

1. Protocolo HTTP
1.1, una breve descripción de HTTP
El nombre completo de HTTP es Protocolo de transferencia de hipertexto, que es un protocolo de capa de aplicación ampliamente utilizado.
Entonces, ¿qué es el hipertexto? El hipertexto se refiere a la transmisión de contenido no solo de texto, como html, css, javaScript y otros datos, sino también de otros recursos, como imágenes, videos, audio y otros datos binarios.
El diagrama esquemático del modelo de referencia OSI y el modelo en capas TCP/IP es el siguiente:
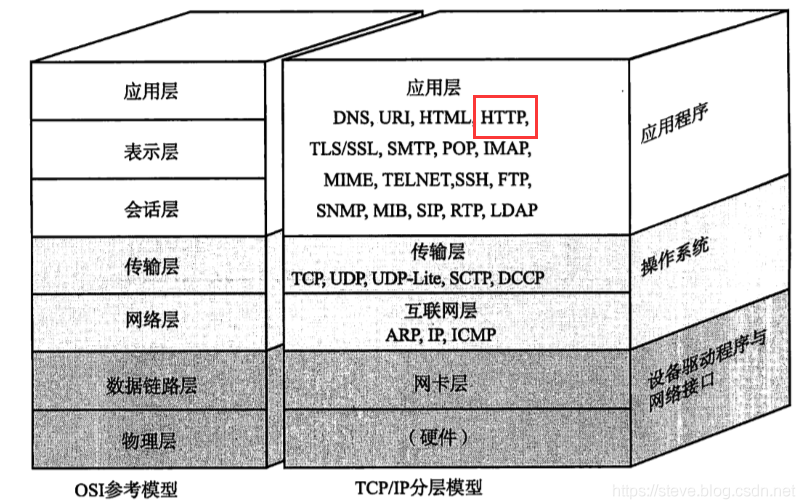
1.2, historial de desarrollo de HTTP
HTTP nació en 1991 y se ha convertido en el protocolo de capa de aplicación más convencional.
Diagrama esquemático del proceso de desarrollo de HTTP:

consejos:
HTTP a menudo se implementa en función del protocolo TCP de la capa de transporte, pero HTTP también se implementa en función del protocolo UDP de la capa de transporte.
- HTTP1.0, HTTP1.1 y HTTP2.0 se basan en TCP, mientras que HTTP3 se basa en UDP.
Aunque HTTP ahora se ha convertido en la versión HTTP3, actualmente usamos principalmente las versiones HTTP/1.1 y HTTP/2.0.
1.3, proceso de trabajo HTTP
El protocolo HTTP es un protocolo de transferencia de hipertexto, un protocolo de comunicación de capa de aplicación entre un cliente u otros programas y un servidor web.
En otras palabras, el protocolo HTTP es la regla para la transmisión de datos entre el servidor y el cliente.
¿Cuál es el proceso de trabajo de HTTP?

**El proceso de trabajo de HTTP es el siguiente: **Cuando ingresamos una "dirección web" (URL) buscada por Sogou en el navegador, el navegador envía una solicitud HTTP al servidor de Sogou. Después de la solicitud HTTP del servidor, un La respuesta HTTP se devuelve al navegador, y el resultado de la respuesta HTTP devuelto por el servidor es analizado por el navegador y luego se muestra como el contenido de la página que vemos.
Durante este proceso, el navegador puede enviar múltiples solicitudes HTTP al servidor, y el servidor devolverá múltiples respuestas correspondientes.Estas respuestas incluyen una serie de contenido como HTML, CSS, JavaScript, imágenes y fuentes de la página.
Es decir, cuando visitamos un sitio web, puede implicar más de un proceso de interacción de solicitud/respuesta HTTP.
Expansión: comprensión del protocolo de la capa de aplicación
La capa de transporte se encuentra en la cuarta capa del modelo OSI y es responsable de proporcionar servicios de transmisión de datos de extremo a extremo entre diferentes hosts en la red, incluidas funciones como conexión de red, segmentación de flujo de datos, control de errores de transmisión de datos, transmisión de datos. reensamblaje de flujo y control de flujo. La selección de rutas y la transmisión entre redes son parte de la función de la capa de transporte, las cuales se completan a través de protocolos como IP (Protocolo Internacional) y TCP (Protocolo de Control de Transmisión). Cuando los datos se transmiten a través de la red a través de la selección de ruta, la capa de transporte necesita encapsular y desencapsular los datos, incluidas operaciones como la segmentación, el ensamblaje y el control de conexión de los datos para garantizar la integridad y corrección de los datos. Por lo tanto, la capa de transporte es la capa clave para realizar la transmisión de datos entre el puerto de origen y el puerto de destino.
A través de la comprensión anterior de la capa de transporte, ya sabemos que en la capa de transporte, los datos se pueden transmitir a través de la red desde el proceso del puerto de origen hasta el proceso del puerto de destino a través de la selección de la ruta.
Sin embargo, ¿el proceso termina simplemente transfiriendo datos desde el puerto de origen al puerto de destino o desde el puerto de destino al puerto de origen?
Obviamente, esto no ha terminado, ya sea que los datos se transmitan del servidor al cliente, o después de que los datos se transmitan del cliente al servidor, el servidor y el cliente aún necesitan procesar o usar los datos. En este momento, necesitamos una capa de protocolo, que no se preocupa por los detalles de la comunicación, sino que solo se preocupa por los detalles de la aplicación, y esta capa de protocolo se llama protocolo de capa de aplicación.
Observaciones: Cliente y servidor son conceptos de la capa de aplicación, mientras que el proceso del puerto de origen y el proceso del puerto de destino son conceptos de la capa de transporte.
Debido a que hay muchos escenarios de aplicación, también hay muchos tipos de protocolos de capa de aplicación, entre los cuales el protocolo HTTP es un protocolo de capa de aplicación relativamente clásico.
Una comprensión simple de los protocolos de la capa de aplicación a través de ejemplos de la vida:
Cuando compramos un producto electrónico en Taobao, el vendedor [cliente] enviará el producto al comprador [servidor] a través de SF Express [entrega + selección de ruta], y el producto en manos del comprador estará acompañado por un Manual del producto , el manual contiene información como la introducción del producto, la introducción del uso y las precauciones, para guiar a los usuarios sobre cómo usar el producto. En este momento, el manual es equivalente al protocolo de la capa de aplicación.
2. Formato del protocolo HTTP
HTTP es un protocolo en formato de texto, que se puede ver a través de las herramientas de desarrollo de Chrome o herramientas de terceros para capturar paquetes y luego analizar los detalles de las solicitudes HTTP y las respuestas HTTP.
2.1, use herramientas de desarrollador para obtener
1. Uso de herramientas de desarrollo
Hay dos formas de abrir las herramientas de desarrollo, a saber:
1) En la página del navegador, haga clic con el botón derecho del mouse y seleccione la opción de verificación para abrir la herramienta de desarrollo
2) Use directamente la tecla de acceso directo F12para abrir la herramienta de desarrollo
Abra las herramientas para desarrolladores de Chrome, cambie a la pestaña Red (red) y luego actualice la página para ver el siguiente efecto:
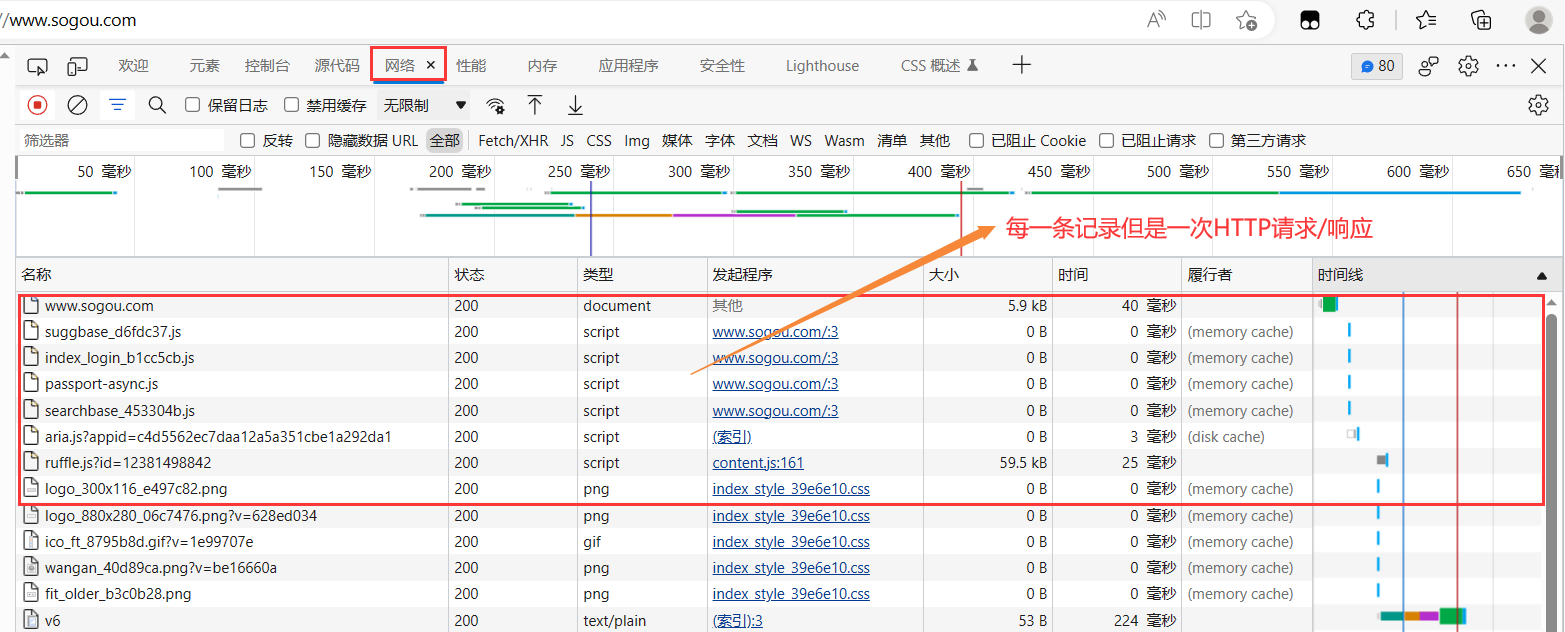
2. Los resultados de las herramientas para desarrolladores
Cuando desee ver la información específica de un registro, haga clic en el nombre del registro.
