algoritmo de árbol de decisión
Ingeniería de características - Extracción de características
La extracción de características es la conversión de datos arbitrarios en características numéricas que se pueden usar para el aprendizaje automático. Las computadoras no pueden reconocer directamente las cadenas de caracteres, y solo al convertir las cadenas de caracteres en características digitales que las máquinas puedan entender, la computadora puede comprender el significado expresado por la cadena de caracteres (características).
Se divide principalmente en: extracción de características del diccionario (discretización de características), extracción de características del texto (frecuencia de aparición de palabras características en los artículos).
Extracción de características del diccionario
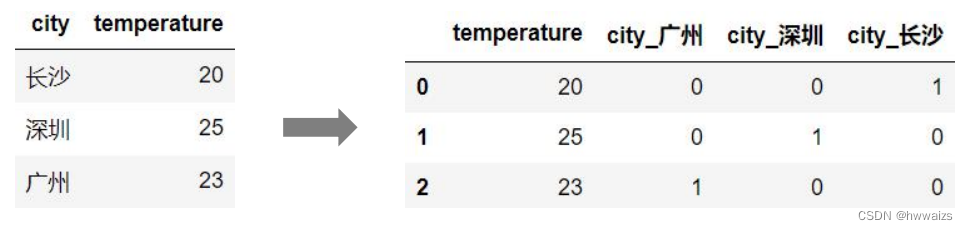
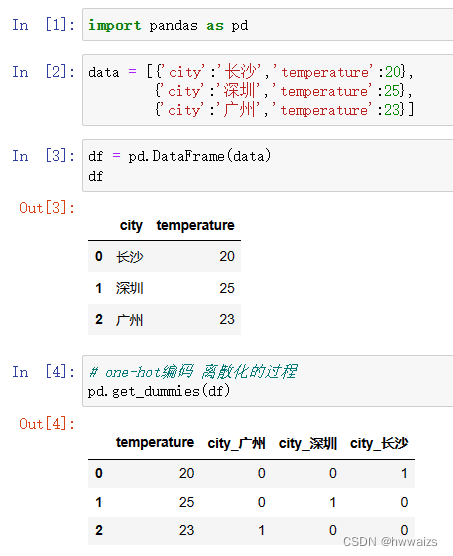
Transforma datos categóricos.
La computadora no puede reconocer los datos de ciudad y temperatura importados directamente, y debe convertirlos en códigos 0, 1 para que la computadora los reconozca.
Implementado en código como:
API de extracción de funciones de diccionario
sklearn.feature_extraction.DictVectorizer(sparse=Ture,...)
DictVectorizer.fit_transform(X),X:字典或者包含字典的迭代器返回值,返回sparse矩阵
DictVectorizer.get_feature_names()返回类别名称

Cuando la cantidad de datos es relativamente grande, el uso de la matriz dispersa puede mostrar mejor los datos de características, que es más intuitivo, no muestra 0 datos y ahorra memoria.
Extracción de características de texto
Caracterizar los datos del texto, la frecuencia de aparición de cada palabra en un artículo.
