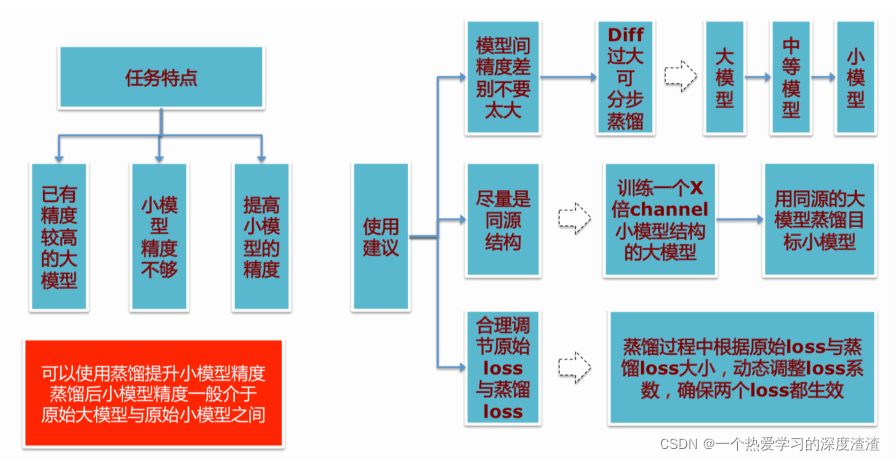
I. Resumen
En una frase : transfiera el poder predictivo de un modelo complejo a una red más pequeña;
(los modelos complejos se llaman modelos de maestros, los modelos más pequeños se llaman modelos de estudiantes)
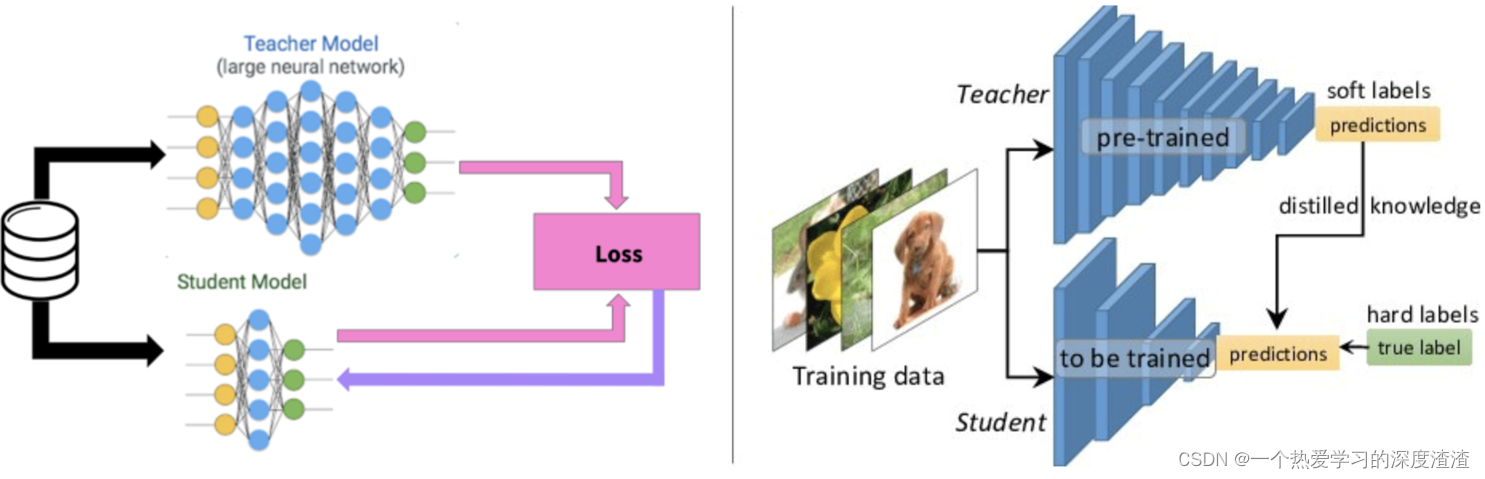
El concepto de Maestro y Alumno:
- "Destile" el conocimiento aprendido por la red grande y transfiéralo a la red pequeña, y el rendimiento de la red pequeña puede ser similar al de la red grande;
- El modelo de destilación (Estudiante) está entrenado para imitar la salida de la red grande (Profesor), en lugar de solo entrenar directamente en los datos originales. De esta manera, la red pequeña puede aprender la capacidad de característica abstracta y la capacidad de generalización de la red grande ;
En segundo lugar, el proceso detallado
método uno
El sencillo proceso es el siguiente:
1. Capacitar a una red de docentes sobre el conjunto de datos;
2. Formar una red de estudiantes para "imitar" a la red de profesores;
3. Deje que la red pequeña simule los logits de la red grande (siguiente explicación);
Ventajas: El profesor puede ayudar a filtrar algunas etiquetas de ruido Para los estudiantes, aprender un valor continuo es más eficiente que las etiquetas 0, 1, y la cantidad de información aprendida es mayor;
¿Qué significa logits?
