Notas de estudio JAX
1. Entorno de instalación
2. Aquí uso el entorno virtual de python3.7
conda create -n jax python=3.7
conda activate jax
2. Descargue e instale paquetes dependientes relacionados, como jax y jaxlib , y luego ingrese al entorno virtual para la instalación
cd C:\Users\dz\Downloads\jax-0.2.9_and_jaxlib-0.1.61-cp37-win_amd64
pip install jaxlib-0.1.61-cp37-none-win_amd64.whl
pip install jax==0.2.9
pip install matplotlib
3. Escriba un archivo py para probar si el entorno se instaló correctamente
import jax.numpy as jnp
import matplotlib.pyplot as plt
x_jnp=jnp.linspace(0,10,1000)
y_jnp=jnp.sin(x_jnp)*jnp.cos(x_jnp)
print(x_jnp,y_jnp)
plt.plot(x_jnp,y_jnp)
plt.show()
De la siguiente manera, la instalación del entorno es exitosa.
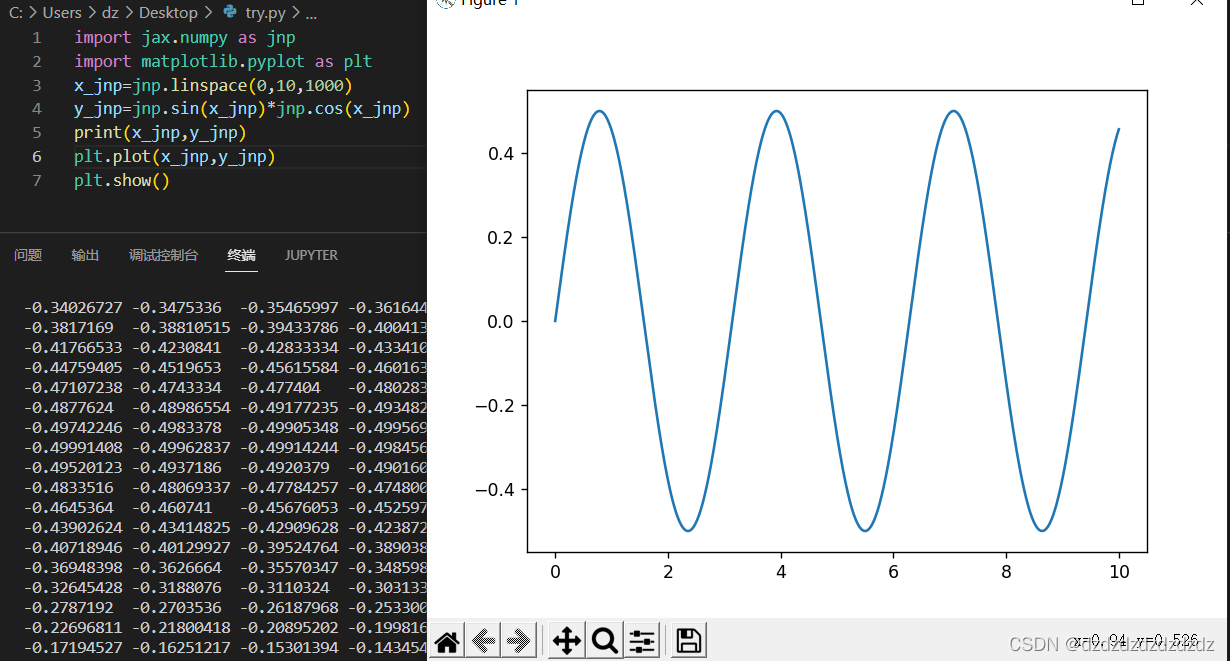
2. Conocimientos básicos
2.1.aleatorio
import jax.numpy as jnp
from jax import random
key=random.PRNGKey(0)#随机种子
x=random.normal(key,(10,),dtype=jnp.float32)#生成1维10个数的数组
print(x)
print(type(x))#<class 'jax.interpreters.xla._DeviceArray'>
Función 2.2.grad y propiedad DeviceArray
- JAX nos permite convertir funciones de Python, jax.grad encontrará el gradiente con respecto al primer argumento
import jax.numpy as jnp
from jax import random
import jax
def sum_of_squares(x):
return jnp.sum(x**2)
sum_of_squares_dx=jax.grad(sum_of_squares)#它接受一个用 Python 编写的数值函数,并返回一个新的 Python 函数,该函数计算原始函数的梯度。
x=jnp.asarray([1.0,2.0,3.0,4.0])
print(sum_of_squares(x))#求平方和》30.0
print(sum_of_squares_dx(x))##求平方和函数对每个自变量x的导数》[2. 4. 6. 8.]
