contenido
¿Qué es opencv?
- OpenCV (Biblioteca de visión artificial de código abierto) es una biblioteca de visión artificial y aprendizaje automático de código abierto que proporciona interfaces como C++, C y python, y es compatible con las plataformas Windows, Linux, Android y MacOS.
- Después de 2016, la aplicación del aprendizaje profundo se ha vuelto cada vez más extensa, y también se han agregado módulos como CNN a OpenCV, que se pueden conectar con los modelos entrenados por Tensorflow y Caffe2.
Fundamentos de digitalización de imágenes
Una imagen se compone de innumerables cuadrados pequeños.
Imágenes en color : se componen de pequeños cuadrados de colores , cada cuadrado de color está cuantificado por un vector de tres valores . (0, 0, 0) representa el negro, (255, 255, 255) representa el blanco y (255, 0, 0) representa el rojo.
Imagen gris : se compone de pequeños cuadrados grises , cada uno de los cuales está cuantificado por un vector de valores numéricos .

Una matriz numérica bidimensional con 508 filas (alto) y 672 columnas (ancho).
La computadora digitalizará cada píxel en un valor numérico. La "profundidad de bits" de la imagen en escala de grises es de 8 bits (el color es de 24 bits), lo que significa que cada cuadrado se digitaliza en un número de tipo uchar entre [0, 255], que Se utilizan 256 números para medir el tono de gris, cuanto mayor sea el valor, más brillante será el valor, cuanto menor sea el valor, más gris, 255 es blanco y 0 es negro.
adquisición de imágen
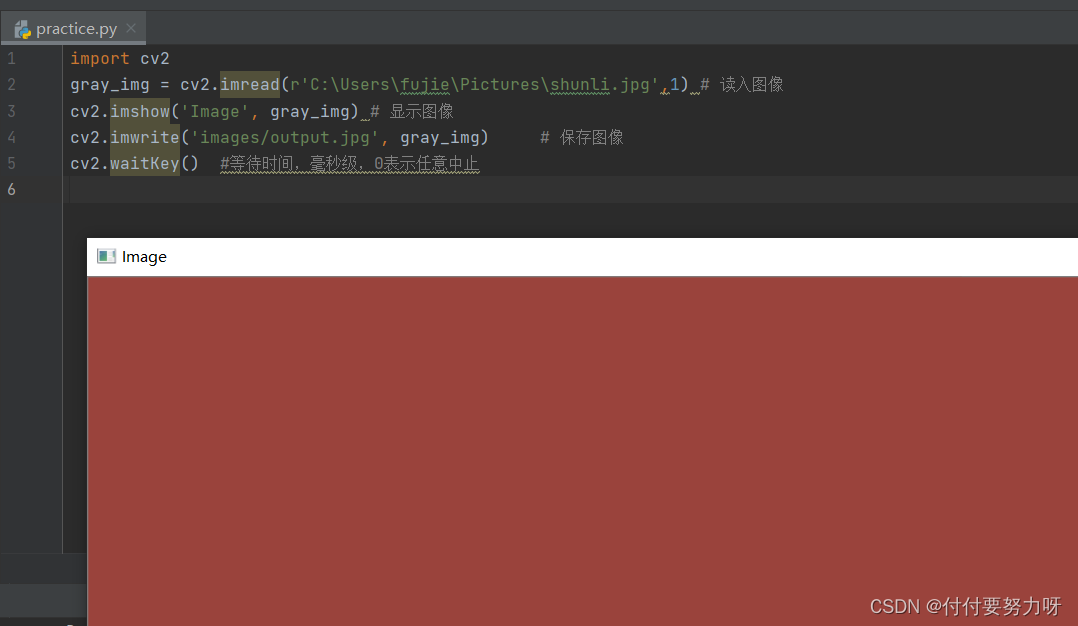
import cv2
gray_img = cv2.imread(r'C:\Users\fujie\Pictures\shunli.jpg',1) # 读入图像
cv2.imshow('Image', gray_img) # 显示图像
cv2.imwrite('images/output.jpg', gray_img) # 保存图像
cv2.waitKey() #等待时间,毫秒级,0表示任意中止
transformación de imagen
La realización de algunas operaciones en las imágenes se puede considerar como un medio de expansión de la imagen .
