Referencia:
https://zhuanlan.zhihu.com/p/642412124
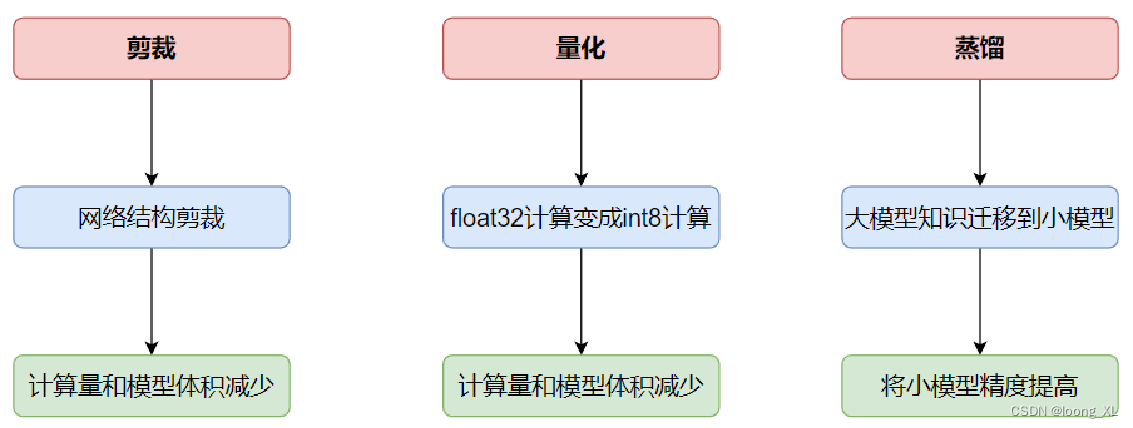
La compresión de modelos es una técnica para reducir la estructura y los parámetros de una red neuronal. El modelo comprimido
hace que su rendimiento sea similar al del modelo original, pero utiliza una pequeña cantidad de recursos informáticos; los comunes incluyen poda, cuantificación, destilación, búsqueda de estructuras neuronales (NAS), etc.
##模型压缩与工程部署关注的常用参数
1)模型大小
一般使用参数量parameter来衡量,单位是兆(M)
2)实时运行内存、模型计算量
就是模型实际运行时所占的内存资源消耗,单位是兆字节 (MB);模型计算量常见有FLOPs(浮点运算数)和MACs两种衡量的方式(MACs ≈ 2 * FLOPs)
3)模型推理响应时间、吞吐量QPS
响应时间是指模型对请求作出响应的时间,单位一般是毫秒(MS);吞吐量是指模型在单位时间内处理请求的数量
1. Cortar
Código de referencia: https://pytorch.org/tutorials/intermediate/pruning_tutorial.html
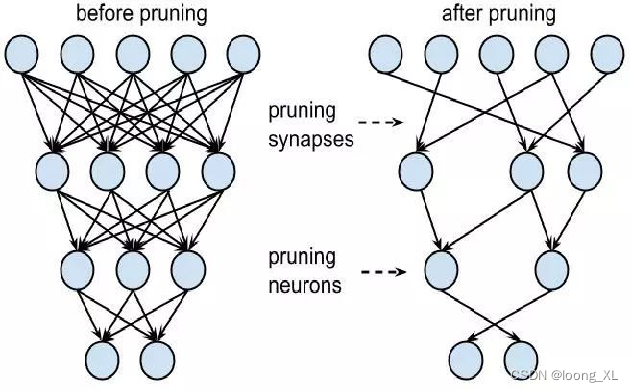
1)结构化的剪枝
神经元剪枝pruning neurons,注意剪枝力度有点大,会对模型精度产生较大的影响
2)非结构化的剪枝
突出剪枝pruning synapses,精度的损失就会小一些,但最终产生的是稀疏矩阵
2. Cuantificación
La cuantificación se refiere al proceso de aproximación de valores continuos (o un gran número de posibles valores discretos) de una señal a un número finito (o menos) de valores discretos. Generalmente, los valores o pesos de activación de punto flotante (generalmente expresados como números de punto flotante de 32 bits) se aproximan como enteros de bits bajos (8 bits)
1) Menos gastos generales de almacenamiento y requisitos de ancho de banda
2) Velocidad de cálculo más rápida
3) Menor consumo de energía y área ocupada
4) Pérdida de precisión aceptable
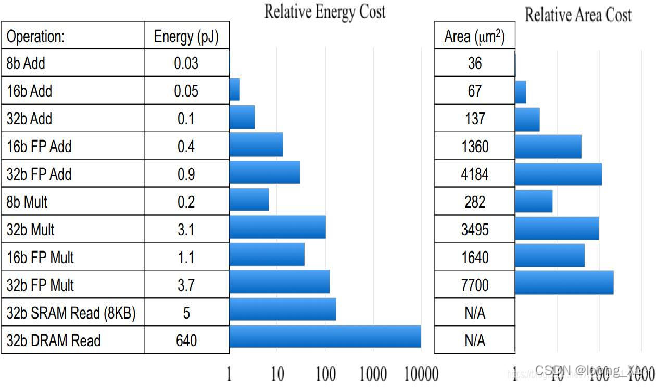