API de extracción de características de texto
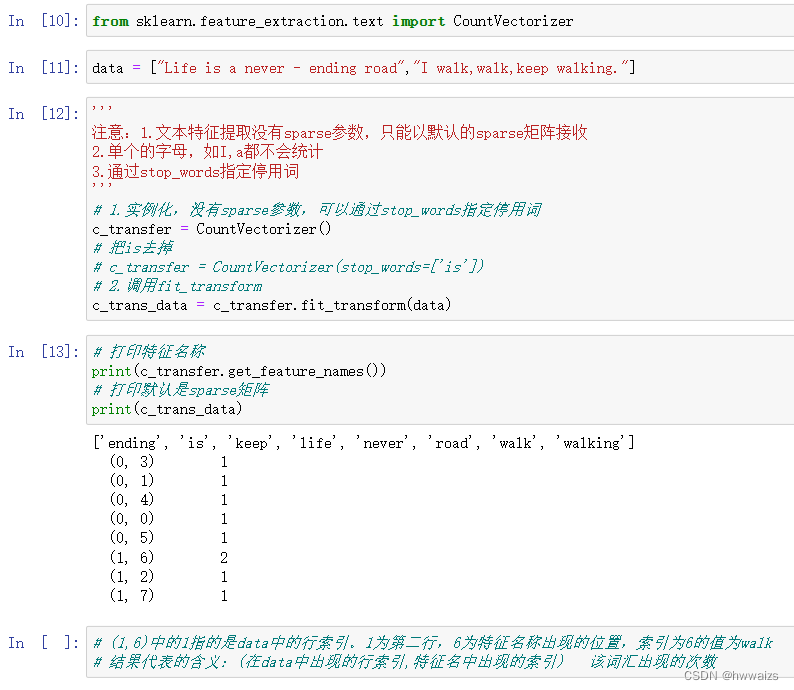
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
返回词频矩阵。
CountVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
CountVectorizer.get_feature_names()返回值:单词列表
Implementación de extracción de características de texto en inglés
Requisitos: reflejar la frecuencia del vocabulario en los siguientes párrafos
[“La vida es un camino de nunca acabar”, “Yo camino, camino, sigo caminando.”]
Nota:
1. No hay un parámetro disperso para la extracción de características de texto, y solo se puede recibir con la matriz dispersa predeterminada.
2. Una sola letra, como I, a, no se contará
. 3. Especifique palabras vacías a través de stop_words
Implementación de extracción de características de texto chino
Requisitos: reflejar la frecuencia del vocabulario en los siguientes párrafos
data = ['Este encuentro','Es tan hermoso, tan hermoso, tan hermoso, tan hermoso, tan hermoso. ']

Requisito: Reflejar la frecuencia de aparición de las palabras en el siguiente texto.
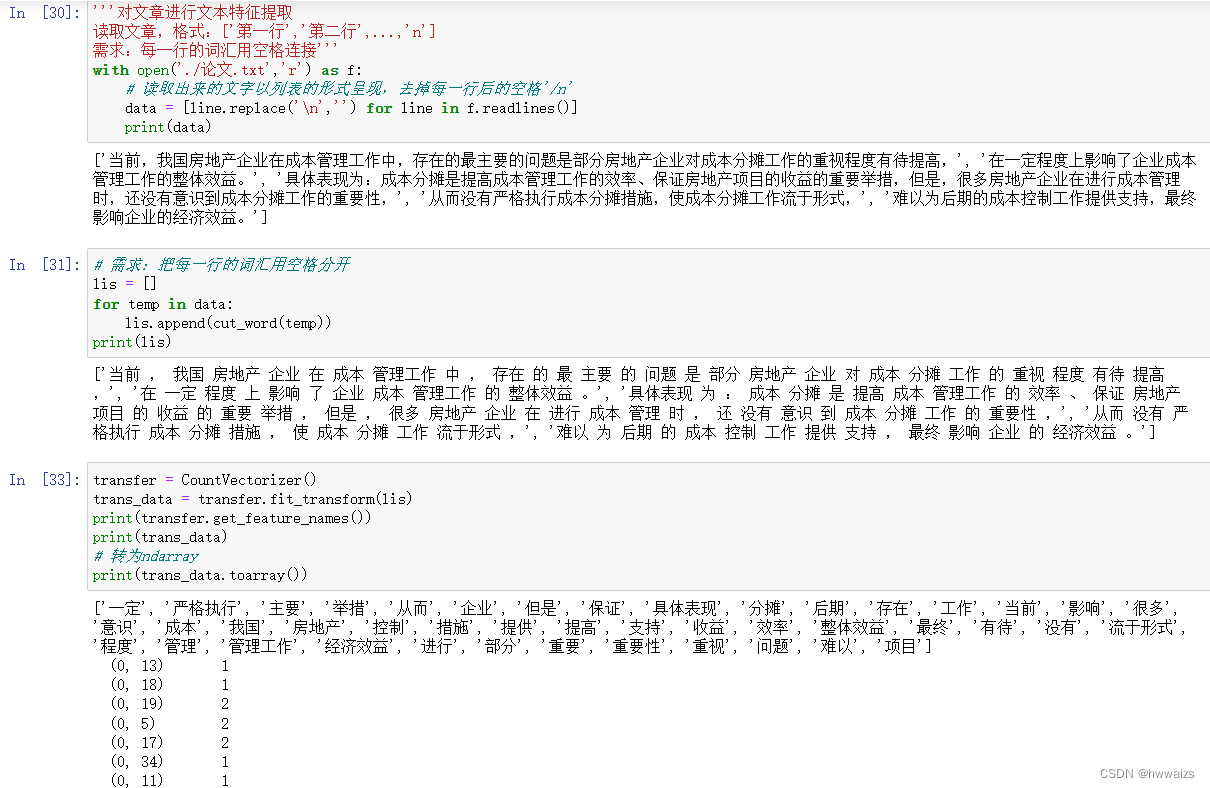
Extraer las palabras del artículo de manera uniforme, eliminar los valores repetidos y ponerlos en una lista. La matriz muestra el número de veces que aparece cada palabra en cada fila. Según la cantidad de palabras que aparecen, los artículos se pueden clasificar como artículos relacionados con las palabras.
Extracción de características de texto Tf-idf