- El propósito de la mejora de la imagen es mejorar el efecto visual de la imagen. Para la aplicación de una imagen determinada, mejore deliberadamente las características generales o locales de la imagen, aclare la imagen original poco clara o mejore algunas características interesantes, amplíe la imagen. La diferencia entre las características de diferentes objetos en la imagen, suprime las características poco interesantes, mejora la calidad de la imagen, enriquece la cantidad de información, interpreta y reconoce la imagen fuerte y satisface las necesidades de algunos análisis de características.
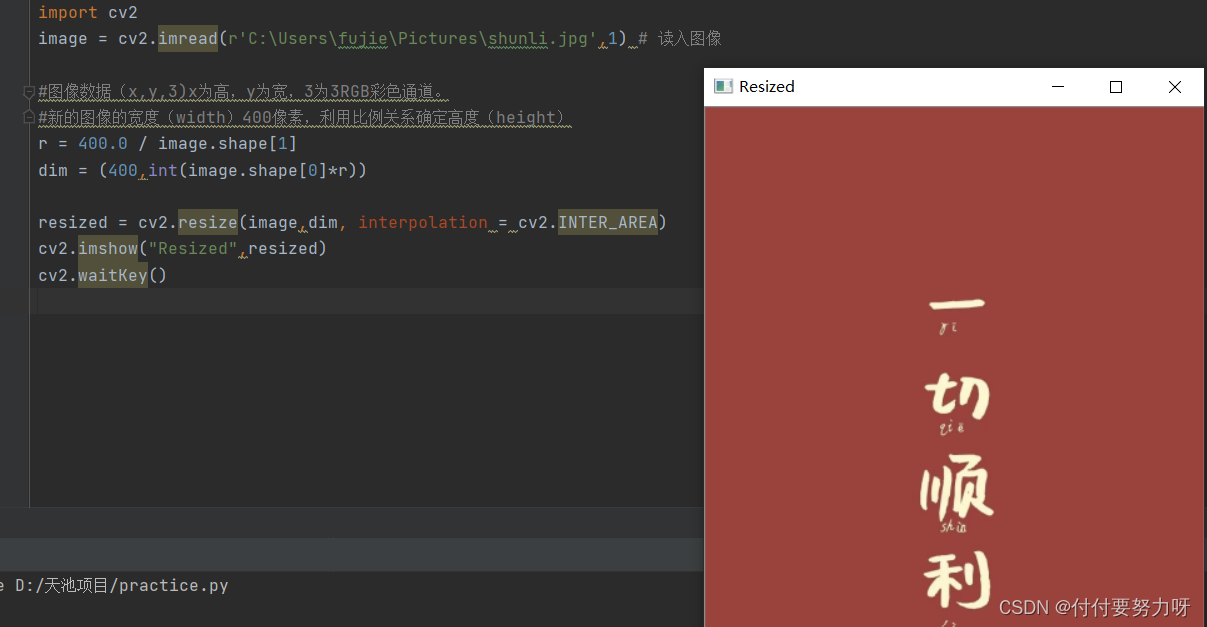
cambiar tamaño
(x,y,3)
fila x - altura
columna y - ancho
Análisis de contenido de reconocimiento de matrículas
- La tecnología de reconocimiento automático de matrículas es conectar el método de procesamiento de imágenes con la tecnología de software de la computadora , para reconocer con precisión los caracteres de la matrícula y transmitir los datos reconocidos al sistema de gestión de tráfico en tiempo real, por lo que como para finalmente realizar la supervisión del tráfico.
- la placa del auto de mi país generalmente se compone de siete caracteres y un punto.
