Algoritmo de agrupación 1.k-medoids
https://www.cnblogs.com/feffery/p/8595315.html todavía es relativamente fácil de entender. Revisé los medios antes y continuamente mueve el punto central de acuerdo con el centro de gravedad.
Puede debilitar la influencia de los valores atípicos, necesita atravesar cada punto, después de calcular el resultado de la clasificación por primera vez, atravesar los puntos que no sean el punto central predeterminado en cada clase, calcular la función de criterio entre todos los puntos de la clase Aquí, la función de criterio es la distancia promedio a todos los puntos. Después de calcularlo, se obtiene el nuevo punto central y luego se reclasifica de acuerdo con la distancia.
Usando el ejemplo de kmeans que acabo de ver, el proceso de cálculo también se entiende bien, suponiendo que p1 y p2 se seleccionen al principio, entonces el punto central puede convertirse en p1 y p4 después de una ronda.
2. ¿Cómo se implementa específicamente GMVAE?
¿Cómo se refleja el gaussiano multivariante en el código?
![]()
Defina el modelo y proporcione los parámetros de cada dimensión, cuántos puntos centrales hay, es decir, cuántas clases.

Defina los parámetros de la distribución ZINB, donde la suma del abandono de tipo k es 1? Entonces, ¿hay una distribución ZINB separada para cada categoría?

Inicialice los parámetros GMM en el modelo, ¿cuáles se usan en sklearn? Confundido:
desde sklearn.mixture import GaussianMixture
https://scikit-learn.org/stable/modules/generated/sklearn.mixture.GaussianMixture.html Esto se ha buscado mucho, de todos modos, la explicación no es detallada,
Función de ajuste: utilice el algoritmo EM para estimar los parámetros del modelo. https://www.cnblogs.com/dahu-daqing/p/9456137.html Esto es bastante bueno. Habla sobre su proceso de cálculo, que es muy bueno.

Iteración del algoritmo EM, primero calcule la puntuación de cada muestra? El puntaje no está claro, predecir es calcular la probabilidad de que cada muestra pertenezca a cada modelo subgaussiano:

Por ejemplo, los cuatro modelos subgaussianos anteriores, luego 233,
En resumen, después del ajuste, puede obtener la probabilidad de a qué distribución subgaussiana pertenece cada muestra.
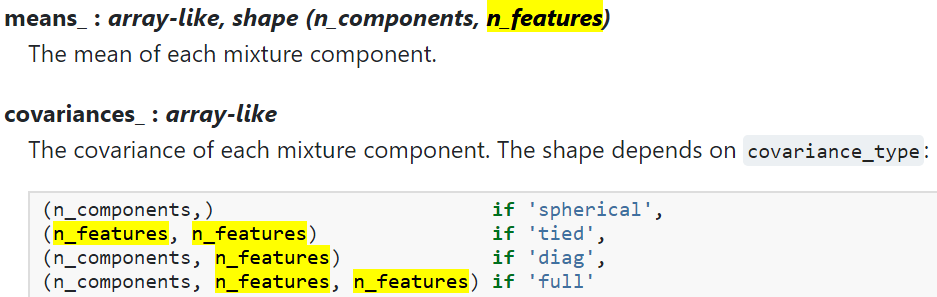
Las n_características aquí deben referirse a la dimensión de z, por ejemplo, z tiene 10 dimensiones y se divide en 3 categorías, luego la media_ devuelta, el tamaño es [3,10], y cada dimensión en cada categoría tiene una media y una varianza Si la varianza es diag, entonces el tamaño es el mismo. Entonces ahora esta función está equipada.
Entonces llame a la función model.fit para calcular directamente la pérdida? De hecho, no entiendo para qué sirve esta función de ajuste. ¿Por qué no reenviar? emm debería ser porque si reenvías directamente, todavía tienes que escribir un bucle for para entrenamiento.
![]()
La función de pérdida se calculará directamente, y la pérdida saldrá,

¿Veamos cómo se crea el codificador?

Se puede encontrar que la definición del codificador también es muy simple, pero creo que el primer parámetro de build_mlp es un poco problemático. Lo probé. ¿Cómo puede h_dim ser un número y [] se agregan directamente?
def fun (lay): para l in lay: print (l) dim = [1,2 ] [x, y] = dim fun ([x] + y) # 输出 : fun ([x] + y) TypeError: solo puede concatenar la lista ( no " int " ) a la lista
De todos modos, generalmente sé lo que significa el código.
La siguiente es la clase GaussianSample: se puede encontrar que el número de entidades es el número de capas ocultas, y luego se construye una capa de salida lineal tanto para μ como para varianza. Al reenviar, el re-muestreo se realiza por separado.
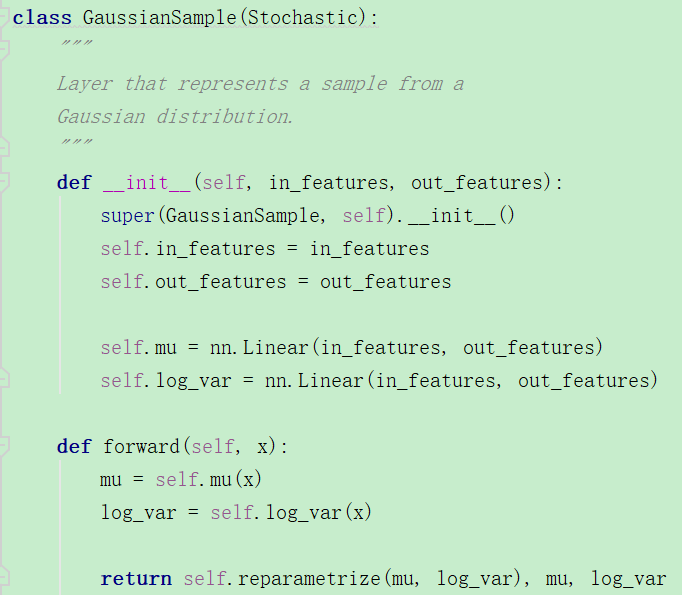
Esto no es diferente del vae ordinario.