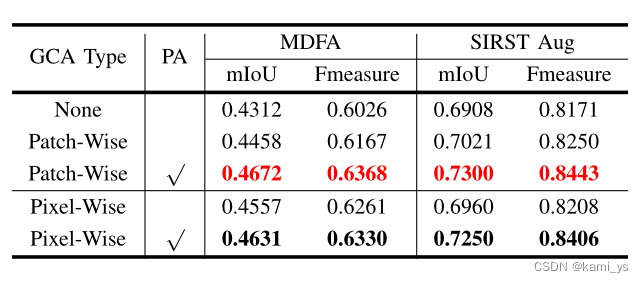
El documento también da la influencia del tipo de GCA (Patch-Wise y Pixel-Wise) y PA en el efecto de entrenamiento.
Códigos correspondientes AGCB y GCA
GCA
class GCA_Channel(nn.Module):
def __init__(self, planes, scale, reduce_ratio_nl, att_mode='origin'):
super(GCA_Channel, self).__init__()
assert att_mode in ['origin', 'post']
self.att_mode = att_mode
if att_mode == 'origin':
self.pool = nn.AdaptiveMaxPool2d(scale)
self.non_local_att = NonLocalBlock(planes, reduce_ratio=reduce_ratio_nl)
self.sigmoid = nn.Sigmoid()
elif att_mode == 'post':
self.pool = nn.AdaptiveMaxPool2d(scale)
self.non_local_att = NonLocalBlock(planes, reduce_ratio=1)
self.conv_att = nn.Sequential(
nn.Conv2d(planes, planes // 4, kernel_size=1),
nn.BatchNorm2d(planes // 4),
nn.ReLU(True),
nn.Conv2d(planes // 4, planes, kernel_size=1),
nn.BatchNorm2d(planes),
nn.Sigmoid(),
)
else:
raise NotImplementedError
def forward(self, x):
if self.att_mode == 'origin':
gca = self.pool(x)
gca = self.non_local_att(gca)
gca = self.sigmoid(gca)
elif self.att_mode == 'post':
gca = self.pool(x)
gca = self.non_local_att(gca)
gca = self.conv_att(gca)
else:
raise NotImplementedError
return gca
AGCB
class AGCB_Patch(nn.Module):
def __init__(self, planes, scale=2, reduce_ratio_nl=32, att_mode='origin'):
super(AGCB_Patch, self).__init__()
# patch size w = h,对应的尺度是s
self.scale = scale
self.non_local = NonLocalBlock(planes, reduce_ratio=reduce_ratio_nl)
self.conv = nn.Sequential(
nn.Conv2d(planes, planes, 3, 1, 1),
nn.BatchNorm2d(planes),
# nn.Dropout(0.1)
)
self.relu = nn.ReLU(True)
self.attention = GCA_Channel(planes, scale, reduce_ratio_nl, att_mode=att_mode)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
## long context
gca = self.attention(x)
## single scale non local
batch_size, C, height, width = x.size()
local_x, local_y, attention_ind = [], [], []
step_h, step_w = height // self.scale, width // self.scale # 每个patch的w h
for i in range(self.scale):
for j in range(self.scale):
start_x, start_y = i * step_h, j * step_w # 当前patch的左上坐标
end_x, end_y = min(start_x + step_h, height), min(start_y + step_w, width) # 算出当前的patch最右下坐标
if i == (self.scale - 1):
end_x = height
if j == (self.scale - 1):
end_y = width
local_x += [start_x, end_x]
local_y += [start_y, end_y]
attention_ind += [i, j] # index
index_cnt = 2 * self.scale * self.scale # 所有index
assert len(local_x) == index_cnt
context_list = []
for i in range(0, index_cnt, 2):
block = x[:, :, local_x[i]:local_x[i+1], local_y[i]:local_y[i+1]]
attention = gca[:, :, attention_ind[i], attention_ind[i+1]].view(batch_size, C, 1, 1)
context_list.append(self.non_local(block) * attention)
tmp = []
for i in range(self.scale):
row_tmp = []
for j in range(self.scale):
row_tmp.append(context_list[j + i * self.scale])
tmp.append(torch.cat(row_tmp, 3))
context = torch.cat(tmp, 2)
context = self.conv(context) # W = (W_input + 2p - w_kernel)/s + 1 = (32 + 2 - 3)/1 + 1 = 32
context = self.gamma * context + x
context = self.relu(context)
return context
Módulo Pirámide de Contexto – CPM
A continuación se describe el módulo de pirámide de contexto propuesto en el documento para la detección de objetivos pequeños por infrarrojos, y su estructura se muestra en la figura. Ingrese el mapa de características de entrada X en múltiples AGCB de diferentes escalas en paralelo, después de una reducción de dimensionalidad de convolución de 1 × 1, el resultado obtenido es A = {AS 1 A^{S1} AS 1 ,COMO 2 A^{S2}AS 2 ,···} representa, donde S es el vector de escala. Luego múltiples mapas de características agregados { A i A^{i} Ai } junto con el mapa de características original. Finalmente, se realiza una convolución 1 × 1 sobre la información del canal, que es la salida del CPM, de modo que los AGCB de diferentes escalas formen una pirámide de contexto.