La idea principal de TF-IDF es: si una palabra o frase tiene una alta probabilidad de aparecer en un artículo y rara vez aparece en otros artículos, se considera que la palabra o frase tiene una buena capacidad de discriminación de categorías y es adecuada para uso en la clasificación.
El papel de TF-IDF: Se utiliza para evaluar la importancia de una palabra para un conjunto de archivos o un archivo en un corpus.
Fórmula de extracción de características de texto tf-idf: tfidfi , j = tfi , j ∗ idfi tfidf_{i,j}=tf_{i,j}*idf_it fi yo d fyo , j=tf _yo , j∗yo d fyo
Frecuencia de término (term frecuencia, tf): se refiere a la frecuencia con la que una palabra dada aparece en el documento
Frecuencia de documento inversa (frecuencia de documento inversa, idf): es una medida de la importancia general de una palabra. El idf de una palabra específica se puede obtener dividiendo el número total de documentos por el número de documentos que contienen la palabra, y luego tomando el logaritmo en base 10 del cociente obtenido.
Por ejemplo, un artículo consta de 1000 palabras y bienes raíces aparece 500 veces, la frecuencia de bienes raíces en este artículo es: 500/1000=0.5; bienes raíces ha aparecido en 1000 documentos, el número total de documentos es 1000000, idf: log 1000000/1000 = 3 log1000000/1000=31000000/1000 _ _ _=3 ;tf-idf es 0,5*3=1,5.
No solo observe la cantidad de veces (frecuencia) que aparece una palabra en un determinado artículo, sino que también debe observar la cantidad de veces que aparece en todo el conjunto de archivos.
api de extracción de características de texto tf-idf
sklearn.feature_extraction.text.TfidfVectorizer
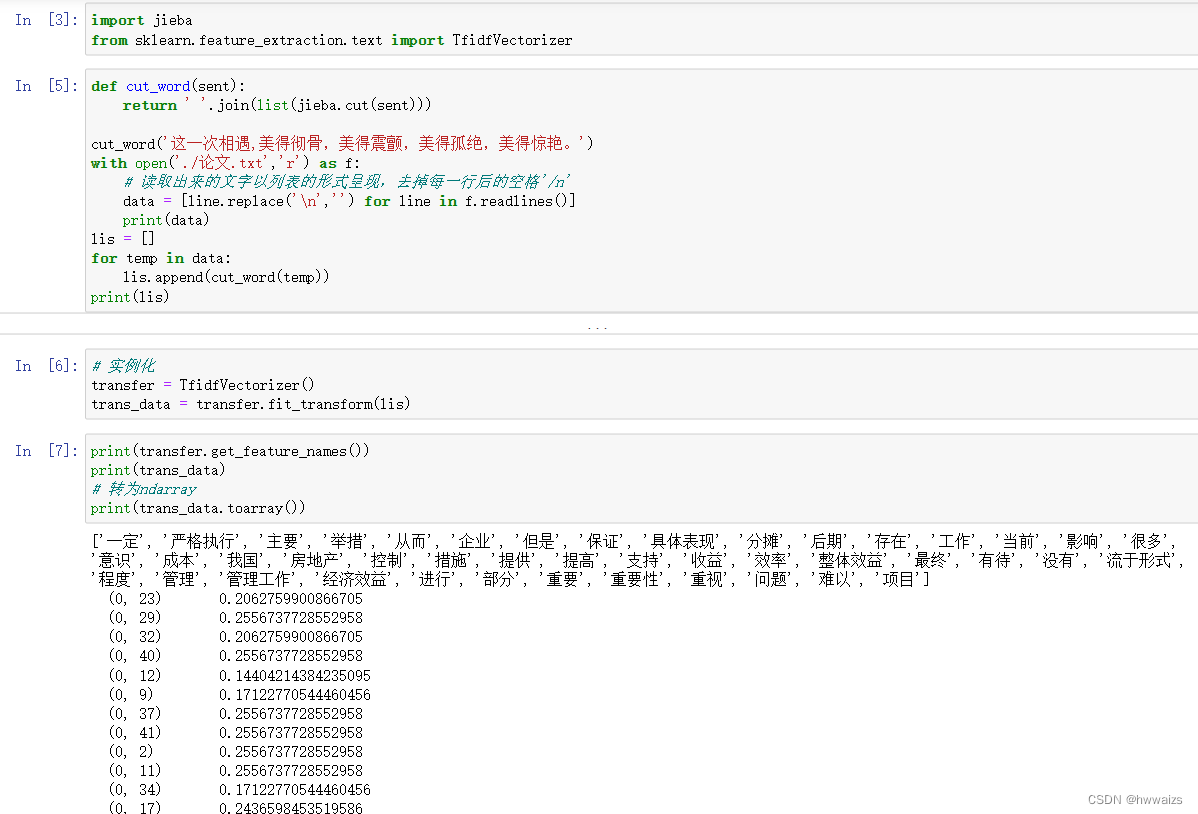

Lo que obtiene es el resultado de tfidf después del cálculo. Si no hay un conjunto de archivos, se divide por líneas. La lista se usa como el conjunto de archivos y cada línea se procesa como un archivo. Al juzgar el tamaño de tfidf, se usa cierto vocabulario como un vocabulario importante para la segmentación.
API de algoritmo de árbol de decisión
Categoría API
sklearn.tree.DecisionTreeClassifier 决策树的分类算法器
- criterion:设置树的类型
- entropy:基于信息熵,也就是ID3算法,实际结果与C4.5相差不大
- gini:默认参数,相当于基尼系数。CART算法是基于基尼系数做属性划分的,
所以criterion=gini时,实际上执行的是CART算法。
- splitter:在构造树时,选择属性特征的原则,可以是best或random。默认是best,
- best代表在所有的特征中选择最好的,random代表在部分特征中选择最好的。
- max_depth:决策树的最大深度,可以控制决策树的深度来防止决策树过拟合。
- min_samples_split:当节点的样本数小于min_samples_split时,不再继续分裂,默认值为2
- min_samples_leaf:叶子节点需要的最小样本数。如果某叶子节点的数目小于这个阈值,则会和
兄弟节点一起被剪枝。可以为int、float类型。
- min_leaf_nodes:最大叶子节点数。int类型,默认情况下无需设置,特征不多时,无需设置。
特征比较多时,可以通过该属性防止过拟合。
Caso: Predicción de supervivencia del pasajero del Titanic
Requisitos: Lea los siguientes datos para predecir la tasa de supervivencia
train.csv es el conjunto de datos de entrenamiento, que contiene información de funciones y etiquetas de supervivencia;
test.csv es el conjunto de datos de prueba, que solo contiene información de funciones.