2.2, utilice la herramienta de captura de paquetes para obtener
1. Uso de herramientas de captura de paquetes
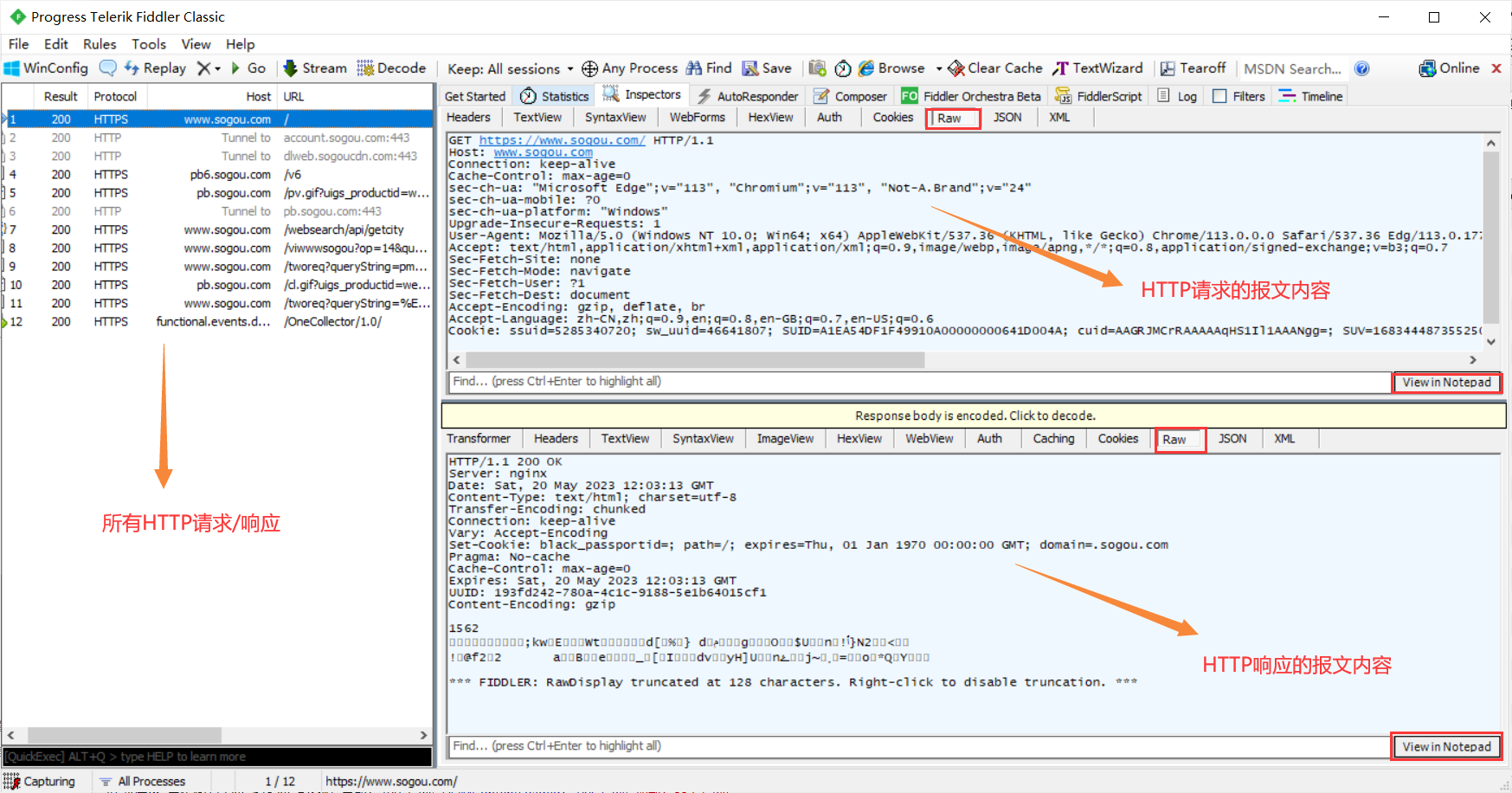
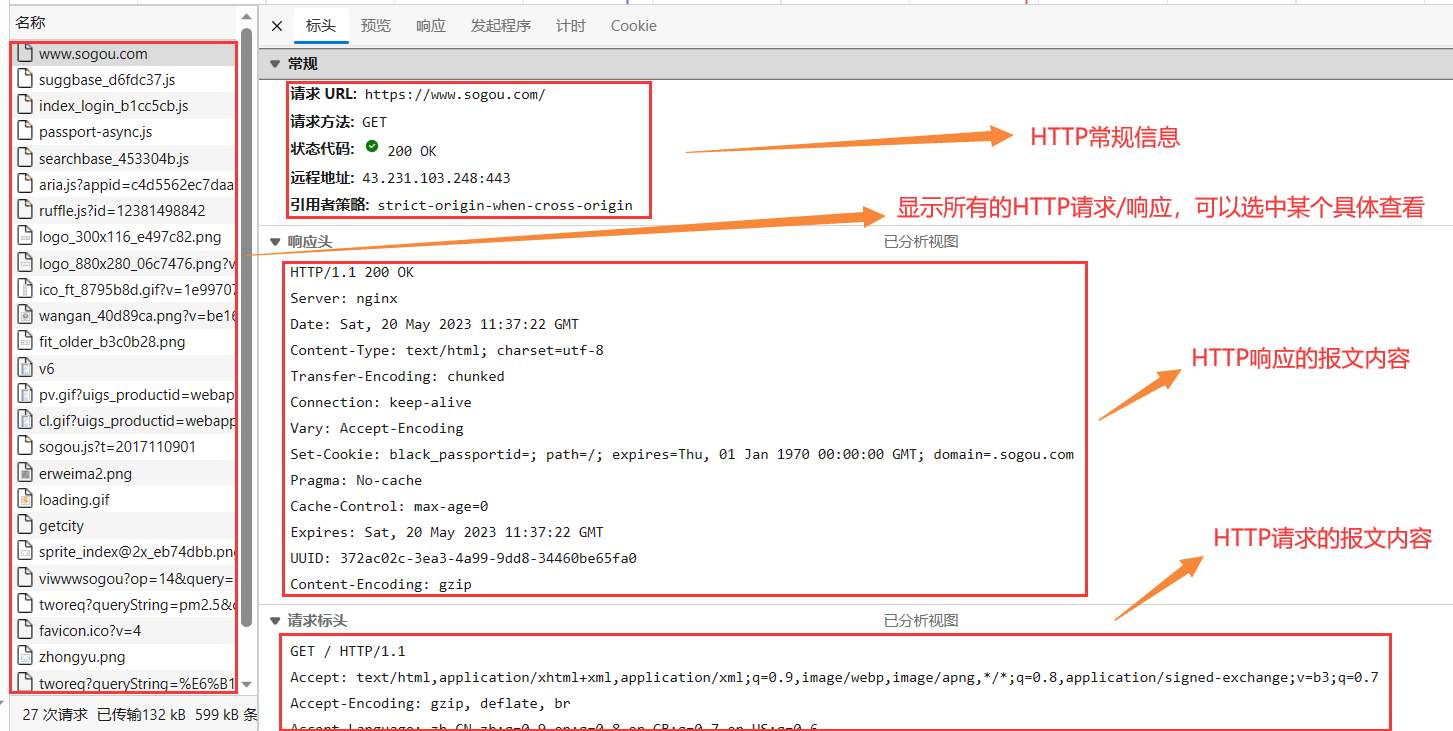
1. La ventana de la izquierda muestra todas las solicitudes/respuestas HTTP, y puede seleccionar una solicitud para ver los detalles
2. El contenido del mensaje de la solicitud HTTP se muestra en la parte superior derecha (cambie a la pestaña Raw para ver el formato de datos detallado)
3. El contenido del mensaje de la respuesta HTTP se muestra en la parte inferior derecha (cambie a la pestaña Raw para ver el formato de datos detallado)
4. Los datos detallados de la solicitud y la respuesta se pueden View in Notepadabrir con el Bloc de notas en la esquina inferior derecha
5. Puede usar ctrl + atodos los resultados de captura a la izquierda para seleccionarlos todos y presionar la tecla Eliminar para borrar todos los resultados seleccionados
2. El principio de la herramienta de captura de paquetes.
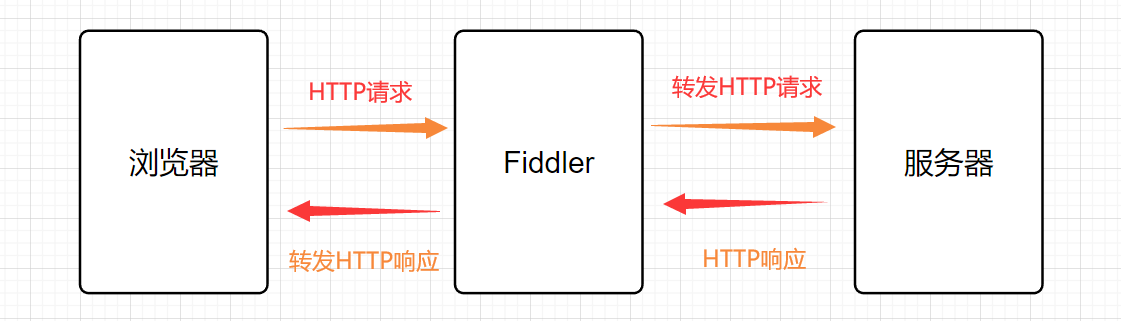
La herramienta de captura de paquetes Fiddler es esencialmente equivalente a un "proxy".
**El principio de funcionamiento es: **Cuando el navegador visita www.sogou.com, primero enviará la solicitud HTTP a Fiddler, y luego Fiddler reenviará la solicitud al servidor de sogou. Cuando el servidor sogou devuelve los datos, Fiddler obtiene los datos devueltos y luego pasa los datos al navegador. Por lo tanto, Fiddler es muy claro acerca de los detalles de los datos de la interacción entre el navegador y el servidor sogou.
Diagrama esquemático de la herramienta de captura de paquetes Fiddler:
Hay dos precauciones al usar la herramienta de captura de paquetes Fiddler:
1. Puede haber conflictos con otros programas proxy. Al usarlo, se deben cerrar otros programas proxy y algunos complementos del navegador.
