El método de detección de objetivos basado en una red neuronal convolucional se divide popularmente en algoritmo de detección de objetivos de dos etapas y algoritmo de detección de objetivos de una sola etapa según la velocidad de detección . La detección de objetivos en dos etapas se basa en la propuesta de región . Por lo general, primero realiza la reparación preliminar del marco propuesta y la eliminación del fondo, y luego realiza la clasificación del marco propuesta y la regresión del cuadro delimitador, como R-CNN, Fast R-CNN, y Faster-R-CNN. La detección de objetivos de una sola etapa se basa en la regresión , que integra estos dos procesos y adopta el marco de implementación de "ancla + refinamiento de clasificación", como YOLO y SSD. Además, existen algoritmos de detección y reconocimiento de objetivos basados en búsqueda , como AttentionNet basado en atención visual, algoritmos basados en aprendizaje por refuerzo, etc.
Este artículo presenta principalmente el algoritmo clásico de detección de objetivos de dos etapas y el algoritmo de detección de objetivos de una sola etapa, y clasifica la evolución de su marco y sus ideas centrales. El contenido se extrae principalmente de "Aprendizaje profundo y detección de objetivos".
Algoritmo objetivo de dos etapas
Durante más de una década antes de la llegada del modelo de detección de objetos basado en redes neuronales convolucionales regionales (regiones con características CNN, R-CNN), la mayoría de las tareas de reconocimiento visual utilizaban el algoritmo de transformación de características invariantes de escala (SIFT) o histograma de gradiente orientado. (HOG) para extraer características. Cuando CNN brilló en el proyecto de clasificación ILSVRC en 2012 (AlexNet), los investigadores se dieron cuenta de que CNN puede aprender características muy sólidas y expresivas . Por lo tanto, Girshick y otros propusieron R-CNN, que se ha convertido en el trabajo pionero del modelo de detección de objetivos basado en CNN.
2014 R-CNN
Al realizar la detección de objetivos en una imagen, R-CNN primero utiliza el método de extracción de cuadros de sugerencias de búsqueda selectiva para seleccionar alrededor de 2000 cuadros de sugerencias en la imagen. A continuación, ajuste cada marco de sugerencia al mismo tamaño (227 × 227) y envíelo a AlexNet para extraer características y obtener un mapa de características. Luego, para cada categoría, use el clasificador SVM de esta categoría para calificar todos los vectores de características obtenidos y obtenga las puntuaciones de todos los cuadros de sugerencias en esta imagen correspondientes a cada categoría. Posteriormente, en cada categoría, el cuadro de sugerencias se examina de forma independiente utilizando un método codicioso de supresión de valor no máximo, filtrando los cuadros de sugerencias de clasificación inferior con IoU mayor que un umbral específico y utilizando el método de regresión del cuadro delimitador al cuadro de sugerencias. Ajustar la posición y el tamaño del objetivo para que sea más preciso rodearlo.

Tenga en cuenta que R-CNN usa la clasificación SVM en lugar de la función softmax de la última capa de CNN para la clasificación, porque los umbrales de muestras positivas y negativas utilizadas para ajustar CNN y entrenar SVM son diferentes. Cuando se utiliza SVM como clasificador, el mAP es del 54,2%. Cuando se utiliza softmax como clasificador, el mAP es del 50,9%. La contribución importante de R-CNN es introducir el aprendizaje profundo en la detección de objetos .
2014 SPP-Net
Una red neuronal convolucional generalmente consta de una parte convolucional y una parte completamente conectada. En la parte convolucional, la operación de convolución se puede realizar en cualquier tamaño de imagen y tamaño de convolución para obtener un mapa de características, mientras que en la parte completamente conectada, se requiere una entrada de tamaño fijo. Por lo tanto, el problema del tamaño fijo proviene de la capa completamente conectada . Sin embargo, debido a los diferentes tamaños de los cuadros de propuesta, escalar, estirar, recortar y otros métodos utilizados para ajustarlos al mismo tamaño darán lugar a diferentes grados de distorsión en la imagen original, incluso con algunos ajustes previos al procesamiento, es imposible eliminar por completo los efectos no deseados del cambio de tamaño.

