Introducción a ELK
La plataforma ELK es un conjunto completo de soluciones de procesamiento centralizado de registros, que utiliza ElasticSearch, Logstash y Kiabana, tres herramientas de código abierto juntas para completar consultas de usuario, clasificación y requisitos estadísticos más potentes para los registros.
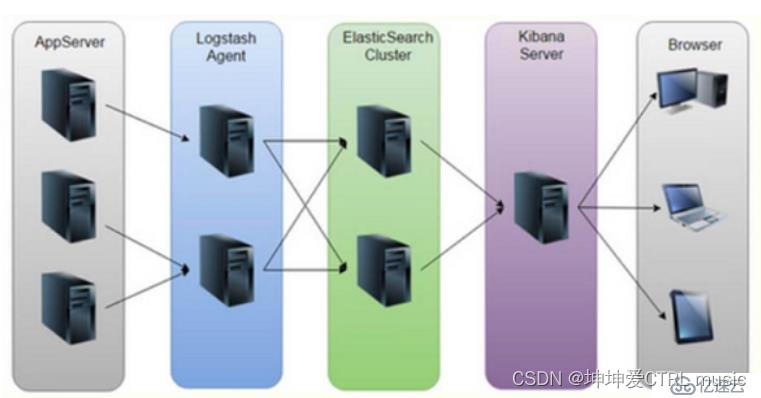
Introducción a los componentes ELK
Búsqueda elástica:
- Es un motor de búsqueda de almacenamiento distribuido desarrollado en base a Lucene (una arquitectura de motor de búsqueda de texto completo) y se utiliza para almacenar varios registros.
- Elasticsearch está desarrollado en Java y puede comunicarse con Elasticsearch a través de una interfaz web RESTful a través de un navegador.
- Elasticsearch es un motor de búsqueda escalable, distribuido y en tiempo real que permite búsquedas estructuradas de texto completo. Normalmente se utiliza para indexar y buscar grandes volúmenes de datos de registro, y también se puede utilizar para buscar muchos tipos diferentes de documentos.
Kiabana:
- Kibana generalmente se implementa junto con Elasticsearch. Kibana es un poderoso panel de visualización de datos para Elasticsearch. Kibana proporciona una interfaz web gráfica para explorar los datos de registro de Elasticsearch, que se pueden usar para resumir, analizar y buscar datos importantes.
Logstash:
- como motor de recopilación de datos. Admite la recopilación dinámica de datos de varias fuentes de datos y realiza operaciones como filtrar, analizar, enriquecer y unificar el formato de los datos, y luego los almacena en una ubicación especificada por el usuario y generalmente los envía a Elasticsearch.
- Logstash está escrito en lenguaje Ruby y se ejecuta en Java Virtual Machine (JVM).Es una poderosa herramienta de procesamiento de datos que puede realizar la transmisión de datos, el procesamiento de formato y la salida de formato. Logstash tiene una poderosa función de complemento, que a menudo se usa para el procesamiento de registros.
El módulo de filtrado es la función central de logstash
Otros componentes que se pueden añadir:
Latido de archivo:
- Recopilador de datos de archivo de registro de código abierto ligero. Por lo general, Filebeat se instala en el cliente que necesita recopilar datos, y se especifican el directorio y el formato de registro. Filebeat puede recopilar datos rápidamente y enviarlos a logstash para su análisis, o directamente al almacenamiento de Elasticsearch. En comparación con logstash que se ejecuta en la JVM en términos de rendimiento Tiene ventajas obvias y es una alternativa a la misma. A menudo se utiliza en la arquitectura EFLK. (Si desea utilizar la función de filtrado, Filebeat no puede reemplazar por completo a logstash. Filebeat no tiene función de filtrado. Después de recopilar datos, debe enviarse a logstash para su procesamiento)
Filebeat combinado con logstash trae beneficios:
- Through Logstash tiene un sistema de almacenamiento en búfer adaptable basado en disco que absorberá el rendimiento entrante, aliviando a Elasticsearch de la presión de escribir datos continuamente.
- Extraiga de otras fuentes de datos, como bases de datos, almacenamiento de objetos S3 o colas de mensajería.