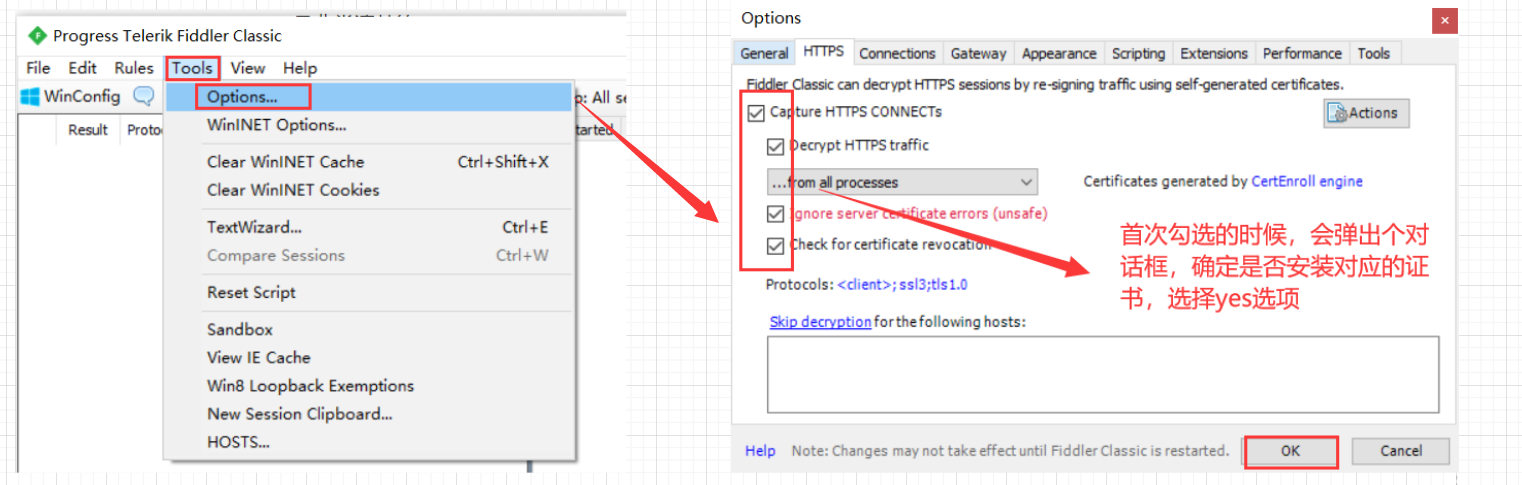
2. Para capturar paquetes correctamente, debe habilitar la función HTTPS. Fiddler no puede capturar paquetes HTTPS de forma predeterminada, y la mayoría de los servidores en Internet actualmente usan HTTPS. HTTPS introduce una capa de cifrado basada en HTTP, así que lo haremos. necesita habilitar manualmente la función HTTPS e instalar el certificado.
Expansión: Fiddler abre la función HTTPS
Expansión: proxy directo y proxy inverso
**Proxy de reenvío (proxy de reenvío)** se refiere a un servidor (servidor proxy) entre el cliente y el servidor de destino. Para obtener contenido del servidor de destino, el cliente envía una solicitud al servidor proxy y especifica el destino, y luego El servidor proxy reenvía la solicitud al servidor de destino y devuelve el contenido obtenido al cliente.
Ejemplo de vida: tú y tu buen amigo están en la escuela y ves a una joven muy hermosa. Quieres saber el WeChat de esta joven, pero no te atreves a preguntar porque eres introvertido. Hola amigo, para Te ayudo, corrí para ayudarte a pedir el WeChat de esta hermana pequeña, y te daré el WeChat de la hermana pequeña cuando regrese.
Ejemplo de explicación: usted es equivalente al cliente, y su buen amigo es equivalente al servidor proxy, y esa jovencita es equivalente al servidor.
La hermana pequeña solo sabe que su buen amigo la ayudó en el pasado, pero no sabe quién quiere agregar su WeChat, y usted sabe claramente de quién es el WeChat que desea.
Esto muestra que el cliente puede conocer la dirección del servidor de destino, pero el servidor de destino no sabe de qué cliente es, solo sabe de qué servidor proxy es.
Por lo tanto, el proxy de reenvío puede proteger u ocultar la información del cliente.
**Proxy inverso (proxy inverso)** se refiere al servidor proxy para recibir la solicitud del cliente, luego reenvía la solicitud al servidor en la red interna y devuelve el resultado obtenido del servidor al cliente. En este momento, el servidor proxy externo Actúa como un servidor proxy inverso.
Ejemplo de vida: invitas a amigos a cenar en un hotel, el mesero entregará el menú que ordenaste a la cocina trasera, y el jefe de cocina en la cocina trasera distribuirá los platos del menú a los chefs de abajo para que los preparen, y después de preparación, el camarero la servirá Servir en la mesa.
Ejemplo: su mesa es equivalente al cliente, el mesero es equivalente al servidor proxy y el chef en la cocina trasera es equivalente al servidor.
Solo sabe que el plato lo sirvió el mesero, pero no sabe qué chef preparó el plato, pero el chef en la cocina trasera sabe para qué mesa es el plato.
Esto muestra que el servidor puede conocer la dirección del cliente, pero el cliente no sabe de qué servidor es, solo sabe de qué servidor proxy es.
Por lo tanto, el proxy inverso puede blindar u ocultar la información del servidor.
3. El resultado de la herramienta de captura de paquetes
1. Lista HTTP
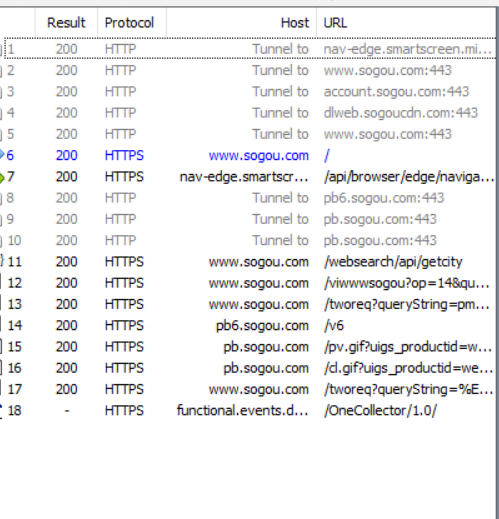
2. Solicitud HTTP
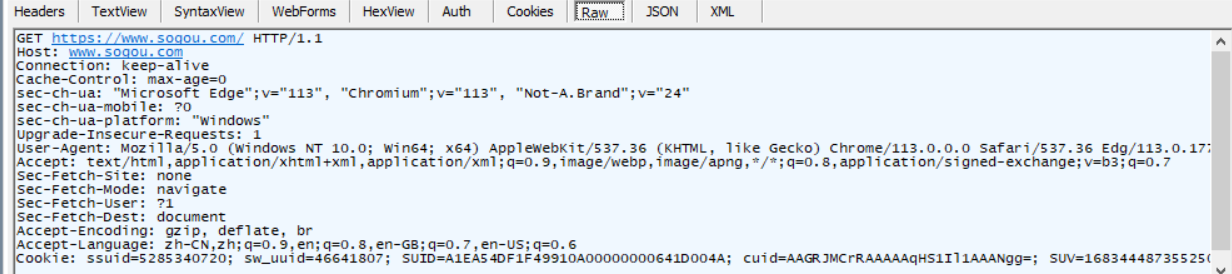
3. Respuesta HTTP
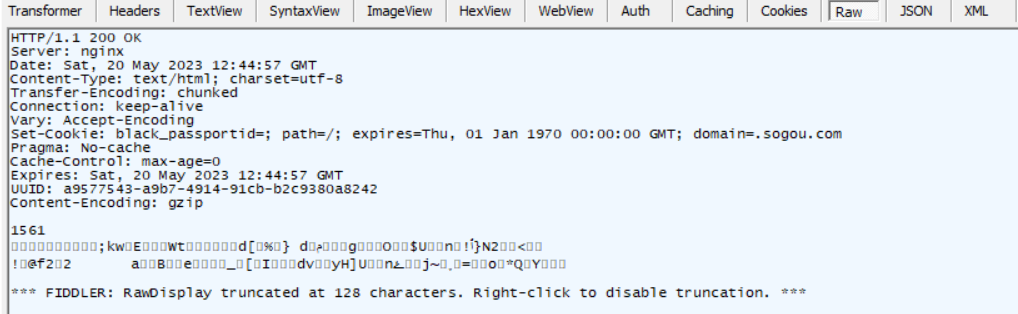
4. Análisis de los resultados de la captura de paquetes
La lista HTTP anterior es la solicitud HTTP generada cuando el navegador accede a la página de inicio de Sogou.
Entre estas solicitudes, lo que más nos preocupa es lo que solicitamos para acceder, y el resto de las solicitudes se generan en función de esta solicitud.
Al buscar una página en el navegador, puede haber una o varias solicitudes HTTP correspondientes.
Las solicitudes HTTP y las respuestas HTTP tienen un formato determinado, y Fiddler las analizará de acuerdo con diferentes formatos y presentará diferentes efectos de visualización.
tcpLa solicitud HTTP y la respuesta HTTP obtenidas mediante la captura de paquetes son datos en formato de texto de línea Comparado con este formato binario, el formato de texto de línea tiene la ventaja de que es conveniente para los usuarios ver la información directamente.
En algunos servidores, el servidor comprimirá los datos de respuesta HTTP para convertir los datos de respuesta en un formato binario, ahorrando así ancho de banda y mejorando la eficiencia de la transmisión.
Expansión: compresión
La compresión se define como convertir datos sin procesar en una forma más compacta para ahorrar espacio y ancho de banda durante el almacenamiento y la transmisión. La compresión es una técnica común utilizada en aplicaciones informáticas, de comunicación y multimedia en general.
Tenga en cuenta que no todos los datos son adecuados para la compresión, y algunos datos pueden ser más grandes después de volver a codificarlos, pero los archivos de texto generales HTMLy JSsimilares son adecuados para la compresión.
