Directorio de artículos
- 1. Descripción general de MapReduce
1. Descripción general de MapReduce
1.1 Definición de MapReduce
MapReduce es un marco de programación para programas informáticos distribuidos y el marco central para que los usuarios desarrollen "aplicaciones de análisis de datos basadas en Hadoop".
La función central de MapReduce es integrar el código de lógica empresarial escrito por los usuarios y sus propios componentes predeterminados en un programa informático distribuido completo , que se ejecuta simultáneamente en un clúster de Hadoop.
1.2 Ventajas y desventajas de MapReduce
1.2.1 Ventajas
- MapReduce es fácil de programar.
Simplemente implementa algunas interfaces para completar un programa distribuido. Este programa distribuido se puede distribuir a una gran cantidad de máquinas PC baratas para ejecutar. Es decir, cuando escribes un programa distribuido, es exactamente lo mismo que escribir un programa serial simple. Es por esta característica que la programación de MapReduce se ha vuelto muy popular. - Buena escalabilidad
Cuando sus recursos informáticos no pueden satisfacerse, puede expandir su poder de cómputo simplemente agregando máquinas. - Alta tolerancia a fallas
La intención original del diseño de MapReduce es permitir que el programa se implemente en máquinas PC económicas, lo que requiere que tenga una alta tolerancia a fallas. Por ejemplo, si una de las máquinas se cuelga, puede transferir las tareas informáticas anteriores a otro nodo para ejecutarlas, de modo que la tarea no falle, y este proceso no requiere participación manual, pero Hadoop lo completa por completo. - Adecuado para el procesamiento fuera de línea de datos masivos por encima del nivel de PB,
puede realizar el trabajo simultáneo de miles de clústeres de servidores y proporcionar capacidades de procesamiento de datos.
1.2.2 Desventajas
- No es bueno en computación en tiempo real.
MapReduce no puede devolver resultados en milisegundos o segundos como MySQL. - No es bueno para la computación de transmisión
Los datos de entrada de la computación de transmisión son dinámicos, mientras que el conjunto de datos de entrada de MapReduce es estático y no se puede cambiar dinámicamente. Esto se debe a que las características de diseño del propio MapReduce determinan que la fuente de datos debe ser estática. - No es bueno para el cálculo de DAG (Gráfico acíclico dirigido)
Hay dependencias entre múltiples aplicaciones, y la entrada de la última aplicación es la salida de la anterior. En este caso, no es que MapReduce no pueda hacerlo, pero después de usarlo, el resultado de salida de cada trabajo de MapReduce se escribirá en el disco, lo que provocará una gran cantidad de E/S en el disco, lo que resultará en un rendimiento muy bajo.
1.3 La idea central de MapReduce
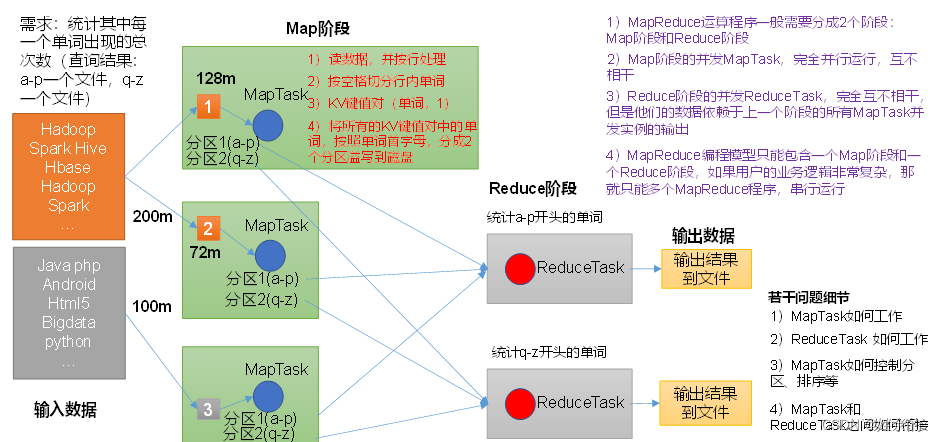
- Los programas de computación distribuida a menudo deben dividirse en al menos dos etapas.
- Las instancias simultáneas de MapTask en la primera etapa se ejecutan completamente en paralelo y son independientes entre sí.
- Las instancias simultáneas de ReduceTask en la segunda etapa son independientes entre sí, pero sus datos dependen de la salida de todas las instancias simultáneas de MapTask en la etapa anterior.
- El modelo de programación MapReduce solo puede contener una etapa Map y una etapa Reduce. Si la lógica comercial del usuario es muy compleja, solo se pueden ejecutar varios programas MapReduce en serie.