Como se muestra en la figura anterior, el consumo de energía de la multiplicación FP32 es 18,5 veces mayor que el de la multiplicación INT8, y
la huella del chip es 27,3 veces mayor que la de int8
Métodos de cuantificación del modelo
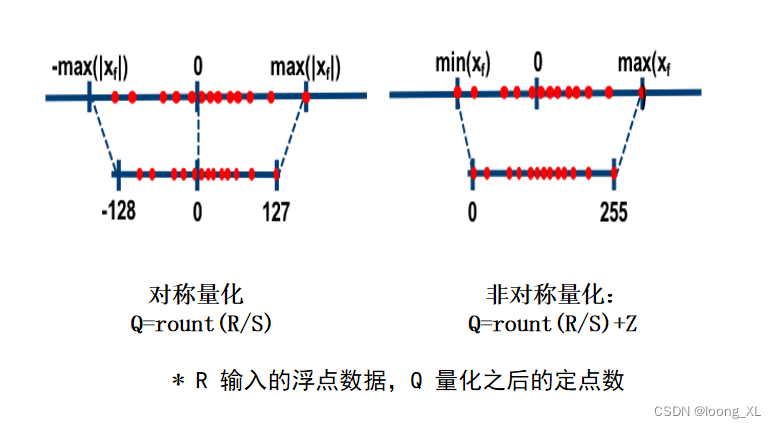
1) Cuantificación lineal
对称量化
非对称量化
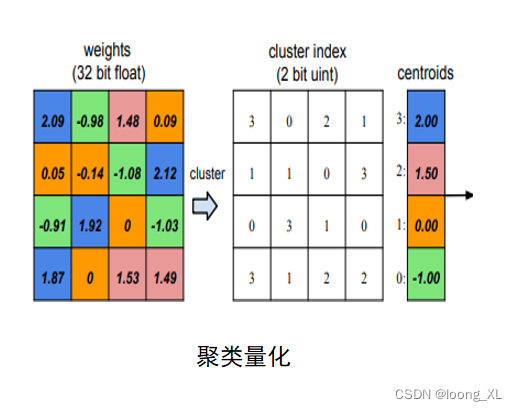
2) Cuantificación no lineal
非线性函数
聚类、对数
3) Binarización de 1 bit, ternaria de 2 bits, etc.
4) Cuantificación de precisión mixta
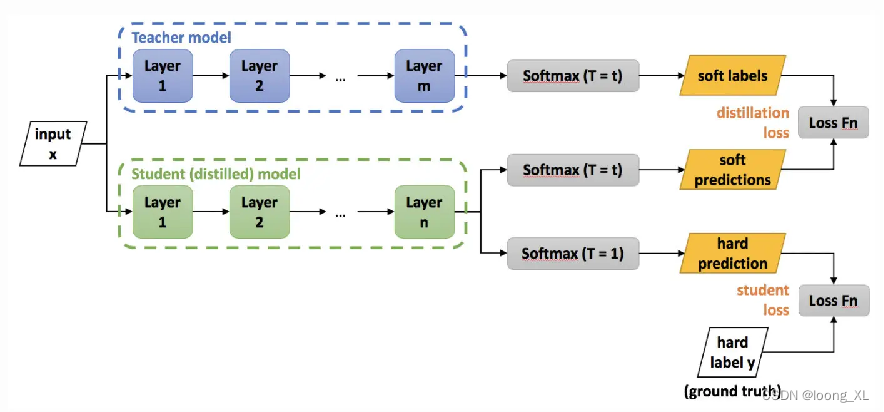
3. Destilación
Código de referencia: https://github.com/airaria/TextBrewer
La destilación del conocimiento, conocida como KD, como su nombre indica, consiste en extraer el conocimiento ("Conocimiento") contenido en el modelo entrenado (red de profesores), destilación ("Destilar") en otro modelo pequeño (red de estudiantes)
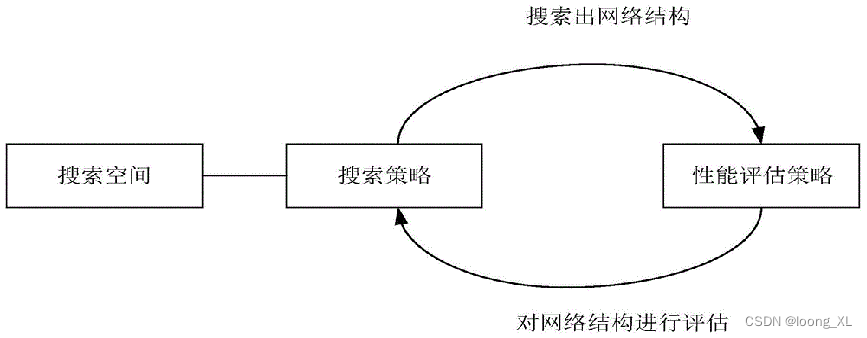
4. Búsqueda de arquitectura neuronal
Código de referencia: https://github.com/awslabs/autogluon
Búsqueda de arquitectura neuronal (Búsqueda de arquitectura neuronal, NAS) se refiere a una estructura de red neuronal candidata llamada espacio de búsqueda, un conjunto de componentes (bloques), a través del controlador para buscar la estructura de subred del conjunto de acuerdo con una determinada búsqueda. estrategia de algoritmo, y Utilice una estrategia de evaluación del rendimiento para evaluar el rendimiento; es un tipo de aprendizaje automático automático (AutoML); como EfficientNet (Google), RegNet (Facebook) y otros modelos