introducir
Introducción a la tarea
El aprendizaje autosupervisado (Self-supervised learning, SSL) es un paradigma de aprendizaje potencial, cuyo objetivo es utilizar datos masivos sin etiquetar para el aprendizaje de representación. En SSL, entrenamos el modelo mediante la construcción de una tarea de preentrenamiento razonable (que puede generar etiquetas automáticamente, es decir, la autosupervisión) y aprendemos un modelo de preentrenamiento con potentes capacidades de modelado. En base al modelo de entrenamiento obtenido por aprendizaje autosupervisado, podemos mejorar el desempeño de diversas tareas de visión descendente (clasificación de imágenes, detección de objetos, segmentación semántica, etc.).
MMSelfSup
MMSelfSup es una caja de herramientas de aprendizaje de representación autosupervisada de código abierto basada en PyTorch.
El marco es el siguiente:
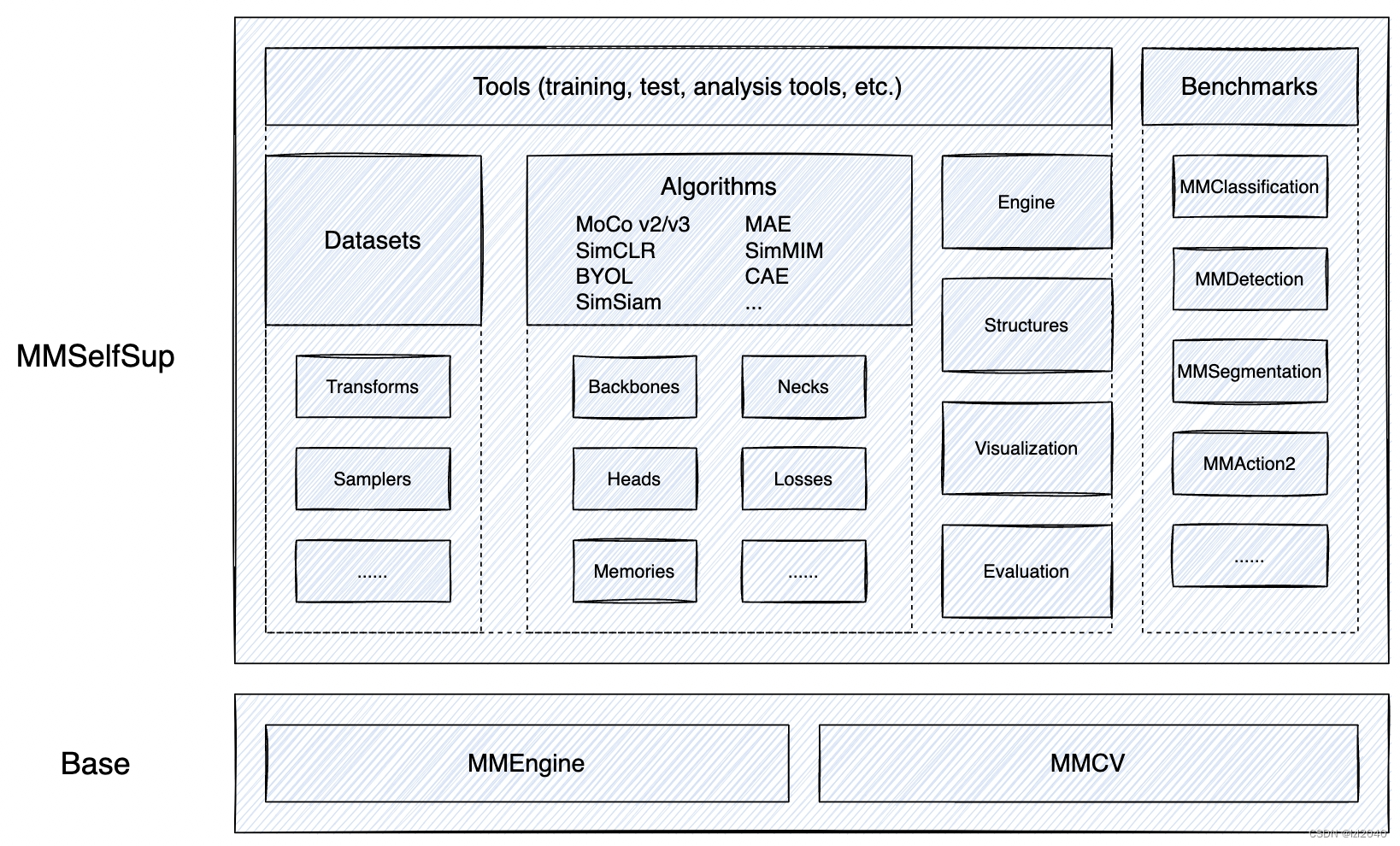
Sus características son:
- Integración multimétodo
MMSelfSup proporciona una variedad de algoritmos de aprendizaje autosupervisados de vanguardia, y la mayoría de las configuraciones de aprendizaje previo al entrenamiento autosupervisado son las mismas para obtener una comparación más justa en el punto de referencia. - Diseño modular
MMSelfSup cumple con la filosofía de diseño consistente del proyecto OpenMMLab y lleva a cabo un diseño modular, que es conveniente para que los usuarios personalicen e implementen sus propios algoritmos. - Evaluación de rendimiento estandarizada
MMSelfSup tiene puntos de referencia ricos para evaluación y prueba, incluida la evaluación lineal, SVM / SVM de tiro bajo de características lineales, clasificación semisupervisada, detección de objetos y segmentación semántica. - Compatibilidad