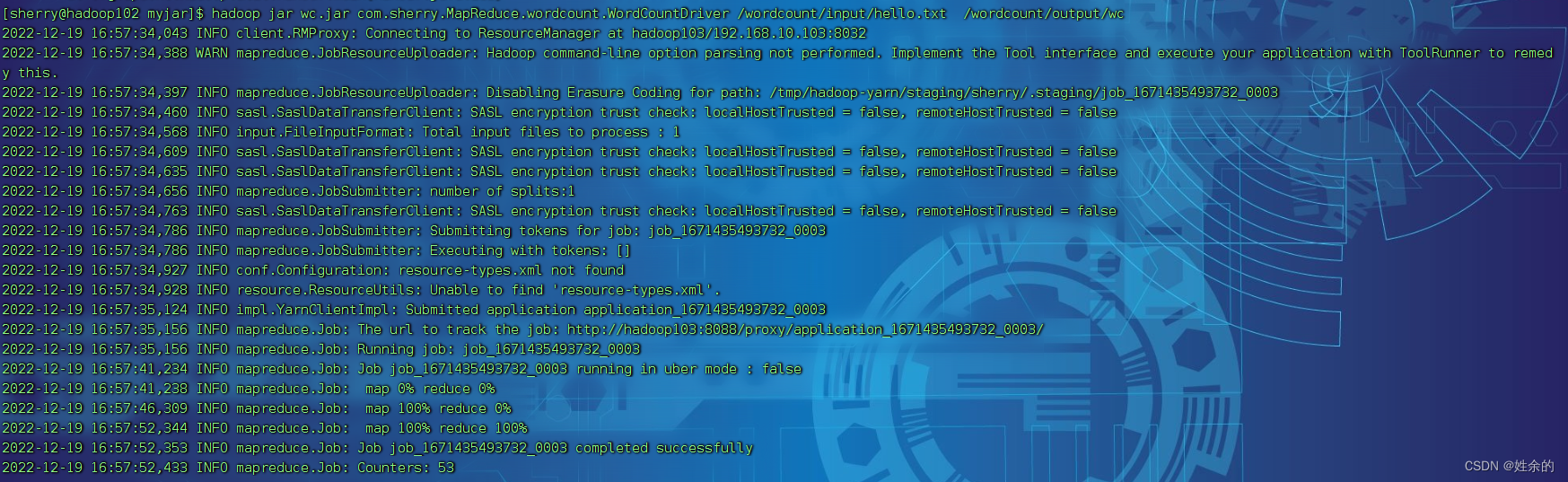
Resumen: analice el flujo de datos de WordCount para comprender profundamente la idea central de MapReduce.
1.4, proceso MapReduce
Un programa MapReduce completo tiene tres tipos de procesos de instancia durante el tiempo de ejecución distribuido:
- MrAppMaster: responsable de la programación de procesos y coordinación de estados de todo el programa.
- MapTask: Responsable de todo el proceso de procesamiento de datos en la fase de Mapa.
- ReduceTask: Responsable de todo el proceso de procesamiento de datos de la fase Reduce.
1.5 Código fuente oficial de WordCount
Utilice la herramienta de descompilación para descompilar el código fuente y descubra que el caso de WordCount incluye la clase de mapa, la clase de reducción y la clase de controlador. Y el tipo de datos es el tipo serializado encapsulado por Hadoop mismo.
1.6 Tipos de serialización de datos comúnmente utilizados
| tipo Java | Tipo de escritura de Hadoop |
|---|---|
| booleano | BooleanoEscribible |
| Byte | ByteEscribible |
| En t | IntWritable |
| Flotar | FlotanteEscribible |
| Largo | LongWritable |
| Doble | Escritura doble |
| Cadena | Texto |
| Mapa | MapaEscribible |
| Formación | ArrayEscribible |
| Nulo | NullEscribible |
1.7 Especificación del programa MapReduce
El programa escrito por el usuario se divide en tres partes: Mapper, Reducer y Driver.
- Etapa del mapeador
- Mappex definido por el usuario debe heredar su propia clase principal
- Los datos de entrada de Mapper están en forma de par KV t (el tipo de KV se puede personalizar)
- La lógica de negocios en Mapper está escrita en el método map()
- Los datos de salida de Mapper están en forma de pares de KV (el tipo de KV se puede personalizar)
- La parte map0 (proceso MapTaski) llama una vez por cada <K, V>
- Etapa reductora
- El reductor definido por el usuario debe heredar su propia clase principal
- El tipo de datos de entrada de Reducer corresponde al tipo de datos de salida de Mapper, que también es KV
- La lógica de negocios de Reducer está bien escrita en el método reduce()
- El proceso ReduceTask llama al método reduceQ una vez para cada grupo del mismo k.
- La etapa Driver
es equivalente al cliente del clúster YARN. Se utiliza para enviar todo nuestro programa al clúster YARN. Lo que se envía es un objeto de trabajo que encapsula los parámetros operativos del programa MapReduce.