- Envíe datos a múltiples destinos como S3, HDFS (Sistema de archivos distribuidos de Hadoop) o escriba en un archivo.
- Utilice lógica de flujo de datos condicional para componer canalizaciones de procesamiento más complejas.
Caché/cola de mensajes (redis, kafka, RabbitMQ, etc.):
- El recorte de picos de tráfico y el almacenamiento en búfer se pueden realizar en datos de registro de alta concurrencia.Dicho almacenamiento en búfer puede proteger los datos contra pérdidas hasta cierto punto, y también puede desacoplar la aplicación de toda la arquitectura.
Fluido:
- es un popular recopilador de datos de código abierto. Debido a las deficiencias de logstash por ser demasiado pesado, el bajo rendimiento y el alto consumo de recursos de Logstash, Fluentd apareció más tarde. En comparación con logstash, Fluentd es más fácil de usar, consume menos recursos, tiene un mayor rendimiento y es más eficiente y confiable en el procesamiento de datos. Es bienvenido por las empresas y se ha convertido en una alternativa a logstash, y se usa a menudo en la arquitectura EFK. EFK también se usa a menudo como una solución para la recopilación de datos de registro en clústeres de Kubernetes.
- Fluentd generalmente se ejecuta a través de un DaemonSet en un clúster de Kubernetes para que pueda ejecutar un Pod en cada nodo de trabajo de Kubernetes. Funciona tomando archivos de registro de contenedores, filtrando y transformando los datos de registro y luego pasando los datos a un clúster de Elasticsearch donde se indexan y almacenan.
CADA UNO, ELFK, EFLKL
ELK: ES+logstash+kibana
ELFK: ES+logstash+filebeat+kibana
ELFK: ES+filebeat+logstash+kafka+kibana
¿Por qué usar ELK?
Los registros incluyen principalmente registros del sistema, registros de aplicaciones y registros de seguridad. La operación y el mantenimiento del sistema y los desarrolladores pueden usar los registros para comprender la información del software y el hardware del servidor, verificar los errores en el proceso de configuración y las razones de los errores. El análisis frecuente de los registros puede ayudarlo a comprender la carga del servidor, la seguridad del rendimiento y tomar medidas oportunas para corregir errores.
A menudo, podemos usar herramientas como grep y awk para analizar los registros de una sola máquina básicamente, pero cuando los registros están dispersos y almacenados en diferentes dispositivos. Si administra decenas o cientos de servidores, todavía está viendo registros utilizando el método tradicional de iniciar sesión en cada máquina por turno. ¿Se siente esto engorroso e ineficiente? Como máxima prioridad, utilizamos la gestión de registros centralizada, como syslog de código abierto, para recopilar y resumir registros en todos los servidores. Después de la administración centralizada de registros, las estadísticas y la recuperación de registros se ha convertido en algo más problemático. En general, podemos usar comandos de Linux como grep, awk y wc para lograr la recuperación y las estadísticas, pero para consultas, clasificación y estadísticas más exigentes. , etc. Y la gran cantidad de máquinas todavía es un poco impotente para usar este método.
Generalmente, un sistema a gran escala es una arquitectura de implementación distribuida, y diferentes módulos de servicio se implementan en diferentes servidores. Cuando ocurre un problema, en la mayoría de los casos, es necesario ubicar el servidor y el módulo de servicio específicos en función de la información clave expuesta por el problema, y construir un conjunto de sistema de registro de tipo centralizado, que puede mejorar la eficiencia de localizar problemas
Características básicas de un sistema de registro completo
Recopilación: capacidad de recopilar datos de registro de múltiples fuentes.
Transmisión: puede analizar, filtrar y transmitir datos de registro de manera estable al sistema de almacenamiento.
Almacenamiento: almacenar datos de registro.
Análisis: Admite análisis de interfaz de usuario.
ADVERTENCIA: Capacidad para proporcionar informes de errores, mecanismos de monitoreo
Cómo funciona ELK
(1) Implemente Logstash en todos los servidores que necesiten recopilar registros; o centralice primero la administración de registros en el servidor de registro e implemente Logstash en el servidor de registro.
