prefacio
Como parte del ajuste fino del modelo de lenguaje, necesitamos recopilar una gran cantidad de datos de texto en Internet. Cierta red está llena de una gran cantidad de preguntas y respuestas públicas de alta calidad, que son adecuadas para la capacitación. Bueno, hoy vamos a descargar su lista principal de preguntas y respuestas de dos años.
tren de pensamiento
Primero, hagamos clic en la respuesta a una pregunta, hagamos clic en compartir y copiemos el enlace.
Se encuentra que la estructura del enlace es la siguiente:
https://www.zhihu.com/question/431730729/answer/1591942026
Un enlace construido a partir de una ID de pregunta y una ID de respuesta conduce a las siguientes preguntas:
1. La ID de la pregunta es la identificación de la pregunta, cómo ¿Qué pasa con todas las identificaciones de preguntas que han estado en la lista caliente durante los últimos dos años?
2. El ID de respuesta es el ID de la respuesta. Esto parece compartir una respuesta para todas las preguntas. No hay forma de obtener el ID de respuesta de la pregunta actual a través de un bucle.
3. ¿Cómo obtener el texto en el enlace después de tener estas identificaciones?
Preparar
1. Puede encontrar la lista de búsqueda activa para el rastreo regular en github:
https://github.com/justjavac/zhihu-trending-hot-questions
a partir del 2020-11-24, descárguelo y descomprímalo, y guárdelo en el archivo carpeta Puede encontrar todos los documentos md buscados en caliente.
2. Instale las bibliotecas necesarias
pip install beautifulsoup4
pip install lxml
3. Código de planificación
De acuerdo con el problema, se puede dividir en tres partes:
la primera parte extrae todos los enlaces de URL de la lista activa del documento md.
La segunda parte obtiene el siguiente enlace de respuesta según el enlace url de la lista activa.
La tercera parte obtiene el contenido de la página basándose en enlaces únicos construidos a partir de preguntas y respuestas.
el código
Tenga en cuenta que el código se almacena en el directorio de archivo de forma predeterminada para leer los nombres de archivo de todos los documentos md.
from bs4 import BeautifulSoup
import json
import numpy as np
import requests
import os
import re
import time
#第一部分
headers = {
'content-type': 'text/html; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/111.0.0.0 Safari/537.36'}
arr = os.listdir()
print(arr)
list_total_question = []
for x in arr:
if x.endswith('.md'):
with open(x,'r',encoding='utf8') as hot_diary:
pattern = r'https://www.zhihu.com/question/(\d+)'
list_total_question+=re.findall(pattern, hot_diary.read())
print(len(list_total_question))
#第二部分
list_all_url = []
for x in list_total_question:
a1 = time.time()
url = 'https://www.zhihu.com/api/v4/questions/'+str(x)+'/feeds?'
datas = requests.get(url,headers=headers).json()
for info in datas['data']:
answerid = info['target']['id']
final_url = 'https://www.zhihu.com/question/'+x+'/answer/'+str(answerid)
list_all_url.append(final_url)
#break #每条问题默认提取五条问答,此处Break则只选默认排序第一条
a2 = time.time()
print(a2-a1) #0.5s
break #选一条问题进行测试
print(list_all_url)
#第三部分
list_json = []
for x in list_all_url:
html = requests.get(url=x, headers=headers)
site = BeautifulSoup(html.text, 'lxml')
title = site.find_all('meta', attrs={
'itemprop': "name"}, recursive=True, limit=1)[0].__getattribute__('attrs')[
'content']
text = site.find('div', attrs={
'class': "RichContent-inner"})
print(title)
total_string = ""
for i in text:
if i.text.find('.css') == -1:
total_string += i.text
dict_json = {
"instruction":title,"input":"","output":total_string}
list_json.append(dict_json)
print(list_json)
Se tarda unos 91 000 segundos en rastrear las 168 500 listas calientes y la extracción de información aún no se ha probado. Si solo desea ver el efecto, puede agregar un solo elemento de prueba de interrupción. De forma predeterminada, el código extrae cinco respuestas a la primera pregunta. El código para guardar archivos no está escrito aquí, es muy simple.
Efecto
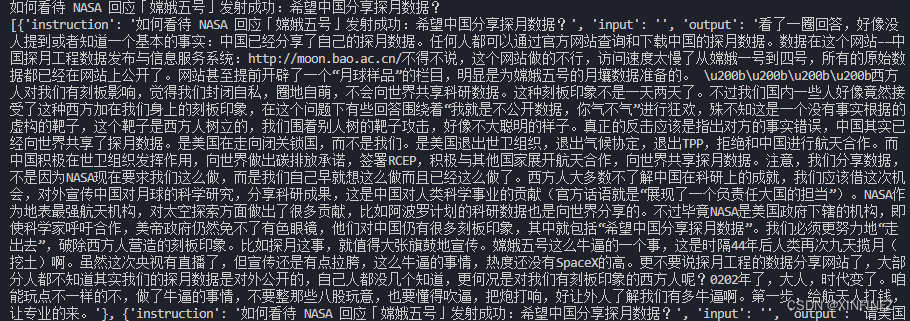
El propósito de construirlo en forma de json aquí es usar la biblioteca para ajustar el modelo de lenguaje grande y eliminarlo si no lo necesita.