Para resolver los problemas causados por el ajuste de tamaño anterior, se propone un método de agrupación de pirámide espacial. La capa de agrupación de pirámide espacial (agrupación de pirámide espacial, SPP) se utiliza para eliminar la limitación del tamaño fijo de la red.La capa SPP se coloca después de la última capa convolucional para agrupar el mapa de características y generar una salida de longitud fija, y this La salida se utiliza como entrada de la capa completamente conectada. Como se muestra a continuación: la primera capa agrupa todo el FeatureMap para obtener 1 característica; la segunda capa divide todo el FeatureMap en 4 bloques para obtener 4 características; la tercera capa divide el FeatureMap en 16 bloques para obtener 16 características. Finalmente, se ingresan 1+4+16=21 características en la capa completamente conectada para el cálculo del peso, donde 256 es el número de filtros en la última capa convolucional. Entonces, la salida de toda la capa SPP es un vector k × M-dimensional, donde M = 21, k = 256.

Otra innovación de SPP-Net es realizar solo una operación de convolución en la imagen original . Dado que R-CNN obtiene la propuesta primero, luego cambia el tamaño y finalmente ingresa a la convolución de CNN, esto es muy ineficiente. SPP-Net solo recopila el mapa de características de la imagen original una vez. Después de obtener el FeatureMap, encuentra el parche correspondiente de cada propuesta en el mapa de características e ingresa este parche como la característica de convolución de cada propuesta en SPP-Net para mejorar la detección. La velocidad es 24~120 veces mayor que la de R-CNN.
2015 rápido R-CNN
Ross Girshick Enlace original Rápido R-CNN
Fast R-CNN absorbe la idea de SPP-Net, utiliza la capa de agrupación de regiones de interés (capa de agrupación de RoI) similar a la capa SPP y agrega el paso de clasificación y el paso de regresión del cuadro delimitador después de la extracción de características a la red profunda para análisis adicional El entrenamiento sincrónico hace que el entrenamiento de Fast R-CNN sea más conciso y ahorra tiempo y espacio en comparación con el entrenamiento de múltiples etapas de R-CNN. La velocidad de entrenamiento de Fast R-CNN es 9 veces mayor que la de R-CNN y la velocidad de detección es 200 veces mayor que la de R-CNN.

El método de Fast R-CNN para extraer el cuadro de sugerencias es el mismo que el de R-CNN, y también se pueden utilizar métodos externos como la búsqueda selectiva. La parte de extracción de características de la imagen utiliza la parte convolucional de la red de clasificación de imágenes, como VGG16, y la imagen completa que se va a detectar se ingresa en ella para la extracción de características y obtener el mapa de características final. Todos los cuadros de propuesta se envían a la capa de agrupación de RoI, el área de mapeo correspondiente se encuentra en el mapa de características y el tamaño es fijo. A esto le siguen dos capas completamente conectadas para obtener vectores de características de RoI de tamaño fijo. Hasta ahora, cada RoI ha extraído una característica de dimensión fija, y el vector de características de RoI se utiliza como entrada para las dos tareas de clasificación de objetivos y regresión del cuadro delimitador , y se puede obtener el resultado de la detección del objetivo.
Tenga en cuenta que los experimentos en Fast R-CNN muestran que el efecto de clasificación que usa la función softmax es mejor que el que usa SVM, lo cual se debe a las diferentes estructuras de los dos . En R-CNN, la función softmax es la última estructura en la red básica AlexNet. El entrenamiento de parámetros se ajusta mediante el aprendizaje por transferencia. Los datos de muestra de entrenamiento son aleatorios, por lo que su efecto no es tan bueno como el SVM entrenado con negativo difícil. muestras. . En Fast R-CNN, se ha eliminado la estructura detrás de la red básica VGG16, y softmax es una nueva estructura independiente en Fast R-CNN. Dado que la función en sí introduce las características de competencia entre clases, puede lograr mejores resultados que SVM. .Efecto.
2015 R-CNN más rápido
Faster R-CNN integra el paso de extraer cuadros candidatos de destino en la red profunda , convirtiéndose en el primer algoritmo de detección de objetivos de aprendizaje profundo de extremo a extremo en tiempo real en el verdadero sentido. Como versión mejorada de Fast R-CNN, podemos simplemente considerar Faster R-CNN como RPN+Fast R-CNN , y RPN+Fast R-CNN comparte una parte de la capa convolucional. Como se muestra en la figura siguiente, se envía una imagen a Faster R-CNN para su detección. Las capas conv representan la capa convolucional de la red básica (como VGG16, ZF). Esta parte es la estructura compartida por RPN y Fast R-CNN . ; la imagen pasa capas Conv, obtiene el mapa de características; envía el mapa de características al RPN para obtener el cuadro de sugerencias; envía el cuadro de sugerencias y el mapa de características a la red residual (Fast R-CNN) comenzando desde la capa de agrupación de RoI para obtener el resultado de la detección del objetivo.