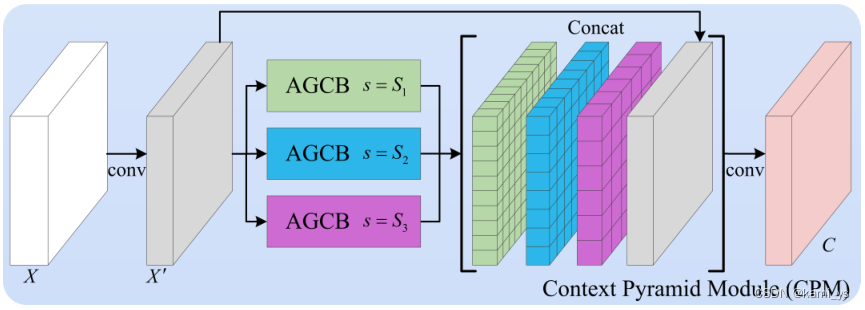
código CPM
class CPM(nn.Module):
def __init__(self, planes, block_type, scales=(3,5,6,10), reduce_ratios=(4,8), att_mode='origin'):
super(CPM, self).__init__()
assert block_type in ['patch', 'element']
assert att_mode in ['origin', 'post']
self.reduce_test = reduce_ratios
inter_planes = planes // reduce_ratios[0] # 降维比,在CPM和Nonlocal Block中分别有两个维度的降维。在网络中,降维不仅减少了冗余信息,而且大大加快了网络训练推理的速度,但这也可能导致信息的丢失
self.conv1 = nn.Sequential(
nn.Conv2d(planes, inter_planes, kernel_size=1),
nn.BatchNorm2d(inter_planes),
nn.ReLU(True),
)
if block_type == 'patch':
self.scale_list = nn.ModuleList(
[AGCB_Patch(inter_planes, scale=scale, reduce_ratio_nl=reduce_ratios[1], att_mode=att_mode)
for scale in scales])
elif block_type == 'element':
self.scale_list = nn.ModuleList(
[AGCB_Element(inter_planes, scale=scale, reduce_ratio_nl=reduce_ratios[1], att_mode=att_mode)
for scale in scales])
else:
raise NotImplementedError
channels = inter_planes * (len(scales) + 1)
self.conv2 = nn.Sequential(
nn.Conv2d(channels, planes, 1),
nn.BatchNorm2d(planes),
nn.ReLU(True),
)
def forward(self, x):
reduced = self.conv1(x)
blocks = []
for i in range(len(self.scale_list)):
blocks.append(self.scale_list[i](reduced))
out = torch.cat(blocks, 1)
out = torch.cat((reduced, out), 1)
out = self.conv2(out)
return out
Módulo de Fusión Asimétrica – AFM
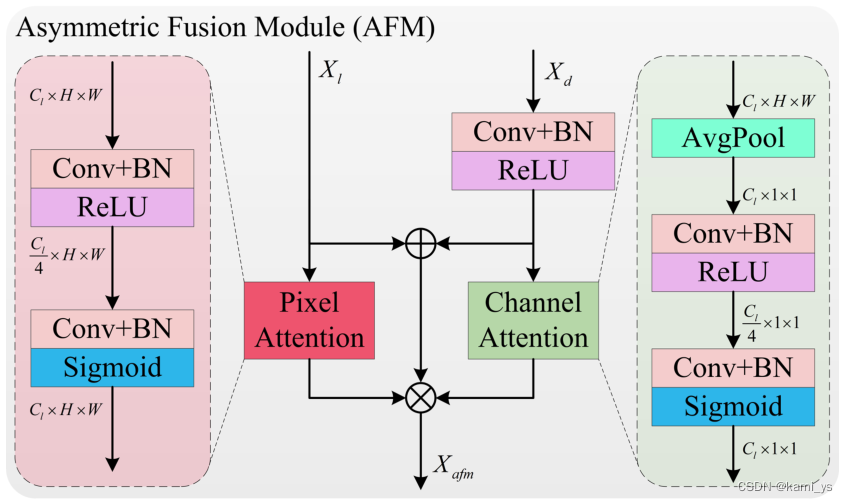
En términos de fusión de características, el documento se basa en CBAM y ACM para proponer un nuevo módulo de fusión semántica asimétrica para fusionar la semántica de bajo nivel y la semántica profunda. Como se muestra en la figura, tomando como entrada la semántica de bajo nivel Xl y la semántica profunda Xd, procesamos por separado las diferentes categorías de información que contienen.
