
来源:知乎 算法进阶
本文约8000字,建议阅读15分钟
本文从计算机视觉的角度说一下自己对深度学习瓶颈的看法。En los últimos años, el aprendizaje profundo se ha convertido en la estrella más deslumbrante en el campo de la informática, y ha derivado muchas aplicaciones prácticas, principalmente en las áreas de razonamiento y toma de decisiones. Sin embargo, cómo lograr más logros en el aprendizaje profundo más allá del procesamiento de imágenes, habla y lenguaje natural, como la comprensión de las emociones humanas, la imitación de la conciencia y la motivación, implicará muchos problemas más profundos, que actualmente son la caja negra del aprendizaje profundo que no se puede abrir Cubo de Rubik.
Autor: hito
fuente:
https://www.zhihu.com/question/40577663/answer/309571753
Debido a que estoy familiarizado con la visión por computadora, hablaré sobre mis puntos de vista sobre el cuello de botella del aprendizaje profundo desde la perspectiva de la visión por computadora.
1. El aprendizaje profundo carece de apoyo teórico
Las ideas de la mayoría de los artículos son propuestas por intuición y hay poco apoyo teórico detrás de ellas. Validar una idea efectiva a través de experimentos no es necesariamente la dirección óptima. Al igual que sgd en el problema de optimización, cada paso es óptimo, pero desde una perspectiva global, no es óptimo.
Sin soporte teórico, el progreso en el campo de la visión por computadora es como SGD, que es efectivo pero lento; si hay soporte teórico, el progreso en el campo de la visión por computadora será tan efectivo y rápido como el método de Newton.
El modelo CNN en sí tiene muchos hiperparámetros, como cuántas capas se configuran, cuántos filtros se configuran para cada capa, si cada filtro es profundo o puntual, o conv ordinario, qué tan grande es el tamaño del kernel del filtro y pronto.
La combinación de estos hiperparámetros es un gran número, y es casi imposible verificarlo solo mediante experimentos. Al final, solo podemos probar algunas combinaciones basadas en la intuición, por lo que el modelo CNN actual solo puede decir que el efecto es muy bueno, pero definitivamente no es óptimo, ya sea en efecto o en eficiencia.
Tomando la eficiencia como ejemplo, resnet funciona muy bien ahora, pero la cantidad de cálculo es demasiado grande y la eficiencia no es alta. Sin embargo, es seguro que la eficiencia de resnet se puede mejorar, porque debe haber parámetros redundantes y cálculos redundantes en resnet, siempre que encontremos estas partes redundantes y las eliminemos, la eficiencia aumentará naturalmente. Uno de los métodos más simples que usará la mayoría de la gente es reducir la cantidad de canales en cada capa.
Si un conjunto de teorías puede estimar la capacidad del modelo, la capacidad del modelo requerida para una tarea. Luego, cuando nos enfrentamos a una tarea, usar un modelo que coincida con la capacidad puede mejorar el efecto y la eficiencia.
2. Cada vez más ideas de ingeniería en el campo
Debido a que el aprendizaje profundo en sí mismo carece de teoría, la teoría del aprendizaje profundo es un hueso duro de roer. Los marcos de aprendizaje profundo se están volviendo cada vez más tontos. Hay implementaciones de código abierto de varios modelos en Internet. Ahora muchas personas en la industria usan el aprendizaje profundo como Lego. .
Ante una tarea, git clone las implementaciones de código abierto de los mejores modelos actuales, mire las instrucciones de los bloques de construcción (es decir, los documentos) de estos modelos y piense qué bloques de construcción se pueden cambiar y si el orden del edificio los bloques se pueden cambiar De manera similar, agregar algunos bloques de construcción puede mejorar el efecto, reducir algunos bloques de construcción puede hacer que la eficiencia sea mayor, y así sucesivamente.
Después de pensarlo, se realizó el experimento y el efecto del experimento fue bueno. Cuando se publicó el artículo, el efecto del experimento no fue el esperado, así que lo intenté de nuevo.
Todo este proceso es un pensamiento muy similar al de un ingeniero, que básicamente se basa en la sensación de prueba y error y en el pensamiento profundo sobre la ausencia. Pocas personas piensan en lo que está mal con el modelo desde un punto de vista teórico y qué mejoras se deben hacer al modelo en respuesta a este problema.