El reconocimiento de matrículas se divide aproximadamente en cuatro partes: adquisición de imágenes (obtención de la información de la imagen del vehículo del sensor visual) - localización de la matrícula (encontrar la posición de la matrícula a partir de la imagen original) - segmentación de caracteres (segmentación de la matrícula matrícula en siete caracteres) Se utiliza para el reconocimiento de caracteres posterior) - reconocimiento de caracteres (reconocer los caracteres individuales separados para identificar el valor de la matrícula)
Localiza la matrícula
Encuentre la ubicación de la matrícula (ubique el área) de la imagen adquirida y segmente la matrícula de esta área para la posterior segmentación de caracteres.
Hay cuatro tipos principales de métodos de posicionamiento de matrículas:
- Segmentación basada en colores: utilice la información del espacio de color, incluido el algoritmo de borde de color, el algoritmo de distancia de color y el algoritmo de similitud.
- Segmentación basada en texturas: por ejemplo, usar las funciones de textura en la dirección horizontal del área de la placa de matrícula para realizar la segmentación, incluida la textura wavelet y la textura de diferencia de gradiente horizontal.
- Segmentación basada en detección de bordes
- Segmentación Basada en Morfología Matemática
Reducción de ruido de imagen
Para adquirir una imagen, la imagen original es a color y se convierte en una imagen en escala de grises para su posterior procesamiento.

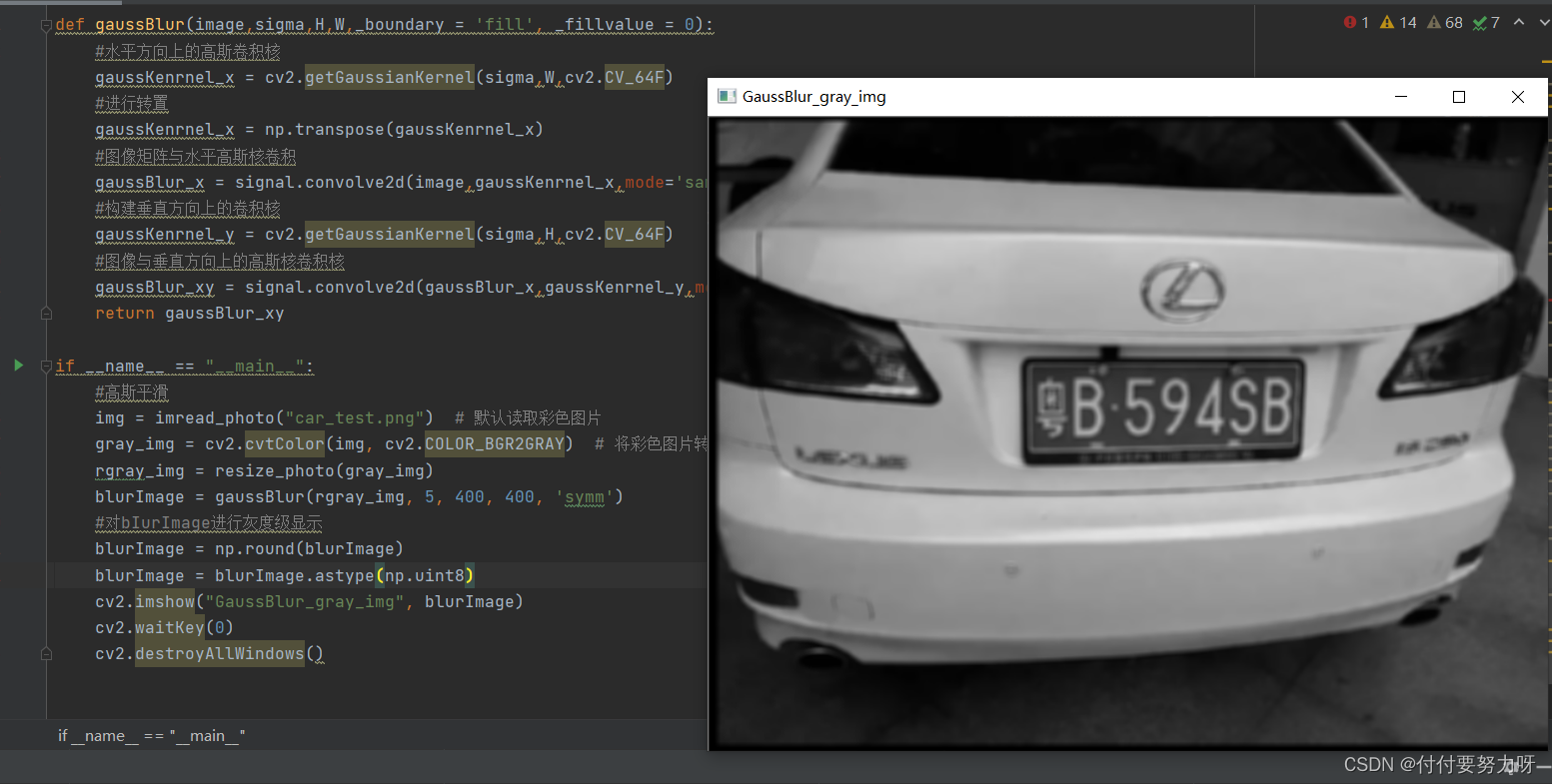
La imagen original contiene información de ruido. El ruido puede entenderse como cambios aleatorios en los valores de la escala de grises causados por uno o más motivos. En la mayoría de los casos, se requieren técnicas de suavizado (filtrado) para eliminarlos. Los algoritmos de suavizado comúnmente utilizados incluyen el suavizado gaussiano y el suavizado medio basado en una convolución discreta bidimensional. . . Esta operación utiliza el método de suavizado gaussiano.
Filtrado gaussiano : si el valor de un píxel es mucho más alto que los puntos circundantes, puede ser un ruido o un borde de alta frecuencia.El filtrado gaussiano utiliza múltiples puntos alrededor del punto para hacer un promedio ponderado de ellos, lo que equivale a usar el valor circundante para reducir este valor alto, lo que se denomina suavizado. La realización matemática del filtrado gaussiano es la operación de reasignar los valores de píxel de toda la imagen mediante un promedio ponderado. (El promedio ponderado puede entenderse como el resultado de calcular y sumar diferentes partes según diferentes proporciones).
