Directorio de artículos
1. Introducción al sistema de análisis de registros ELK
1.1 Resumen
- Sistema de análisis de registros ELK
E:ElasticSearch Cluster
L:LogStash Agent
K:kibana Server
1.2 Servidor de registro
- Mejorar la seguridad
- Almacenamiento centralizado de registros
- Defecto: dificultad para analizar registros
1.3 Pasos de procesamiento de registros
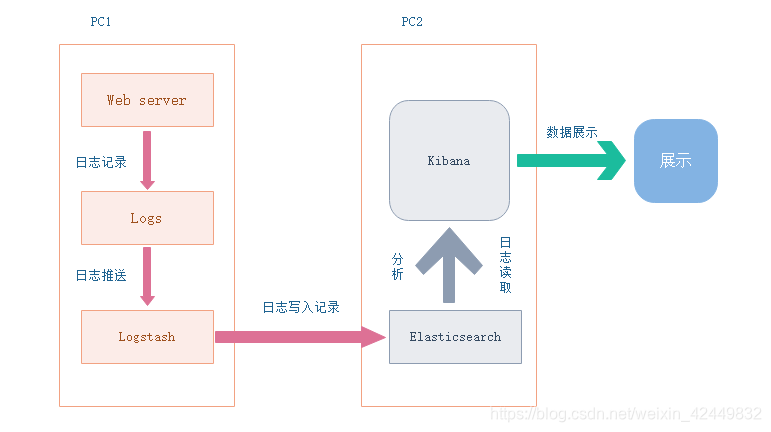
1.将日志进行集中化管理,即将APP servers的日志进行集中化管理到Logstash agent
2.将日志格式化(Logstash)并输出到 Elasticsearch
3.对格式化后的数据进行索引和存储(Elasticsearch)
4.前端数据的展示(Kibana)
可以在线查看界面化展示
Nota:
Logstash收集APP server产生的log,然后存放到Elasticsearch集群节点中
kibana从Elasticsearch集群节点中查询数据生成图表,再返回给Brower
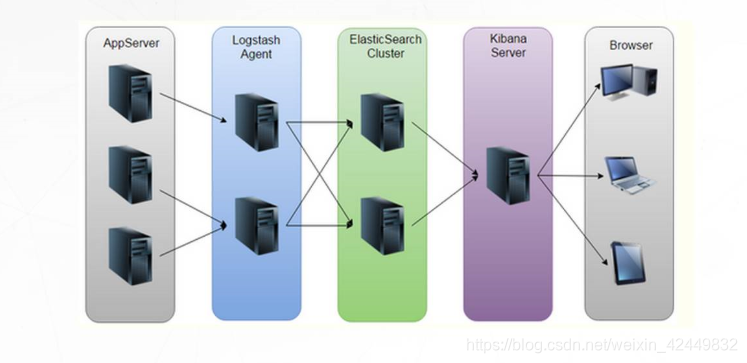
1.4 Cómo funciona la arquitectura ELK
1) Logstash部署至服务主机,对各个服务的日志进行采集、过滤、推送。
2) Elasticsearch存储Logstash传送的结构化数据,提供给Kibana。
3) Kibana提供用户UIweb页面进行,数据展示和分析形成图表等。
4) logs 泛指,各种日志文件以及日志信息:windows,negix,tomcat,webserver等等。
2. Introducción a Elasticsearch
2.1 Descripción general de Elasticsearch
- Proporciona un motor de búsqueda de texto completo con capacidades distribuidas para múltiples usuarios.
是一个基于Lucene的搜索服务器
基于restful web接口
使用java开发
作为apache许可条款下的开放源码发布,是第二流行的企业搜索引擎
被设计用于云计算中,能够达到实时搜索、稳定、可靠、快速、安装实用方便的需求
2.2 Conceptos importantes de Elasticsearch
2.2.1 Tiempo casi real (NRT)
- Elasticsearch es una plataforma de búsqueda casi instantánea. Hay un ligero retraso en el proceso de indexación de un documento para saber que se puede buscar en el documento (generalmente 1S)
2.2.2 Clúster (clúster)
-
Organizados por uno o más nodos, almacenan conjuntamente todos los datos y proporcionan funciones de indexación y búsqueda juntas
-
Uno de los nodos es el nodo principal. Este nodo se puede elegir y proporciona funciones de búsqueda e indexación conjunta entre nodos.