Para dar un ejemplo extremo, un dato es en realidad una función lineal, pero siempre tratamos de ajustarlo con una función cuadrática. Si encontramos que el resultado del ajuste no es bueno, entonces usamos una función cúbica para ajustarlo. Si falla tres veces, o cuatro veces, luego nos damos por vencidos. . Rara vez pensamos en qué distribución son estos datos. Para tal distribución, ¿hay una función que pueda ajustarse? Si es así, qué función es la más adecuada.
El aprendizaje profundo debe ser una ciencia y debe enfrentarse con el pensamiento científico para obtener mejores resultados.
3. Las muestras antagónicas son un problema del aprendizaje profundo, pero no el cuello de botella del aprendizaje profundo
Creo que aunque los ejemplos contradictorios son un problema del aprendizaje profundo, no son el cuello de botella del aprendizaje profundo. También hay ejemplos contradictorios en el aprendizaje automático.En comparación con el aprendizaje profundo, el aprendizaje automático tiene más apoyo teórico, pero aún no resuelve el problema de los ejemplos contradictorios.
La razón por la que pensamos que las muestras antagónicas son el cuello de botella del aprendizaje profundo es porque las imágenes son muy intuitivas. Cuando vemos dos imágenes casi idénticas, el modelo de aprendizaje profundo finalmente da dos resultados de clasificación completamente diferentes, lo que tiene un gran impacto en nosotros. .
Si modifica el valor de un elemento en una función cuya categoría original es A y luego cambia la clasificación de svm a B, nos sentiremos desaprobados, "Cambió el valor de un elemento en esta función y su resultado de clasificación cambia normalmente ah".
作者:PENG Bo
https://www.zhihu.com/question/40577663/answer/413331053
Personalmente, creo que el cuello de botella actual del aprendizaje profundo puede estar en la escalabilidad. Sí, oíste bien.
Ya tenemos cantidades masivas de datos y una potencia informática enorme, pero es difícil para nosotros entrenar modelos de redes profundas a gran escala (modelos de nivel GB a TB), porque BP es difícil de paralelizar a gran escala. Si el paralelismo de datos no es suficiente, la relación de aceleración se reducirá considerablemente después de usar el paralelismo de modelos. Incluso después de agregar muchas mejoras, los requisitos de ancho de banda del proceso de capacitación siguen siendo demasiado altos.
Es por eso que la DGX-2 de nVidia solo tiene 16 V100, pero se venderá por 2,5 millones. Porque aunque se puede ensamblar la misma potencia de cómputo total con mucho menos dinero, es difícil construir una máquina que pueda usar de manera eficiente tantas tarjetas gráficas.

Y las GPU dentro de DGX-2 no están completamente interconectadas:
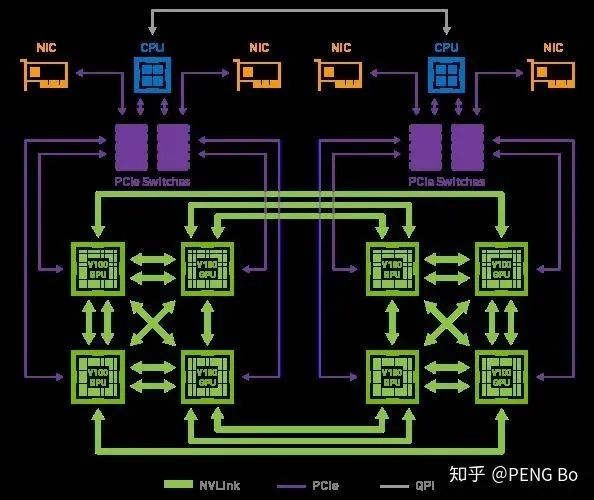
Otro ejemplo es el entrenamiento de AlphaGo Zero: solo se usa una pequeña cantidad de TPU para el entrenamiento. Incluso si hay decenas de miles de TPU, no hay forma de usarlos de manera eficiente para entrenar la red.
Si el aprendizaje profundo puede aumentar continuamente la velocidad de entrenamiento al apilar máquinas sin cerebro (al igual que la minería puede apilar máquinas de minería), de modo que se pueda usar una red multitarea a gran escala para aprender todo tipo de datos en el nivel PB EB , entonces lo que se puede lograr El efecto es probable que sea sorprendente.
