Directorio de artículos
- Prefacio
- 1. Descripción general de los principios de los algoritmos de reconocimiento de objetos.
- 2. Opencv llama al modelo de reconocimiento de objetos de la darknet (yolov3/yolov4)
-
- 1. Obtención del modelo darknet
- 2. Python llama al modelo darknet para realizar el reconocimiento de objetos.
- 3. LabVIEW llama al modelo darknet para realizar el reconocimiento de objetos yolo_example.vi
- 4. LabVIEW implementa el reconocimiento de objetos de cámara en tiempo real (yolo_example_camera.vi)
- 3. Llamada al modelo de reconocimiento de objetos de Tensorflow
- 4. Descarga del código fuente del proyecto y del modelo.
- Resumen y ampliación
Prefacio
Hoy me gustaría compartir con ustedes cómo usar LabVIEW para llamar al modelo pb para lograr el reconocimiento de objetos. El kit de herramientas inteligente utilizado en este blog se puede descargar desde el tutorial de descarga e instalación de LabVIEW AI Vision Toolkit (no NI Vision) en el blog superior en la página de inicio.
1. Descripción general de los principios de los algoritmos de reconocimiento de objetos.
1. El concepto de reconocimiento de objetos.
El reconocimiento de objetos también se llama detección de objetivos . El problema a resolver mediante la detección de objetivos es dónde está el objetivo y su estado. Sin embargo, este problema no es fácil de resolver. La forma no es razonable y el área donde aparece el objeto es incierta, sin mencionar que el objeto también puede ser de múltiples categorías.
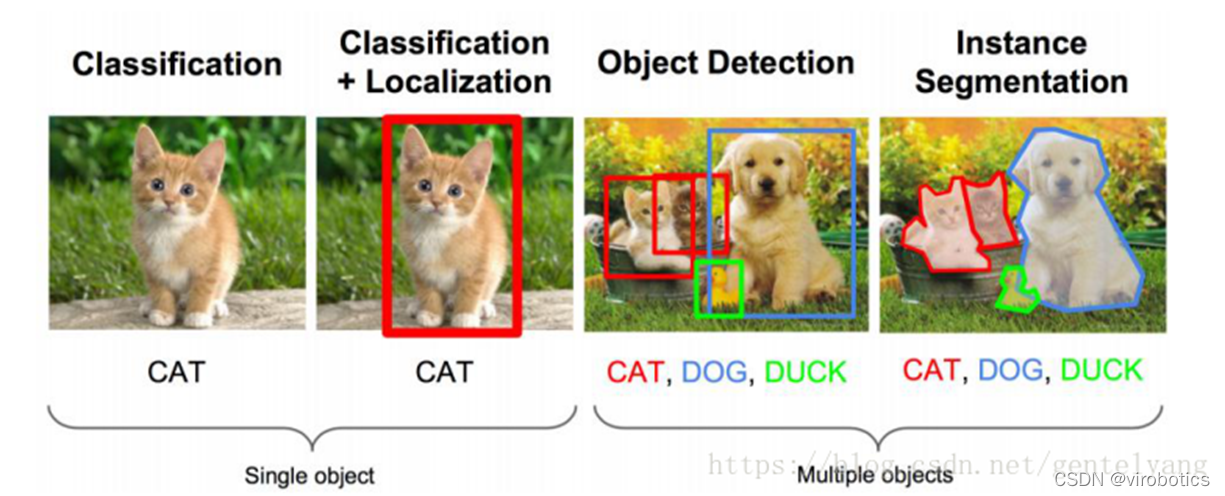
Los métodos de detección de objetivos más utilizados son RCNN, spp-net, fast-rcnn, fast-rcnn; series YOLO, como YOLOV3 y YOLOV4; además, existen SSD, ResNet, etc.
2. Descripción general del principio del algoritmo Yolo
El principio de reconocimiento de Yolo es simple y claro. Para la imagen de entrada, la imagen completa se divide en cuadrados de 7 × 7 (7 es un parámetro, ajustable). Cuando el punto central de un objeto cae en un determinado cuadrado, ese cuadrado es responsable de predecir el objeto. Cada cuadrado generará 2 cuadros candidatos (parámetros, ajustables) para el objeto predicho y generará la confianza de cada cuadro. Finalmente, se selecciona la casilla con mayor confianza como resultado de la predicción.
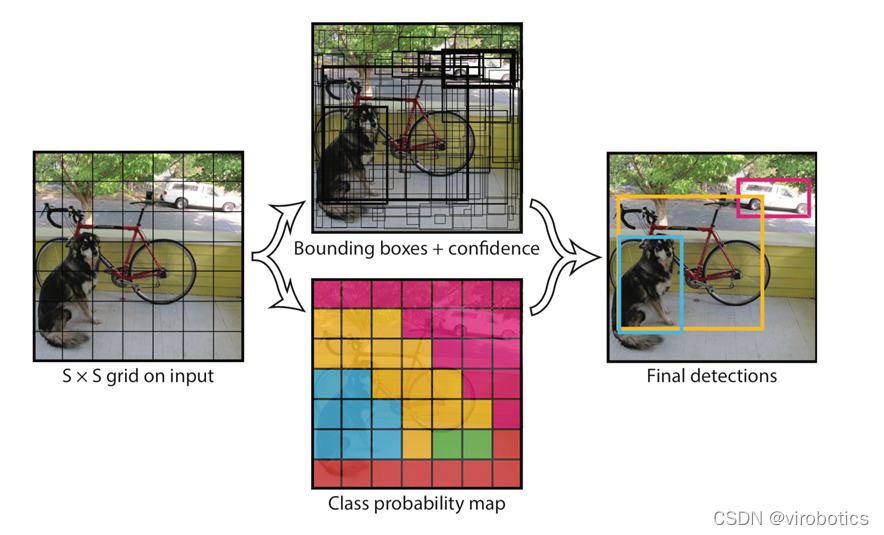
2. Opencv llama al modelo de reconocimiento de objetos de la darknet (yolov3/yolov4)
El código fuente y los modelos relevantes se encuentran en la carpeta darknt.

Utilice darknet para entrenar el modelo yolo y generar el archivo de pesos. Utilice opencv para llamar al modelo generado
1. Obtención del modelo darknet
Significado del archivo:
- archivo cfg: archivo de descripción del modelo
- archivo de pesos: archivo de peso del modelo
Enlace de acceso a Yolov3:
https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg
https://pjreddie.com/media/files/yolov3.weights
Enlace de adquisición de Yolov4:
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.cfg
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
2. Python llama al modelo darknet para realizar el reconocimiento de objetos.
(1) El módulo dnn llama al modelo darknet
net = cv2.dnn.readNetFromDarknet("yolov3/yolov3.cfg", "yolov3/yolov3.weights")
(2) Obtenga el LayerName de los tres terminales de salida
Utilice getUnconnectedOutLayer para obtener los nombres de tres capas con solo entrada y sin salida. Los nombres de las tres capas de salida de Yolov3 son: ['yolo_82', 'yolo_94', 'yolo_106']
def getOutputsNames(net):
# Get the names of all the layers in the network
layersNames = net.getLayerNames()
# Get the names of the output layers, i.e. the layers with unconnected outputs
return [layersNames[i - 1] for i in net.getUnconnectedOutLayers()]
(3) Preprocesamiento de imágenes
Utilice blobFromImage para convertir la imagen en imagen
Tamaño=(416,416) o (608,608)
Escala=1/255
Media=[0,0,0]
blob = cv2.dnn.blobFromImage(frame, 1/255, (416, 416), [0,0,0], 1, crop=False)
(4) Razonamiento
Utilice net.forward(multiNames) para obtener los resultados de varias capas, donde getOutputsNames(net)=['yolo_82', 'yolo_94', 'yolo_106']
net.setInput(blob)
outs = net.forward(getOutputsNames(net))
(5) Postprocesamiento
Hay tres matrices (out) en los resultados obtenidos (outs). El tamaño de cada matriz es 85*n. n significa que se han detectado n objetos. El orden de 85 es el siguiente: La columna 0 representa el centro del objeto x en la imagen
. La posición (0~1) de
la columna 1 representa la posición del centro y del objeto en la imagen (0~1). La
segunda columna representa el ancho del objeto.
La tercera columna representa la altura. del objeto
. La cuarta columna es la probabilidad de confianza, y el rango de valores es [0 -1], que se utiliza para comparar con el umbral para decidir si marcar el objetivo. Las
columnas 5 a 84 son los pesos de marcado de las 80 categorías basadas en el conjunto de datos COCO, y el más grande es la categoría de salida.
Utilice estos parámetros para conservar los resultados del reconocimiento con alta confianza (confianza>confThreshold)
def postprocess(frame, outs):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
classIds = []
confidences = []
boxes = []
classIds = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
print(boxes)
print(confidences)
(6) Postprocesamiento
Utilice la función NMSBoxes para filtrar regiones identificadas duplicadas.
indices = cv.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
for i in indices:
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
drawPred(classIds[i], confidences[i], left, top, left + width, top + height)
(7) Dibujar el objeto detectado
def drawPred(classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv.rectangle(frame, (left, top), (right, bottom), (0, 0, 255))
label = '%.2f' % conf
# Get the label for the class name and its confidence
if classes:
assert(classId < len(classes))
label = '%s:%s' % (classes[classId], label)
#Display the label at the top of the bounding box
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255))
(8) Código fuente completo y resultados de detección (cv_call_yolo.py)
import cv2
cv=cv2
import numpy as np
import time
net = cv2.dnn.readNetFromDarknet("yolov3/yolov3.cfg", "yolov3/yolov3.weights")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
confThreshold = 0.5 #Confidence threshold
nmsThreshold = 0.4 #Non-maximum suppression threshold
frame=cv2.imread("dog.jpg")
classesFile = "coco.names";
classes = None
with open(classesFile, 'rt') as f:
classes = f.read().rstrip('\n').split('\n')
def getOutputsNames(net):
# Get the names of all the layers in the network
layersNames = net.getLayerNames()
# Get the names of the output layers, i.e. the layers with unconnected outputs
return [layersNames[i - 1] for i in net.getUnconnectedOutLayers()]
print(getOutputsNames(net))
# Remove the bounding boxes with low confidence using non-maxima suppression
def postprocess(frame, outs):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
classIds = []
confidences = []
boxes = []
# Scan through all the bounding boxes output from the network and keep only the
# ones with high confidence scores. Assign the box's class label as the class with the highest score.
classIds = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
# Perform non maximum suppression to eliminate redundant overlapping boxes with
# lower confidences.
print(boxes)
print(confidences)
indices = cv.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
for i in indices:
#print(i)
#i = i[0]
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
drawPred(classIds[i], confidences[i], left, top, left + width, top + height)
# Draw the predicted bounding box
def drawPred(classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv.rectangle(frame, (left, top), (right, bottom), (0, 0, 255))
label = '%.2f' % conf
# Get the label for the class name and its confidence
if classes:
assert(classId < len(classes))
label = '%s:%s' % (classes[classId], label)
#Display the label at the top of the bounding box
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255))
blob = cv2.dnn.blobFromImage(frame, 1/255, (416, 416), [0,0,0], 1, crop=False)
t1=time.time()
net.setInput(blob)
outs = net.forward(getOutputsNames(net))
print(time.time()-t1)
postprocess(frame, outs)
t, _ = net.getPerfProfile()
label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency())
cv.putText(frame, label, (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255))
cv2.imshow("result",frame)

