Raspado de imágenes
Visión general
El fondo del escritorio de la película se cansará después de mucho tiempo. Si cambia el fondo, generalmente tendrá que descargarlo en línea y recogerlo. Pasar página por página es muy molesto. ¿Puede mostrar muchas imágenes a la vez? Mira cada página de la provincia. La forma más sencilla es guardar las imágenes localmente y luego verlas todas a la vez. Esta parte es para escribir un rastreador sin ninguna estructura complicada para rastrear las imágenes en Internet hasta el local. (De hecho, no sé qué escribir, así que simplemente pongo las cosas que escribí para jugar y describo todo el proceso en palabras). El código y algunos fondos de pantalla se pueden obtener respondiendo al "fondo de pantalla" en la cuenta oficial. No es fácil de crear, haga clic en "Mirándolo" "cantar.
Análisis de tareas
El requisito es obtener algunos fondos de pantalla de computadora atractivos de Internet y adoptar una estrategia de implementación de rastreadores.
1. Encuentre el sitio web de imágenes que necesita ser rastreado, aquí tomo Biantu.com como ejemplo
2. Elija el método de rastreo apropiado Dado que esta tarea es demasiado simple, simplemente escriba un rastreador.
Diseño de orugas
Decir que es diseño, de hecho, hablar de la composición básica de un rastreador. Los rastreadores generalmente se dividen en varios pasos (aquí, los pasos se dividen al mínimo).
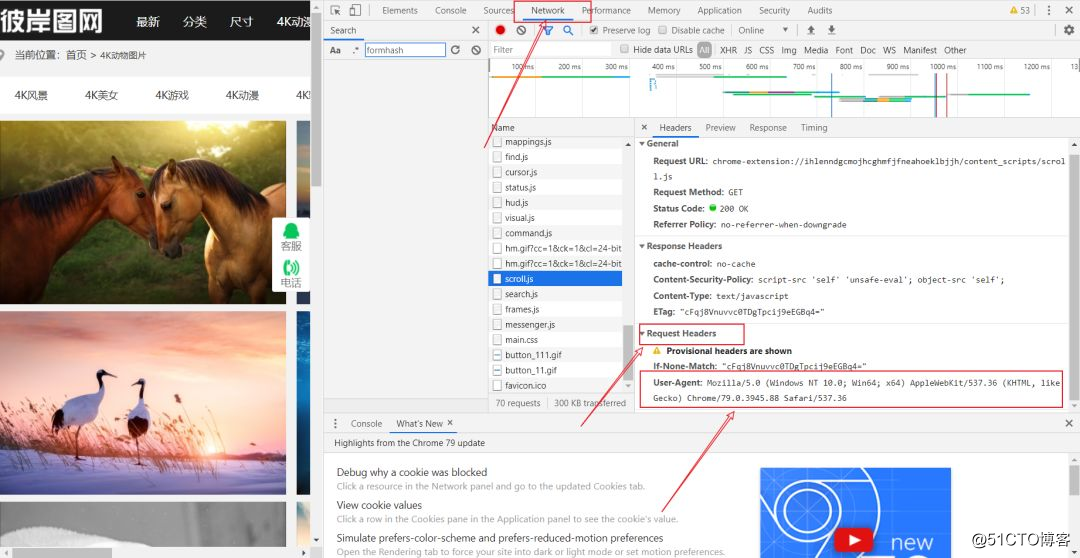
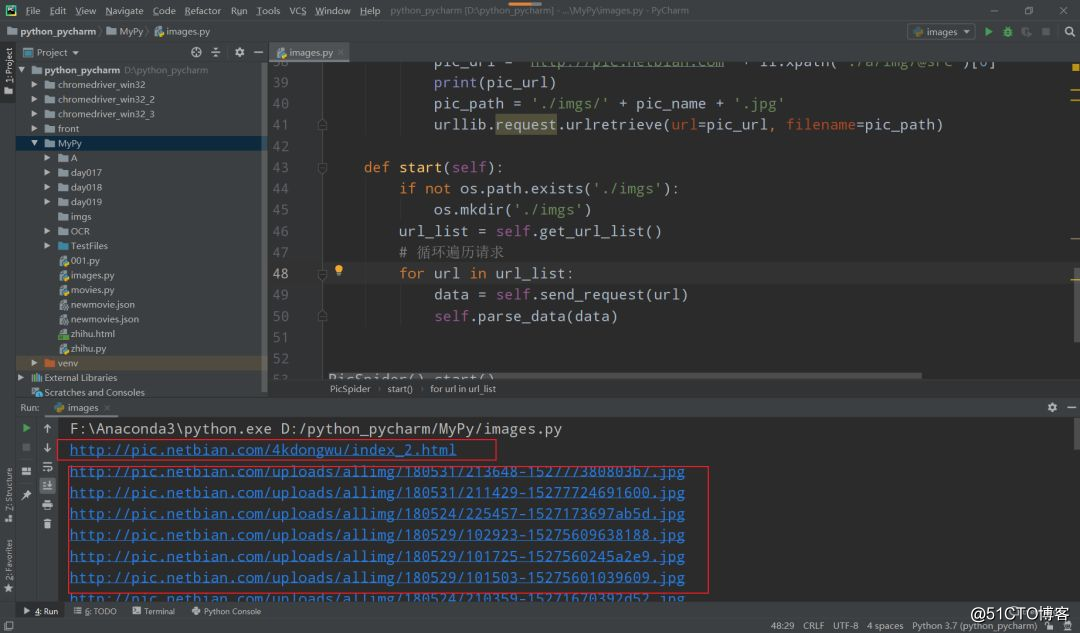
1. Asegúrese de tomar la URL del objetivo (el núcleo es encontrar), esta parte se puede observar en general, preste atención a la redirección de la página de inicio.