2.3, formato de protocolo HTTP
1. Formato de solicitud HTTP
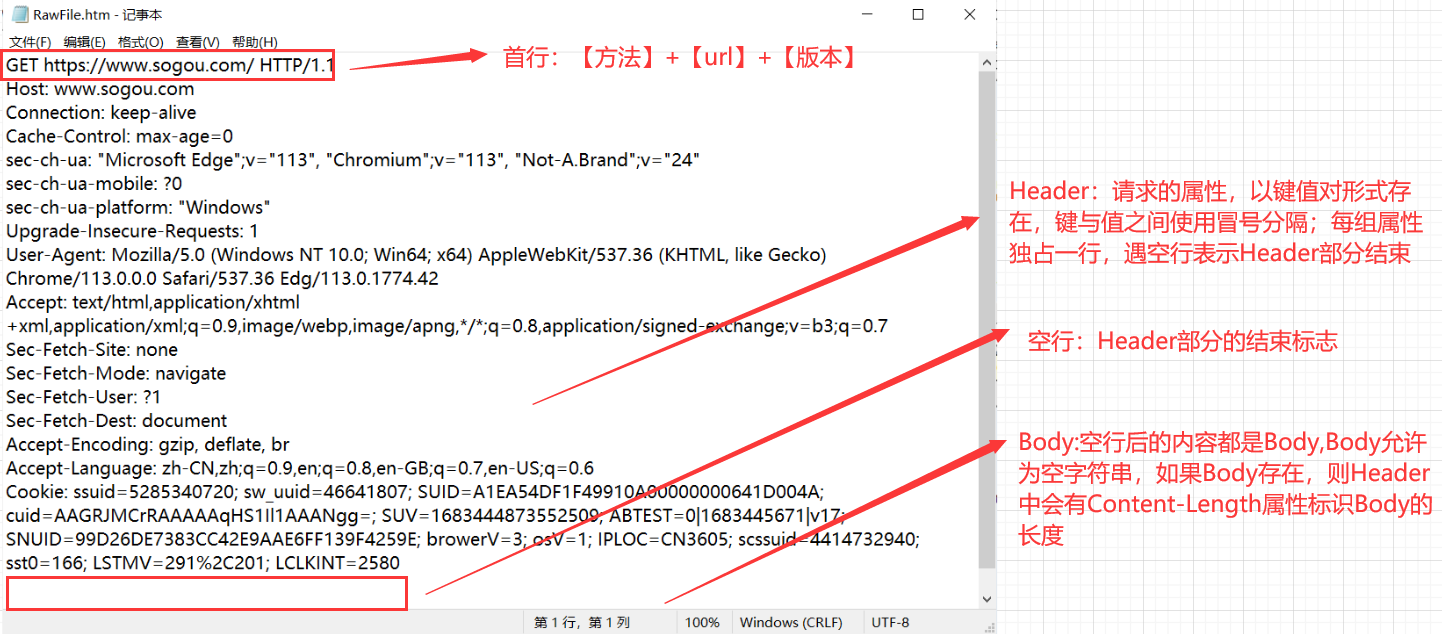
2. Formato de respuesta HTTP
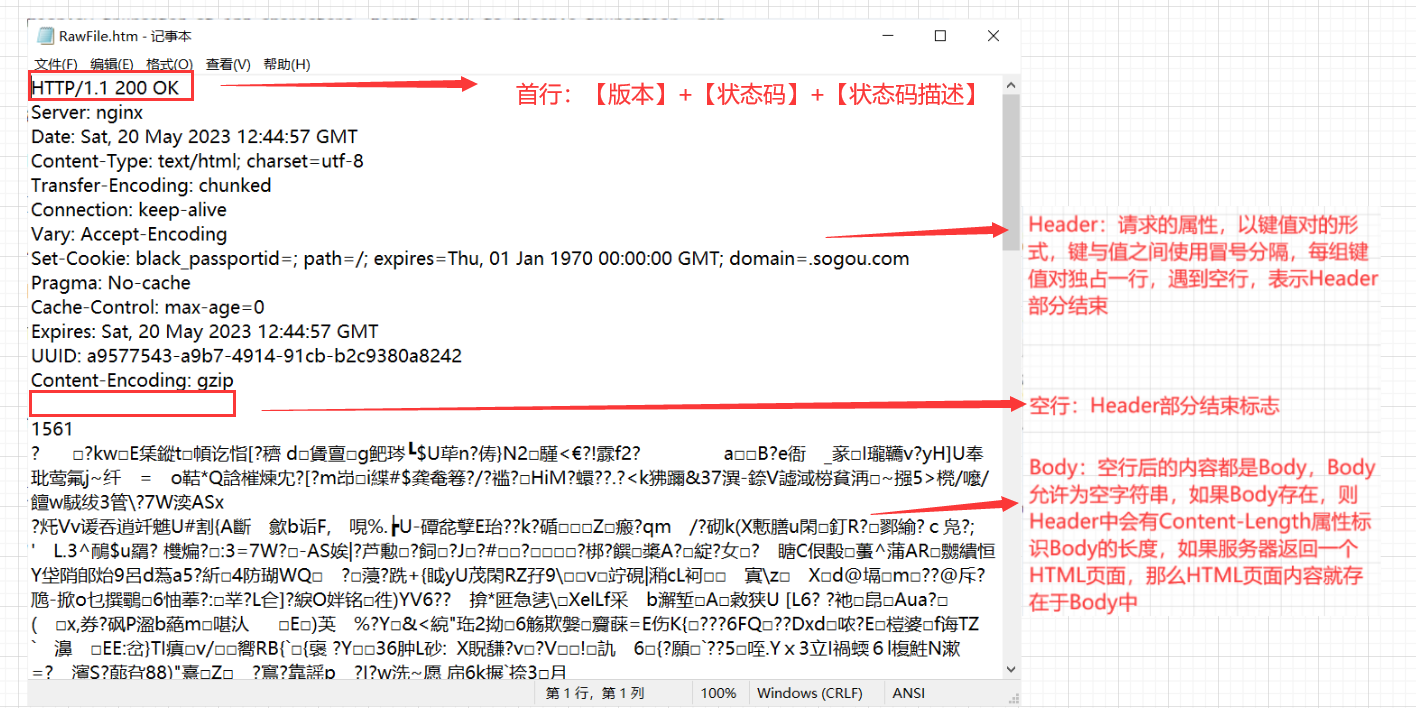
3. Resumen del formato HTTP

Expansión: ¿Por qué hay una "línea en blanco" en el mensaje HTTP?
Dado que el protocolo HTTP no estipula el número de pares clave-valor en la parte del encabezado, una línea en blanco equivale a "el marcador final del encabezado" o "el separador entre el encabezado y el cuerpo".
HTTP se basa en el protocolo TCP en la capa de transporte y TCP está orientado a bytes. Si no hay tal línea en blanco, habrá un "problema de paquete pegajoso".
3. Solicitud HTTP
3.1, método HTTP
1. Método de solicitud HTTP
El método HTTP se refiere a que HTTP define un conjunto de métodos de solicitud para indicar la operación que se realizará en un recurso determinado o para indicar la acción deseada que se realizará en un recurso determinado.
Los métodos HTTP comunes son los siguientes:
| método HTTP | Descripción del método | versión compatible |
|---|---|---|
| CONSEGUIR | El recurso identificado por la URL utilizada para obtener la línea de solicitud | 1.0,1.1 |
| CORREO | Se utiliza para enviar entidades al recurso especificado | 1.0,1.1 |
| PONER | Se utiliza para transferir archivos específicos | 1.0,1.1 |
| CABEZA | El encabezado de respuesta utilizado para obtener el recurso identificado por la URL | 1.0,1.1 |
| BORRAR | Se utiliza para eliminar el recurso identificado por la URL | 1.0,1.1 |
| RASTRO | Se utiliza para realizar pruebas de bucle invertido de mensajes a lo largo de la ruta al recurso de destino | 1.1 |
| OPCIONES | Opciones de comunicación permitidas para solicitar una URL o servidor determinado | 1.1 |
| CONECTAR | Se utiliza para establecer un túnel al servidor identificado por el recurso de destino, el proxy de conexión | 1.1 |
| COMO | Se utiliza para establecer vínculos con los recursos. | 1.0 |
| DESHACER | Se utiliza para desconectarse de los recursos. | 1.0 |
Si desea tener una comprensión más profunda de los métodos HTTP anteriores, puede aprender en [Documentación de desarrollo] ( Métodos de solicitud HTTP - HTTP | MDN (mozilla.org) ).
En el desarrollo real, la mayoría de los métodos anteriores no se utilizan y los métodos HTTP más comunes son GET方法y POST方法.
2. Método de solicitud GET
GET es el método HTTP más utilizado, a menudo para obtener un recurso en el servidor.
Ingrese la URL directamente en el navegador, y el navegador enviará una solicitud GET en este momento; además, el enlace, img, script y otras etiquetas en el HTML también activarán la solicitud GET.
Además de los dos métodos anteriores para activar solicitudes GET, Ajax en JavaScript también se puede usar para construir solicitudes GET.
Visite la página de inicio de Sogou y use la herramienta de captura de paquetes Fiddler para ver los resultados de la captura de paquetes

Como se puede ver en los resultados de captura de paquetes anteriores, el registro de captura de paquetes superior  es una solicitud GET enviada a través de la barra de direcciones del navegador.
es una solicitud GET enviada a través de la barra de direcciones del navegador.
Algunas de las siguientes solicitudes relacionadas con el nombre de dominio sogou se generan a través de las etiquetas link/scripy/img en html, como las siguientes solicitudes:

También hay algunas solicitudes generadas a través de Ajax, como las siguientes solicitudes:

Seleccione el primer registro de captura de paquetes  para observar los resultados detallados de la solicitud.
para observar los resultados detallados de la solicitud.
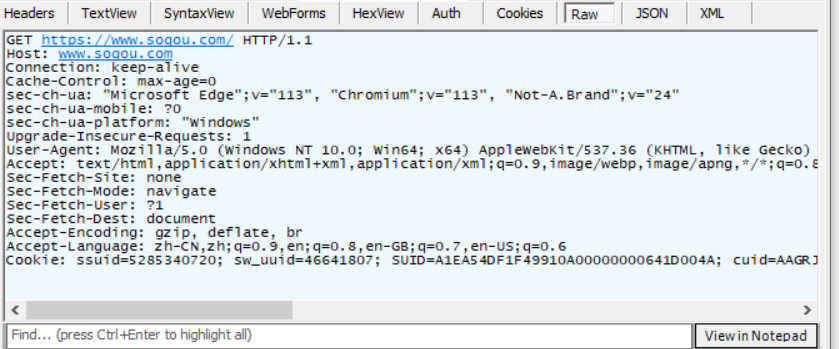
Características de las solicitudes GET:
1) El método HTTP de la línea de solicitud es GET y la URL query stringpuede estar vacía o no.