(2) Logstash recopila registros, formatea y envía registros al clúster de Elasticsearch.
(3) Elasticsearch indexa y almacena los datos formateados.
(4) Kibana consulta datos de clústeres de ES para generar gráficos y muestra datos de front-end
Resumen: logstash, como recopilador de registros, recopila datos de fuentes de datos, filtra y formatea los datos y luego los almacena en Elasticsearch, y Kibana visualiza los registros
3. Implementación en clúster del sistema de análisis de registros ELK
| Tipo de servidor | Sistema y dirección IP | Componentes que necesitan ser instalados | hardware |
|---|---|---|---|
| nodo01 nodo | CentOS7.4 (64 bits) 192.168.52.110 | Elasticsearch, Kibana | 2 núcleos 4G |
| nodo02 nodo | CentOS7.4 (64 bits) 192.168.52.120 | Elasticsearch | |
| nodo apache | CentOS7.4 (64 bits) 192.168.52.130 | Logstash Apache |
Inicializar el entorno (todos los nodos)
#关闭防火墙
systemctl stop firewalld.service
setenforce 0Implementación de clúster de ELK Elasticsearch (operado en nodos Node1, Node2)
#设置Java环境
java -version
#如果没有安装,
yum -y install javaImplementar el software Elasticsearch
Instale el paquete elasticsearch-rpm
上传elasticsearch-5.5.0.rpm到/opt目录下
rpm -ivh elasticsearch-5.5.0.rpmmodificar nombre de host
#以node01为例
hostnamectl set-hostname node01
su
vim /etc/hosts
192.168.137.10 node01
192.168.137.15 node02Modificar el archivo de configuración principal de elasticsearch
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
node.master: true#是否master节点,false为否
node.data: true#是否数据节点,false为否
--34--取消注释,指定数据存放路径
path.data: /var/lib/elasticsearch
--38--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch
--44--取消注释,避免es使用swap交换分区
bootstrap.memory_lock: false
--56--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--60--取消注释,ES 服务的默认监听端口为9200
http.port: 9200 #指定es集群提供外部访问的接口
transport.tcp.port: 9300 #指定es集群内部通信接口
--69--取消注释,集群发现通过单播实现,指定要发现的节点
discovery.zen.ping.unicast.hosts: ["192.168.137.15:9300", "192.168.137.10:9300"]
grep -v "^#" /etc/elasticsearch/elasticsearch.ymlparámetros de ajuste de rendimiento de es
#优化最大内存大小和最大文件描述符的数量需重启生效
vim /etc/security/limits.conf
......
* soft nofile 65536 可打开的文件描述符的最大数(软限制)
* hard nofile 131072 可打开的文件描述符的最大数(硬限制)
* soft memlock unlimited 单个用户可用的最大进程数量(软限制)
* hard memlock unlimited 单个用户可用的最大进程数量(硬限制)Optimice los permisos de memoria propiedad del usuario de elasticsearch
Dado que ES se basa en lucene, la fuerza del diseño de lucene es que lucene puede hacer un buen uso de la memoria del sistema operativo para almacenar en caché datos de índice para proporcionar un rendimiento de consulta rápido. Los segmentos del archivo de índice de Lucene se almacenan en un solo archivo y es inmutable. Para el sistema operativo, es muy amigable mantener el archivo de índice en el caché para un acceso rápido; por lo tanto, es necesario que reservemos la mitad de la memoria física para lucene. ; la otra mitad de la memoria física está reservada para ES (montón JVM). Por lo tanto, en términos de configuración de la memoria ES, se pueden seguir los siguientes principios:
- Cuando la memoria de la máquina sea inferior a 64G, siga el principio general, 50% para ES, 50% para el sistema operativo, para uso lucene
- Cuando la memoria de la máquina sea superior a 64G, siga el principio: se recomienda asignar 4~32G de memoria a ES y dejar la otra memoria al sistema operativo para uso de lucene.
vim /etc/sysctl.conf
#一个进程可以拥有的最大内存映射区域数,参考数据(分配 2g/262144,4g/4194304,8g/8388608)
vm.max_map_count=262144
sysctl -p 重载配置文件
sysctl -a | grep vm.max_map_countYa sea para iniciar elasticsearch con éxito
systemctl start elasticsearch.service
systemctl enable elasticsearch.service
netstat -antp | grep 9200Ver información del nodo
Acceda a 2http://192.168.137.10:9200 y 2http://192.168.137.15:9200 con el navegador para consultar la información del Nodo01 y Nodo02.