Luego nos fijamos en el ancho de banda actual:
https://en.wikipedia.org/wiki/List_of_interface_bit_rates
En 2011, se lanzó PCI-E 3.0 x16, que es de 15,75 GB/s. Ahora las computadoras de consumo todavía están en este nivel, y 4.0 todavía no ha salido, pero puede ser porque todos no están motivados (los juegos no requieren tanto banda ancha).
NVLink 2.0 es de 150 GB/s, que todavía no es suficiente para la paralelización a gran escala.
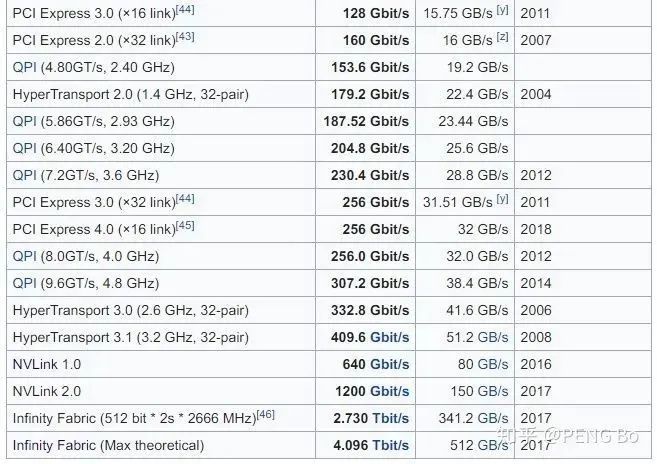
Puede decir que el ancho de banda aumentará gradualmente.
Genial, así que aquí viene la pregunta más extraña, que creo que vale la pena reflexionar:
El chip de IA se ha esforzado tanto y todavía tiene un ancho de banda limitado, entonces, ¿por qué el cerebro humano no tiene un ancho de banda limitado?
Mi opinión es:
La paralelización del cerebro humano se realiza tan bien que solo se necesita un ancho de banda de nivel kB entre las neuronas. Vale la pena aprender para los investigadores de chips y algoritmos de IA.
El método de aprendizaje del cerebro humano es mucho más tosco que el de BP, por lo que se puede paralelizar a una escala tan grande.
El método de aprendizaje del cerebro humano es descentralizado, en mi opinión, se acerca más a un método basado en la energía.
Otras características del cerebro humano pueden ser imitadas por el aprendizaje de transferencia actual + aprendizaje multitarea + aprendizaje continuo.
El cerebro humano también utiliza el lenguaje para ayudar a pensar. Sin lenguaje, es difícil para el cerebro humano aprender rápidamente cosas complejas.
Ejemplo: Gigante
https://www.zhihu.com/question/40577663/answer/1974793135
Mi campo de investigación es principalmente el procesamiento del lenguaje natural (PNL).Desde la perspectiva de la PNL, combinada con mi propia investigación científica y experiencia laboral, resumiré los 8 cuellos de botella típicos detrás de la prosperidad y la fascinación del aprendizaje profundo.
1. Alta dependencia de los datos etiquetados
Como todos sabemos, ya sea clasificación tradicional, coincidencia, etiquetado de secuencias, tareas de generación de texto o tareas intermodales recientes, como comprensión de imágenes, análisis de sentimientos de audio, Text2SQL, etc., dondequiera que se utilicen modelos de aprendizaje profundo, hay un alta dependencia de los datos etiquetados .
Esta es la razón por la cual el efecto del modelo de aprendizaje profundo no es satisfactorio debido a la insuficiencia de datos en la etapa inicial o en la etapa de inicio en frío. Los modelos necesitan más ejemplos que los humanos para aprender cosas nuevas.
Aunque recientemente se han realizado algunos trabajos con pocos recursos o incluso con recursos nulos (como dos artículos sobre la generación de diálogos [1-2]), en general, estos métodos solo son aplicables a ciertos campos específicos y son difíciles de promover directamente.
2. El modelo depende del dominio y es difícil de migrar directamente
Inmediatamente después del tema anterior, cuando obtuvimos datos etiquetados a gran escala a través de iteraciones a largo plazo a través de equipos de etiquetado o crowdsourcing, y entrenamos el modelo, pero cuando se cambió el escenario comercial, el efecto del modelo volvió a caer en picado.