2) La parte del encabezado del encabezado de la solicitud tiene varios conjuntos de atributos de la estructura de pares clave-valor. Cada conjunto de pares clave-valor ocupa una sola línea, y la parte del encabezado termina con una línea en blanco.
3) La parte del cuerpo del cuerpo de la solicitud está vacía.
3. Método de solicitud POST
El método POST también es un método HTTP común, a menudo utilizado para enviar datos ingresados por el usuario al servidor (como una página de inicio de sesión).
Una solicitud POST se puede construir a través de una etiqueta de formulario en HTML, o una solicitud POST se puede construir usando JavaScript ajax.
Inicie sesión en el sitio web oficial de la escuela y use la herramienta de captura de paquetes Fiddler para ver los resultados de la captura de paquetes

Como se puede ver en los resultados de captura de paquetes anteriores, el registro de captura de paquetes superior  es una solicitud POST construida a través de un formulario.
es una solicitud POST construida a través de un formulario.
Seleccione el primer registro de captura de paquetes para observar los resultados detallados de la solicitud.
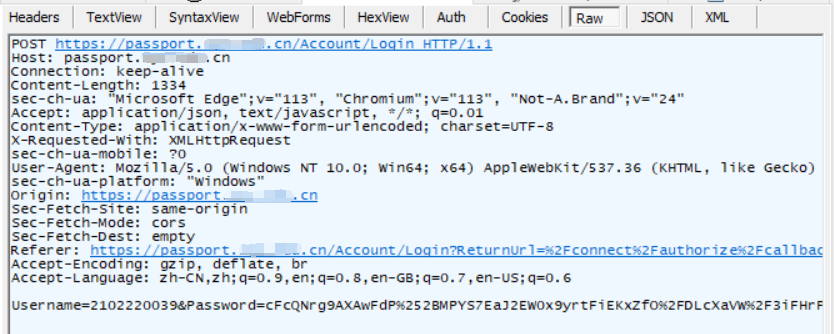
Características de las solicitudes POST:
1) El método HTTP de la línea de solicitud es POST, y la URL query stringgeneralmente está vacía, o puede que no esté vacía.
2) La parte del encabezado del encabezado de la solicitud tiene varios conjuntos de atributos de la estructura de pares clave-valor. Cada conjunto de pares clave-valor ocupa una sola línea, y la parte del encabezado termina con una línea en blanco.
3) La parte del cuerpo del texto de la solicitud generalmente no está vacía, el formato de datos en el cuerpo se especifica en el encabezado Content-Typey la longitud del cuerpo se especifica en el encabezado Content-Length.
4. La diferencia entre POST y GET
Diferencias típicas entre POST y GET:
1) Las solicitudes GET generalmente se usan para obtener datos del servidor, mientras que las solicitudes POST generalmente se usan para enviar datos al servidor.
2) El cuerpo de una solicitud GET generalmente está vacío y los datos que se transferirán pasan a través de query string, mientras que el cuerpo de una solicitud POST query stringgeneralmente está vacío y los datos que se transferirán pasan a través del cuerpo.
3) Las solicitudes GET generalmente son idempotentes, mientras que las solicitudes POST generalmente no son idempotentes.
4) Los resultados de las solicitudes GET se pueden almacenar en caché, pero los resultados de las solicitudes POST no se pueden almacenar en caché. (Esto es para emprender la idempotencia)
Nota: En realidad, no existe una diferencia esencial entre las solicitudes GET y las solicitudes POST. Las diferencias anteriores son solo diferencias en los hábitos de uso. En la mayoría de los escenarios, los dos se pueden usar indistintamente.
Expansión: la característica central de la idempotencia es que el impacto de cualquier número de ejecuciones es el mismo que el de una ejecución.
5. Extensión de la solicitud GET
1. Volumen de datos de transferencia de solicitudes GET
El tamaño de los datos de transmisión de la solicitud GET no está claramente estipulado en el documento estándar rfc, es decir, el protocolo HTTP no estipula la capacidad máxima de los datos de transmisión de la solicitud GET, que puede ser infinita en teoría, pero debido a que el GET solicitud utiliza la información del parámetro como una cadena de consulta La forma de la URL se coloca después de la URL, y muchos navegadores generalmente limitan la longitud de la URL a no más de 2 Kb. La limitación de la longitud de la URL limita la capacidad de la solicitud GET a transmitir datos durante la transmisión real de datos.
Y puede haber una pregunta cuando vea esto, ¿hay un límite para la longitud de la URL en la solicitud GET?
El protocolo HTTP está definido por el estándar RFC 2616. El texto original del estándar establece claramente: "Hypertext Transfer Protocol -- HTTP/1.1," does not specify any requirement for URL lengthes decir, no hay límite para la longitud de la URL en el protocolo HTTP, y la longitud real de la URL depende de la implementación. del navegador y la implementación del servidor HTTP. En el lado del navegador, diferentes navegadores tienen diferentes longitudes máximas; en el lado del servidor, usted mismo puede configurar esta longitud sin limitación.
Cuando la longitud de la URL de una solicitud GET supera el límite del navegador o del servidor, la solicitud se trunca o se rechaza. Por lo tanto, si se necesita pasar una gran cantidad de datos, se recomienda utilizar una solicitud POST o almacenar los datos en el lado del servidor y referirse a ellos mediante un identificador.
En resumen, no hay límite para el tamaño de los datos transmitidos por solicitud GET, pero debido a la limitación del servidor (navegador), esta limitación se refiere a la limitación de la cadena de consulta en la url, que a su vez conduce a la transmisión. de capacidad de datos en modo de solicitud GET restringida.
2. OBTENER solicitud de seguridad
En la superficie, debido a que la información de parámetros del método de solicitud de obtención se mostrará en texto sin formato en la barra de direcciones URL, mientras que los parámetros pasados por el método de solicitud posterior están ocultos en el contenido del texto, por lo general, los usuarios no profesionales no abrirán el modo de desarrollador para ver, así que publicar y obtener En comparación con el método de solicitud, la publicación es relativamente más segura; en el nivel profundo, si es seguro o no depende de si el front-end realiza operaciones de cifrado al transmitir información confidencial, como contraseñas y si el método de cifrado es bueno o malo, y si el método de solicitud es GET o POST es irrelevante.
3. Tipo de datos de transferencia de solicitud GET
Las solicitudes GET pueden transmitir no solo datos de texto, sino también datos binarios, como imágenes, audio, video, etc. Sin embargo, dado que las solicitudes GET transfieren datos en texto claro en la URL, no es adecuado para transferir datos binarios de gran tamaño. Porque la URL puede contener algunos caracteres especiales, como espacios, +, /, etc., que afectarán la integridad y corrección de los datos.
Las solicitudes GET no son adecuadas para transferir grandes cantidades de datos binarios, entonces, ¿qué pasa con la transferencia de una pequeña cantidad de datos binarios?
Si solo se necesita transferir una pequeña cantidad de datos binarios, se puede usar una solicitud GET. En este caso, los datos binarios se pueden convertir al formato de codificación de URL mediante la codificación de URL y luego se pueden agregar a la cadena de consulta de la URL.
3.2, URL HTTP
URL es Uniform Resource Locatorla abreviatura de URL, llamado Uniform Resource Locator, y así es como solemos llamar a la URL.
Cada archivo en Internet tiene una URL única, que contiene información de contenido que indica la ruta del archivo y cómo debe comportarse el navegador (es decir, cómo debe manejarse).
Las reglas detalladas de URL están estipuladas por el estándar de Internet RFC1738. (https://datatracker.ietf.org/doc/html/rfc1738)
Diagrama esquemático del formato de URL:

1) https: Nombre del esquema del protocolo, los comunes son http y https, y existen otros tipos, como los que se usan al acceder a mysql jdbc:mysql.
2) user:pass: información de inicio de sesión, la autenticación de identidad del sitio web actual generalmente ya no se realiza a través de la URL y generalmente se omite.
3) www.example.jp: dirección del servidor, aquí hay un "nombre de dominio", el nombre de dominio se resolverá en una dirección IP específica a través del sistema DNS, y la IP real se puede ver a través de ping命令.
4) 80: Número de puerto, utilizado para describir qué programa se utiliza, que se puede omitir. Cuando se omite el número de puerto, el navegador determinará automáticamente qué puerto usar según el tipo de protocolo.
- Por ejemplo, el protocolo http usa el puerto 80 de manera predeterminada y el protocolo https usa el puerto 443 de manera predeterminada.
5) /dir/index.html : Se puede omitir la ruta del archivo con jerarquía, utilizada para encontrar qué archivo en el directorio del programa.
6) ?userId=1 : cadena de consulta (query string), esencialmente una estructura de par clave-valor, los pares clave-valor están separados por &, y las claves y los valores están separados por =.
7) #ch1: identificador de fragmento, que se utiliza principalmente para realizar saltos en la página y se puede omitir.
Una URL específica:
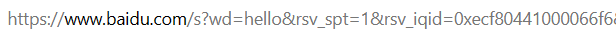
En la URL anterior, podemos ver que se omite cierta información en la URL, como la información de inicio de sesión, el número de puerto del servidor y el identificador de fragmento.
1. Dirección del servidor
La dirección del servidor también se denomina nombre de dominio, y este nombre de dominio se resolverá en una dirección IP específica a través del sistema DNS, y la IP real se puede ver a través de ping命令.
Expansión: use el comando ping para ver la dirección IP correspondiente al nombre de dominio
1) Ingrese cmd en el menú de inicio para abrir el símbolo del sistema.
2) Ingrese el nombre de dominio en el símbolo del sistema y podrá ver el resultado de la resolución del nombre de dominio.
2. Rutas de archivo jerárquicas
/Representa el directorio raíz, es decir, el directorio raíz del servidor HTTP, que puede ser cualquier directorio del sistema.