RPN es una red neuronal utilizada para extraer propuestas de regiones . La característica de la red RPN es que la extracción de marcos candidatos se logra mediante una ventana deslizante . El centro de la ventana deslizante pasará por cada punto del mapa de características, y cada punto del mapa de características tiene un conjunto de k anclajes preestablecidos centrados en el punto. Estos k anclajes tienen diferentes proporciones y tamaños, y el valor de k suele ser 9. La salida de RPN contiene los valores predichos de dos categorías (primer plano y fondo, juzgados por IoU) y 4 parámetros (x, y, w, h) de regresión del cuadro delimitador.

Métodos de detección de objetos de una etapa
Para que la detección de objetivos cumpla con los requisitos en tiempo real, los investigadores propusieron un método de detección de objetivos de una sola etapa. En el método de detección de objetivos de una sola etapa, el cuadro de sugerencias ya no se utiliza para "detección aproximada + refinamiento fino", pero el resultado se obtiene en un solo paso . El método de detección de objetos de una sola etapa solo realiza el cálculo de la red de avance una vez, por lo que la velocidad mejora considerablemente.
YOLO en 2015
Joseph Redmon Solo miras una vez: detección de objetos unificada en tiempo real
YOLO es el primer método de detección de objetivos de una sola etapa y el primero en lograr la detección de objetivos en tiempo real . YOLO puede alcanzar una velocidad de detección de 45 cuadros por segundo y su mAP es dos veces o incluso mayor que otros sistemas de detección en tiempo real. YOLO v1 trata la detección como un problema de regresión, por lo que el proceso de procesamiento de imágenes es muy simple y directo. Primero se cambia el tamaño de la imagen de entrada a 448 píxeles por 448 píxeles, luego se ejecuta una red convolucional en la imagen y, finalmente, se utiliza una capa completamente conectada para la detección. YOLO divide la imagen de entrada en una cuadrícula S×S . Si el punto central de un objeto cae dentro de una celda de la cuadrícula, esa celda de la cuadrícula detecta el objeto. Cada celda de la cuadrícula predice n cuadros delimitadores y puntuaciones de confianza para esos cuadros delimitadores. Estos puntajes de confianza reflejan la confianza de YOLO en que el objeto está contenido en el cuadro delimitador y la precisión del cuadro delimitador previsto.