2. Para encontrar el gradiente con respecto a diferentes parámetros (o múltiplos), puede establecer los argnums
import jax.numpy as jnp
import jax
def sum_squared_error(x,y):
return jnp.sum((x-y)**2)
sum_squared_error_dx_dy=jax.value_and_grad(sum_squared_error,argnums=(0,1))
x = jnp.asarray([2.0, 3.0, 4.0, 5.0])
y = jnp.asarray([1.0, 2.0, 3.0, 4.0])
#对x求导:2x-2y;对y求导:2y-2x
print(sum_squared_error_dx_dy(x,y))#[2., 2., 2., 2.];[-2., -2., -2., -2.]
3. Necesita encontrar el valor y el gradiente de la función con jax.value_and_grad
import jax.numpy as jnp
import jax
def sum_squared_error(x,y):
return jnp.sum((x-y)**2)
sum_squared_error_dx_dy=jax.value_and_grad(sum_squared_error)
x = jnp.asarray([2.0, 3.0, 4.0, 5.0])
y = jnp.asarray([1.0, 2.0, 3.0, 4.0])
#(DeviceArray(4., dtype=float32), DeviceArray([2., 2., 2., 2.], dtype=float32))
print(sum_squared_error_dx_dy(x,y))#jax.value_and_grad(f)(*xs) == (f(*xs), jax.grad(f)(*xs))
4. La función grad no es una función, sino un conjunto de tuplas (funciones intermedias), use has_aux=True
import jax.numpy as jnp
import jax
def sum_squared_error(x,y):
return jnp.sum((x-y)**2),x-y
"""jax.grad is only defined on scalar functions,
and our new function returns a tuple.
But we need to return a tuple to return our intermediate results!
This is where has_aux comes in"""
sum_squared_error_dx_dy=jax.grad(sum_squared_error,has_aux=True)
x = jnp.asarray([2.0, 3.0, 4.0, 5.0])
y = jnp.asarray([1.0, 2.0, 3.0, 4.0])
#(DeviceArray([2., 2., 2., 2.], dtype=float32), DeviceArray([1., 1., 1., 1.], dtype=float32))
print(sum_squared_error_dx_dy(x,y))
5. La modificación de DeviceArray debe basarse en el índice, y es una modificación suave
import jax.numpy as jnp
import numpy as np
#1.修改numpy数组
"""x=np.array([1,2,3])
def in_place_modify(x):
x[0]=4
return None
in_place_modify(x)
print(x)#[4 2 3]"""
#2.修改jnp数组:按索引进行就地修改,旧数组未受影响
y=jnp.array([1,2,3])
def jax_in_place_modify(x):
return x.at[0].set(4)
print(jax_in_place_modify(y))#[4 2 3]
print(y)#[1 2 3]
2.3.Vmap vectorización automática
3. Pequeños proyectos
3.1 Función XOR
Ingrese una matriz bidimensional, 3 neuronas en la primera capa, 1 neurona en la segunda capa y genere el resultado XOR (OR exclusivo) de la matriz bidimensional, de la siguiente manera

import random
import itertools
import jax
import jax.numpy as jnp
import numpy as np
learning_rate=1
inputs=jnp.array([[0,0],[0,1],[1,0],[1,1]])
def sigmoid(x):
return 1/(1+jnp.exp(-x))
def net(params,x):
w1,b1,w2,b2=params
hidden=jnp.tanh(jnp.dot(w1,x)+b1)
return sigmoid(jnp.dot(w2,hidden)+b2)#输出0,1分类
def loss(params,x,y):
out=net(params,x)
cross_entropy=-y*jnp.log(out)-(1-y)*jnp.log(1-out)
return cross_entropy
def test_all_inputs(inputs,params):
predictions=[int(net(params,inp)>0.5) for inp in inputs]
for inp,out in zip(inputs,predictions):
print(inp,'->',out)
return (predictions==[np.bitwise_xor(*inp) for inp in inputs])#网络输出结果进行异或运算
#1.jax.grad 接受一个函数并返回一个新函数,该函数计算原始函数的渐变。默认情况下,相对于第一个参数进行渐变;这可以通过 jgn.grad 的 argnums 参数来控制。
loss_grad=jax.grad(loss)
def initial_params():
return [np.random.randn(3,2),np.random.randn(3),np.random.randn(3),np.random.randn()]
params=initial_params()#初始化参数
for n in itertools.count():#迭代
x=inputs[np.random.choice(inputs.shape[0])]#四个数据中随机拿一个数据