Compatible con las principales bibliotecas de algoritmos de OpenMMLab, con una gran cantidad de tareas de evaluación posteriores y aplicaciones de modelos previamente entrenados.
paso
Primero asegúrese de que pytorch esté instalado.
1. Instalar la biblioteca mmcv
pip install openmim
mim install mmcv
### 2. Descarga el proyecto mmselfsup
git clone https://github.com/open-mmlab/mmselfsup.git
Puede usar git, o puede descargar el paquete comprimido en github y descomprimirlo
3. Ingrese a la carpeta principal del proyecto e instale los paquetes de terceros requeridos
cd mmselfsup-main
pip install -e .
4. Busque el archivo de configuración del modelo seleccionado, la ruta del archivo está en: configs/selfsup
Los archivos en configs/selfsup se muestran en la siguiente figura: el nombre
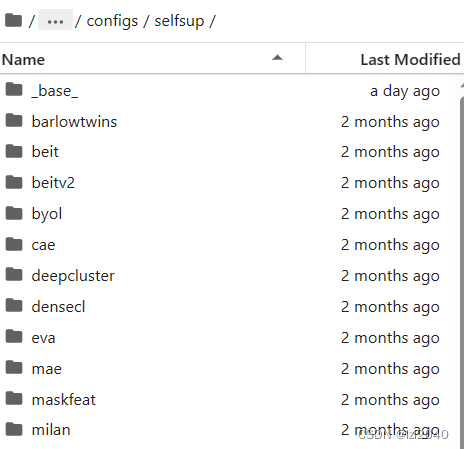
de la carpeta es el nombre del modelo y beit representa el modelo BEIT.
Aquí elijo simsiam.
5. Ingrese a esta carpeta, hay algunos archivos de configuración debajo de esta carpeta para el proceso de capacitación posterior
La situación en esta carpeta es la siguiente:
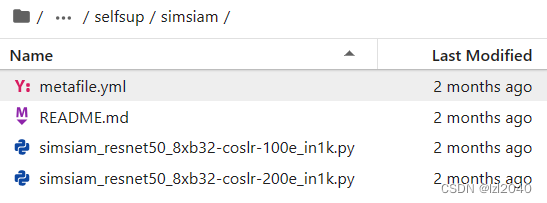
las reglas de nomenclatura de los archivos de configuración son:
{模型信息}_{模块信息}_{训练信息}_{数据集信息}
simsiam_resnet50_8xb32-coslr-100e_in1k.py indica que el nombre del modelo es simsiam, los módulos utilizados incluyen resnet50, el entrenamiento es de 8 tarjetas, el tamaño del lote es 32, se usa la función de cambio de tasa de aprendizaje del tipo cos y el conjunto de datos es imagenet1k.