El servidor HTTP es un proceso en el sistema, y el servidor está encargado de administrar un directorio específico en el sistema, y se puede acceder a cualquier recurso en este directorio desde el exterior.
En términos generales, se proporcionan muchos recursos en un servidor HTTP y se pueden obtener diferentes recursos correspondientes a través de diferentes rutas jerárquicas.
3. Cadena de consulta (cadena de consulta)
El contenido de la cadena de consulta es una estructura de par clave-valor, y keyel valuevalor y la cantidad de sumas dependen completamente del programador.
En el proceso de desarrollo real, podemos usar este método para personalizar y transmitir la información que necesitamos al servidor.
Extensión: codificación de URL
Algunos caracteres de la URL tienen significados especiales. Por ejemplo, la URL ha interpretado caracteres como /, ?, etc. como significados especiales, por lo que estos caracteres no pueden aparecer de forma aleatoria.:
Pero, ¿qué debemos hacer si se requieren estos caracteres especiales en un parámetro? En este momento, primero debemos escapar de estos caracteres especiales.
Un carácter chino UTF-8o GBKun método de codificación de este tipo no tiene un significado especial en la URL, pero aun así debe escaparse; de lo contrario, el navegador puede considerar un determinado byte en UTF-8la codificación o GBK como un símbolo especial en la URL.
URL encodeLas reglas de escape son las siguientes: convierta el carácter a transcodificar en hexadecimal, luego tome 4 dígitos de derecha a izquierda (menos de 4 dígitos se procesan directamente), haga un dígito por cada 2 dígitos, agregue % al frente y codifíquelo en formato %XY.
uso de la herramienta de transcodificación 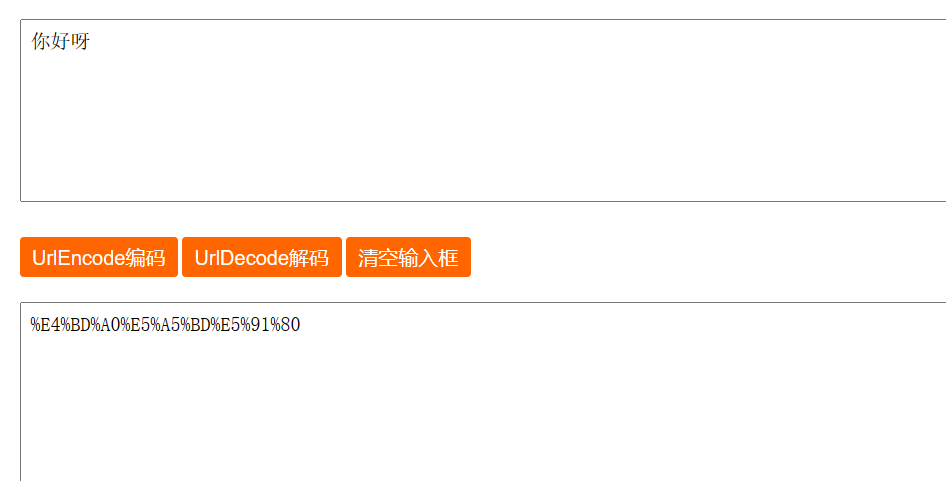
Expansión: la URL se puede omitir y las instrucciones de la nota
Las cuatro partes más críticas de la URL son la dirección IP, el número de puerto, la ruta del archivo jerárquico y la cadena de consulta.
El nombre del protocolo, la información de inicio de sesión, la dirección IP/nombre de dominio, el número de puerto, la ruta del archivo jerárquico, la cadena de consulta y el identificador de fragmento en la URL generalmente se pueden omitir.
Si se omite el nombre del protocolo, el valor predeterminado será http://, y si se omite el número de puerto, el navegador determinará automáticamente qué puerto usar de acuerdo con el tipo de protocolo.
Es equivalente a omitir la ruta del archivo con jerarquía /. Se accederá automáticamente a algunos servidores cuando se encuentre la ruta / /index.html.
En algunos casos, se puede omitir la dirección IP/nombre de dominio en la URL, por ejemplo:
- Al acceder a los recursos en el host local, puede omitir la dirección IP o el nombre de dominio y usar directamente localhost o 127.0.0.1 para acceder.
- Al acceder a otros recursos con el mismo nombre de dominio, puede omitir la dirección IP o el nombre de dominio y usar directamente la ruta relativa para acceder.
Sin embargo, en la mayoría de los casos, es mejor no omitir las direcciones IP o los nombres de dominio para mayor precisión y confiabilidad.
Nota: Las dos situaciones anteriores ocurren localmente o bajo el mismo nombre de dominio.Si ocurren entre diferentes servidores, la dirección IP/nombre de dominio no se puede omitir.
3.3, encabezado de solicitud
El encabezado de la solicitud se utiliza principalmente para transmitir información adicional al servidor, como el tipo de datos que el cliente puede recibir, el método de compresión, el idioma y la dirección URL de la página a la que pertenece el hipervínculo que envía la solicitud. Cuando el navegador realiza una solicitud al servidor, los encabezados de solicitud enviados son diferentes según los diferentes requisitos funcionales.
Cada encabezado de solicitud se compone del nombre y el valor del campo del encabezado. El nombre y el valor del campo del encabezado están separados por dos puntos, y cada encabezado de la solicitud termina con un símbolo de retorno de carro y salto de línea.
Debe tenerse en cuenta que los nombres de los campos de encabezado no distinguen entre mayúsculas y minúsculas, y es habitual escribir en mayúscula la primera letra de una palabra.
Campos de encabezado de solicitud de uso común:
1,Aceptar
El campo Aceptar se utiliza para indicar los tipos MIME (Extensiones multipropósito de correo de Internet) que el programa cliente (generalmente un navegador) puede manejar.
Ejemplo de uso: Si tanto el navegador como el servidor soportan imágenes de tipo PNG, el navegador puede enviar un
image/pngcampo de Aceptar incluido, cuando el servidor comprueba que la cabecera de Aceptar contieneimage/pngeste tipo MIME, se puede utilizar PNG en el elemento img de la web página tipo de archivo.Si hay un archivo de imagen que no es PNG, ¿cómo lo manejará el servidor? ¿Se convertirá el archivo? ¿O no lidiar con eso?
De hecho, el servidor no convertirá archivos, es decir, no convertirá imágenes que no sean PNG en tipos PNG. El servidor seleccionará el archivo apropiado para enviar al cliente de acuerdo con el tipo MIME especificado en el campo Aceptar. Si Si el cliente no puede manejar el tipo MIME, puede mostrar que el archivo no se puede abrir o descargar.
Los tipos MIME que se pueden utilizar como valor del campo Aceptar son los siguientes:
1) Accept:text/html: Indica que el cliente quiere recibir texto HTML
2) Accept:image/gif: indica que el cliente quiere recibir recursos en formato de imagen GIF
3) Accept:image/*: Indica que el cliente puede recibir todos los subtipos de formato de imagen
4) Accept:*/*: Indica que el cliente puede recibir contenido en todos los formatos
2, anfitrión
El campo Host se usa para especificar el número de host y el número de puerto donde se encuentra el recurso, y el contenido del valor puede ser el mismo que la URL o parte de la URL.
En HTTP1.1, cada mensaje de solicitud enviado por navegadores y otros clientes debe contener el campo de encabezado de solicitud de host, de modo que el servidor web pueda distinguir el sitio web virtual que el cliente desea visitar de acuerdo con el nombre de host en el campo de encabezado de host. Cuando un navegador accede a un sitio web, generará automáticamente el encabezado de solicitud de host correspondiente de acuerdo con la dirección URL en la barra de direcciones.
3,Contenido-Longitud,Tipo de contenido
Content-Length se usa para indicar la longitud de datos del cuerpo de la solicitud; Content-Type se usa para indicar el formato de datos del cuerpo de la solicitud.
La solicitud POST tiene una entidad de transmisión, por lo que hay un cuerpo de solicitud y los dos campos Content-Length y Content-Type existen en el encabezado de la solicitud.
Las solicitudes GET también pueden tener un cuerpo de solicitud, pero no se usa comúnmente. En este momento, también habrá dos campos, Content-Length y Content-Type, en el encabezado de la solicitud.
Content-Type no solo se usa para indicar el formato de datos del cuerpo de la solicitud, sino que también se usa para indicar el formato de datos del cuerpo de la respuesta.
Las opciones comunes de Content-Type son:
1) application/x-www-form-urlencoded: formulario El formato de datos presentado por el formulario.
El formato del cuerpo de la solicitud correspondiente es el siguiente:

2) multipart/form-data: formato de datos de envío del formulario, agregado en la etiqueta del formulario enctyped="multipart/form-data", generalmente utilizado para enviar imágenes/archivos.
El formato del cuerpo de la solicitud correspondiente es el siguiente:
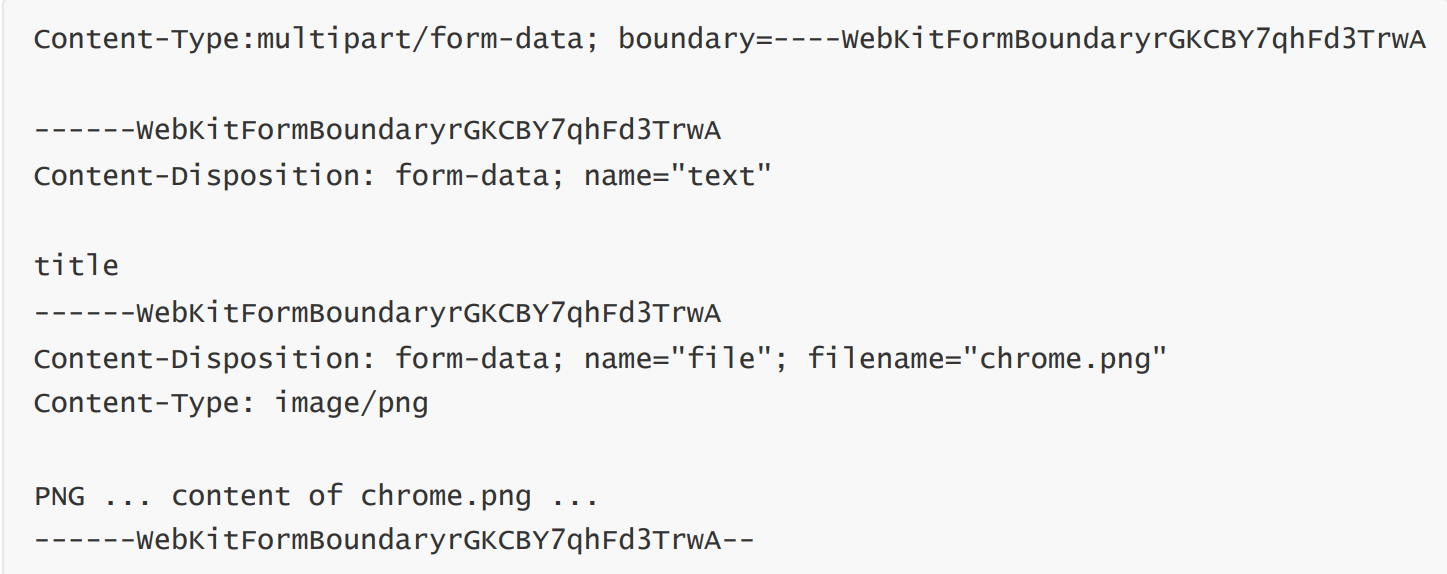
3) application/json: Los datos están en formato json.