1.8, práctica de casos de WordCount
1.8.1 Pruebas locales
- Se requiere
contar el número total de ocurrencias de cada palabra en un texto dado,
preparar un archivo de datos
y subir los datos a HDFS

sherry sherry banzhang banzhang cls cls wly wly hadoop xue sss
- Análisis de requisitos
De acuerdo con la especificación de programación de MapReduce, Mapper, Reducer y Driver se escriben respectivamente. - Preparación ambiental
- Crear un proyecto Maven => MapReduce
- Agregue las siguientes dependencias al archivo pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
3. En el directorio src/main/resource del proyecto, cree un nuevo archivo llamado "log4j.properties", complete el archivo
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4. Cree el nombre del paquete: com.sherry.MapReduce.wordcount
- Programación
- Escribe la clase Mapper
package com.sherry.MapReduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
- Escribe la clase Reducer
package com.sherry.MapReduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
- Escribir clase de controlador de controlador
package com.sherry.MapReduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 关联本Driver程序的jar
job.setJarByClass(WordCountDriver.class);
// 3 关联Mapper和Reducer的jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
- prueba local
- Primero debe configurar la variable HADOOP_HOME y las dependencias de ejecución de Windows
- Ejecute el programa en IDEA/Eclipse
1.8.2 Someterse a la prueba de clúster
Prueba en clúster
- Empaquete el programa en un paquete jar
. Si el programa tiene una carpeta de destino, límpiela primero.
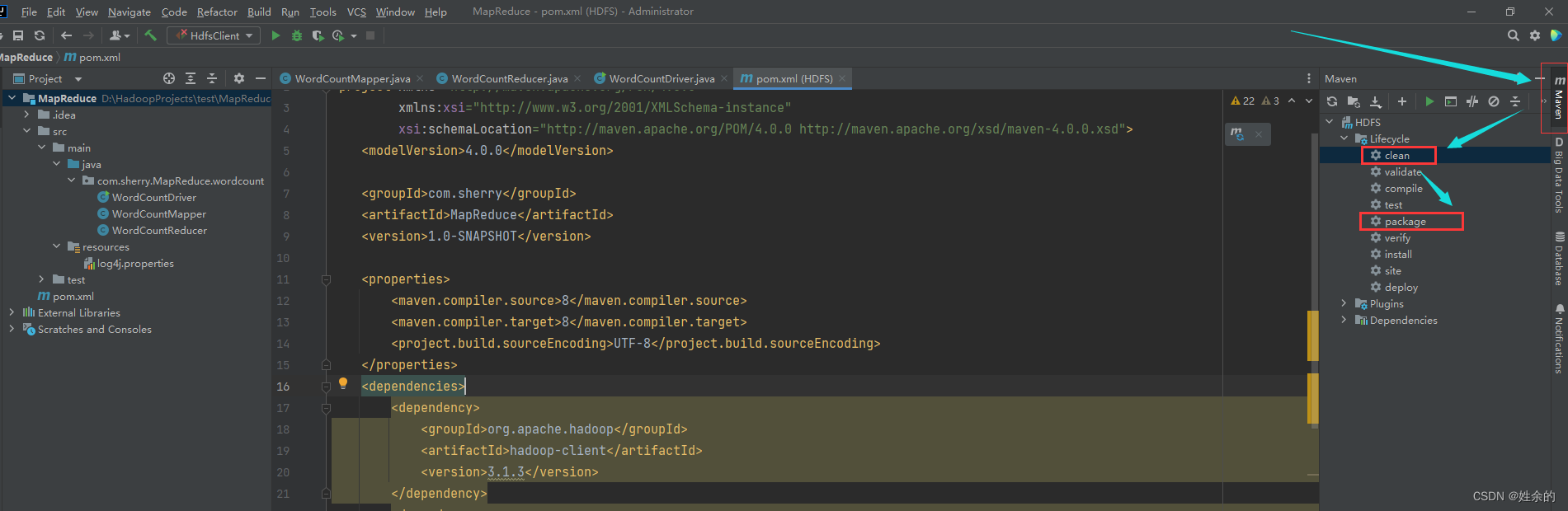
Cambie el nombre del paquete jar sin dependencias a wc.jar y copie el paquete jar en la/opt/module/hadoop-3.1.3/myjarruta del clúster de Hadoop.
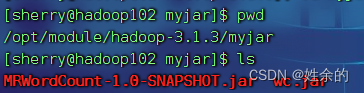
- Ejecute el programa de recuento de palabras.
Recuerde abrir hdfs e yarn antes de ejecutar el programa de recuento de palabras.
Nota: rutas de archivo y similares, donde se cargan sus archivos.
hadoop jar wc.jar com.sherry.MapReduce.wordcount.WordCountDriver /wordcount/input/hello.txt /wordcount/output/wc