El interior del archivo de configuración es:
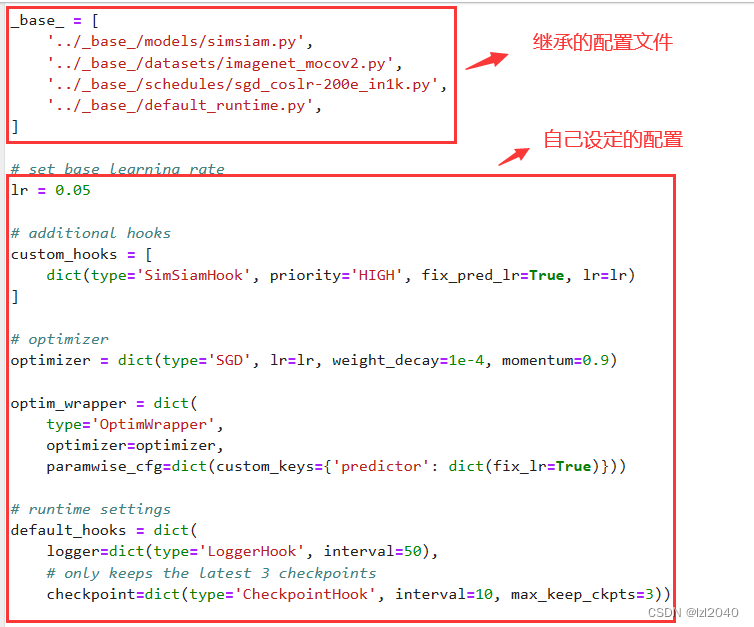
la dirección del archivo de configuración heredado es: configs/selfsup/ base , como se muestra a continuación:
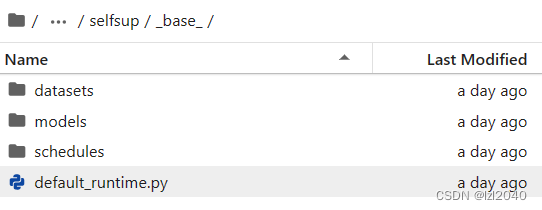
6. Ver el archivo de configuración heredado del conjunto de datos
Introducción al documento
Debido a que la ruta del conjunto de datos que usamos es diferente de la ruta establecida en el archivo de configuración heredado, debe modificarse.
Para hacer esto, primero debe ver qué hay en el archivo de configuración heredado.
Primero, debe modificar el directorio raíz del conjunto de datos:
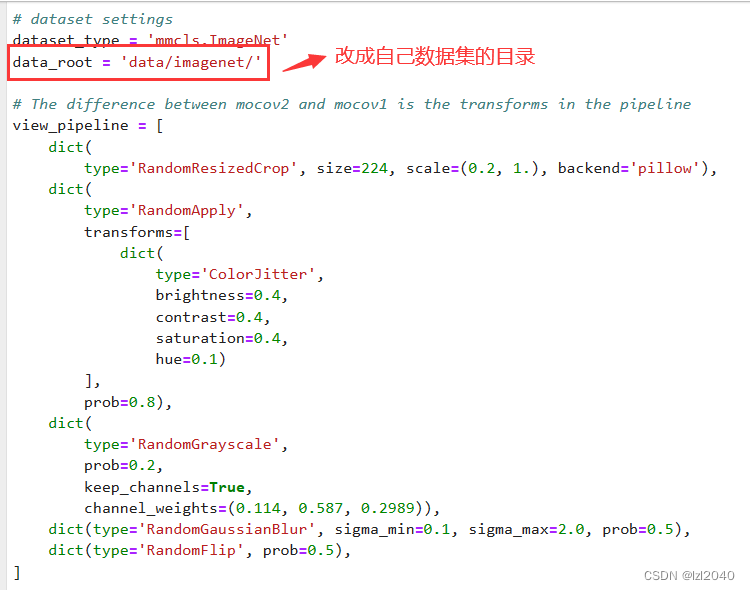
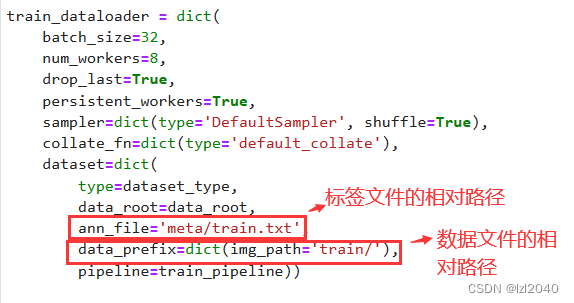
luego cambie la ruta relativa del archivo de etiquetas y el archivo de datos por la suya.
Construcción de archivos de etiquetas.
Cabe señalar que, a excepción del tipo VOC, la estructura general de carpetas del conjunto de datos es:
data
│ ├── datasetname
│ │ ├── meta
│ │ ├── train
│ │ ├── val
Entre ellos, hay archivos de etiquetas en la metacarpeta y archivos de datos , como imágenes, se almacenan en las carpetas train y val . (train y val también se pueden colocar en una carpeta)
Para el entrenamiento supervisado, la composición básica del archivo de etiquetas es:
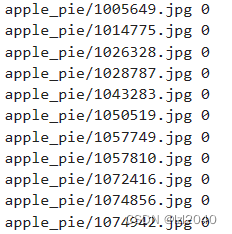
el lado izquierdo es la ruta relativa del archivo de datos y el lado derecho es la etiqueta correspondiente.
La construcción del archivo de etiqueta mmselfsup nos proporciona una muestra, la ruta del archivo es: tools/dataset_converters/convert_imagenet_subsets.py , simplemente modifíquelo de acuerdo con sus ideas.
7. Cree su propio archivo de configuración
Cree un nuevo archivo en la carpeta donde se encuentra el archivo de configuración. El método de nomenclatura es el mismo que el mencionado anteriormente, lo cual es fácil de entender.
Luego haga las modificaciones correspondientes de acuerdo con su situación real. Tenga en cuenta que los nombres de las variables definidas no se definen casualmente al modificar, y deben ser consistentes con los nombres en los archivos heredados . El proceso general se describe a continuación.
Primero elige que archivo heredar, aquí elijo: simsiam_resnet50_8xb32-coslr-200e_in1k.py
_base_ = 'simsiam_resnet50_8xb32-coslr-200e_in1k.py'
Tenga en cuenta que se usa _base_, y el de la derecha es equivalente a la ruta donde se encuentra el archivo de configuración.
Luego cambie la tasa de aprendizaje, ya que no usa la misma configuración que el archivo de configuración heredado, por lo que debe modificarse. El archivo de configuración heredado usa 8*32 y yo estoy usando 1*32, por lo que la tasa de aprendizaje se divide por 8.
lr = 0.05 / 8
optimizer = dict(lr=lr)
Luego modifique la configuración relevante del conjunto de datos, como: raíz_datos
data_root = '/root/dataset/food-101/'
train_dataloader = dict(
dataset=dict(
ann_file='meta/food101_train.txt',
data_prefix=dict(img_path='images/')
)
)
Finalmente, modifique la cantidad de tiempos de entrenamiento, cuántas veces se guarda el modelo y el intervalo entre la impresión de registros.
default_hooks = dict(
logger=dict(interval=10),
checkpoint=dict(interval=20, max_keep_ckpts=5)
)
train_cfg = dict(max_epochs=200)
8. Llevar a cabo la capacitación
El código de entrenamiento está en tools/train.py, también puedes usar el archivo dist_train.sh. Entre ellos, train.py es adecuado para una sola tarjeta y dist_train.sh puede realizar un entrenamiento distribuido.
El código para entrenar usando dist_train.sh es el siguiente:
bash dist_train.sh ${
CONFIG} ${
GPUS} --cfg-options model.pretrained=${
PRETRAIN}
El código para entrenar usando train.py es el siguiente:
python train.py ${
CONFIG_FILE} [optional arguments]
Tales como: python train.py /root/Project/mmselfsup-main/configs/selfsup/simsiam/simsiam_resnet50_1xb32-coslr-200e_food101.py
Si desea ejecutarlo en segundo plano, cámbielo a: nohup python train.py /root/Project/mmselfsup-main/configs/selfsup/simsiam/simsiam_resnet50_1xb32-coslr-200e_food101.py &
epílogo
La serie openmm es un marco de código abierto muy bueno para el aprendizaje profundo, que integra muchos algoritmos excelentes, de los que vale la pena aprender y puede ahorrar mucho tiempo para escribir código usted mismo.