Procesamiento por lotes de Python de tablas de Excel
Preámbulo
El jefe se ha vuelto cada vez más extremo últimamente. Estaba a punto de salir del trabajo y me envió cientos de formularios para que combinara el contenido en un solo formulario.

Afortunadamente, conozco Python y puedo hacerlo en minutos. Si lo cambio a alguien que no sabe Python, no podré trabajar horas extras hasta el amanecer del día siguiente~

Una habilidad tan útil debe ser compartida con todos. Sin más preámbulos, ¡comencemos!
Listo para trabajar
Necesitamos preparar los datos de la tabla primero. Los hermanos que pueden gatear pueden gatear un poco solos. Si no, puedes encontrarme para obtener los datos directamente.
Colóquelo en el lado izquierdo de la computadora y colóquelo en la parte inferior del teléfono móvil
Aquí solo muestro los datos en la tabla
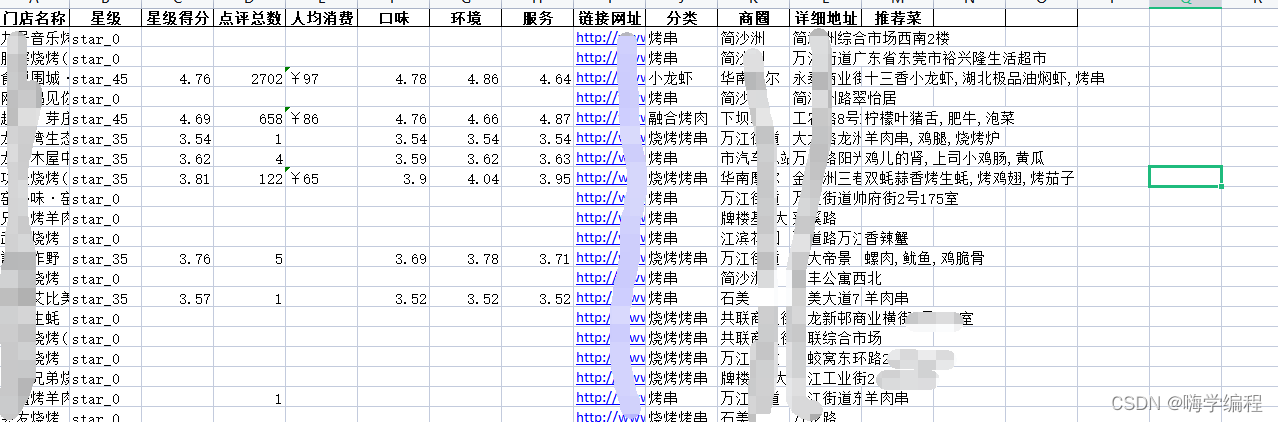 , por lo que solo se usan cinco tablas. Hoy, fusionamos el nivel municipal con el nivel provincial.
, por lo que solo se usan cinco tablas. Hoy, fusionamos el nivel municipal con el nivel provincial.

La idea de este artículo.
- Resumir todo Excel en la carpeta actual a la provincia de Guangdong.xlsx
- Agregue un nuevo campo ciudad, el contenido del campo es la ciudad donde se encuentra la tienda, y este campo se coloca al frente;
- No se requieren todos los datos con una calificación de estrellas de star_0
- Siempre que tres campos de un dato sean campos vacíos, no se necesita el dato completo;
- Eliminar el símbolo $ del precio
Código
Todo el código se comparte con todos, no nos gusta ocultarlo.
import glob
import openpyxl
workbook = openpyxl.Workbook()
sheet_total = workbook.active
sheet_total.append(['城市', '门店名称', '星级', '星级得分', '点评总数', '人均消费', '口味', '环境', '服务', '链接网址', '分类', '商圈', '详细地址', '推荐菜'])
def count_none(line):
"""返回空内容的数据"""
count = 0
for d in line:
if not d:
count += 1
return count
filenames = glob.glob('*/*.xlsx')
for filename in filenames:
# print(filename)
city = filename.split('.')[0].split('\\')[-1]
workbook_temp = openpyxl.load_workbook(filename)
sheet = workbook_temp.active
for row in sheet.iter_rows(min_row=2, min_col=1, max_col=sheet.max_column, max_row=sheet.max_row):
row_data = [col.value for col in row]
if row_data[1] == 'star_0':
continue
# 定义一个方法判断空字段的数量
if count_none(row_data) >= 3:
continue
# 去掉平均价格中的 ¥
if row_data[4]:
row_data[4] = row_data[4].strip('¥')
row_data.insert(0, city)
# print(row_data)
sheet_total.append(row_data)
# break # 调试只处理一个
workbook.save('广东省.xlsx')
Efecto
Recién salido del horno, muy fresco.
 He filtrado, de lo contrario, todo se mostrará en un solo lugar.
He filtrado, de lo contrario, todo se mostrará en un solo lugar.
Como puede ver, los datos se han fusionado con éxito en una tabla.

Si te gusta, recuerda darle me gusta y recolectarlo ~
Sígueme para compartir más productos secos técnicos
. Tomar el código directamente es equivalente a prostituirse por nada. Me gusta y recolectar es la verdad ...
Su apoyo es la fuerza motriz de mi ¡actualizar!