Enlace de detalles
- La imagen resultante está ligeramente borrosa en comparación con la original. De esta forma, un solo píxel se vuelve casi insignificante en la imagen suavizada gaussiana.
- Suavizado gaussiano de OpenCV:
el suavizado gaussiano se realiza mediante una operación de convolución discreta bidimensional entre dos matrices, y el kernel de convolución gaussiana se convoluciona con la imagen original.


- circunvolución:

- La función para construir un kernel de convolución gaussiana en dirección vertical unidimensional se proporciona en OpenCV: Mat getGaussianKernel(int ksize, double sigma, in ktype = CV/_64F)
Procesamiento morfológico
El procesamiento morfológico se utiliza principalmente para extraer componentes de la imagen que son significativos para expresar y describir la forma de la región de la imagen, de modo que el trabajo de reconocimiento posterior pueda capturar las características de forma más esenciales (más discriminatorias) del objeto de destino, como los límites. y formas áreas conectadas, etc. Al mismo tiempo, técnicas como el adelgazamiento, la pixelación y el recorte de rebabas se utilizan a menudo en el preprocesamiento y posprocesamiento de imágenes, convirtiéndose en un poderoso complemento para las técnicas de mejora de imágenes.
Operaciones básicas de procesamiento morfológico: erosión, expansión, operación de apertura, operación de cierre, golpe y error, extracción de esqueleto, etc. Por ejemplo, la erosión hace que las áreas oscuras sean más grandes y la dilatación hace que las áreas brillantes sean más grandes.

Realice la operación de apertura ( la operación de apertura puede suavizar el contorno de la imagen y también puede desconectar las conexiones estrechas y eliminar las rebabas finas . Esta operación allana el camino para una extracción más precisa del contorno de la matrícula más adelante):
Enlace de detalles de la operación
abierta La operación abierta es principalmente en blanco y negro, y el área negra se vuelve más grande. Eliminar puntos de información inútiles.
La operación cerrada es principalmente para comer negro gratis, y el área blanca se vuelve más grande. Aumente el área de resaltado blanco.

Combine la imagen original en escala de grises y la imagen morfológica en una sola imagen para operaciones de segmentación de umbral posteriores:
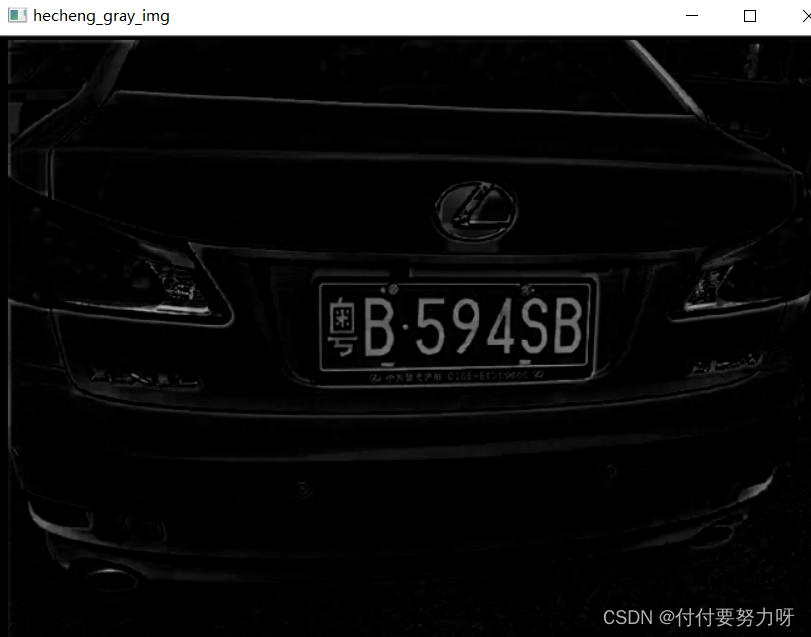
Segmentación de umbral + detección de bordes
La segmentación por umbral es un algoritmo común para segmentar imágenes directamente y depende del valor de gris de los píxeles de la imagen. Correspondiente a una sola imagen objetivo, solo se puede seleccionar un umbral para dividir la imagen en dos categorías: objetivo y fondo. Esto se denomina segmentación de umbral único; si la imagen objetivo es compleja, se pueden seleccionar múltiples umbrales para separar el área objetivo. y fondo en la imagen. Se divide en varias piezas, lo que se denomina segmentación de umbral múltiple. En este momento, también es necesario distinguir los objetivos de la imagen en los resultados de detección e identificar de forma única cada área objetivo de la imagen para distinguir.
Mediante la umbralización, esperamos poder separar nuestro objeto de investigación del fondo. La imagen se divide en varias regiones específicas con propiedades únicas, cada región representa una colección de píxeles y cada colección representa un objeto.
Uso del procesamiento de umbral de Ostu : al usar la función cv.threshold() para el procesamiento de umbral, debe personalizar un umbral y utilizar este umbral como base para el procesamiento de umbral de imagen. OTSU puede ayudarnos a atravesar todos los umbrales posibles para encontrar el mejor.
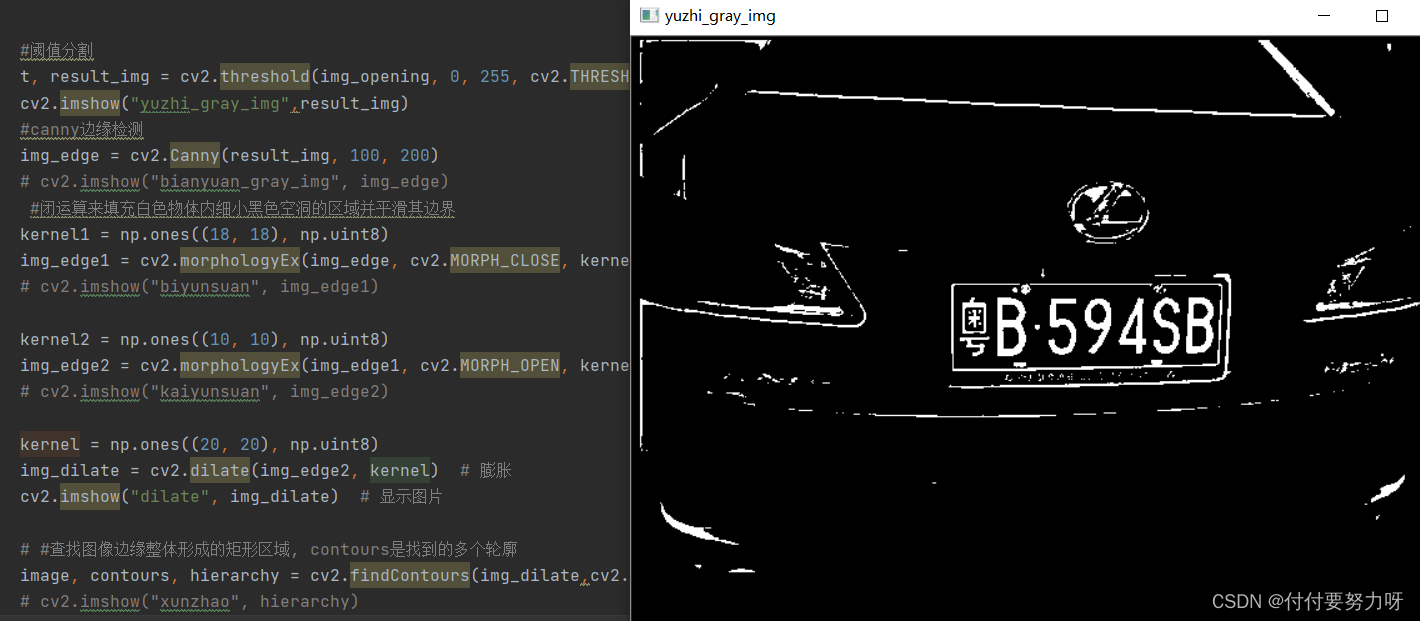
Realice un suavizado de ejecución cerrada (sin detección de bordes después de la segmentación del umbral)
Agregue la detección de bordes después de la segmentación del umbral: (use la detección de bordes astutos aquí)

y luego realice una operación de cierre para aumentar el área resaltada en blanco:

realice una operación de apertura para eliminar la parte blanca inútil y llene el espacio:

finalmente, realice una expansión para llenar el espacio nuevamente y aumente la parte blanca resaltada:

cada contorno puede considerarse como un conjunto ordenado de puntos (píxeles), y ahora queremos extraer los contornos de estas áreas blancas. (dibuje la imagen original con el contorno)

Ahora que tenemos el contorno, debemos filtrar el contorno donde se encuentra la placa (puede ver que el área donde se encuentra la placa es un rectángulo), ya que la proporción de la placa se fija el ancho y la altura (la placa La altura y el ancho de los caracteres son fijos, 90 mm y 45 mm respectivamente), de acuerdo con esta característica geométrica, filtramos y luego usamos las líneas verdes para seleccionar la placa obtenida marco, y al mismo tiempo interceptar la matrícula para la siguiente segmentación de caracteres. .
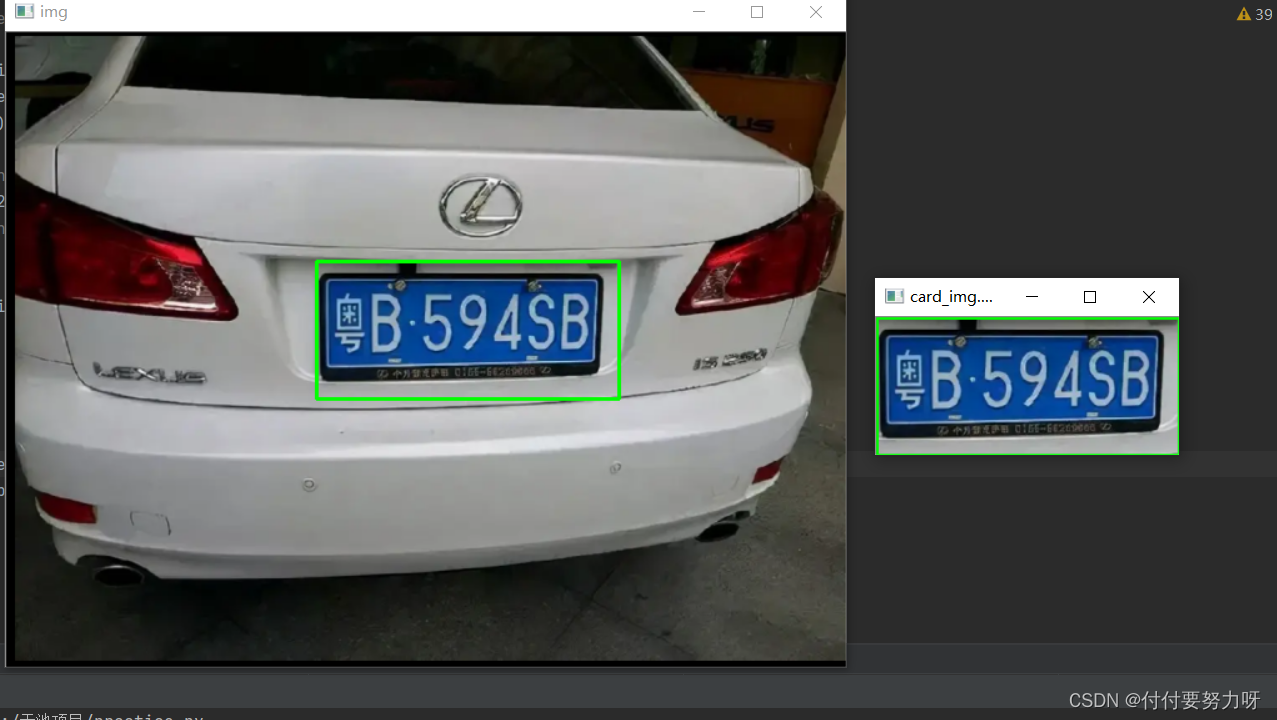
Localiza el código completo de la matrícula:
import cv2
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
#########该函数能够读取磁盘中的图片文件,默认以彩色图像的方式进行读取
def imread_photo(filename, flags=cv2.IMREAD_COLOR):
return cv2.imread(filename, flags)
##############这个函数的作用就是来调整图像的尺寸大小,当输入图像尺寸的宽度大于阈值(默认1000),我们会将图像按比例缩小#######
def resize_photo(imgArr,MAX_WIDTH = 1000):
img = imgArr
rows, cols= img.shape[:2] #获取输入图像的高和宽即第0列和第1列
if cols > MAX_WIDTH:
change_rate = MAX_WIDTH / cols
img = cv2.resize(img ,( MAX_WIDTH ,int(rows * change_rate) ), interpolation = cv2.INTER_AREA)
return img
# ################高斯平滑###############
#我们首先会对图像水平方向进行卷积,然后再对垂直方向进行卷积,其中sigma代表高斯卷积核的标准差
def gaussBlur(image,sigma,H,W,_boundary = 'fill', _fillvalue = 0):
#水平方向上的高斯卷积核
gaussKenrnel_x = cv2.getGaussianKernel(sigma,W,cv2.CV_64F)
#进行转置
gaussKenrnel_x = np.transpose(gaussKenrnel_x)
#图像矩阵与水平高斯核卷积
gaussBlur_x = signal.convolve2d(image,gaussKenrnel_x,mode='same',boundary=_boundary,fillvalue=_fillvalue)
#构建垂直方向上的卷积核
gaussKenrnel_y = cv2.getGaussianKernel(sigma,H,cv2.CV_64F)
#图像与垂直方向上的高斯核卷积核
gaussBlur_xy = signal.convolve2d(gaussBlur_x,gaussKenrnel_y,mode='same',boundary= _boundary,fillvalue=_fillvalue)
return gaussBlur_xy
def chose_licence_plate(contours, Min_Area=2000):
temp_contours = []
for contour in contours:
if cv2.contourArea(contour) > Min_Area:
temp_contours.append(contour)
car_plate = []
for temp_contour in temp_contours:
rect_tupple = cv2.minAreaRect(temp_contour)
rect_width, rect_height = rect_tupple[1]
if rect_width < rect_height:
rect_width, rect_height = rect_height, rect_width
aspect_ratio = rect_width / rect_height
# 车牌正常情况下宽高比在2 - 5.5之间
if aspect_ratio > 2 and aspect_ratio < 5.5:
car_plate.append(temp_contour)
rect_vertices = cv2.boxPoints(rect_tupple)
rect_vertices = np.int0(rect_vertices)
return car_plate
def license_segment( car_plates ):
if len(car_plates)==1:
for car_plate in car_plates:
row_min,col_min = np.min(car_plate[:,0,:],axis=0)
row_max, col_max = np.max(car_plate[:, 0, :], axis=0)
cv2.rectangle(img, (row_min,col_min), (row_max, col_max), (0,255,0), 2)
card_img = img[col_min:col_max,row_min:row_max,:]
cv2.imshow("img", img)
cv2.imwrite( "card_img.png", card_img)
cv2.imshow("card_img.png", card_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
return "card_img.png"
if __name__ == "__main__":
img = imread_photo("car_test.png") # 默认读取彩色图片
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将彩色图片转换为灰色图片,灰色图像更便于后续处理。
rgray_img = resize_photo(gray_img)
# 高斯平滑
blurImage = gaussBlur(gray_img, 5, 400, 400, 'symm')
#对bIurImage进行灰度级显示
blurImage = np.round(blurImage)
blurImage = blurImage.astype(np.uint8)
kernel = np.ones((10, 10), np.uint8)
#开运算
img_opening = cv2.morphologyEx(blurImage, cv2.MORPH_OPEN, kernel)
# cv2.imshow("GaussBlur_gray_img", blurImage)
# cv2.imshow("xingtai_gray_img", img_opening)
#将两幅图像合成为一幅图像
img_opening = cv2.addWeighted(rgray_img, 1, img_opening, -1, 0)
# cv2.imshow("hecheng_gray_img", img_opening)
#阈值分割
t, result_img = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# cv2.imshow("yuzhi_gray_img",result_img)
#canny边缘检测
img_edge = cv2.Canny(result_img, 100, 200)
# cv2.imshow("bianyuan_gray_img", img_edge)
#闭运算来填充白色物体内细小黑色空洞的区域并平滑其边界
kernel1 = np.ones((18, 18), np.uint8)
img_edge1 = cv2.morphologyEx(img_edge, cv2.MORPH_CLOSE, kernel1)
# cv2.imshow("biyunsuan", img_edge1)
kernel2 = np.ones((10, 10), np.uint8)
img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel2)
# cv2.imshow("kaiyunsuan", img_edge2)
kernel = np.ones((20, 20), np.uint8)
img_dilate = cv2.dilate(img_edge2, kernel) # 膨胀
cv2.imshow("dilate", img_dilate) # 显示图片
# #查找图像边缘整体形成的矩形区域, contours是找到的多个轮廓
image, contours, hierarchy = cv2.findContours(img_dilate,cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# cv2.imshow("xunzhao", hierarchy)
draw_img = img.copy()
result = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
# 画出带有轮廓的原始图片
cv2.imshow('ret',result)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
car_plates = chose_licence_plate(contours)
card_img = license_segment(car_plates)