Tabla de contenido
2. Introducción de componentes
4. Experimento de grupo de recopilación de registros ELK
2. Instale elasticsearch en los nodos nodo1 y nodo2
3. Inicie el servicio elasticsearch
4. Instale el complemento elasticsearch-head en el nodo1
6. Instale logstash en el servidor nodo1
8. Instale kibana en el nodo nodo1
Prefacio
ELK se refiere a la combinación de Elasticsearch, Logstash y Kibana. Son un conjunto de sistemas de recopilación, almacenamiento, búsqueda y visualización de registros de código abierto que a menudo se utilizan para administrar y analizar datos de registros de forma centralizada.
1. Elasticsearch: motor distribuido de búsqueda y análisis en tiempo real. Puede manejar datos a gran escala y proporcionar capacidades rápidas de búsqueda, agregación y análisis de datos.
2. Logstash: una herramienta para la recopilación, el procesamiento y la transmisión de registros. Admite la recopilación de datos de registro de múltiples fuentes, puede realizar limpieza, transformación y filtrado de datos, y enviar los datos al almacenamiento de destino, como Elasticsearch.
3. Kibana: una herramienta para visualización y análisis de datos. Puede mostrar datos visualmente en Elasticsearch a través de gráficos, paneles e informes para ayudar a los usuarios a comprender y analizar los registros.
El flujo de trabajo del sistema de recopilación de registros ELK es el siguiente:
1. Configuración de Logstash: configure el complemento de entrada en Logstash y especifique la fuente de los datos de registro, como archivos, redes o colas de mensajes.
2. Procesamiento de datos: utilice el complemento de filtro Logstash para limpiar, convertir y filtrar los datos de registro para que satisfagan las necesidades y luego enviar los datos procesados a Elasticsearch.
3. Almacenamiento de datos: Elasticsearch indexa y almacena los datos de registro recibidos para una búsqueda y análisis rápidos.
4. Visualización de datos: utilice Kibana para crear componentes visuales como gráficos, paneles e informes, y muestre información estadística y tendencias de datos de registro mediante la búsqueda y agregación de datos.
5. Búsqueda y análisis en tiempo real: a través de la función de búsqueda proporcionada por Kibana, los datos de registro se pueden buscar y analizar en tiempo real para ayudar a descubrir problemas, monitorear el sistema y optimizar el rendimiento.
Las ventajas del sistema de recopilación de registros ELK incluyen:
- Procesamiento eficiente de datos de registros a gran escala: Elasticsearch, como motor de búsqueda y almacenamiento, puede manejar datos de registros a gran escala.
- Procesamiento y filtrado de datos flexibles: Logstash proporciona una gran cantidad de complementos y filtros para procesar y transformar de manera flexible los datos de registro.
- Visualización de datos intuitiva: Kibana proporciona una interfaz gráfica para mostrar estadísticas y tendencias de datos de registro de forma intuitiva.
- Búsqueda y análisis en tiempo real: el sistema ELK admite búsqueda y análisis en tiempo real, lo que puede ayudar a localizar y resolver problemas rápidamente.
En resumen, el sistema de recopilación de registros ELK es una poderosa combinación de herramientas que puede ayudar a las empresas a administrar, almacenar, buscar y visualizar de manera centralizada grandes cantidades de datos de registros y mejorar las capacidades de monitoreo y resolución de problemas del sistema.
I. Descripción general
1. ELK consta de tres componentes: Elasticsearch, Logstash y Kibana.
| Colección de registros | Logstash |
| Análisis de registros | búsqueda elástica |
| Visualización de registros | kibana |
2. ¿Por qué usarlo?
Los registros son muy importantes para analizar el estado de los sistemas y aplicaciones, pero generalmente la cantidad de registros es relativamente grande y está dispersa.
Si hay relativamente pocos servidores o programas bajo administración, también podemos iniciar sesión en cada servidor uno por uno para verlos y analizarlos. Pero si la cantidad de servidores o programas es grande, este método resultará insuficiente. En base a esto, se han aplicado algunos sistemas de registro centralizados. Actualmente, los más famosos y maduros incluyen Splunk (comercial), Scribe de FaceBook, Fluentd de Chukwa Cloudera de Apache y ELK, etc.
2. Introducción de componentes
1、búsqueda elástica
Función: análisis de registros, recopilación de registros de código abierto, análisis, programa de almacenamiento
Características:
Distribuido,
configuración cero,
descubrimiento automático
, fragmentación automática de índices,
mecanismo de copia de índices,
interfaz de estilo Restful,
múltiples fuentes de datos,
carga de búsqueda automática
2、logstash
Función: herramienta para recopilación, recopilación, análisis y filtrado de registros.
Proceso de trabajo:
El método de trabajo general es la arquitectura c/s. El cliente se instala en el servidor que necesita recopilar registros. El servidor se encarga de filtrar y modificar los registros recibidos de cada nodo, y luego los envía a Elasticsearch junto con Entradas → Filtros →
Salidas
. -->Filtrado-->Salida
| Archivo: lee desde un archivo en el sistema de archivos, similar al comando tail -f |
| Syslog: escuche los mensajes de registro del sistema en el puerto 514 y analícelos de acuerdo con el estándar RFC3164 |
| Redis: leer desde el servicio redis |
| Beats: leer desde filebeat |
| Grok: analiza datos de texto arbitrarios. Grok es el complemento más importante para Logstash. Su función principal es convertir cadenas de formato de texto en datos estructurados específicos y utilizarlos con expresiones regulares. |
| Expresión grok proporcionada oficialmente: logstash-patterns-core/patterns en main · logstash-plugins/logstash-patterns-core · GitHub |
| Depuración en línea de Grok: Depurador de Grok |
| Mutar: convertir campos. Por ejemplo, eliminar, reemplazar, modificar, cambiar el nombre de campos, etc. |
| Soltar: descartar algunos eventos sin procesar. |
| Clonar: Copiar el Evento. También se pueden agregar o eliminar campos durante este proceso. |
| Geoip: agrega información geográfica (utilizada para la visualización gráfica de kibana en el front-end) |
| Elasticsearch: puede guardar datos de manera eficiente y consultarlos de manera conveniente y sencilla. |
| Archivo: guarde los datos del evento en un archivo. |
| Graphite: envía datos de eventos a un componente gráfico, implementando un componente de código abierto actualmente popular para almacenar visualización gráfica. |
3、kibana
Función: visualización de registros
Una interfaz web amigable para que Logstash y ElasticSearch realicen análisis en función de los registros recopilados y almacenados, lo que puede ayudar a resumir, analizar y buscar registros de datos importantes.
3. Tipo de arquitectura
1、ELK
es
logstash
kibana
2、ELKK
es
logstash
kafka
kibana
3. ELFK
es
logstash es pesado y ocupa más recursos del sistema.
filebeat es liviano y ocupa menos recursos del sistema
. kibana
4、ELFKK
es
logstash
filebeat
kafka
kibana
4. Experimento de grupo de recopilación de registros ELK
1. Topología experimental
Al realizar este experimento, se proporcionan al menos 2 núcleos 4G para cada host. De lo contrario jeje~~ ya lo entiendes.
Dirección de descarga https://elasticsearch.cn/download/

Establecer nombres de host en el nodo1 y el nodo2
####分别修改主机名#####
###node1
hostnamectl set-hostname node1
echo "192.168.115.131 node1" "192.168.115.136 node2" >> /etc/hosts
scp /etc/hosts 192.168.115.136:/etc/hosts
bash
###node2
hostnamectl set-hostname node2
bash
######测试通联#######
###node1
ping node2
###node2
ping node1

2. Instale elasticsearch en los nodos nodo1 y nodo2
2.1. Primero verifique la versión Java del entorno Java. Si no, instale yum install -y java-1.8.0-openjdk.
2.2 Instalar búsqueda elástica
Como se muestra a continuación, este es el paquete de instalación utilizado en este experimento.

##安装elasticsearch
rpm -ivh elasticsearch-5.5.0.rpm
##配置
vim /etc/elasticsearch/elasticsearch.yml
###进去解开注释
cluster.name:my-elk-cluster #集群名称
node.name:node1 #节点名字
path.data: /var/lib/elasticsearch #数据存放路径
path.logs:/var/log/elasticsearch/ #日志存放路径
bootstrap.memory_lock:false #在启动的时候不锁定内存
network.host:192.168.115.131 #提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 #侦听端口为9200
discovery.zen.ping.unicast.hosts:["node1","node2"] #群集发现通过单播实现
###同理安装node2的elasticsearch
###把这份配置文件传输给node2,修改一下节点名字和IP就好了
scp /etc/elasticsearch/elasticsearch.yml 192.168.115.136:/etc/elasticsearch/elasticsearch.yml
3. Inicie el servicio elasticsearch
3.1 Inicie el comando systemctl start elasticsearch.service
nodo1
nodo2
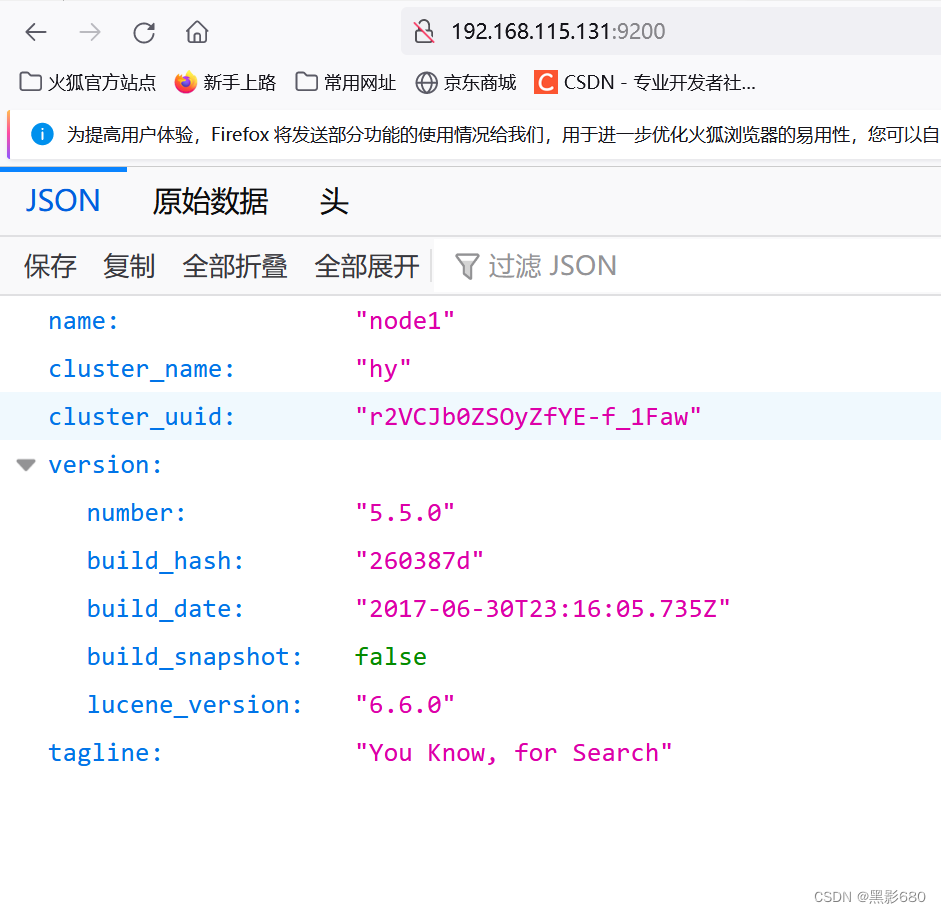
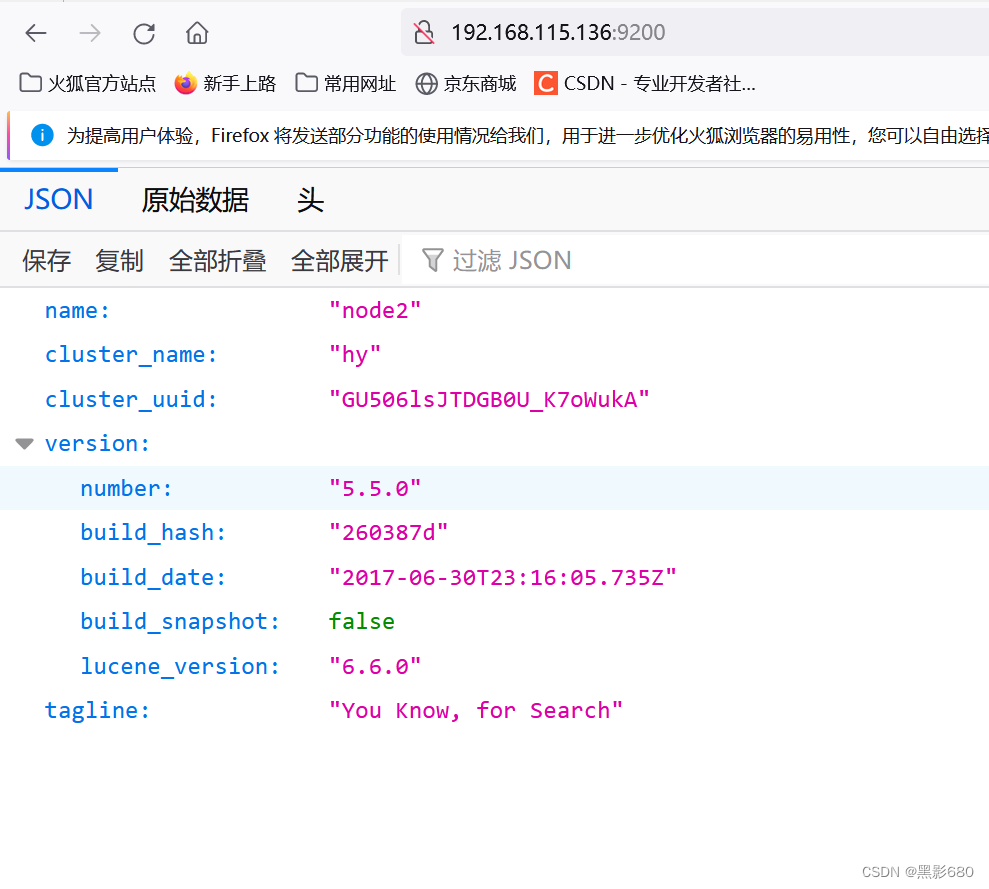
3.2 Acceso al navegador para ver la información del nodo
192.168.115.131:9200
192.168.115.136
:9200
Verifique el estado de salud del clúster: 192.168.115.131:9200/cluster/health
192.168.115.136:9200/clúster/salud
Verde salud amarillo advertencia grupo rojo no disponible, error grave
4. Instale el complemento elasticsearch-head en el nodo1
####编译安装
cd elk
tar xf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure && make && make install
###等待安装完毕。安装完毕后会生成命令:npm
###拷贝命令
cd elk
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
##安装elasticsearch-head
cd elk
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head
npm install
###修改elasticsearch配置文件node1、2都要改
vim /etc/elasticsearch/elasticsearch.yml
# Require explicit names when deleting indices:
#
#action.destructive_requires_name:true
http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin: "*" //跨域访问允许的域名地址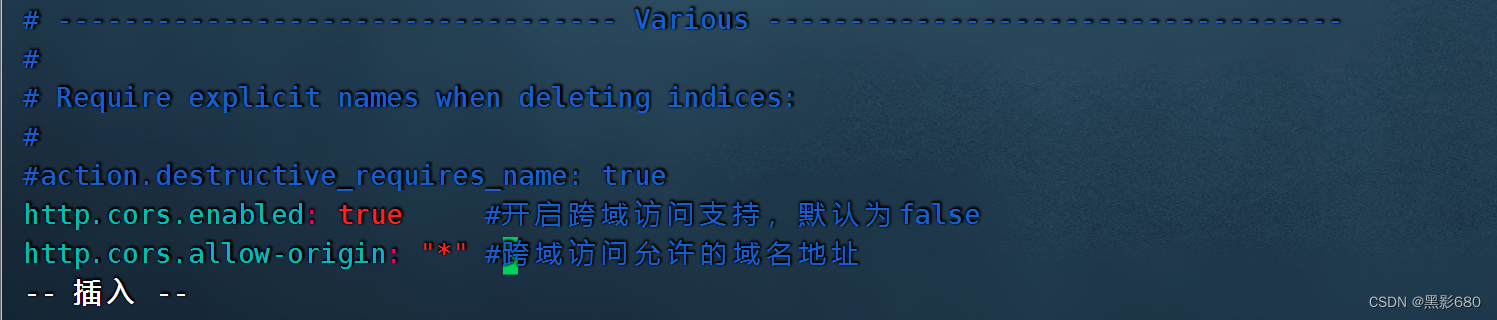 4.1 Reinicie el servicio: systemctl reinicie elasticsearch. Verifique si el puerto 9200 está activo en ambos nodos.
4.1 Reinicie el servicio: systemctl reinicie elasticsearch. Verifique si el puerto 9200 está activo en ambos nodos.

###启动elasticsearch-head
cd /root/elk/elasticsearch-head
npm run start &
##查看监听: netstat -anput | grep :9100
 4.2 Visita 192.168.115.136:9100
4.2 Visita 192.168.115.136:9100
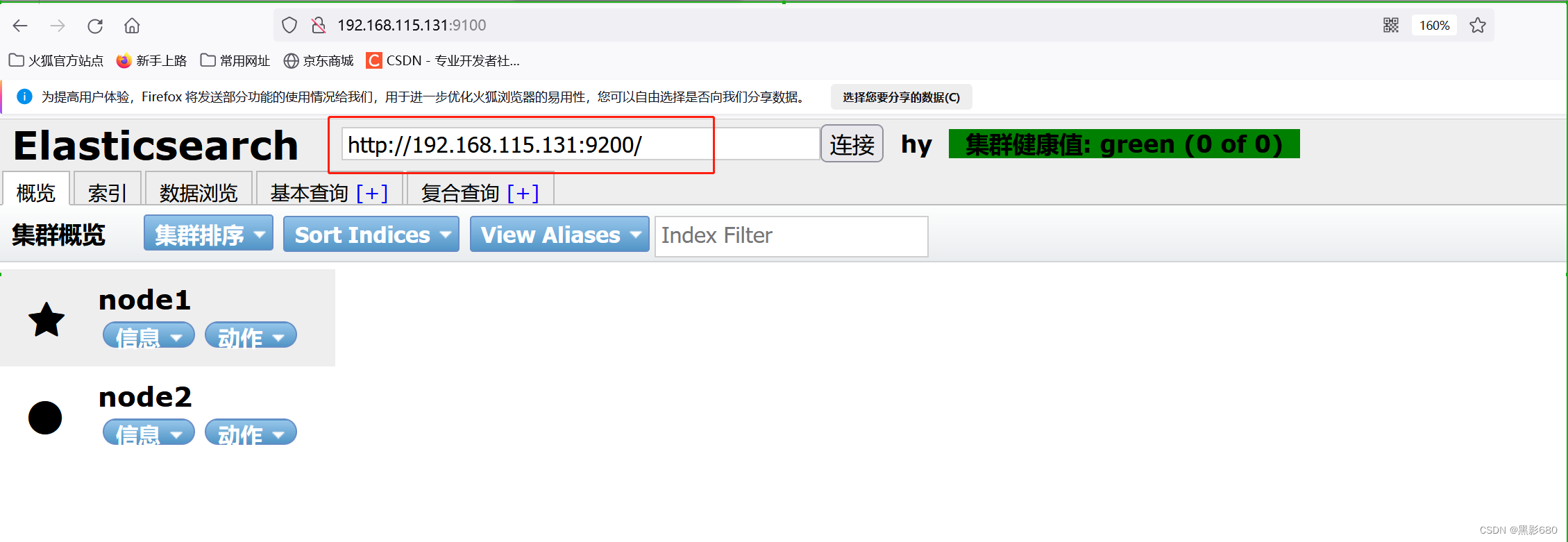
5. Entrada de prueba
5.1、curl -XPUT '192.168.115.131:9200/index-demo/test/1?pretty&pretty' -H 'Tipo de contenido: aplicación/json' -d '{"user":"hy","mesg":" Hola"}
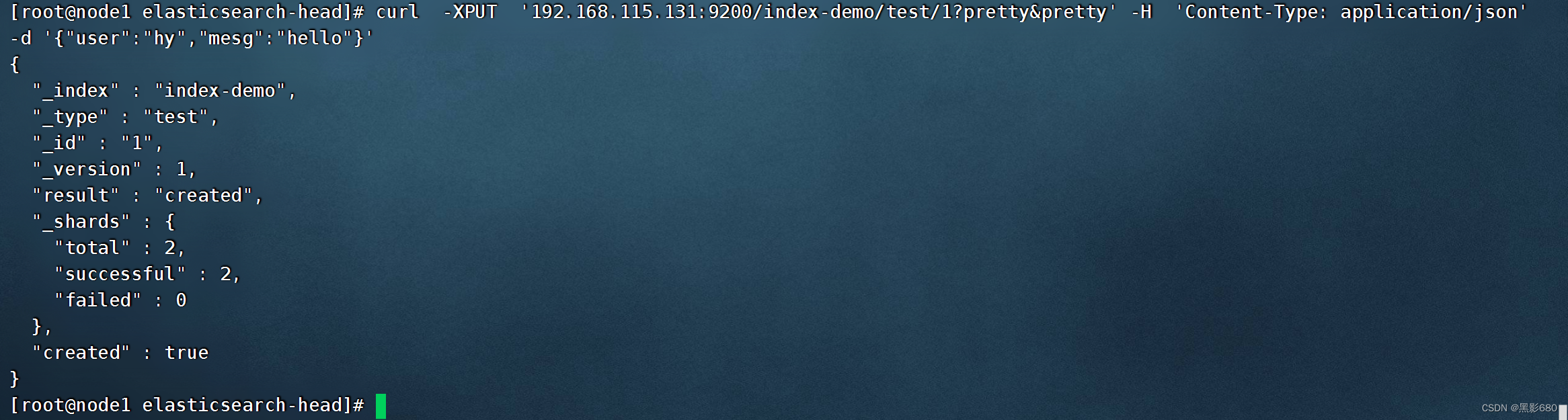
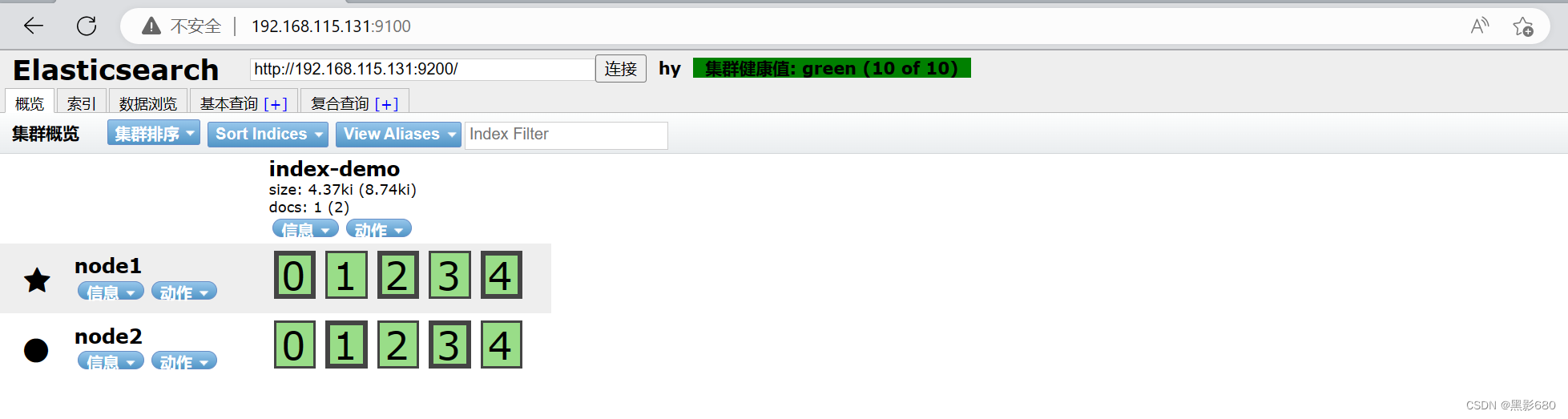
Visita 192.168.115.131:9100 para ver los datos de nuestra prueba "hola"

6. Instale logstash en el servidor nodo1
cd elk
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
In -s /usr/share/logstash/bin/logstash /usr/local/bin/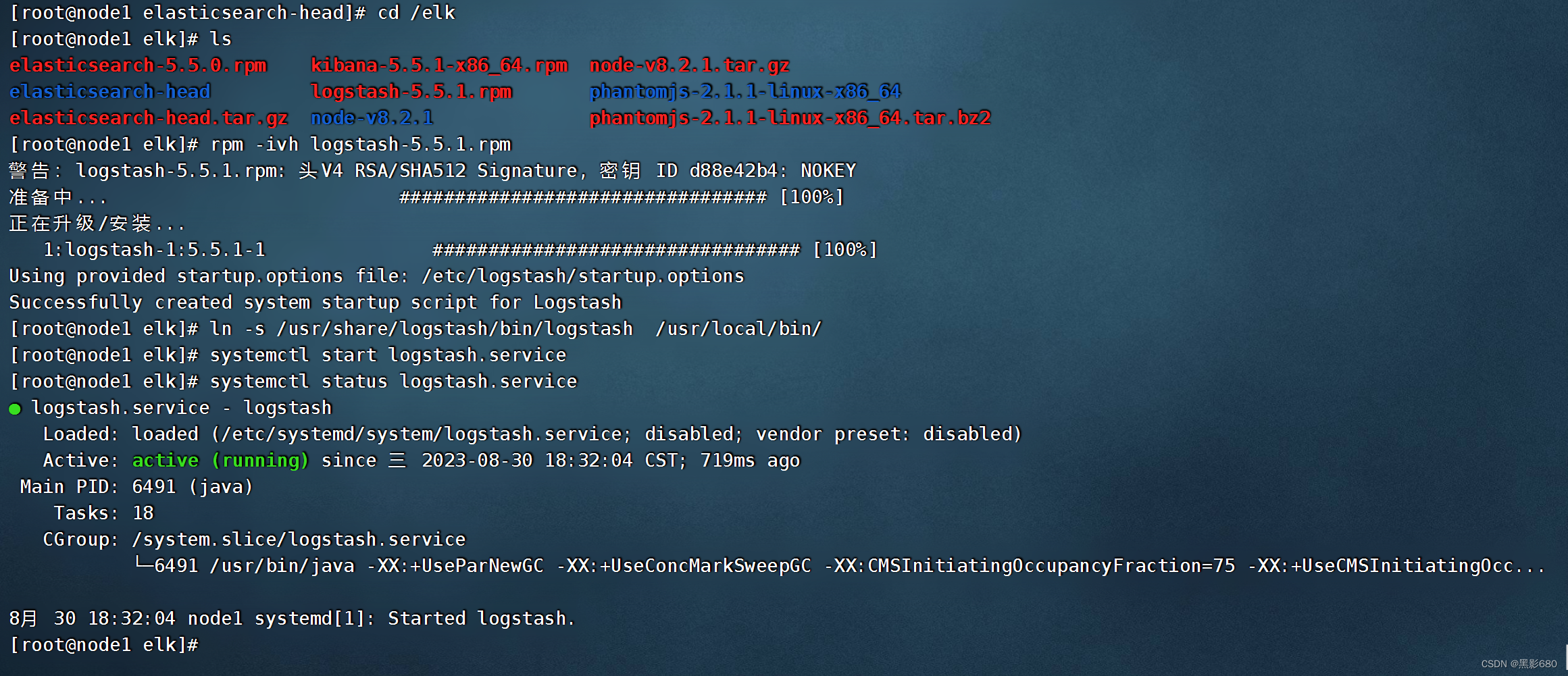
Prueba 1: entrada y salida estándar logstash -e 'input{ stdin{} }output { stdout{} }'
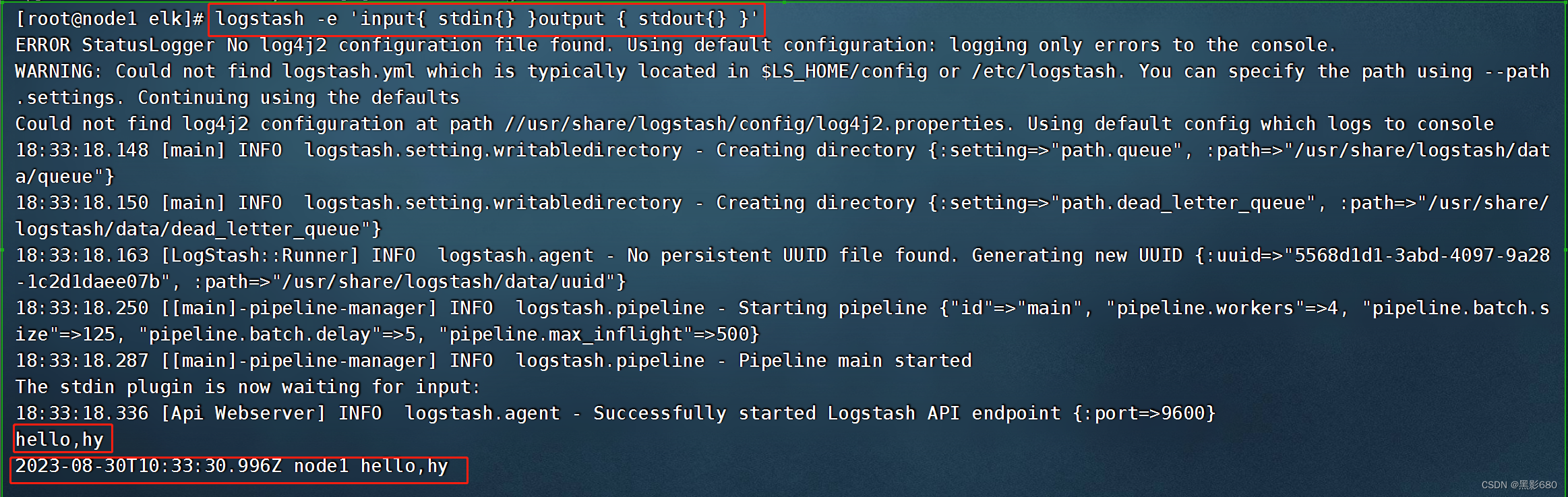
Prueba 2: use rubydebug para decodificar logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'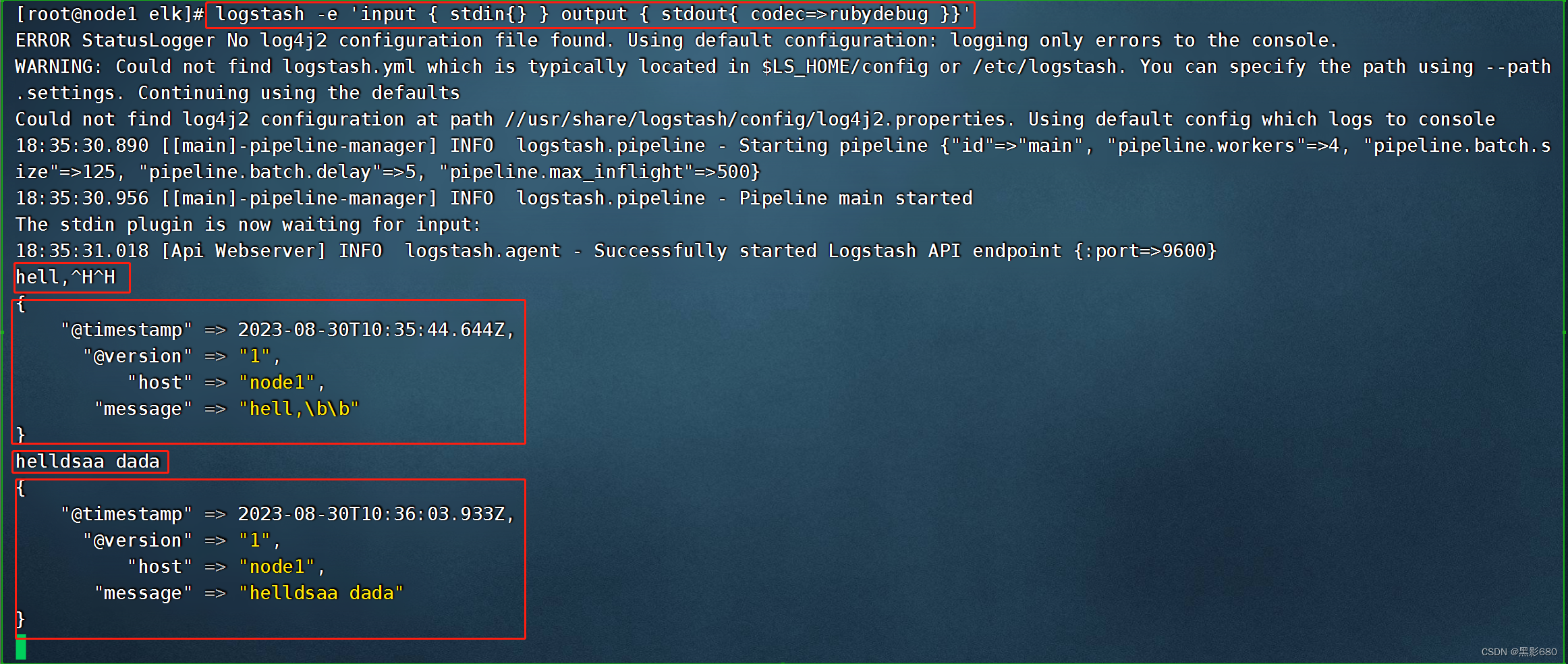
Prueba 3: Salida a elasticsearch
logstash -e 'entrada { stdin{} } salida { elasticsearch{ hosts=>["192.168.115.131:9200"]} }'
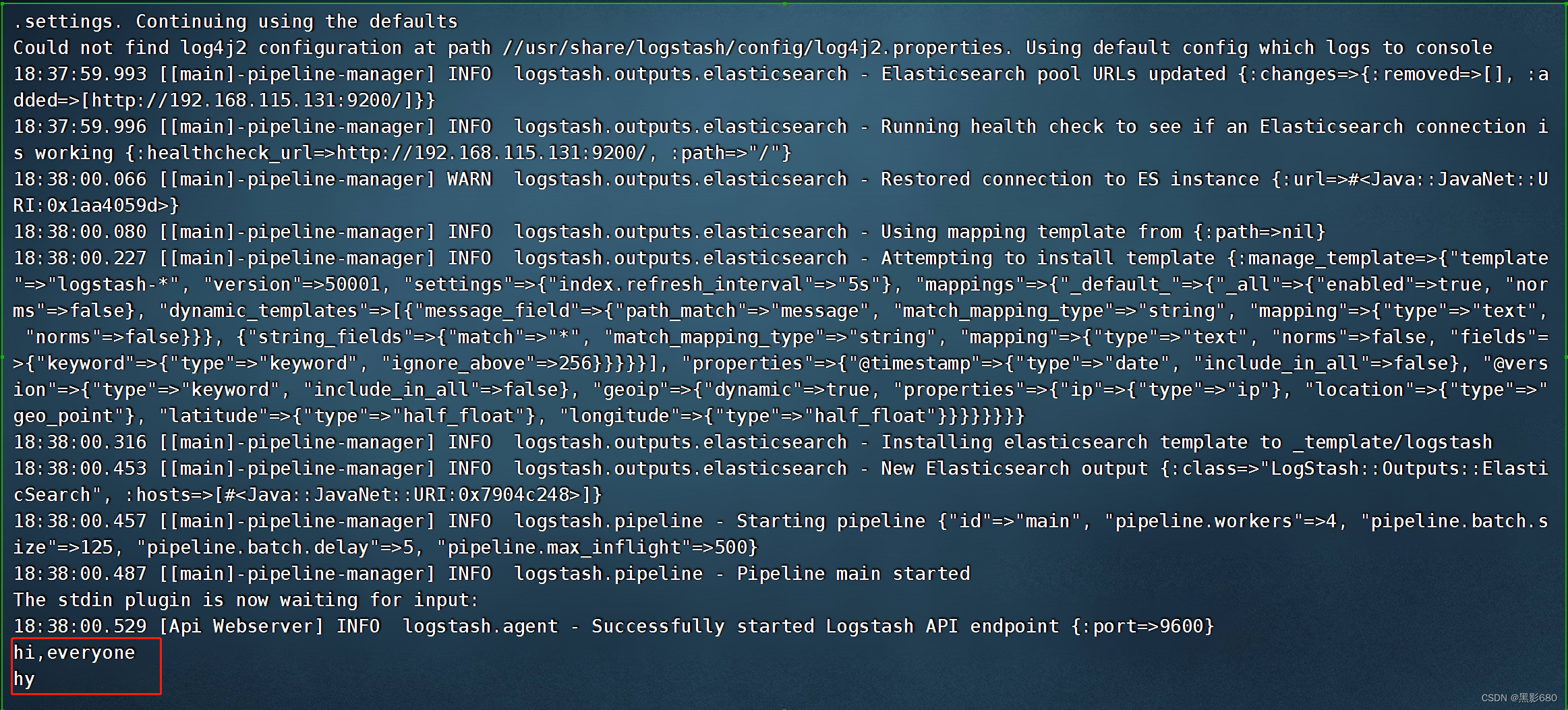
OK, la prueba terminó, verifiquemos en 192.168.115.131:9100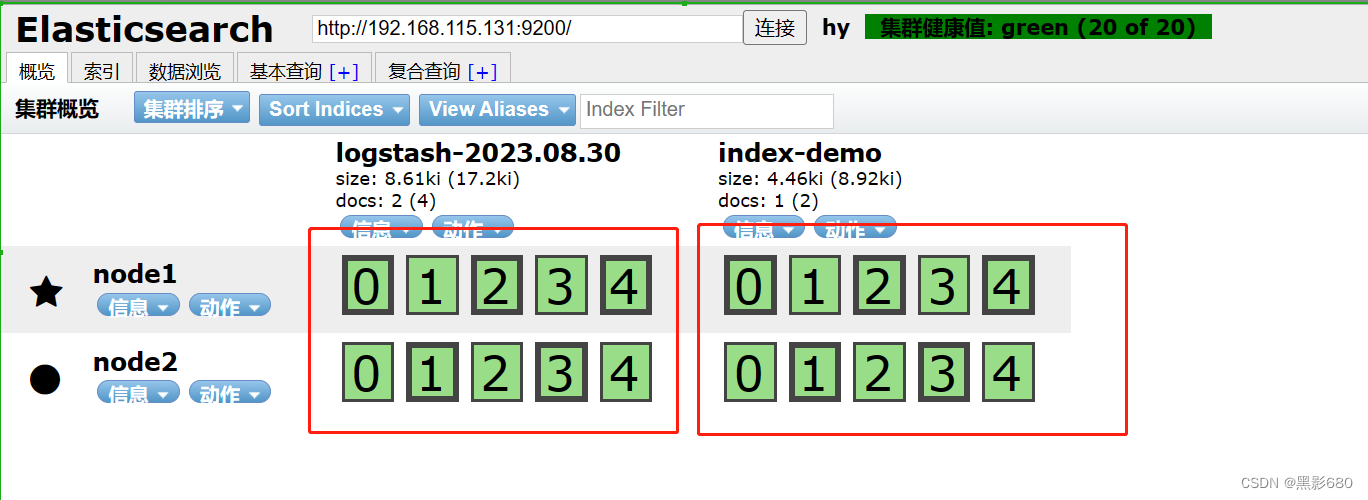
Elasticsearch ya está analizando, este es el contenido medido y hay un índice adicional.
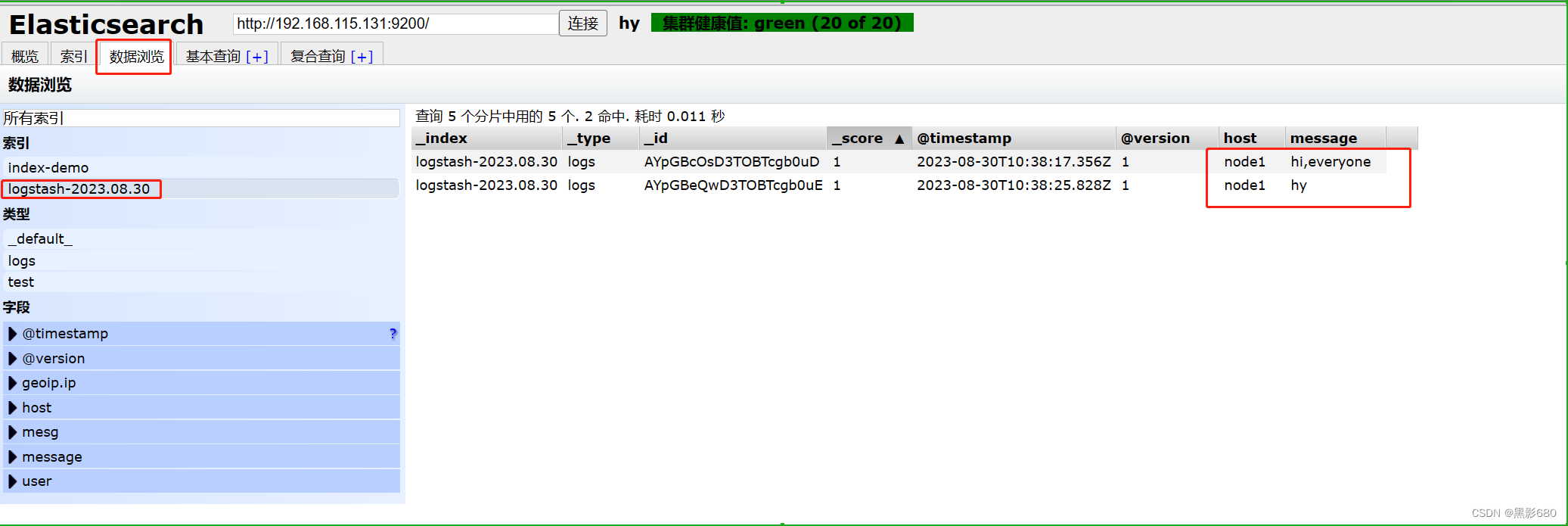
7. Formato de archivo de recopilación de registros de Logstash (almacenado en /etc/logstash/conf.d de forma predeterminada)
7.1 Introducción
Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}7.2 Configuración
Recopile registros de información del sistema a través de logstash
##因为要收集日志,root用户可以操作,其他用户是没权限的,所以加个读取的权限,否则是收集不到日志的
chmod o+r /var/log/messages
vim /etc/logstash/conf.d/system.conf
##system.conf是自定义的因为我搜集的是系统日志,若其他的应用的话可以取对应的名字来作为区分
##插入
input {
file{ ##类型:文件
path =>"/var/log/messages" ##系统日志文件路径
type => "system" ##类型自定义
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.115.131:9200"] ##给谁处理
index => "system-%{+YYYY.MM.dd}" ##自定义索引
}
}
Reinicie el servicio de registro: systemctl restart logstash
Vista del navegador 192.168.115.131:9100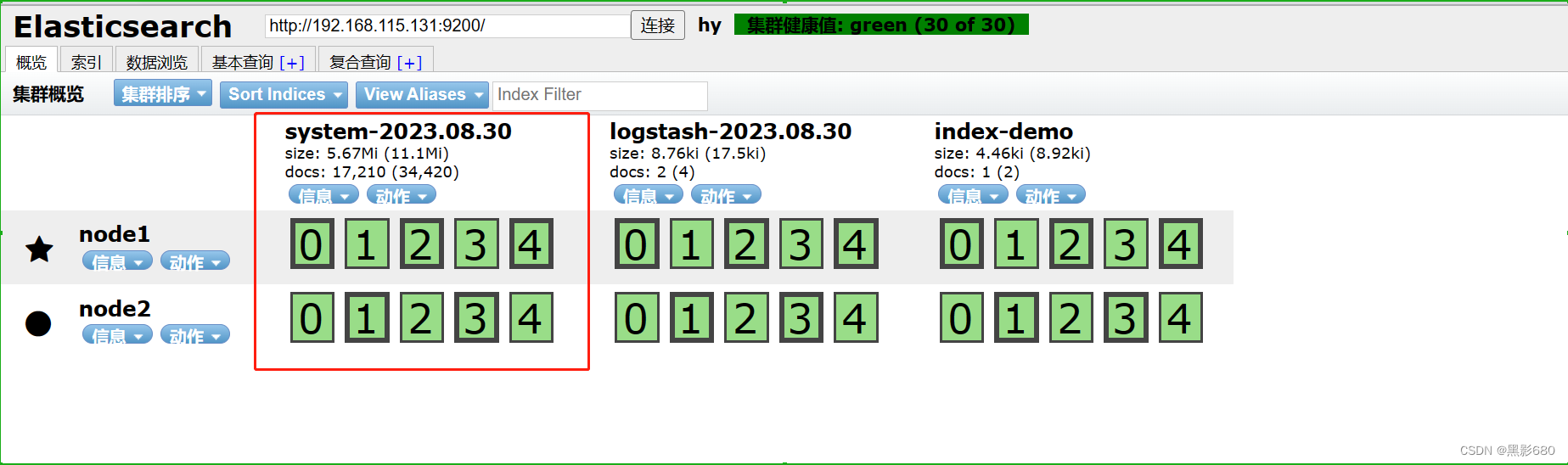
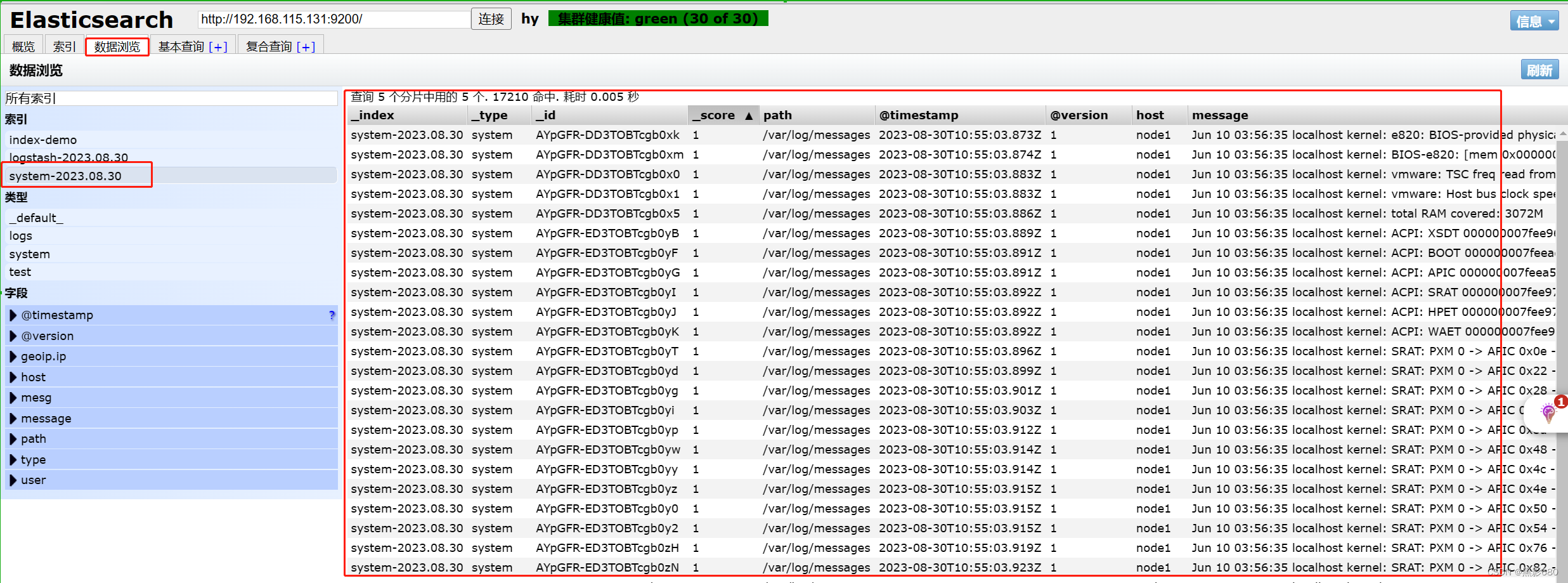
8. Instale kibana en el nodo nodo1
8.1 Instalación y configuración
####安装kibana
cd elk
rpm -ivh kibana-5.5.1-x86_64.rpm
##配置kibana
vim /etc/kibana/kibana.yml
server.port:5601 #Kibana打开的端口
server.host:"0.0.0.0" #Kibana侦听的地址
elasticsearch.url: "http://192.168.115.131:9200" #和Elasticsearch 建立连接
kibana.index:".kibana" #在Elasticsearch中添加.kibana索引
##启动kibana
systemctl start kibana8.2 Acceder a kibana
Visita 192.168.115.131:9100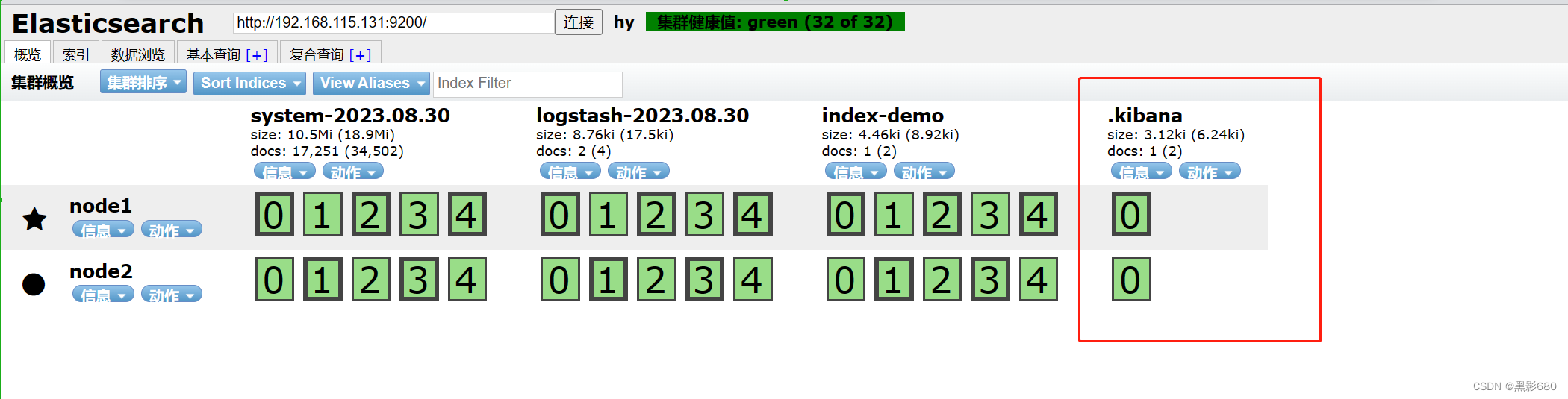