Las limitaciones de YOLO también son muy obvias. En comparación con los sistemas de detección de objetos de dos etapas, YOLO produce más errores de localización y se queda atrás en precisión (especialmente pobre para objetos pequeños). Al mismo tiempo, YOLO impone una restricción espacial en la predicción del cuadro delimitador (ya que cada celda de la cuadrícula solo predice dos cuadros delimitadores y solo puede tener una clase). Esta restricción espacial limita la cantidad de objetivos cercanos que YOLO puede predecir, por lo que las predicciones de bandadas, multitudes y convoyes no son ideales con YOLO.
Vale la pena señalar que para lograr una detección de alta precisión en tiempo real, el marco de la serie YOLO ha estado evolucionando a toda velocidad y hasta ahora se ha iterado a la versión v7, y hay muchas variantes.
SSD en 2015
Enlace original de Wei Liu SSD: detector MultiBox de disparo único
Wei Liu y otros propusieron el método SSD el mismo año en que nació YOLO. SSD absorbe la idea de la detección rápida de YOLO, al tiempo que combina las ventajas de RPN en Faster R-CNN y mejora el procesamiento de objetivos de múltiples escalas (ya no utiliza solo el mapa de características de nivel superior para la predicción). Debido a los diferentes tamaños de las características contenidas en diferentes capas convolucionales, SSD utiliza el método de predicción de la pirámide de características para integrar los resultados de detección de múltiples capas convolucionales para realizar la detección de objetivos de diferentes tamaños . En Faster R-CNN, se utiliza la predicción de mapas de características de una sola capa, es decir, la predicción solo se realiza en el mapa de características en la parte superior de la red básica. SSD predice en mapas de características multicapa y detecta objetos de diferentes tamaños en mapas de características de diferentes tamaños.
Como método de detección de objetivos de una sola etapa, SSD no predice el cuadro de sugerencias como Faster R-CNN, sino que predice directamente el cuadro delimitador del objetivo . Al predecir el cuadro delimitador del objetivo, SSD introduce el concepto de cuadro predeterminado (que es equivalente al ancla en Faster R-CNN). SSD detecta objetivos de diferentes tamaños en mapas de características de diferentes tamaños. Por lo tanto, los cuadros predeterminados de diferentes tamaños estarán representados por mapas de características de diferentes tamaños. Cuanto más cerca de la capa superior, mayor será el tamaño del cuadro predeterminado en el mapa de características. y cuanto más cerca esté de la capa inferior , más pequeño será el tamaño del cuadro predeterminado en el mapa de características . Como se muestra a continuación: el tamaño del cuadro predeterminado en el mapa de características de 8 × 8 es pequeño y se detectará un gato con un tamaño más pequeño; mientras que el tamaño del cuadro predeterminado en el mapa de características de 4 × 4 es más grande, el tamaño Se detectarán perros más grandes. Para cada punto en cada mapa de características, también es posible usar cuadros predeterminados de diferentes escalas para corresponder a diferentes formas.