-
El clúster tiene un nombre de identificación exclusivo, el predeterminado es elaticsearch
-
El nombre del clúster es muy importante. Cada nodo se agrega a su clúster en función del nombre del clúster;
por lo tanto, para garantizar la singularidad del clúster, use diferentes nombres de clúster en diferentes entornos. -
Un clúster solo puede tener un nodo. Se recomienda configurar el modo de clúster al configurar elasticsearch
2.2.3 Nodo
1) 节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能
2) 像集群一样,节点之间可是通过名字来标识区分,默认是在节点启动时随机分配的字符名
3) 当然,你可以自己定义,该名字很重要,起到在集群中定位到对应的节点
4) 节点可以通过指定集群名字来加入到集群中,默认情况下,每个节点被设置成加入到elasticsearch集群。
5) 如果启动了多个节点,假设能够自动发现对方,他们将会自动组建一个名为elastisearch的集群
2.2.4 Índice (índice)
- Índice (biblioteca) → tipo (tabla) → documento (registro)
1) 一个索引就是一个拥有几分相似特征的文档的集合
2) 比如说,你可以有一个客户数据的索引、一个产品目录的索引、还有一个订单数据的索引
3) 一个索引用一个名字来标识(必须全部是小写字母组合),并且当我们要对相应的索引中的文档进行索引、收缩、更新和
删除的时候,都要用到这个名字
4) 在一个集群中,可以定义多个索引
2.2.5 Tipo y documento
- Tipo
1) 在一个索引中,你可以定义一种或多种类型
2) 一个类型是你的索引的一个逻辑上的分类分区,其寓意完全由你来定义。通常,会为具有一组共同字段的文档定义一个类型
比如:我们假设运营一个博客平台并且将所有的数据存储到一个索引中,在这个索引中,你可以为用户数据定义一个类型,
为博客数据定义一个类型,也可以为评论数据定义另一个类型
- Documento
1) 一个文档是一个可被索引的基础信息单元
2) 在一个index/type内,你可以存储任意多的文档
比如:你可以拥有一个客户的文档,某一个产品的文档;文档以JSON(Javascript Object Notation)格式来表示,
json是一个通用的互联网数据交互模式
注意:虽然一个文档在物理上位于一个索引内,但是实际上一个文档必须在一个索引内可以被索引和分配一个类型
2.2.6 Fragmentos y réplicas
- El propósito de usar fragmentación: en situaciones reales, los datos almacenados por el índice pueden exceder la configuración de hardware de un solo nodo
例如,一个30TB的日志,无法存储在单个磁盘上,而且索引极慢。
为了解决这个问题,elasticsearch集群提供将索引分割开,进行分片的功能
1) 当创建索引时,可以定义想要分片的数量
2) 每一个分片就是一个全功能的独立的索引,可以位于集群中的任何节点上
- Ventajas de fragmentación
1) 水平分割扩展,增大存储量
2) 分布式并行跨分片操作,提高性能和吞吐量
- Copiar ventajas
1) 高可用,应对分片节点单点故障
2) 提高性能,增大吞吐量
3.Introducción a Logstash
3.1 Descripción general de Logstash
1) 由JRuby语言编写,基于消息(message-based)的简单架构,并且运行在java虚拟机上
2) 一款强大的数据处理工具,可以实现数据传输、格式处理、格式化输出
3) 工作思路:数据输入(collect)、数据加工(如过滤、改写等enrich)以及数据输出(transport)
4) 特点:不同于分离的代理端(agent)或主机端(server),Logstash可配置单一的代理端(agent)与其他开源软件
结合,以实现不同的功能
3.2 Componentes principales de Logstash
-
Remitente: la recopilación de registros
es responsable de monitorear los cambios de los archivos de registro locales y recopilar el contenido más reciente de los archivos de registro a tiempo.
Por lo general, el agente remoto solo necesita ejecutar este componente -
Indexador: almacenamiento de registros
Responsable de recibir registros y escribir en archivos locales -
Agente: el centro de registro
es responsable de vincular varios remitentes y el número correspondiente de indexadores -
Búsqueda y almacenamiento
permite buscar y almacenar eventos. -
Interfaz web Interfaz
de pantalla basada en web
Nota:
- Los componentes anteriores se pueden implementar de forma independiente en la arquitectura lLogstash, lo que proporciona una buena escalabilidad del clúster.
3.3 Cómo funciona Logstash
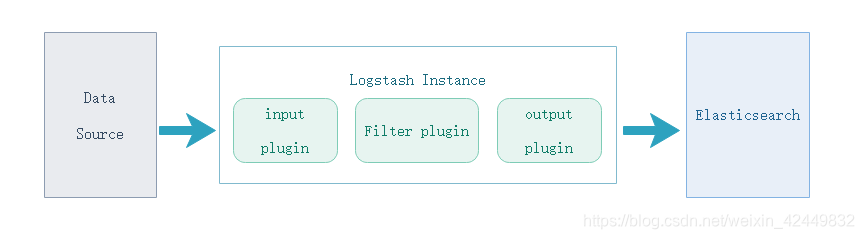
- Logstash consta de tres partes: entrada, filtro y salida
input负责从数据源提取数据,
filter负责解析、处理数据,
output负责输出数据,每部分都有提供丰富的插件
3.4 Clasificación de host de Logstash
- Dividido en: host del agente y host central
1)代理主机(agent):作为事件的传递者(shipper),将各种日志数据发送到中心主机;只需要运行logstash代理程序
2)中心主机(central host):可运行包括中间转发器(broker)、索引器(indexer)、搜索和存储器(search & storage)、
web界面端(web interface)在内的各个组件,以实现对日志数据地接收、处理和存储
4. Kibana
4.1 Descripción general de Kibana
1) 一个针对Elasticsearch的开源分析及可视化平台
2) 搜索、查看存储在Elasticsearch索引中的数据
3) 通过各种图标进行高级数据分析及展示
- Caracteristicas
1) 让海量数据更容易理解
2) 操作简单,基于浏览器地用户界面就可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态
3) 设置安装Kibana非常简单,无需编写代码,几分钟内就可以完成Kibana安装并启动Elasticsearch监测
4.2 Funciones principales
- Integración perfecta de Elasticsearch
- Datos integrados, análisis de datos complejos
- Interfaz flexible, fácil de compartir
- Configuración y visualización simples de múltiples fuentes de datos
- Exportación de datos simple