O el modelo solo funciona bien en el conjunto de datos en papel y no puede reproducir efectos similares en el resto de los datos. Estas son preguntas muy comunes.
Mejorar la transferibilidad de los modelos es un tema muy valioso en el aprendizaje profundo, que puede reducir en gran medida el costo del etiquetado de datos. Por ejemplo, un compañero mío tiene mucha experiencia en correr karts. Ahora que se lanzó el nuevo juego móvil QQ Speed , puede aprender por analogía después de dos rondas y subirse fácilmente a Xingyao y Chariot, sin tener que comenzar desde el práctica de deriva más primitiva.
Aunque el método de preentrenamiento + ajuste fino de PNL alivia este problema, la transferibilidad del aprendizaje profundo debe mejorarse aún más.
3. El modelo Big Mac tiene altos requerimientos de recursos
Aunque los modelos gigantes con efectos sorprendentes han aparecido con frecuencia en el campo de la PNL en los últimos dos años, han desanimado a los investigadores ordinarios. Independientemente del costo de decenas de miles de pre-entrenamiento (BERT->1.2w$, GPT2->4.3w$) o incluso millones de dólares, el uso de pesos de pre-entrenamiento tiene altos requisitos en la GPU y otro hardware.
Porque el número de parámetros del modelo grande está aumentando exponencialmente: BERT (110 millones), T5 (11 mil millones), GPT3 (150 mil millones), Pangu (200 mil millones)... Desarrollar modelos pequeños de alto rendimiento es otro aspecto importante de aprendizaje profundo dirección del valor.
Afortunadamente, ha habido algunos buenos trabajos ligeros en el campo de la PNL, como TinyBERT[3], FastBERT[4], etc.
4. El modelo carece de sentido común y capacidad de razonamiento.
Como mencionó el sujeto, la comprensión actual de las emociones humanas mediante el aprendizaje profundo aún se encuentra en un nivel semántico superficial, sin una buena capacidad de razonamiento y sin poder comprender realmente las demandas de los usuarios. Por otro lado, cómo integrar efectivamente el sentido común o el conocimiento previo en la capacitación de modelos también es uno de los cuellos de botella que el aprendizaje profundo debe superar.
Un día en el futuro, además de escribir poemas, resolver ecuaciones y jugar Go, el modelo de aprendizaje profundo también podrá responder preguntas breves de sentido común de los padres, y se considerará verdaderamente "inteligente".
5. Escenarios de aplicación limitados
Aunque la PNL tiene muchos subcampos, las mejores direcciones para el desarrollo siguen siendo la clasificación, la coincidencia, la traducción y la búsqueda, y los escenarios de aplicación de la mayoría de las tareas aún son limitados.
Por ejemplo, los chatbots generalmente se usan como el módulo de abajo hacia arriba del sistema de preguntas y respuestas, y responden con un discurso antropomórfico estándar cuando las preguntas frecuentes o el módulo de intención no responden a la pregunta del usuario. Sin embargo, si los chatbots se aplican directamente en el dominio abierto, es fácil pasar de la inteligencia artificial al retraso mental artificial, lo que disgusta a los usuarios.
6. Falta de un esquema de búsqueda automática de hiperparámetros eficiente
Hay muchos hiperparámetros en el campo del aprendizaje profundo. Aunque existen algunas herramientas de ajuste de parámetros automatizadas, como nni[5] de Microsoft, todavía se basan en la experiencia personal de los ingenieros de algoritmos; debido al largo tiempo de capacitación, el proceso de verificación de parámetros requiere un alto costo de tiempo.
Además, AutoML aún requiere poder de cómputo a gran escala para producir resultados rápidamente, por lo que también se debe prestar atención al aumento de la escala de cómputo.
7. Algunos trabajos solo están orientados a la competencia SOTA
Será la práctica de muchos investigadores (incluyéndome a mí una vez) pasar un juego conocido a SOTA y luego publicar un artículo. Una canalización típica es:
Pase la lista al primer lugar a cualquier costo de los recursos;
Comience a retroceder y explique por qué este método funciona tan bien (algo así como una autojustificación).
Por supuesto, esto no quiere decir que este método no sea bueno, sino que no debemos apuntar solo a hacer rankings cuando investigamos. Porque en muchos casos, realmente no tiene sentido mejorar la puntuación del 0,XX % después del punto decimal, y es difícil aportar beneficios al desarrollo de aprendizaje profundo existente.
Esto también explica que el entrevistador preguntó "cómo obtener un buen resultado en una determinada competencia", y se disgustó cuando escuchó la forma de "integración multimodo" y otros modelos apilados. Debido a que la escena real está limitada por factores como los recursos y el tiempo, generalmente no se realiza de esta manera.
8. Poco interpretable
El último punto también es un problema común en este campo: toda la red de aprendizaje profundo es como una caja negra, que carece de una interpretabilidad clara y transparente.
Por ejemplo, ¿por qué el nivel de confianza de ser clasificado como un gibón es tan alto como 99,3% al agregar una pequeña perturbación de ruido (equivalente a un ejemplo adversario) a la imagen del panda gigante?

Visualizar las funciones aprendidas por algunos modelos (CNN, Atención, etc.) puede ayudarnos a comprender cómo aprende el modelo. Anteriormente, el campo del aprendizaje automático también usaba técnicas de reducción de dimensionalidad (t-SNE, etc.) para comprender la distribución de características de alta dimensión.
Puede consultar más investigaciones sobre la interpretabilidad del aprendizaje profundo en [6].
Recientemente , los ganadores del Premio Turing 2018, Bengio, LeCun y Hinton, fueron invitados por ACM a reunirse para revisar los conceptos básicos del aprendizaje profundo y algunos logros revolucionarios, y también hablaron sobre los desafíos que enfrenta el desarrollo futuro del aprendizaje profundo.
Autor: usuario de Zhihu
https://www.zhihu.com/question/40577663/answer/224699031
Después de leer algunas respuestas, siento que lo que todos dijeron es muy razonable, pero siempre siento que el cuello de botella mencionado por muchas personas es el cuello de botella del "aprendizaje automático", no el cuello de botella del "aprendizaje profundo". Te daré una respuesta contundente a continuación.
Aprendizaje profundo, profundo es la apariencia, no el objetivo. La teoría de la aproximación universal demuestra que solo se necesita una capa oculta para ajustar cualquier función, lo que demuestra que el enfoque no es profundo. Aprendizaje profundo en comparación con el aprendizaje automático tradicional: el aprendizaje profundo se trata de representaciones de aprendizaje. Es decir, las características esenciales (representación) de los datos se aprenden a través de una estructura jerárquica bien diseñada.
Hablando de cuellos de botella, el aprendizaje profundo también es un tipo de aprendizaje automático y también tiene el cuello de botella del propio aprendizaje automático. Por ejemplo, depende en gran medida de los datos. Es la "inteligencia conductual" de los datos en lugar de la inteligencia artificial con autoconciencia real. Las respuestas a estas preguntas anteriores dicen mucho.
Además de eso, tiene algunos cuellos de botella únicos.
Por ejemplo, la estructura de características es difícil de cambiar. El formato de los datos (tamaño, longitud, canal de color, formato de diccionario de texto, etc.) es exigente. El extractor de funciones entrenado no es tan fácil de transferir a otras tareas.
Es muy inestable. Por ejemplo, en las tareas de NLP, al realizar la generación de texto (QA), la anotación de imágenes y otros trabajos, a veces el contenido generado lo abrumará. Pero a menudo puede ser sorprendente. Por lo tanto, su falta de control hace que no se use mucho en aplicaciones de ingeniería. Muchas aplicaciones que sacrifican la recuperación y la precisión no se pueden implementar con aprendizaje profundo, de lo contrario, son propensas al peligro. Por el contrario, el método basado en reglas es mucho más fiable. Al menos si algo sale mal, puedes depurarlo.
Es difícil de corregir, y si algo sale mal, básicamente depende del entrenamiento de reparación de parámetros. Hay muchas dificultades potenciales encontradas en el proceso de solicitud.
La optimización de modelos profundos depende demasiado de la experiencia personal. Las tres principales metafísicas del mundo: astrología occidental, Zhouyi oriental y aprendizaje profundo.