PassengerId: número de pasajero; Survived: sobrevivió; Pclass: clase de billete; Name: nombre; Sex: género; Age: edad; SibSp:
número de familiares (hermanos); Parch: número de familiares (padres e hijos); Ticket: número de billete ; Tarifa: precio del billete; Cabina: cabina;
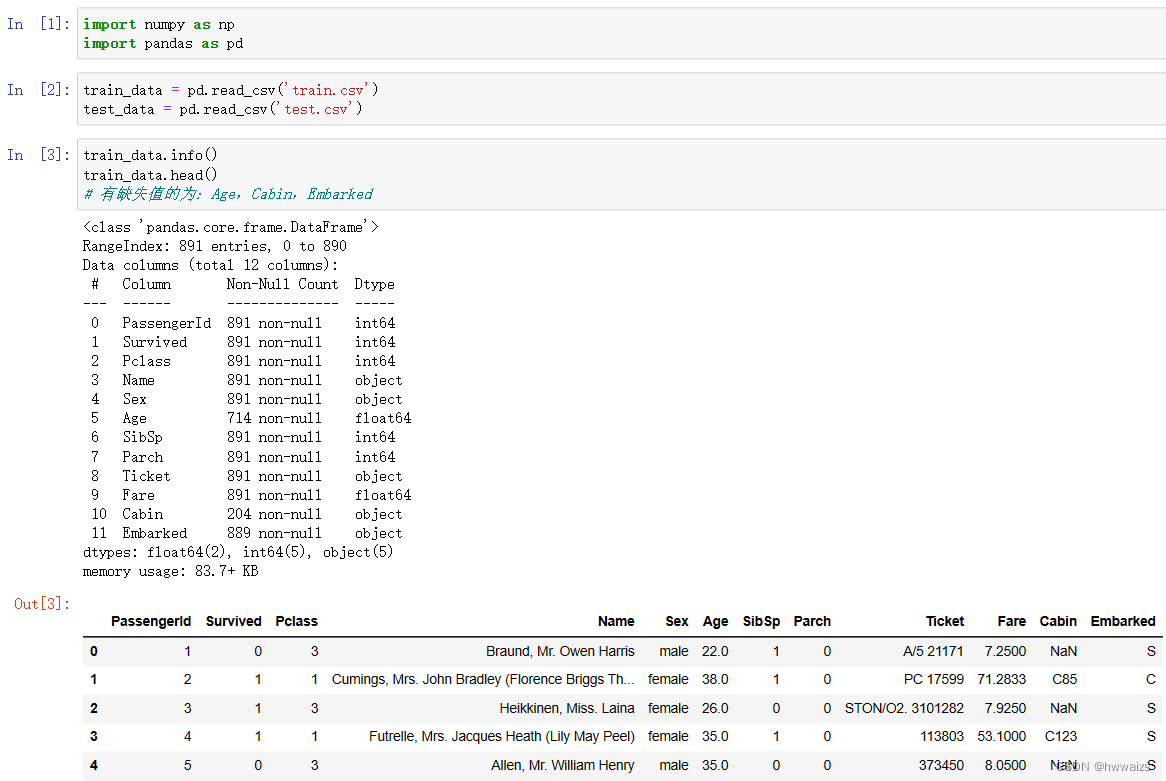


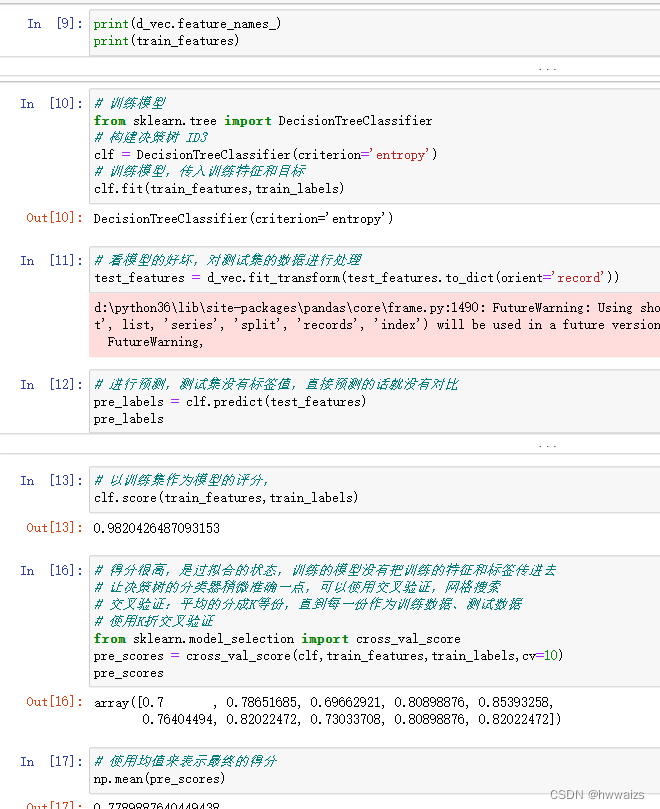
A través del análisis de los campos, tenga en cuenta que el tipo de número puro se puede reemplazar por el valor medio. Si el valor faltante del tipo de cadena es demasiado grande, se eliminará directamente. Si el valor faltante es relativamente pequeño, será llenado con