2. Use el código Python para enviar una solicitud para obtener datos (java go)
3. Analice los datos precisos adquiridos, busque un nuevo destino (nueva URL) y vuelva al primer paso (automatización)
4. Persistencia de datos (guardar en local)
Implementación del rastreador
En la implementación, puse directamente el análisis de datos y el almacenamiento de datos juntos, también se puede dividir en dos métodos.
Para las personas que son nuevas en los rastreadores, la dificultad radica en cómo encontrar lo que necesitan a partir de un montón de código.
El análisis de datos generalmente se divide en tres categorías: expresiones regulares, xpath, bs4. Se recomiendan las dos últimas. Por supuesto, si eres un tipo grande, también puedes usar la primera. Yo personalmente prefiero usar xpath, por lo que lo siguiente también se implementa usando xpath. Este proyecto fue hecho por mí en ese momento como un proyecto introductorio, que es muy adecuado para que los principiantes comiencen .
import urllib
import os
import requests
from bs4 import BeautifulSoup
from lxml import etree
import json
class PicSpider(object):
def __init__(self):
self.base_url = "http://pic.netbian.com/4kdongwu/index_{}.html"
self.headers = {
# 浏览器版本
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) "
"Chrome/14.0.835.163 Safari/535.1",
}
# 1.构建所有url
def get_url_list(self):
url_list = []
for i in range(2, 4):
url = self.base_url.format(i)
url_list.append(url)
return url_list
# 2.发送请求
def send_request(self, url):
print(url)
data = requests.get(url, headers=self.headers).content.decode('gbk')
return data
# 3.解析存储数据
def parse_data(self, data):
tree = etree.HTML(data)
li_list = tree.xpath("//div[@class='slist']//li")
for li in li_list:
pic_name = li.xpath('./a/b/text()')[0]
pic_url = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0]
print(pic_url)
pic_path = './imgs/' + pic_name + '.jpg'
urllib.request.urlretrieve(url=pic_url, filename=pic_path)
def start(self):
if not os.path.exists('./imgs'):
os.mkdir('./imgs')
url_list = self.get_url_list()
# 循环遍历请求
for url in url_list:
data = self.send_request(url)
self.parse_data(data)
PicSpider().start()Al inicializar, hay un parámetro llamado User-Agent, que se llama encabezado de solicitud. Algunos sitios web (casi ninguno) no necesitan el encabezado de solicitud, por lo que este parámetro puede llamarse parámetro obligatorio y el punto de acceso está en su navegador red.
Dado que la URL de este sitio web cambia en index_ {}, base_url se define como:
self.base_url = "http://pic.netbian.com/4kdongwu/index_{}.html"
En el paso 1, el bucle for se utiliza para construir una lista de URL que se visitarán, rango (página de inicio, página final).
Utilice solicitudes de módulos de terceros al realizar la solicitud. De hecho, debe usar la solicitud urllib que viene con Python. Después de todo, esto es nativo.
El análisis de datos es utilizar el análisis xpath.