Usar la probabilidad generada por el modelo grande como el "objetivo blando” del modelo pequeño puede transferir la capacidad de generalización del modelo grande al modelo pequeño. En esta etapa de transferencia, se puede usar el mismo conjunto de entrenamiento o un conjunto de datos separado para entrenar el modelo grande;
Cuando la entropía del objetivo suave es alta, puede proporcionar más información y menos variación de gradiente que los objetivos duros durante el entrenamiento, por lo que los modelos pequeños generalmente pueden usar menos muestras de entrenamiento y mayores tasas de aprendizaje;
Nota : el objetivo suave aquí representa un valor de probabilidad específico, y la salida de valores de 0 y 1 generalmente se denomina objetivo duro;
Veamos un diagrama de proceso de entrenamiento:
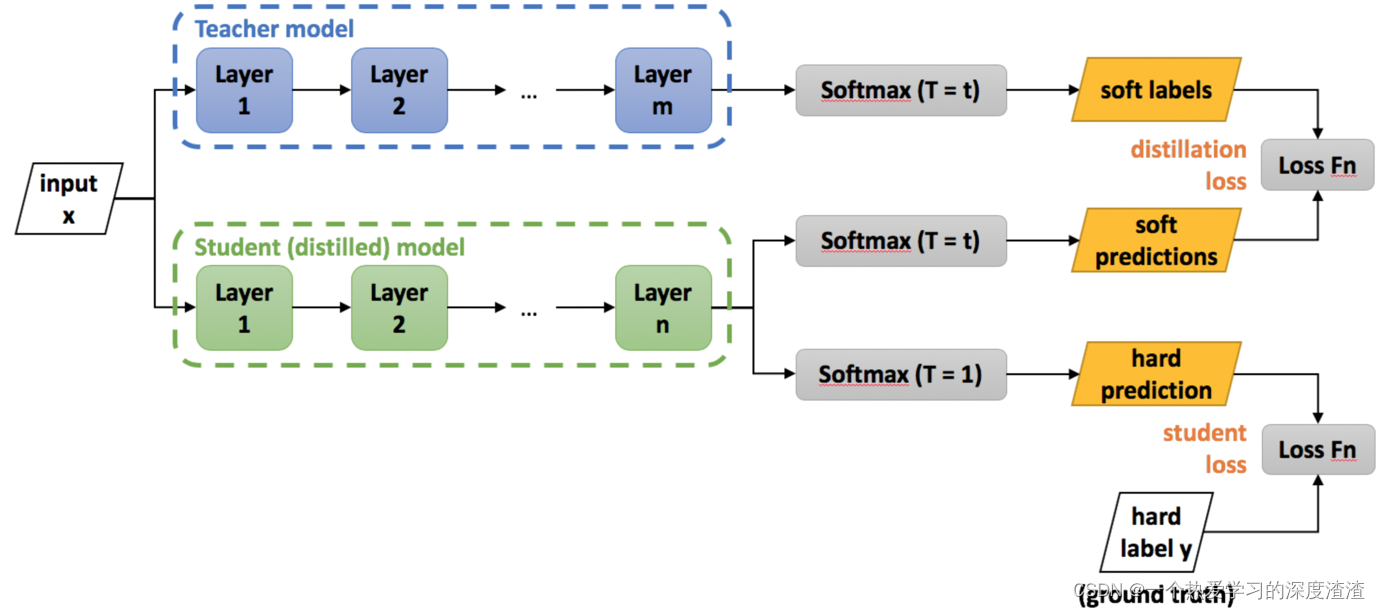
ilustrar:
1. La salida de la red del profesor se usa como la etiqueta flexible de la red del estudiante, es decir, la etiqueta flexible, y el valor de salida es un valor continuo;
2. La salida de la red de estudiantes tiene dos ramas, una es predicciones blandas y la otra es predicciones duras, donde duras significa etiquetas duras, y el valor de salida está en formato one-hot;
3. La pérdida final es la salida de la red de estudiantes y las etiquetas blandas de la red del maestro y las etiquetas duras reales para calcular el valor de pérdida y, finalmente, combinar los valores de pérdida de los dos;
Un truco sobre softmax:
Para la tarea de destilación del conocimiento, se mejora la fórmula de la función de salida softmax;
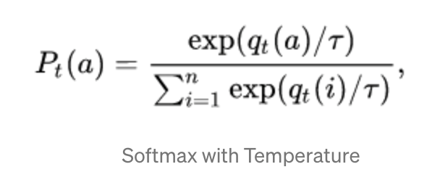
Explicación: Se agrega una variable de ponderación T. Cuando T es grande, la probabilidad de todas las categorías es casi la misma y la probabilidad será menor. Cuando T es pequeña, la probabilidad de la categoría con la mayor recompensa esperada se aproxima a 1; en el proceso de destilación, aumente el valor de T hasta que el modelo de maestro produzca un conjunto adecuado de objetivos suaves, y luego use el mismo valor de T para igualar estos objetivos suaves al entrenar el modelo de estudiante;
La siguiente figura es un ejemplo práctico:

Método dos
Redes de ajuste:
Principio: El alumno utiliza la información de la capa intermedia oculta del profesor para obtener un mejor rendimiento;
FitNets es una red de estudiantes, más estrecha pero más profunda que la red de profesores, que agrega una "capa de guía" a la red de estudiantes, es decir, aprende de una capa oculta en la red de profesores;
Echemos un vistazo al efecto del experimento:

3. Análisis de estado
1. La investigación sobre la destilación del conocimiento se ha vuelto extensa y específica en algunos campos, por lo que es difícil evaluar el rendimiento de generalización de un método;