El proceso de Faster R-CNN basado en el ancla y SSD basado en el cuadro predeterminado es similar, pero el SSD está un paso por delante del cuadro predeterminado : realiza directamente un juicio de múltiples categorías y una predicción del cuadro delimitador del objetivo. Vale la pena señalar que las redes clásicas como YOLO y SSD son la base para la posterior evolución de las redes, y es por ello que se hablará de trabajos pioneros.
RetinaNet 2017
Tsung-Yi Lin Enlace original Pérdida focal para la detección de objetos densos
El modelo RetinaNet utiliza ResNet + FPN (red piramidal de funciones, FPN) como marco básico . Después de FPN, se obtienen múltiples mapas de características de diferentes tamaños. Los mapas de características de cada nivel están conectados a dos subredes, a saber, la subred de caja (subred de regresión de cuadro delimitador) y la subred de clase (subred de clasificación de objetivos). Para el problema del tamaño de muestra desequilibrado en la subred de clase, este método utiliza la función de pérdida focal para calcular la pérdida.
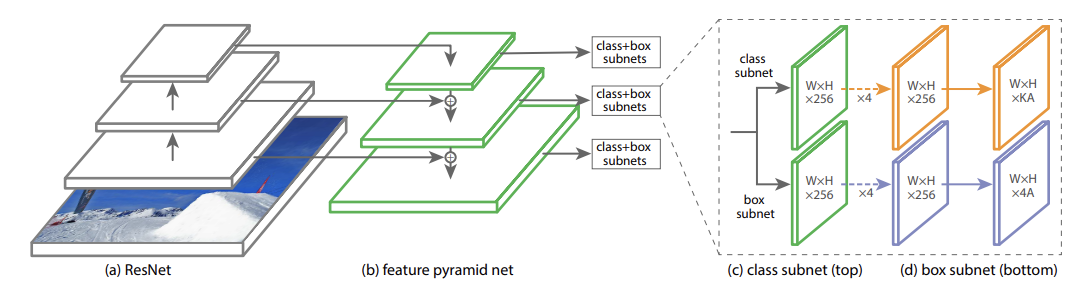
En la pirámide de imágenes, las características de alto nivel, baja resolución y alto nivel tienen información semántica rica y una fuerte capacidad de reconocimiento de objetos; las características de bajo nivel, alta resolución y bajo nivel no contienen información semántica rica y tienen una capacidad de reconocimiento de objetos pobre . FPN propone una nueva estructura piramidal de funciones para el problema de que SSD no utiliza funciones de bajo nivel, que integra funciones de bajo nivel con funciones de alto nivel y aumenta la información semántica de las funciones de bajo nivel, de modo que el reconocimiento de objetivos se pueda realizar en funciones de bajo nivel y se mejora el reconocimiento de objetivos pequeños.
Además, la función de pérdida focal recientemente propuesta equivale a agregar pesos relacionados con la probabilidad predicha del modelo a cada muestra, reducir el peso de pérdida de muestras simples y retener al máximo la pérdida de muestras difíciles , lo que resuelve el problema de las muestras simples. Muestras y muestras difíciles El problema del equilibrio entre muestras.
2017Refinar
RefineDet puede considerarse como una combinación de SSD, RPN y FPN , que combina las ventajas de los métodos de detección de objetivos de una sola etapa y los métodos de detección de objetivos de dos etapas. RefineDet es un método de detección de objetivos de una sola etapa que utiliza dos estructuras de módulos interconectados. Sus módulos de serie de dos pasos son ARM (módulo de refinamiento de anclaje, módulo de mejora del marco de anclaje) y DOM (módulo de detección de objetos, módulo de detección de objetivos). El TCB (bloque de conexión de transferencia, módulo de conexión de conversión) en RefineDet se utiliza para convertir las funciones obtenidas en ARM y pasarlas a ODM, lo que tiene el efecto de fusión de funciones.

ARM se utiliza para identificar y filtrar el área de fondo (es decir, ancla negativa) y ajustar aproximadamente el tamaño y la posición del ancla , de modo que el posicionamiento preciso posterior del cuadro delimitador. Esto es similar a la función de RPN en Faster R-CNN, pero RPN opera en un mapa de características y ARM necesita procesar múltiples mapas de características de diferentes tamaños. El ancla ajustada de ARM se ingresará en el ODM posterior y el El cuadro delimitador se puede procesar y se realizan la regresión y la clasificación de objetivos. Al igual que SSD, ODM también se detecta en múltiples mapas de características de diferentes escalas. Sin embargo, SSD usa un ancla fija (es decir, cuadro predeterminado) al detectar, mientras que ODM usa un ancla filtrada y con corrección aproximada , por lo que se obtendrán mejores resultados de detección. Dos módulos interconectados simulan la estructura de la detección de objetos en dos etapas, lo que permite que el modelo mejore la precisión de la detección manteniendo una alta eficiencia.
La parte TCB realiza la operación de conversión de características, es decir, mapa de características de salida de la parte ARM se convierte en la entrada de la parte ODM . La fusión de características de TCB y FPN es similar, y también adopta la idea de aumentar el muestreo del mapa de características y fusionarlo con características de alto nivel, lo que hace que RefineDet sea mejor que SSD en la detección de objetivos pequeños.
"Aprendizaje profundo y detección de objetivos" Du Peng et al. Electronic Industry Press Capítulo 4 y Capítulo 5
"Principios prácticos, arquitectura y optimización de redes neuronales profundas en plataformas móviles" Capítulo 8 Lu Yusheng Machinery Industry Press