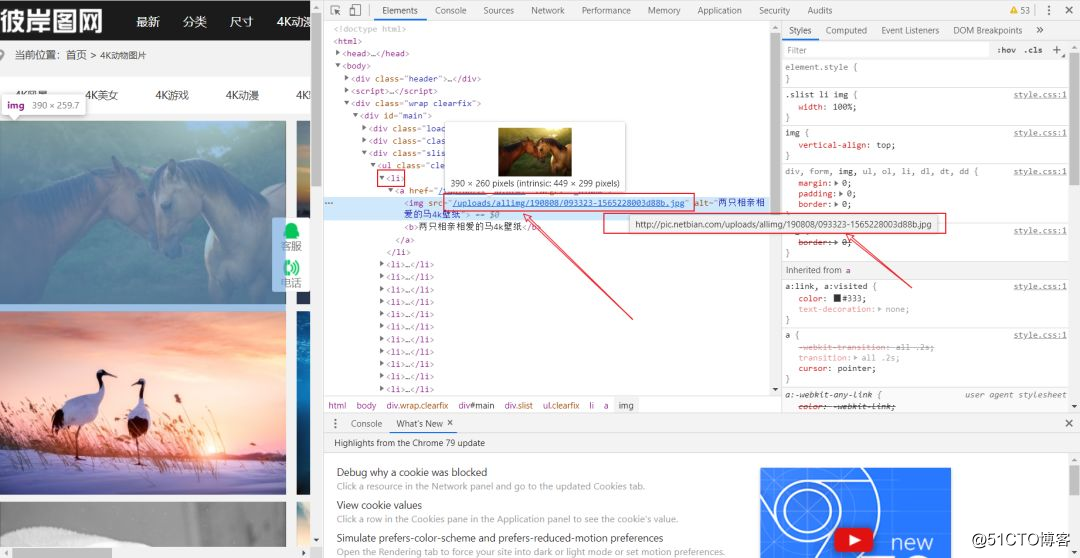
Dado que lo que se obtiene bajo src es parte de la url, hay más empalmes secundarios de la url, que es el código en la línea 38
pic_url = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0]
El siguiente paso es crear una carpeta para almacenarlo.
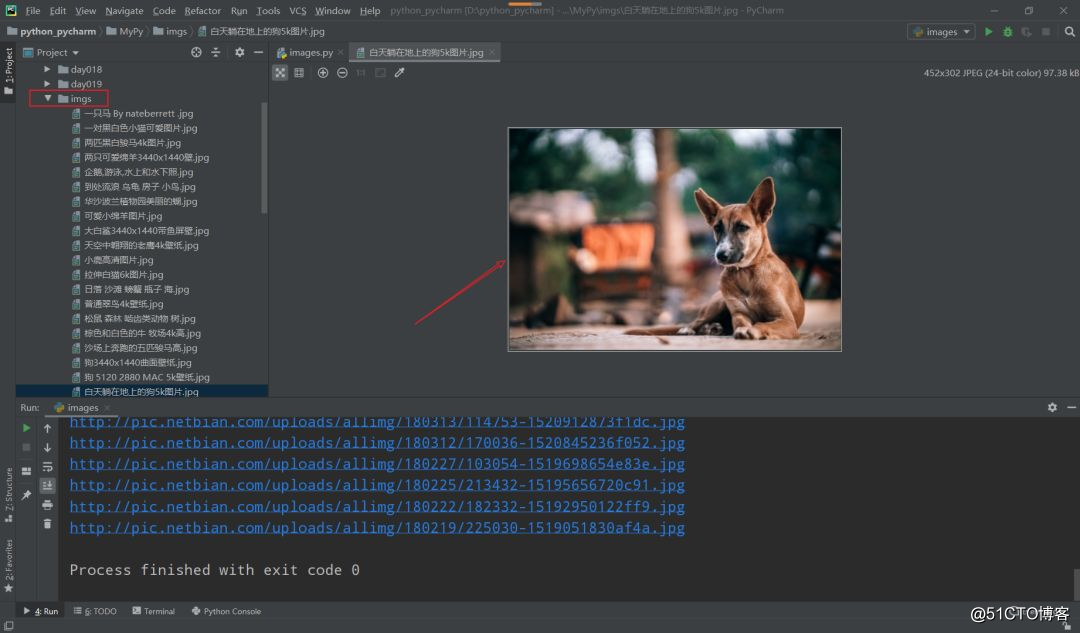
Visualización de resultados
Para mostrar el progreso de la adquisición durante el proceso de ejecución, se puede imprimir la URL.
El resultado se almacena en la carpeta imgs en el mismo directorio de nivel.