y=np.bitwise_xor(*x)#两个值的异或运算
grads=loss_grad(params,x,y)
params=[param-learning_rate*grad for param,grad in zip(params,grads)]#参数更新
if not n%100:
print('Iteration {}'.format(n))#每100次训练测试1次
if test_all_inputs(inputs,params):#如果结果都正确了就结束循环
break
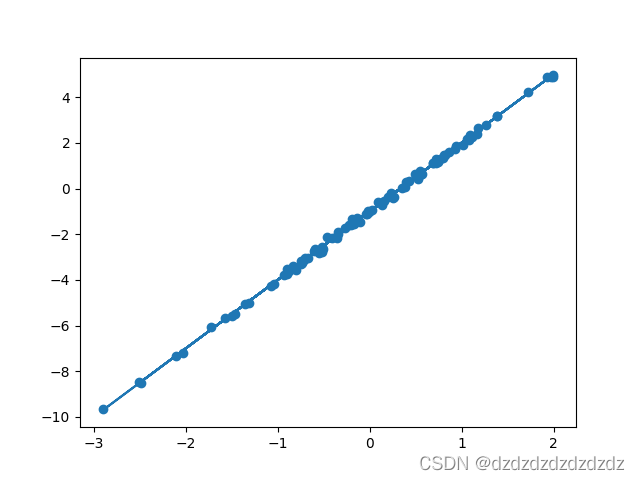
3.2 Regresión lineal
import numpy as np
import matplotlib.pyplot as plt
import jax.numpy as jnp
import jax
#1.数据
xs=np.random.normal(size=(100,))
noise=np.random.normal(scale=0.1,size=(100,))
ys=xs*3-1+noise
plt.scatter(xs,ys)
# plt.show()
#2.模型\hat y(x; \theta) = wx + b
def model (theta,x):
w,b=theta
return w*x+b
def loss_fn(theta,x,y):
prediction=model(theta,x)
return jnp.mean((prediction-y)**2)#误差方J(x, y; \theta) = (\hat y - y)^2
#3.参数更新
def update(theta,x,y,lr=0.1):#参数更新\theta_{new} = \theta - 0.1 (\nabla_\theta J) (x, y; \theta)
return theta -lr*jax.grad(loss_fn)(theta,x,y)
theta=jnp.array([1.,1.])
for _ in range(1000):
theta=update(theta,xs,ys)
plt.plot(xs,model(theta,xs))
plt.show()
w,b=theta
print(f"w:{
w:<.2f},b:{
b:<.2f}") #w:2.99,b:-1.00
3.3 Reconocimiento de escritura a mano MNIST
pip install tensorflow_datasets -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow
import tensorflow as tf
import tensorflow_datasets as tfds
import jax
import jax.numpy as jnp
from jax import jit,grad,random
from jax.experimental import optimizers,stax
num_classes= 10
input_shape=(-1,28*28)
step_size=0.001#学习率
batch_size=128
momentum_mass=0.9
rng=random.PRNGKey(0)
#1.数据
x_train=jnp.load(r"C:\Users\dz\Desktop\JAX\mnist_train_x.npy")
y_train=jnp.load(r"C:\Users\dz\Desktop\JAX\mnist_train_y.npy")
total_train_imgs=len(y_train)
def one_hot_nojit(x,k=10,dtype=jnp.float32):
return jnp.array(x[:,None]==jnp.arange(k),dtype)
y_train=one_hot_nojit(y_train)
ds_train=tf.data.Dataset.from_tensor_slices((x_train,y_train)).shuffle(1024).batch(256).prefetch(tf.data.experimental.AUTOTUNE)
ds_train=tfds.as_numpy(ds_train)
#2.网络
init_random_params,predict=stax.serial(stax.Dense(1024),stax.Relu,stax.Dense(1024),stax.Relu,stax.Dense(10),stax.LogSoftmax)
def pred_check(params,batch):
inputs,targets=batch
predict_result=predict(params,inputs)
predicted_class=jnp.argmax(predict_result,axis=1)
targets=jnp.argmax(targets,axis=1)
return jnp.sum(predicted_class==targets)
def loss(params,batch):
inputs,targets=batch
return jnp.mean(jnp.sum(-targets*predict(params,inputs),axis=1))
opt_init,opt_update,get_params=optimizers.adam(step_size=2e-4)
_,init_params=init_random_params(rng,input_shape)
opt_state=opt_init(init_params)
def update(i,opt_state,batch):
params=get_params(opt_state)
return opt_update(i,grad(loss)(params,batch),opt_state)
#3.训练
for _ in range(17):
itercount=0
for batch_raw in ds_train:
data=batch_raw[0].reshape((-1,28*28))
targets=batch_raw[1].reshape((-1,10))
opt_state=update((itercount),opt_state,(data,targets))
itercount+=1
params=get_params(opt_state)
train_acc=[]
correct_preds=0.0
for batch_raw in ds_train:
data=batch_raw[0].reshape((-1,28*28))
targets=batch_raw[1]
correct_preds+=pred_check(params,(data,targets))
train_acc.append(correct_preds/float(total_train_imgs))
print(f"training set accuracy:{
train_acc}")
3.4 Clasificación del iris
4 valores propios, 3 problemas de clasificación, utilizando 2 capas de perceptrones para la clasificación.