El formato del cuerpo de la solicitud correspondiente es el siguiente:

4,Agente de usuario
El campo User-Agent se conoce como UA (User Agent), que se utiliza para describir el sistema operativo y la información de la versión, el navegador y la información de la versión, etc. utilizados por el navegador especificado u otros programas cliente.
El campo User-Agent permite que el servidor devuelva contenido diferente para diferentes tipos de navegadores. Por ejemplo, si el servidor verifica este campo y encuentra que el cliente es un terminal portátil inalámbrico, devuelve un documento WML, y si encuentra que el cliente es un navegador común, devuelve un documento HTML.

Entre ellos, Windows NT 10.0; Win64; x64representa información del sistema operativo y AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36representa información del navegador.
5, consulte
El campo Referer se utiliza para indicar desde qué página se redirigió esta página.
La solicitud enviada por el navegador al servidor se puede enviar directamente ingresando la URL en la barra de direcciones del navegador o haciendo clic en el enlace favorito, o haciendo clic en un hipervínculo en la página web.
La solicitud enviada a través del primer método no contiene el campo Referer, mientras que la solicitud enviada a través del segundo método contiene el campo Referer.
Los administradores de sitios web a menudo usan el campo Referer para rastrear cómo los visitantes del sitio web navegan en el sitio web, y también se puede usar como un enlace anti-leeech para el sitio web.
Expansión: hotlink y anti-hotlink
Hotlinking se refiere a mostrar algún contenido que no existe en su propio servidor en su propia página. Al usar etiquetas en archivos HTML para vincular a recursos en otros sitios web, puede obtener los recursos de otras personas y omitir las páginas de visualización de recursos de otras personas. , Mostrado directamente en su propia página para que los espectadores la vean. En general, los recursos como imágenes, música y videos están vinculados.
El hotlinking puede reducir la carga sobre su propio servidor, pero aumenta la carga sobre el servidor del sitio web con el hotlink y daña sus derechos e intereses legítimos. Entonces apareció la cadena antirrobo.
Para proteger sus propios recursos de ser hotlinked, el sitio web puede detectar de dónde proviene el enlace a la página o recurso actual a través del campo Referer. Una vez que se detecta que el acceso no es a través del enlace de este sitio, puede bloquear el acceso o saltar a la página especificada.
6, galleta
El campo Cookie se utiliza en el mensaje de solicitud HTTP para enviar información de Cookie al servidor. El formato del campo Cookie es: Cookie: nombre1=valor1; nombre2=valor2; nombre3=valor3.
¿Cuál es la información de las cookies? Cookie se refiere a un archivo de datos que el servidor del sitio web almacena en la computadora local del usuario a través del navegador del cliente. El navegador almacena la cookie en la computadora del usuario y la envía de regreso al servidor en solicitudes posteriores para rastrear al usuario. Actividad en el Sitio y almacenar las preferencias del usuario. Una cookie generalmente contiene un nombre, un valor y un tiempo de caducidad.Cuando un usuario visita un sitio web, el servidor leerá el archivo de la cookie para obtener información del usuario y brindar servicios personalizados.
El campo Cookie en el encabezado de solicitud contiene la información de Cookie ya almacenada por el cliente, y el campo Set-Cookie en el encabezado de respuesta se usa para enviar nueva información de Cookie al cliente.
Los campos específicos se describen a continuación:
- Cookie: Se utiliza para enviar la información de la cookie almacenada por el cliente al servidor en la solicitud HTTP, en el formato de "nombre=valor".
- Set-Cookie: Se utiliza para enviar nueva información de Cookie al cliente en la respuesta HTTP, el formato es "nombre=valor;".
3.4, cuerpo de la solicitud
El formato de contenido del cuerpo de la solicitud está estrechamente relacionado con el del encabezado de la solicitud Content-Type. Los formatos de contenido comunes del cuerpo son los siguientes:
1,application/x-www-form-urlencoded
application/x-www-form-urlencoded: formulario El formato de datos enviado por el formulario. El formato del cuerpo de la solicitud correspondiente es el siguiente:
2,multipart/form-data:
multipart/form-data: formato de datos de envío de formulario, agregado en la etiqueta del formulario enctyped="multipart/form-data", generalmente utilizado para enviar imágenes/archivos.
El formato del cuerpo de la solicitud correspondiente es el siguiente:
3)application/json
multipart/form-data: Los datos están en formato json. El formato del cuerpo de la solicitud correspondiente es el siguiente:
4. Respuesta HTTP
4.1, código de estado HTTP
El código de estado describe el resultado del estado de la respuesta HTTP, es decir, si la respuesta fue exitosa y el motivo del error.
Los códigos de estado HTTP se pueden dividir en cinco categorías, a saber, información, éxito, redirección, solicitud fallida y error del servidor.
1. Información, el código de estado significa que la solicitud ha sido aceptada y necesita ser procesada.
- Este tipo de respuesta es provisional, contiene solo una línea de estado y alguna información de encabezado de respuesta opcional, y termina con una línea en blanco.
2. Éxito, el código de estado significa que el servidor ha recibido, entendido y aceptado correctamente la solicitud.
3. Redirección, el código de estado significa que el cliente debe realizar más acciones para completar la solicitud.
- Por lo general, estos códigos de estado se utilizan para la redirección y la dirección de solicitud subsiguiente (objetivo de redirección) se especifica en el campo Ubicación de esta respuesta.
4. La solicitud falló y el código de estado indica que puede haber ocurrido un error en el lado del cliente, lo que dificultó el procesamiento del servidor.
- A menos que la respuesta sea una solicitud HEAD, el servidor DEBE devolver una entidad que explique la condición de error actual y si se trata de una condición temporal o permanente.
5. Error del servidor, el código de estado significa que el servidor tiene un error o un estado anormal al procesar la solicitud, o se da cuenta de que el procesamiento de la solicitud no se puede completar con los recursos de hardware y software actuales.
Tabla de códigos de estado HTTP:

Códigos de estado HTTP comunes:
1, 200 OK : Indica que la solicitud es exitosa y pertenece al estado normal.
2, 301 Movido permanentemente : Redirección permanente, utilizada para indicar que la URL solicitada se ha movido permanentemente a una nueva URL y no se puede restaurar a la dirección URL original en el futuro.
- Al recibir dicha respuesta, el cliente saltará automáticamente a la nueva dirección URL y todas las solicitudes de acceso posteriores se cambiarán automáticamente a la nueva dirección URL.
3, 302 Mover temporalmente : redirección temporal, que se utiliza para indicar que la URL solicitada se ha movido temporalmente a una nueva URL, pero puede volver a la dirección URL original en el futuro.
- Cuando el cliente acceda a la URL original, el servidor devolverá un código de estado 301 y una nueva dirección URL, y el cliente saltará automáticamente a la nueva dirección URL.
4, 403 Prohibido : el servidor deniega el acceso al recurso solicitado por el cliente porque el cliente no tiene permiso para acceder al recurso.
5, 404 No encontrado : el recurso solicitado por el cliente no existe en el servidor, generalmente porque la dirección URL solicitada por el cliente es incorrecta o el recurso se eliminó o movió.
6, 500 Error interno del servidor : se produjo un error interno mientras el servidor procesaba la solicitud del cliente, lo que impidió que el servidor completara la solicitud.
7, 504 Tiempo de espera de la puerta de enlace : cuando el cliente envía una solicitud al servidor, el servidor no responde después de un período de tiempo, lo que genera un error de tiempo de espera de la puerta de enlace.
Extensión: la diferencia esencial entre la redirección y el reenvío de solicitudes
La redirección y el reenvío de solicitudes son dos métodos de salto comúnmente utilizados en servidores web
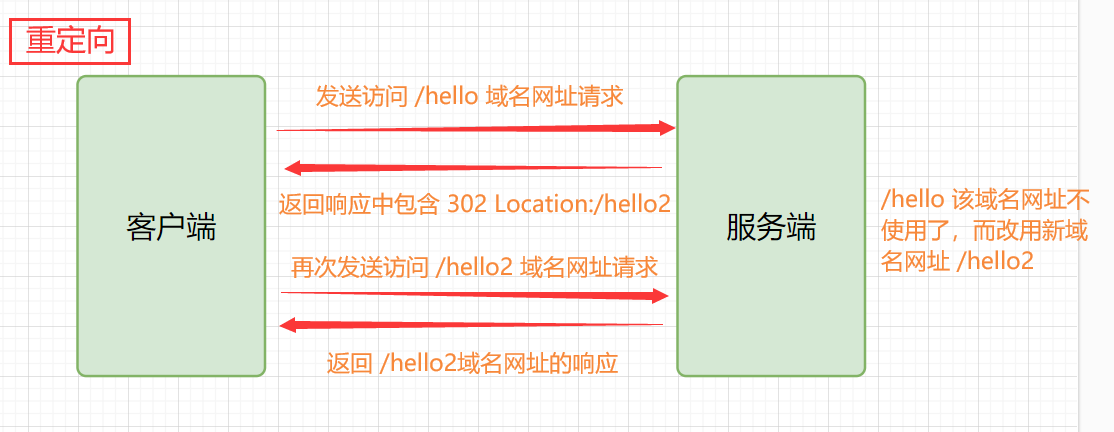
Redirección: Redirección significa que después de que el servidor recibe la solicitud del cliente, redirige la dirección del recurso solicitado a otra dirección. El cliente reiniciará una nueva solicitud para obtener nuevos recursos. Por lo tanto, la esencia de la redirección es una interacción entre el cliente y el servidor. El cliente necesita restablecer la conexión, es decir, el cliente necesita enviar dos solicitudes, por lo que la redirección aumentará la demora de la red y la carga del servidor.
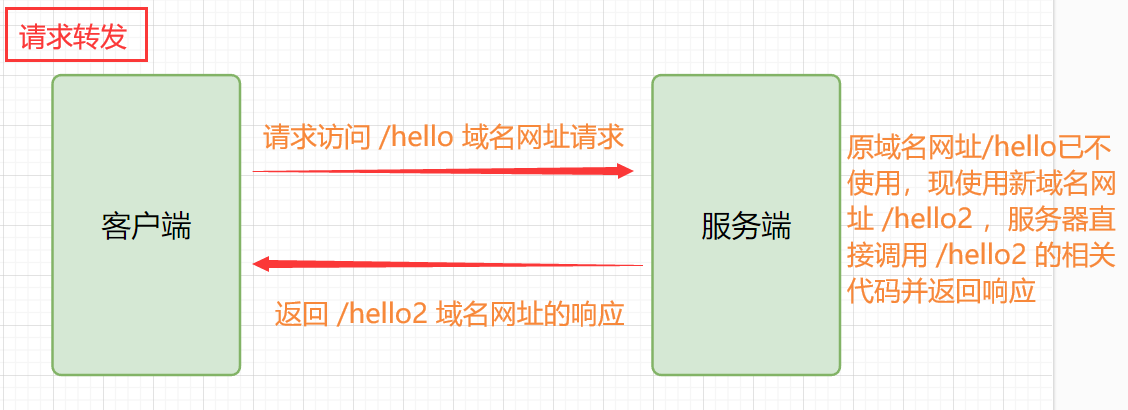
Reenvío de solicitudes: el reenvío de solicitudes significa que después de recibir una solicitud de un cliente, el servidor reenvía la solicitud a otra dirección y el servidor en otra dirección procesa la solicitud y devuelve el recurso. El cliente no sabe que la solicitud se reenvió a otro servidor. Por lo tanto, la esencia del reenvío de solicitudes es una interacción entre servidores, y el cliente solo necesita enviar una solicitud una vez, por lo que el reenvío de solicitudes reducirá la demora de la red y la carga del servidor.
En general, tanto la redirección como el reenvío de solicitudes pueden realizar la función de salto, pero la diferencia esencial entre ellos es si es necesario restablecer la conexión.
Si necesita saltar entre dominios o necesita reenviar la solicitud a un servidor diferente para su procesamiento, se recomienda utilizar el reenvío de solicitudes.
Si simplemente necesita redirigir la solicitud a otra dirección en el mismo servidor, se recomienda la redirección.
Redirigir el esquema real:
Solicitud para reenviar el esquema real:
4.2, encabezado de respuesta
El formato básico del encabezado de respuesta HTTP es básicamente el mismo que el del encabezado de solicitud, y los campos del encabezado también son básicamente los mismos.
Los valores comunes de Content-Type en la respuesta son los siguientes:
1. texto/html: el formato de datos del cuerpo es HTML
2. texto/css: el formato de datos del cuerpo es CSS
3. aplicación/javascript: el formato de datos del cuerpo es JavaScript
4. aplicación/json: el formato de datos del cuerpo es JSON
4.3, cuerpo de respuesta
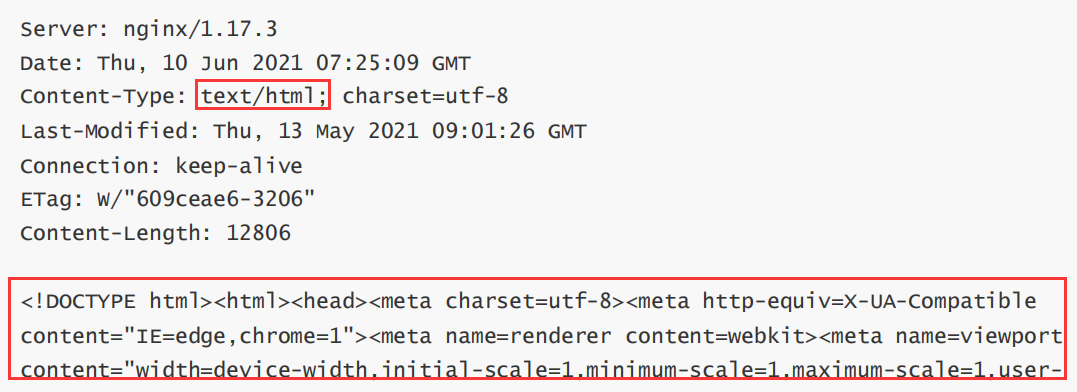
El formato de contenido del cuerpo de la respuesta está estrechamente relacionado con el encabezado de la respuesta Content-Type. Los formatos de contenido comunes del cuerpo son los siguientes:
1. texto/html: el formato de datos del cuerpo es HTML
2. texto/css: el formato de datos del cuerpo es CSS
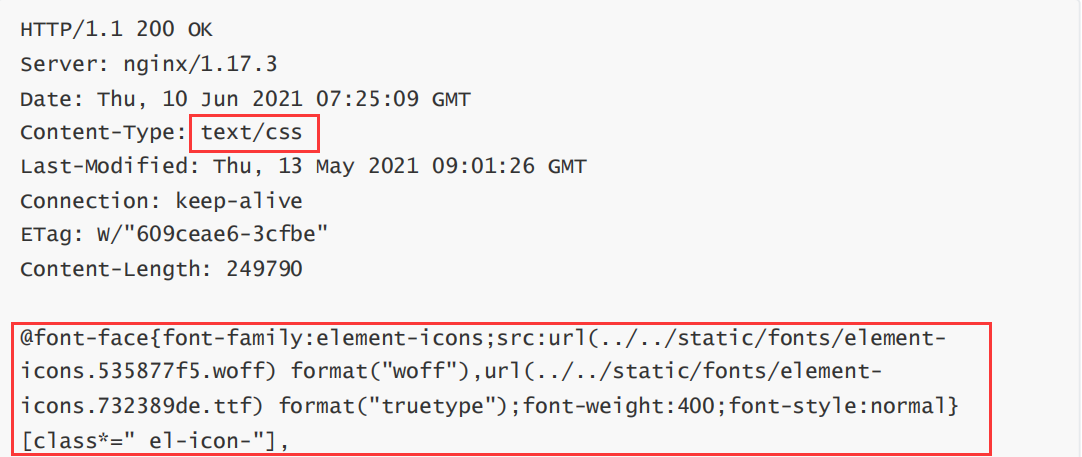
3. aplicación/javascript: el formato de datos del cuerpo es JavaScript
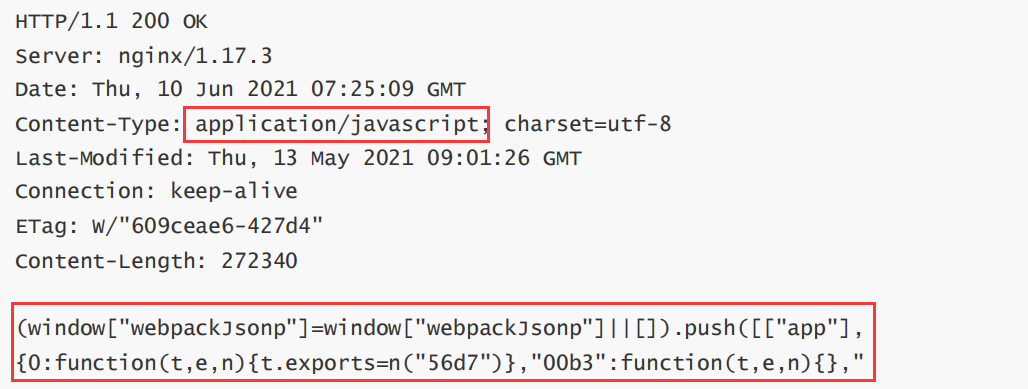
4. aplicación/json: el formato de datos del cuerpo es JSON
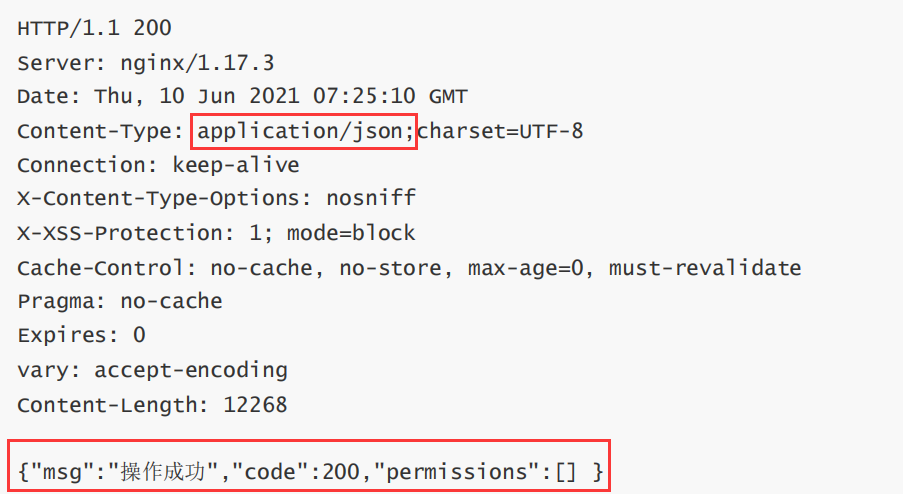
Resumir
Lo anterior es todo el contenido básico de HTTP, espero que pueda ser útil para todos. Si tiene algún problema que no se puede resolver, deje un mensaje en el área de comentarios o envíeme un mensaje privado. Si sientes que te es útil, puedes darle me gusta o prestar atención para alentar a los bloggers, lo haré cada vez mejor, gracias por tu apoyo, ¡nos vemos en el próximo número!