Visite 192.168.115.131:5601 para agregar índices. Puede agregar los índices en la imagen de arriba.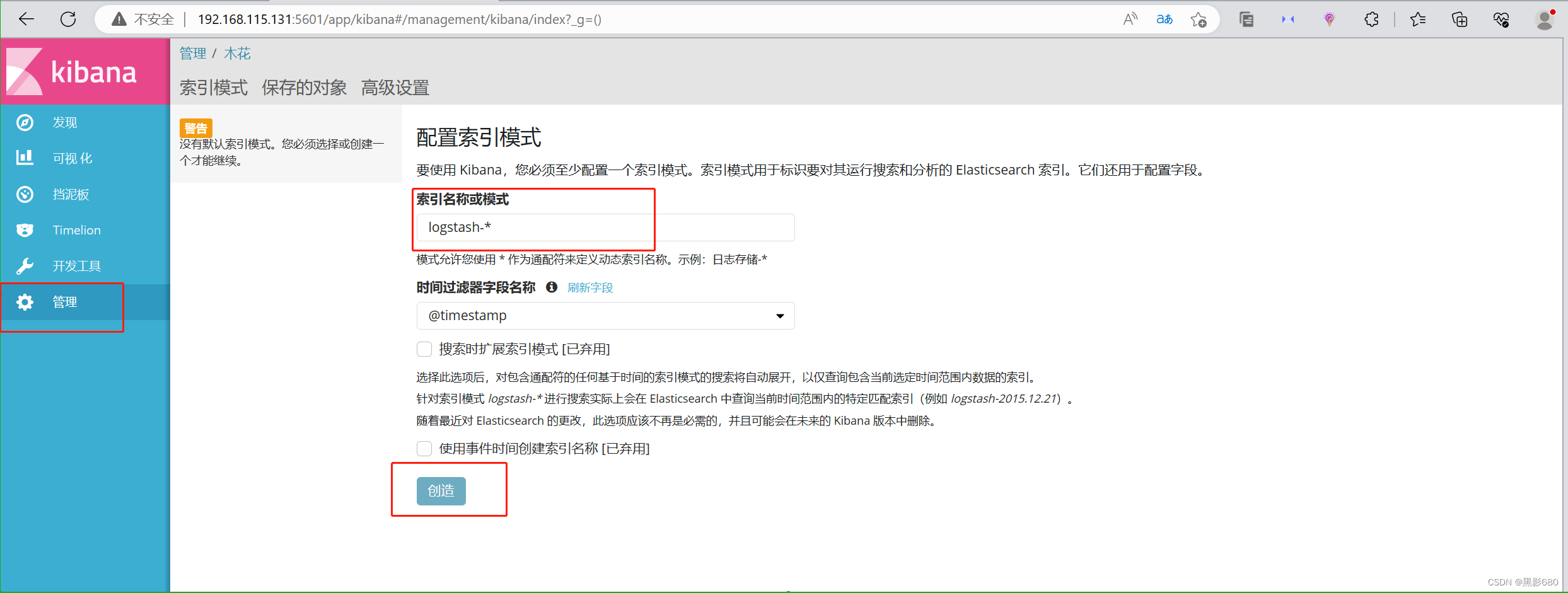
Aquí agrego un índice del sistema.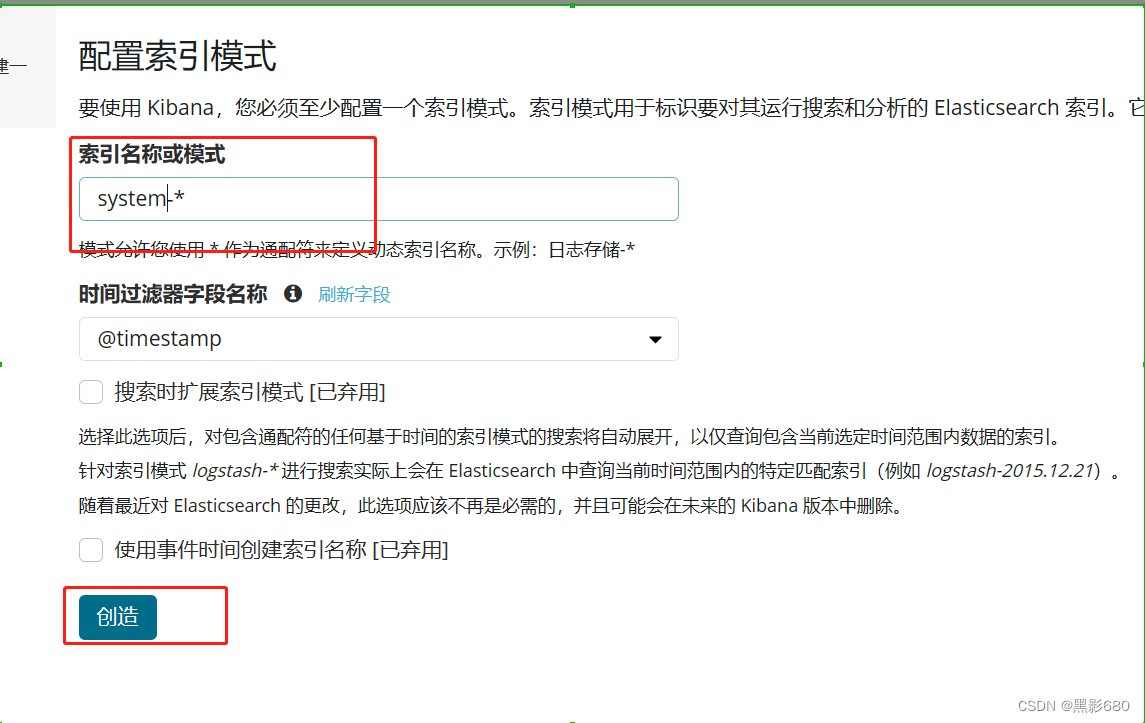
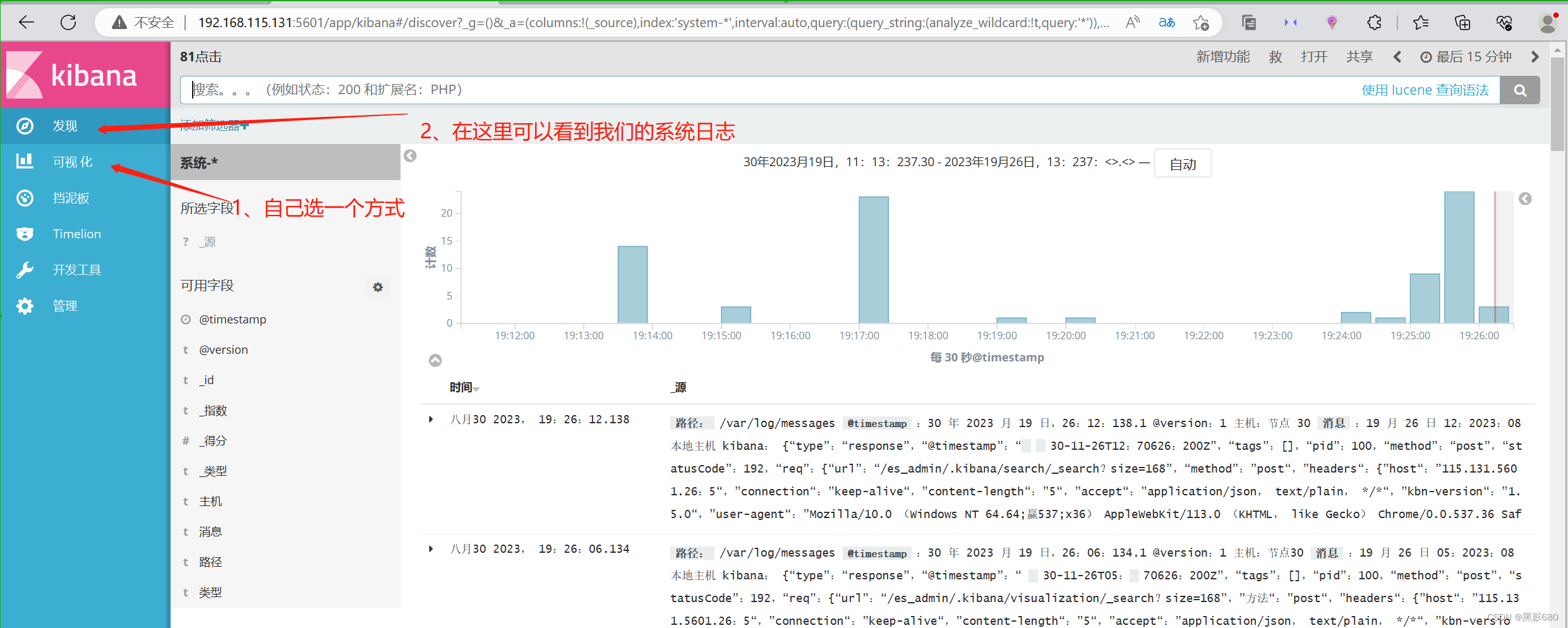
5. Configurar el nodo http
1. Configurar el servicio http de 192.168.115.140
yum -y install httpd
systemctl start httpd
netstat -anput | grep 80Visita httpd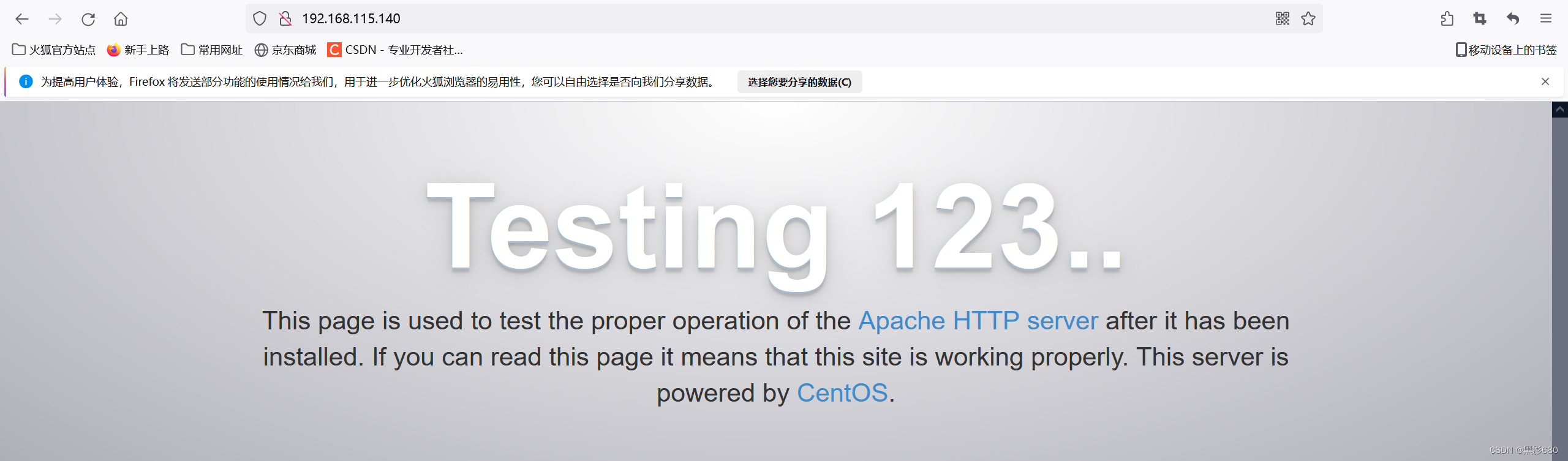
2. Configure nuestro logstash en este nodo para recopilar los registros de acceso de nuestro servidor http.
ruta de registro de acceso http/var/log/httpd/access_log
##安装logstash
rpm -ivh logstash-5.5.1.rpm3. Modificar el archivo de configuración.