from cgitb import reset
from sklearn.datasets import load_iris
import jax.numpy as jnp
from jax import random,grad
import jax
#1.数据
data=load_iris()
iris_data=jnp.float32(data.data)#数据转化为float类型的list
iris_target=jnp.float32(data.target)
iris_data=jax.random.shuffle(random.PRNGKey(17),iris_data)#伪随机打乱数据
iris_target=jax.random.shuffle(random.PRNGKey(17),iris_target)
def one_hot_nojit(x,k=3,dtype=jnp.float32):
return jnp.array(x[:,None]==jnp.arange(k),dtype)
iris_target=one_hot_nojit(iris_target)
#2.网络结构
def Dense(dense_shape=[1,1]):
rng=random.PRNGKey(17)
weight=random.normal(rng,shape=dense_shape)
bias=random.normal(rng,shape=(dense_shape[-1],))
params=[weight,bias]#参数结构
def apply_fun(inputs,params=params):
w,b=params
return jnp.dot(inputs,w)+b#参数与输入数据点乘
return apply_fun
def selu(x,alpha=1.67,lmbda=1.05):
return lmbda*jnp.where(x>0,x,alpha*jnp.exp(x)-alpha)
def softmax(x,axis=-1):
unnormalized=jnp.exp(x)
return unnormalized/unnormalized.sum(axis,keepdims=True)
def cross_entropy(y_true,y_pred):
y_true==jnp.array(y_true)
y_pred=jnp.array(y_pred)
red=-jnp.sum(y_true*jnp.log(y_pred+1e-7),axis=-1)
return red
def mlp(x,params):
a0,b0,a1,b1=params
x=Dense()(x,[a0,b0])
x=jax.nn.selu(x)
x=Dense()(x,[a1,b1])
x=softmax(x,axis=-1)
return x
def loss_mlp(params,x,y):
preds=mlp(x,params)
loss_value=cross_entropy(y,preds)
return jnp.mean(loss_value)
rng=random.PRNGKey(17)
a0=random.normal(rng,shape=(4,5))
b0=random.normal(rng,shape=(5,))
a1=random.normal(rng,shape=(5,3))
b1=random.normal(rng,shape=(3,))
params=[a0,b0,a1,b1]
learning_rate=2.17e-4
#3.训练
for i in range(20000):
loss=loss_mlp(params,iris_data,iris_target)
if i%1000==0:
predict_result=mlp(iris_data,params)
predicted_class=jnp.argmax(predict_result,axis=1)
_iris_target=jnp.argmax(iris_target,axis=1)
accuracy=jnp.sum(predicted_class==_iris_target)/len(_iris_target)
print("i:",i,"loss:",loss,"accuracy:",accuracy)
params_grad=grad(loss_mlp)(params,iris_data,iris_target)
params=[(p-g*learning_rate) for p,g in zip(params,params_grad)]
predict_result=mlp(iris_data,params)
predicted_class=jnp.argmax(predict_result,axis=1)
iris_target=jnp.argmax(iris_target,axis=1)
accuracy=jnp.sum(predicted_class==iris_target)/len(iris_target)
print(accuracy)
4. Referencia
[1]https://zhuanlan.zhihu.com/p/56468260
[2]https://jax.readthedocs.io/en/latest/notebooks/quickstart.html
[3]https://github.com/google /jaxa