3. LabVIEW llama al modelo darknet para realizar el reconocimiento de objetos yolo_example.vi
(1) El método y los pasos de LabVIEW para llamar a yolov3 son similares a los de Python, el código fuente es el siguiente:

coloque la imagen identificada y yolo_example.vi en la misma ruta para realizar el reconocimiento de objetos.
(2) Los resultados del reconocimiento son los siguientes:

4. LabVIEW implementa el reconocimiento de objetos de cámara en tiempo real (yolo_example_camera.vi)
(1) Utilice la aceleración de GPU
Detectar el tiempo de inferencia de una red neuronal usando una estructura secuencial

Comparar la velocidad de inferencia con y sin GPU
Modo normal : net.serPerferenceBackend(0), net.serPerferenceTarget(0)
Modo Nvidia GPU : net.serPreferenceBackend(5), net.serPerferenceTarget(6)

Nota: Para las versiones normales de C ++, Python y LabVIEW de opencv, incluso si se selecciona el modo GPU, el programa aún se ejecuta en la CPU. Debe instalar CUDA y CUDNN y volver a compilar opencv desde el código fuente.
(2) El código fuente del programa es el siguiente:

(3) Los resultados del reconocimiento de objetos son los siguientes:

Tenga en cuenta que cuando utilice el programa anterior, puede hacer clic en el botón DETENER para detener el reconocimiento de objetos, o puede marcar la casilla para usar GPU para aceleración.
(4) Uso de GPU para acelerar los resultados:

3. Llamada al modelo de reconocimiento de objetos de Tensorflow
El código fuente y los modelos relevantes se encuentran en la carpeta tf1.

1. Descargue el modelo previamente entrenado y genere un archivo pbtxt.
(1) Descargue ssd_mobilenet_v2_coco, la dirección de descarga es la siguiente:
http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz
(2) Contenido del archivo descomprimido

(3) Generar archivo pbtxt según el modelo pb Ejecute
tf_text_graph_ssd.py para generar un archivo pptxt
Ejecute en cmd:
python tf_text_graph_ssd.py --input ssd_mobilenet_v1_coco_2017_11_17/frozen_inference_graph.pb --config ssd_mobilenet_v1_coco_20 17_11_17/ssd_mobilenet_v1_coco.config - -salida ssd_mobilenet_v1_coco_2017_11_17.pbtxt
2. LabVIEW llama al modelo tensorflow para razonar y realizar el reconocimiento de objetos (callpb.vi)
(1) El código fuente del programa es el siguiente:

(2) Los resultados de la ejecución son los siguientes:

4. Descarga del código fuente del proyecto y del modelo.
Enlace: https://pan.baidu.com/s/1zwbLQe0VehGhsqNIHyaFRw?pwd=8888
Código de extracción: 8888
Resumen y ampliación
Puede usar Yolov3 para entrenar su propio conjunto de datos. Para métodos de entrenamiento específicos, consulte el blog: https://blog.csdn.net/qq_38915710/article/details/97112788
Casos alcanzables: reconocimiento de uso de máscara, clasificación de neumonía, tomografía computarizada , etc., como el uso de máscaras Detección
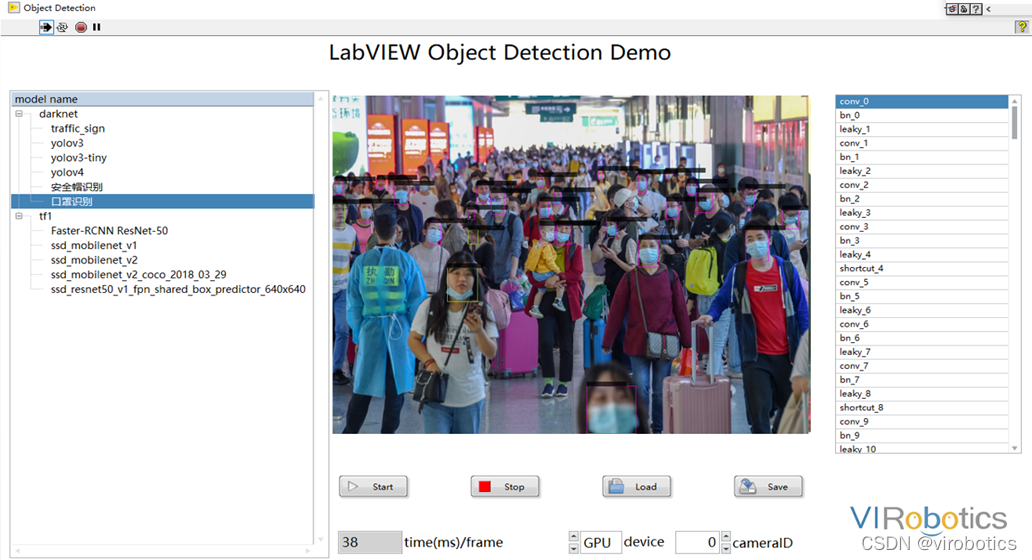
Para obtener más información sobre LabVIEW y la tecnología de inteligencia artificial, puede unirse al grupo de intercambio técnico para seguir discutiendo. Número de grupo QQ: 705637299