2. A diferencia de otras técnicas de compresión de modelos, la destilación no necesita tener una estructura similar a la red original, lo que también significa que la extracción de conocimiento es muy flexible y teóricamente puede adaptarse a una amplia gama de tareas;
Análisis de ventajas y desventajas:
Ventajas: si hay una red de docentes bien capacitada, se requieren menos datos de capacitación para capacitar a una red de estudiantes más pequeña, y cuanto menos red, más rápida es la velocidad; no hay necesidad de mantener la unidad estructural entre las redes de maestros y estudiantes;
Desventajas: Si no hay una red de maestros pre-entrenados, se requiere un conjunto de datos más grande y más tiempo para la destilación;
4. Caso de código
En primer lugar, primero calculamos la media y la varianza del conjunto de datos, que también es un valor que se usa a menudo en Normal;
Ejemplo de código:
def get_mean_and_std(dataset):
"""计算数据集(训练集)的均值和标准差"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=2)
# 创建两个矩阵保存均值和标准差
mean = torch.zeros(3)
std = torch.zeros(3)
print('==> Computing mean and std..')
for inputs, targets in dataloader:
# 这里要注意是三个通道,所以要遍历三次
for i in range(3):
mean[i] += inputs[:, i, :, :].mean()
std[i] += inputs[:, i, :, :].std()
# 最后用得到的总和除以数据集数量即可
mean.div_(len(dataset))
std.div_(len(dataset))
return mean, std
El siguiente es un caso simple de destilación de conocimiento;
fondo:
modelo de profesor: VGG16;
Modelo de estudiante: un modelo personalizado, que reduce algunas capas en comparación con VGG16;
Conjunto de datos: conjunto de datos cifar10;
Los pasos de carga de los dos modelos durante el proceso de destilación no se muestran aquí, específicamente en la definición de la función de pérdida:
# 默认交叉熵损失
def _make_criterion(alpha=0.5, T=4.0, mode='cse'):
# targets为teacher网络的输出,labels为student网络的输出
def criterion(outputs, targets, labels):
# 根据传入模式用不同的损失函数
if mode == 'cse':
_p = F.log_softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = -torch.mean(torch.sum(_q * _p, dim=1))
elif mode == 'mse':
_p = F.softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = nn.MSELoss()(_p, _q) / 2
else:
raise NotImplementedError()
# 还原原始的soft_loss
_soft_loss = _soft_loss * T * T
# 用softmax交叉熵计算hard的loss值
_hard_loss = F.cross_entropy(outputs, labels)
# 将soft的loss值和hard的loss值加权相加
loss = alpha * _soft_loss + (1. - alpha) * _hard_loss
return loss
return criterion
El código anterior es la parte más importante de la destilación del conocimiento.
5. Expansión
Puede consultar los documentos de resumen de la destilación del conocimiento en los últimos años: Documentos
Resumir
Algunas sugerencias para usar la destilación de conocimiento: