El conocimiento científico
ICML es la abreviatura de Conferencia Internacional sobre Aprendizaje Automático, la Conferencia Internacional sobre Aprendizaje Automático. ICML ahora se ha convertido en una importante conferencia internacional anual sobre aprendizaje automático organizada por la Sociedad Internacional de Aprendizaje Automático (IMLS).

# Prefacio
SEP.
En el último artículo de teoría del aprendizaje profundo, aprendimos una red representativa profunda: GoogLeNet en un momento, que construyó una red más profunda a través del módulo Inception propuesto. Hoy, entraremos en la red más representativa de la red profunda de aprendizaje profundo: la red ResNet. ¿En qué se diferencia de la estructura de red anterior? ¿Y por qué se propone la red? Consulte el desglose a continuación.

Red ResNet

El título de este documento compartido es: aprendizaje residual profundo para el reconocimiento de imágenes, el título traducido significa: aprendizaje residual profundo para el reconocimiento de imágenes. Tan pronto como se propuso la red, actualizó por completo la cognición de la red profunda en el campo de la visión por computadora, y luego derivó múltiples variantes de la red residual en muchos campos, y su influencia de gran alcance ha continuado hasta el día de hoy. un poco exagerado Se dice que en el campo del reconocimiento de imágenes solo se conoce la red residual, pero no otras redes, aunque es un poco exagerado, refleja que la red residual es popular entre los investigadores.
Captura de pantalla del papel:

Dirección en papel: https://arxiv.org/pdf/1512.03385.pdf
1. El porqué de la red residual

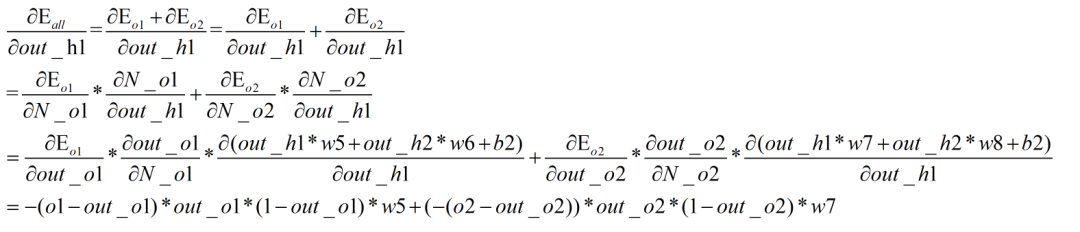

Las dos imágenes anteriores muestran el proceso de derivación del algoritmo de descenso de gradiente y retropropagación anterior.
Por el motivo de la propuesta de la red residual, el autor planteó al inicio del resumen, es decir, cuanto más profundo es el entrenamiento de la red neuronal, más difícil es, pero ¿por qué? ¿No dijimos que cuanto más profunda extrae la red más características, cuanto más profunda es la capa, más información representa? Sí, en términos generales, este es el caso, pero hay un límite para esta oración, es decir, dentro del alcance de un cierto número de capas de red, ¿qué tan grande es este alcance? En términos generales, se puede comparar con la red VGG anterior y la red GoogLeNet. Estas dos redes son lo suficientemente profundas. Si son más profundas, es posible que no se pueda entrenar la red. ¿Por qué? Esto debe explicarse desde la perspectiva del gradiente. ¿Recuerda lo que compartimos en nuestro artículo original de aprendizaje profundo, la actualización de los parámetros de red depende del algoritmo de retropropagación, y el algoritmo de retropropagación generalmente usa el algoritmo de descenso de gradiente? ¿Cuál es la relación entre la profundidad de la red neuronal y el algoritmo de descenso de gradiente? Sabemos que el algoritmo de descenso de gradiente es derivar la derivada de la regla de la cadena en toda la red, y aquí surge el problema. La profundidad de la red está dentro de un cierto rango, y la regla de la cadena está completamente bien. Cuantos más elementos de multiplicación, y estos valores de gradiente (incluso elementos de multiplicación) son números de coma flotante en muchos casos, más y más multiplicaciones harán que el valor de gradiente final sea muy pequeño, de modo que el gradiente final sea 0, que también es El gradiente desaparece. el gradiente desaparece, de acuerdo con la fórmula de descenso del gradiente, el último gradiente es 0 y el valor del gradiente actual permanece sin cambios. Por lo tanto, los parámetros de la red ya no se actualizan y no se puede realizar el siguiente paso de entrenamiento. . Por lo tanto, a medida que se profundiza la profundidad de la red, se presenta el problema de la desaparición del gradiente, por lo tanto, cuanto más profundo es el entrenamiento de la red, más difícil es, lo que generalmente se puede explicar como la razón propuesta por la red residual .
2. Estructura de la red

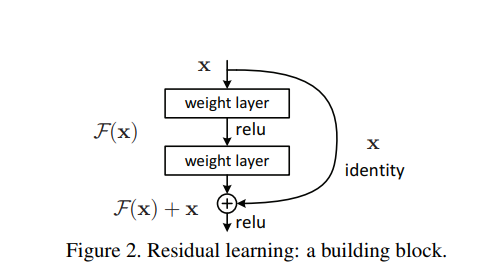
La imagen de arriba muestra el aprendizaje residual rápido propuesto en el artículo, que también es el módulo básico de la red residual.Después de una observación cuidadosa, ¿hay alguna diferencia con la red anterior? De hecho, es muy simple, es decir, hay una conexión de salto adicional, que conecta la terminal de entrada directamente a la terminal de salida.La gente ignora. La red ordinaria tiene dos ventajas después de agregar un paso más a la entrada x:
La información de alto nivel se integra con la información de bajo nivel para que la expresión característica sea más abundante.
Debido a la aparición de la entrada x, al realizar backpropagation, siempre habrá una derivada más de la x actual en el algoritmo de descenso del gradiente, lo que hace que el gradiente nunca parezca muy pequeño, y resuelve el gradiente El problema desaparece y las redes más profundas puede ser entrenado.
La configuración de la estructura de red en el papel: de 18 capas a 152 capas
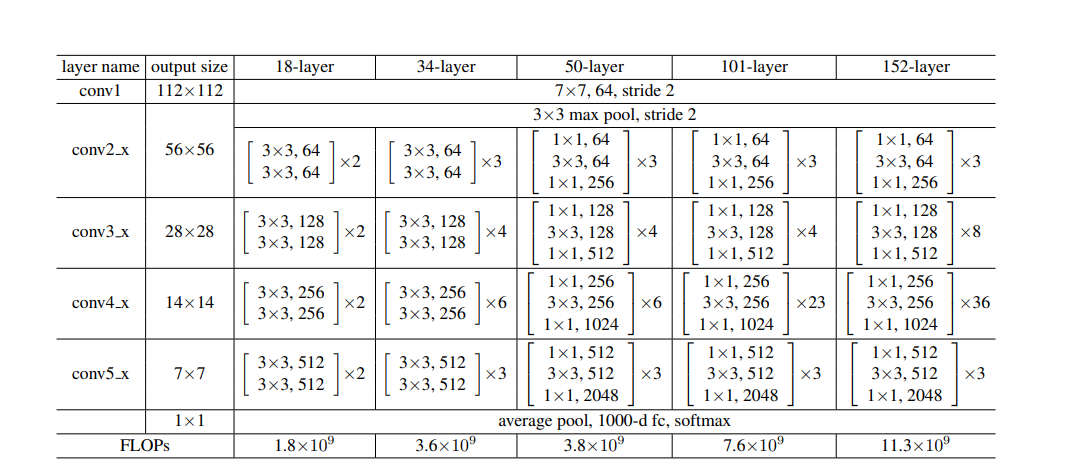
Uno de los ejemplos: estructura de red residual de 32 capas

Dado que el bloque residual básico es relativamente simple, no explicaremos la estructura de cada capa en detalle, lo explicaremos en detalle cuando lo compartamos en el combate real.
FIN
epílogo
Este es el final del intercambio de este problema. La aparición de la red residual ha liderado el proceso de aprendizaje profundo, que también nos guía hasta cierto punto. Una mejor solución no es más difícil. Tal vez aparezca un pequeño cambio para mayor mejora, tenemos que partir de los principios básicos, para poder ir más allá.
¡Nos vemos en el próximo número!
Editor: Layman Yueyi|Reseña: Layman Xiaoquanquan

Recorrido avanzado de TI
Revisión pasada
Teoría del aprendizaje profundo (16) -- La reexploración de GoogLeNet del misterio de la profundidad
Teoría del aprendizaje profundo (15): la exploración inicial de VGG del misterio de la profundidad
Teoría del aprendizaje profundo (14): el siguiente nivel de AlexNet
Qué hemos hecho en el último año:
[Resumen de fin de año] 2021, adiós a lo viejo y bienvenida a lo nuevo

Haga clic en "Me gusta" y vamos ~