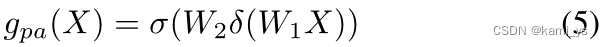
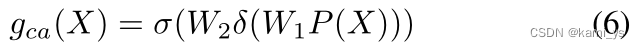
El Xl semántico de bajo nivel contiene una gran cantidad de información de ubicación de objetos, usando el mecanismo de atención de puntos en la Ecuación 5. Por otro lado, Deep Semantic Xd primero usa la convolución 1 × 1 para la reducción de dimensionalidad, contiene más información y usa el mecanismo de atención en la Ecuación 6 para seleccionar los canales más importantes. Después de que las características se suman y fusionan directamente, gpa y gca se restringen respectivamente, como se muestra en la Ecuación 7, lo que puede resolver el problema de la falta de coincidencia de características causada por restricciones individuales. Donde ⊗ y ⊙ son la correspondiente multiplicación unitaria y la correspondiente multiplicación del tensor vectorial, respectivamente, y σ es la función sigmoidea.
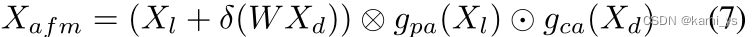
codigo AFM
class AsymFusionModule(nn.Module):
def __init__(self, planes_high, planes_low, planes_out):
super(AsymFusionModule, self).__init__()
self.pa = nn.Sequential(
nn.Conv2d(planes_low, planes_low//4, kernel_size=1),
nn.BatchNorm2d(planes_low//4),
nn.ReLU(True),
nn.Conv2d(planes_low//4, planes_low, kernel_size=1),
nn.BatchNorm2d(planes_low),
nn.Sigmoid(),
)
self.plus_conv = nn.Sequential(
nn.Conv2d(planes_high, planes_low, kernel_size=1),
nn.BatchNorm2d(planes_low),
nn.ReLU(True)
)
self.ca = nn.Sequential(
# 通道注意力,需要先通过平均池化下采样
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(planes_low, planes_low//4, kernel_size=1),
nn.BatchNorm2d(planes_low//4),
nn.ReLU(True),
nn.Conv2d(planes_low//4, planes_low, kernel_size=1),
nn.BatchNorm2d(planes_low),
nn.Sigmoid(),
)
self.end_conv = nn.Sequential(
nn.Conv2d(planes_low, planes_out, 3, 1, 1),
nn.BatchNorm2d(planes_out),
nn.ReLU(True),
)
def forward(self, x_high, x_low):
x_high = self.plus_conv(x_high)
pa = self.pa(x_low)
ca = self.ca(x_high)
feat = x_low + x_high
feat = self.end_conv(feat)
feat = feat * ca
feat = feat * pa
return feat
3. Cálculo de pérdidas
La salida del FCN propuesto es un valor de probabilidad que representa la posibilidad de que un píxel sea parte de un objeto. Por lo tanto, no podemos medir con precisión la puntuación de IoU directamente desde la salida de la red. Proponemos utilizar valores de probabilidad para aproximar la puntuación IoU. Más formalmente, sea V = {1,2,...,N} el conjunto de todos los píxeles de todas las imágenes en el conjunto de entrenamiento, X sea la salida de la red (fuera de la capa sigmoidea), denote la probabilidad de que píxel en el conjunto V, Y∈ { 0 , 1 } v {\{0, 1}\}^{v}{ 0 ,1 }v es la asignación de verdad del terreno del conjunto V, donde 0 representa píxeles de fondo y 1 representa píxeles de objeto. Entonces, el conteo de IoU se puede definir como:

En la fórmula, I(X) y U(X) se pueden aproximar como:
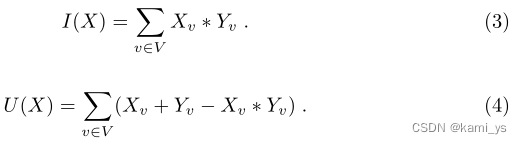
Por lo tanto, la pérdida de IoU LIoU se puede definir como:
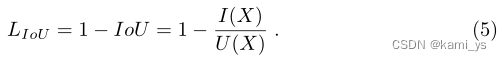
Cuando Yv es 1, la pérdida de cierto píxel es 1 - X v Y v \frac{Xv}{Yv}Yv _Xv _, que es 1 - XV.
4. Indicadores de evaluación
En términos de indicadores de evaluación, el autor enumera principalmente dos indicadores de uso común: F-measure y mIoU.
F-measure es un indicador integral que combina precisión y recuperación. La fórmula de cálculo es la siguiente:
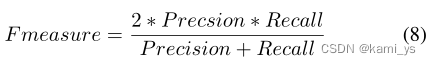
mIoU es la abreviatura de intersección media sobre unión, y la fórmula de cálculo es la siguiente:
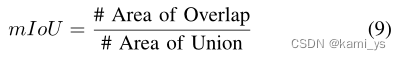
entre ellos, el numerador es el área superpuesta y el denominador es el área de unión
5. Información en papel
Dirección de descarga del artículo: https://arxiv.org/pdf/2111.03580v1.pdf
Código fuente del artículo (implementación de PyTorch): https://github.com/Tianfang-Zhang/AGPCNet
con conjunto de datos