Acceda al navegador 2http://192.168.137.10:9200/_cluster/health?pretty, http://192.168.137.15:9200/_cluster/health?pretty para ver el estado del clúster, puede ver que el valor de estado es verde (verde), lo que indica que el nodo se está ejecutando correctamente.
Acceso al navegador http://192.168.137.10:9200/_cluster/state?pretty Verifique la información de estado del clúster
Usar el método anterior para ver el estado del clúster no es amigable para los usuarios Puede administrar el clúster de manera más conveniente instalando Elasticsearch -enchufe de cabeza.
Instale el complemento Elasticsearch-head
Después de la versión 5.0 de Elasticsearch, el complemento Elasticsearch-head debe instalarse como un servicio independiente y debe instalarse mediante la herramienta npm (una herramienta de administración de paquetes para NodeJS).
Para instalar Elasticsearch-head, debe instalar el nodo de software dependiente y phantomjs por adelantado.
nodo: es un entorno de tiempo de ejecución de JavaScript basado en el motor Chrome V8.
phantomjs: Es una API JavaScript basada en webkit, que puede entenderse como un navegador invisible, puede hacer cualquier cosa basada en navegadores webkit
Compilar e instalar el nodo
#上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make && make installinstalar phantomjs
#上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到opt
cd /opt
tar xvf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd /opt/phantomjs-2.1.1-linux-x86_64/bin
ln -s phantomjs /usr/local/binInstale la herramienta de visualización de datos de Elasticsearch-head
#上传软件包 elasticsearch-head.tar.gz 到/opt
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm installModificar el archivo de configuración principal de Elasticsearch
vim /etc/elasticsearch/elasticsearch.yml
......
--末尾添加以下内容--
http.cors.enabled: true
#开启跨域访问支持,默认为 false
http.cors.allow-origin: "*"
#指定跨域访问允许的域名地址为所有
systemctl restart elasticsearchInicie el servicio de cabeza de búsqueda elástica
El servicio debe iniciarse en el directorio elasticsearch-head descomprimido y el proceso leerá el archivo gruntfile.js en este directorio; de lo contrario, el inicio puede fallar.
cd /usr/local/src/elasticsearch-head/
npm run start &
> [email protected] start /usr/local/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
#elasticsearch-head 监听的端口是 9100
netstat -natp |grep 9100Ver información de Elasticsearch a través de Elasticsearch-head
Visite la dirección http://192.168.137.10:9100/ a través de un navegador y conéctese al clúster. Si ve que el valor de estado del clúster es verde, significa que el clúster está en buen estado.
insertar índice
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
//输出结果如下:
{
"_index": "index-demo",
"_type" : "test",
"_id": "1",
"_version": 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"created" : true
}Visite http://192.168.52.10:9100/ con un navegador para ver la información del índice. Puede ver que el índice está dividido en 5 fragmentos de manera predeterminada y hay una copia.
Haga clic en "Examinar datos", encontrará el índice creado en el nodo 1 como demostración de índice y la información relacionada de tipo prueba.
Implementación de ELK Logstash (operando en nodos de Apache)
Logstash generalmente se implementa en servidores cuyos registros deben monitorearse. En este caso, Logstash se implementa en el servidor Apache para recopilar la información de registro del servidor Apache y enviarla a Elasticsearch.