vim /etc/logstash/conf.d/httpd.conf
###插入
input {
file{ ##类型:文件
path =>"/var/log/httpd/access_log" ##系统日志文件路径
type => "access" ##类型自定义
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.115.131:9200"] ##给谁处理
index => "httpd-%{+YYYY.MM.dd}" ##自定义索引
}
}
Iniciar la recopilación de registros systemctl start logstash.service
Utilice el comando logstash para importar la configuración:
Cree una conexión suave en -s /usr/share/logstash/bin/logstash /usr/local/bin/
Importar logstash -f /etc/logstash/conf.d/httpd.conf
4. Visita 192.168.115.131:9200

kibana 192.168.115.131:5601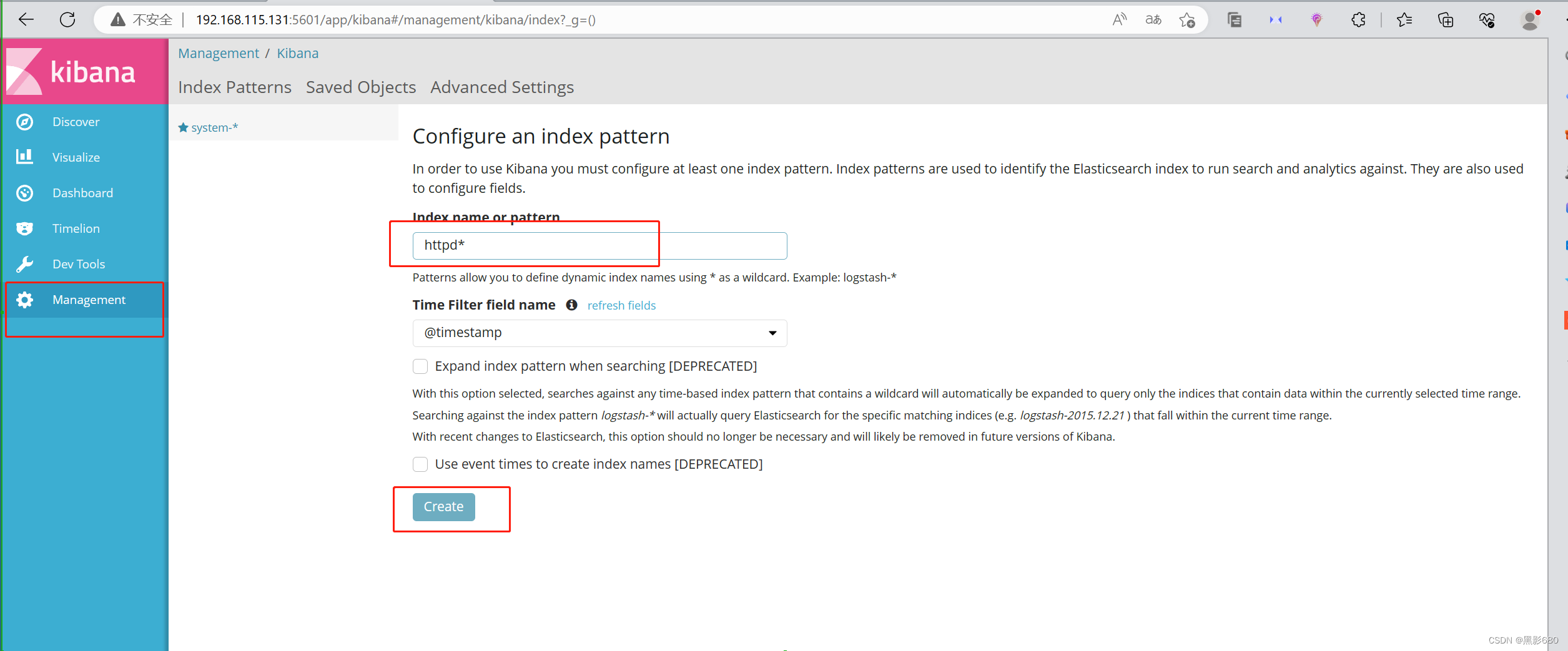
Verifique el registro de acceso de httpd
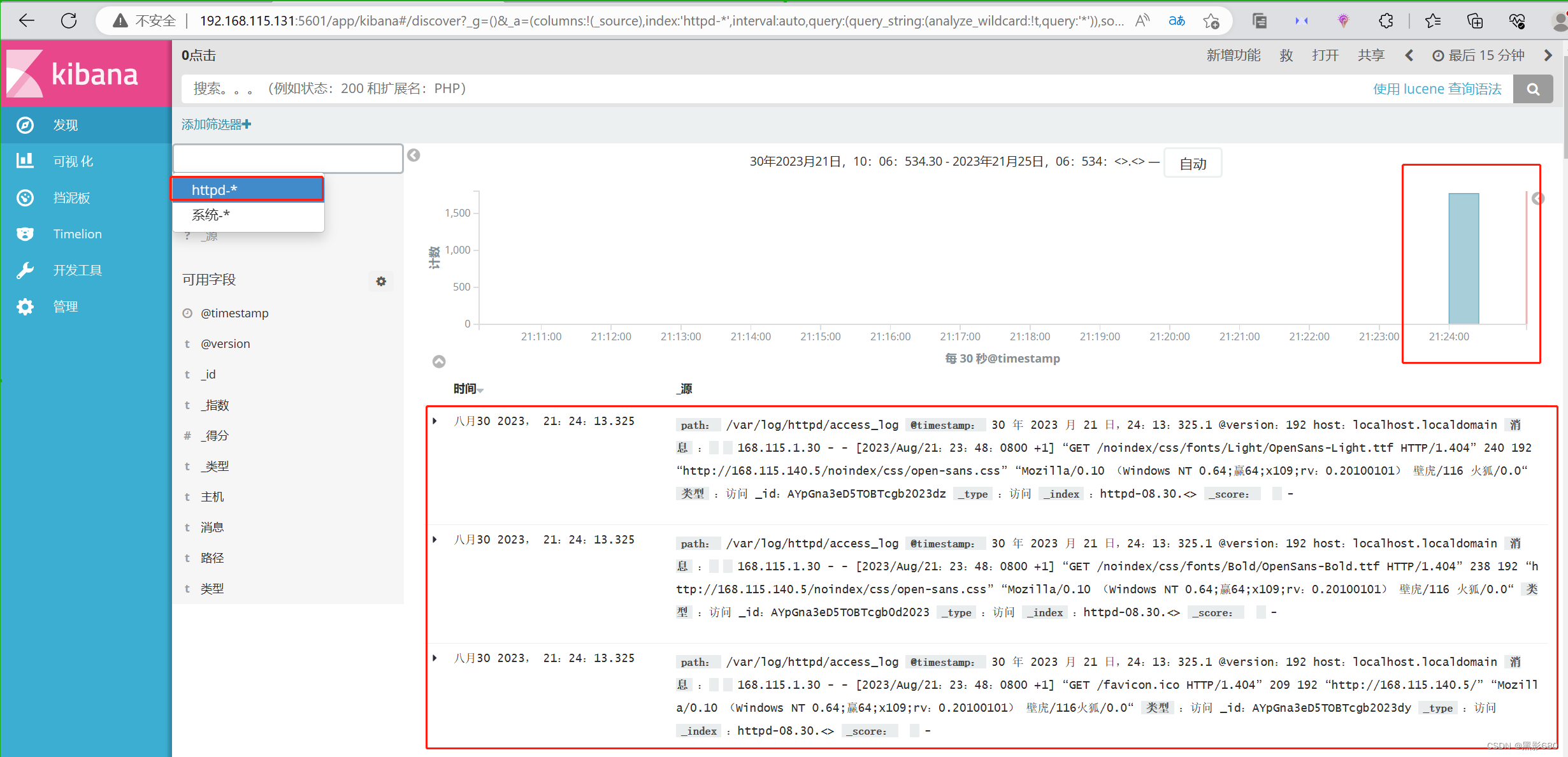
Bien, este es el final del experimento.