una mayor proporción La selección de características debe ser lo más cercana posible Las etiquetas tienen características relacionadas, convierten el texto de las características en valores correspondientes y finalmente entrenan el modelo y luego realizan una validación cruzada de K-fold.
Visualización del árbol de decisiones
安装graphviz工具,下载地址:http://www.graphviz.org/download/
将graphviz添加到环境变量PATH中,然后通过pip install graphviz 安装graphviz库
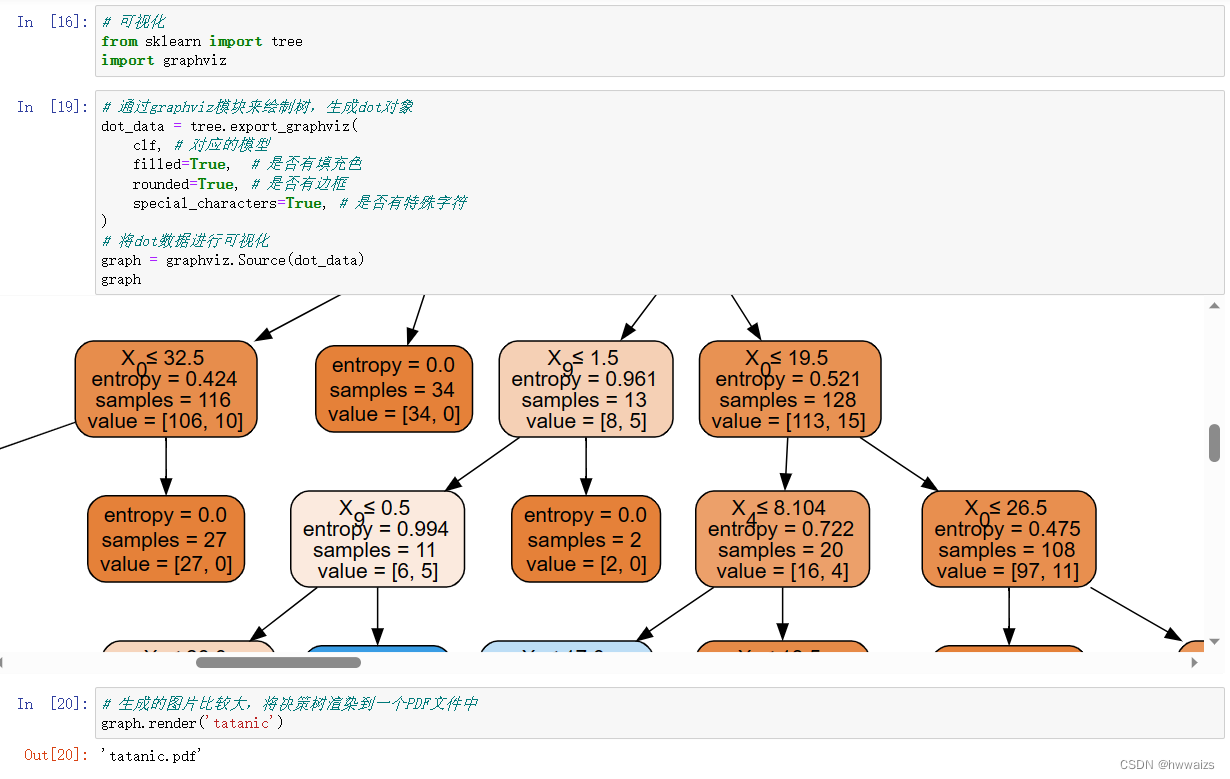
La imagen generada es relativamente grande y se puede guardar como archivo pdf. El efecto es el siguiente
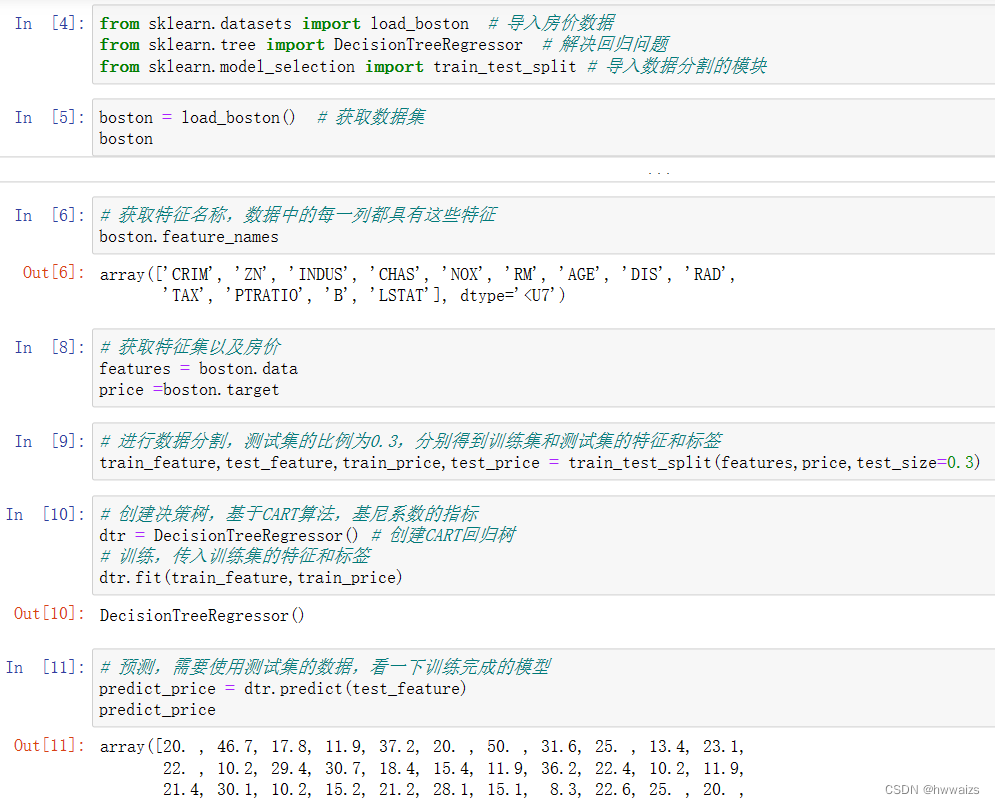
Árboles de decisión para problemas de regresión
El árbol de decisión se basa en los algoritmos ID3, C4.5 y CART, y el problema de regresión se implementa en base al algoritmo CART y el coeficiente de Gini.
Importe los datos de los precios de la vivienda de Boston y la interfaz del problema de regresión del árbol de decisión. Luego, llame a la interfaz de datos para obtener el conjunto de datos, luego obtenga el nombre de la característica, el conjunto de características, obtenga las características y las etiquetas del conjunto de entrenamiento y el conjunto de prueba y, a continuación, realice el entrenamiento y la predicción.