cambiar nombre de host
hostnamectl set-hostname apache
suInstalar el servicio Apache (httpd)
yum -y install httpd
systemctl start httpdInstalar el entorno Java
yum -y install java
java -versioninstalar logstash
#上传软件包 logstash-5.5.1.rpm 到/opt目录下
cd /opt
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/Prueba Logstash
Opciones comunes para los comandos de Logstash:
| -F | A través de esta opción, se puede especificar el archivo de configuración de Logstash y los flujos de entrada y salida de Logstash se pueden configurar de acuerdo con el archivo de configuración. |
|---|---|
| -t | Pruebe que el archivo de configuración es correcto, luego salga. |
| -mi | Obtenidos desde la línea de comando, la entrada y la salida van seguidas de una cadena, que se puede usar como la configuración de Logstash (si está vacía, se usa stdin como entrada y stdout como salida por defecto). |
Definir flujos de entrada y salida:
#输入采用标准输入,输出采用标准输出(类似管道)
logstash -e 'input { stdin{} } output { stdout{} }'
......
www.baidu.com #键入内容(标准输入)
#输出结果(标准输出)
www.sina.com.cn #键入内容(标准输入)
#输出结果(标准输出)
//执行 ctrl+c 退出Definir el archivo de configuración logstash
El archivo de configuración de Logstash consta básicamente de tres partes: entrada, salida y filtro (opcional, utilícelo según sea necesario).
| aporte | Indica la recopilación de datos de fuentes de datos, fuentes de datos comunes como Kafka, archivos de registro, etc. |
|---|---|
| filtrar | Representa la capa de procesamiento de datos, incluido el formato de datos, la conversión de tipos de datos, el filtrado de datos, etc., y admite expresiones regulares |
| producción | Indica que los datos recopilados por Logstash son procesados por el filtro y luego enviados a Elasticsearch. |
#格式如下:
input {...}
filter {...}
output {...}
#在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file {
path =>"/var/log/messages"
type"syslog"
file { path =>"/var/log/httpd/access.log"
type =>"apache"
}
}修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
chmod +r /var/log/messages #让 Logstash 可以读取日志
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages" #指定要收集的日志的位置</span>
type =>"system" #自定义日志类型标识
start_position =>"beginning" #表示从开始处收集
}
}
output {
elasticsearch { #输出到 elasticsearch
hosts => ["192.168.52.110:9200","192.168.52.120:9200"] #指定 elasticsearch 服务器的地址和端口
index =>"system-%{+YYYY.MM.dd}" #指定输出到 elasticsearch 的索引格式
}
}
systemctl restart logstash Acceda al navegador http://192.168.137.10:9100/ para ver la información del índice
Despliegue de ELK Kiabana (operado en el nodo Node1)
Instalar Kiabana
#上传软件包 kibana-5.5.1-x86_64.rpm 到/opt目录
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpmConfigurar el archivo de configuración principal de Kibana
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,配置es服务器的ip,如果是集群则配置该集群中master节点的ip
elasticsearch.url: "http://192.168.137.10:9200","http://192.168.137.15:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
--86--取消注释,配置kibana的日志文件路径(需手动创建),不然默认是messages里记录日志
logging.dest: /var/log/kibana.logCree un archivo de registro e inicie el servicio Kibana
touch /var/log/kibana.log
chown kibana:kibana /var/log/kibana.log
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 5601Verificar Kibana
Acceso al navegador http://192.168.137.10:5601
第一次登录需要添加一个 Elasticsearch 索引:
Index name or pattern
//输入:system-* #在索引名中输入之前配置的 Output 前缀“system”
单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果Agregue registros del servidor Apache (acceso, errores) a Elasticsearch y muéstrelos a través de Kibana
vim /etc/logstash/conf.d/apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log"> #指定真确目录位置
type=> "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log" #指定错误日志目录
type => "error"
start_position => "beginning"
}
output {
if[ type ] == "access" {
elasticsearch {
hosts => ["192.168.137.10:9200","192.168.137.15:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [ type] == "error"{
elasticsearch {
hosts => ["192.168.137.10:9200","192.168.137.15:9200"]
index => "apache_access-%{+YYYY.MM.dd}
}
}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.confAcceda al navegador http://192.168.137.10:9100 para verificar si se crea el índice
Acceda al navegador http://192.168.137.10:5601 para iniciar sesión en Kibana
单击“Index ->Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output
前缀 apache_access-*,并单击“Create”按钮。
用相同的方法添加 apache_error-*索引。
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access-* 、apache_error-* 索引, 可以查看相应的图表及日志信息。