La estructura del modelo es cada vez más compleja y cada vez es más difícil integrar diferentes sistemas. Es como si se estuvieran criando supersoldados todo el tiempo, pero no hablan el idioma para formar un superejército.
Problemas de información sensible. Si los datos utilizados en el modelo de entrenamiento no se desensibilizan, es posible probar información confidencial a través de algunos métodos.
problema de ataque La existencia de Adversarial Sample ahora ha sido confirmada. La creación de algunos ejemplos contradictorios puede eliminar directamente los algoritmos existentes. Sin embargo, cree que la generación de muestras antagónicas se debe al hecho de que la extracción de características no aprende las características de flujo de los datos. En otras palabras, un cierto grado de sobreajuste trae este problema,
Sin embargo, el mayor problema en la actualidad es la demanda de datos masivos. Debido a la necesidad de conocer la distribución real, nuestros datos son solo una pequeña fracción muestreada de la distribución real. Si desea que el modelo se aproxime realmente a la distribución real, necesita la mayor cantidad de datos posible. La demanda de volumen de datos ha aumentado y hay muchas preguntas: ¿De dónde provienen los datos? ¿Dónde existen los datos? ¿Cómo lavar datos? ¿Quién etiquetará los datos? ¿Cómo entrenar con una gran cantidad de datos? ¿Cómo equilibrar el costo (equipo, datos) y el efecto?
Ampliado por la Cláusula 8. ¿Es el aprendizaje profundo que requiere cantidades masivas de datos realmente "inteligencia artificial"? De todos modos, no lo creo. El cerebro humano puede generalizar con un conocimiento limitado, en lugar de simplemente usar pautas diseñadas por humanos para dirigir el aprendizaje automático a la distribución de espacios de características. Por lo tanto, ¡la inteligencia artificial real no debería tener una demanda tan grande de datos e informática! (Esto es en realidad un problema de aprendizaje automático)
En definitiva, son muchos los factores que limitan su aplicación. Pero desde un punto de vista optimista, no tienes miedo a los problemas y siempre se pueden resolver.
Autor: usuario anónimo
https://www.zhihu.com/question/40577663/answer/311095389
Los gráficos computacionales son cada vez más complejos y los diseños son cada vez más contradictorios.
Ya sea que las innovaciones de Dropout/BN/Residual sean trucos o trucos, al menos puede inventar una explicación intuitiva atractiva para engañarlo, y también se aplican con éxito en escenarios y tareas completamente diferentes. El año pasado, básicamente no hubo trucos nuevos y útiles de este nivel. La población de alquimistas es cada vez más grande, pero no se ha descubierto el truco universal, lo que demuestra que el campo ha llegado a un cuello de botella y se han recogido los melocotones que son fáciles de recoger.
¿Se ha aprovechado el potencial de la estructura? ¿O no hemos encontrado una tarea más general y representativa como caldo de cultivo de nuevos trucos? Estas son las preguntas que la investigación de DL debe responder. Ahora parece que la forma no es optimista. La investigación tradicional de DL se basa en cambiar algunas líneas y agregar algunas capas más. Cada vez es más difícil emitir documentos de alta calidad para una tarea específica.
Mi opinión personal es que si DL realmente quiere usar el sombrero de la inteligencia artificial, debe hacer cosas que se modifican inteligentemente. Ahora se divide artificialmente en NLP/CV/ASR según los escenarios de aplicación. Después de todo, hay una parte superior límite para el ajuste aproximado Tampoco tiene nada en común con la forma en que los humanos adquieren inteligencia.
Autor: Él Zhiyuan
https://www.zhihu.com/question/40577663/answer/224656397
Simplemente diga lo que piensa. En mi opinión, la mayoría de los modelos actuales de aprendizaje profundo, sin importar cuán compleja sea la construcción de la red neuronal, en realidad están haciendo lo mismo:
Use una gran cantidad de datos de entrenamiento para ajustar una función objetivo y=f(x).
x e y son en realidad la entrada y la salida del modelo, por ejemplo:
Problema de clasificación de imágenes. En este momento, x es generalmente una matriz numérica de imagen de ancho*alto*número de canal, e y es la categoría de clasificación.
Problema de reconocimiento de voz. x es la señal de muestreo de voz e y es el texto correspondiente a la voz.
máquina traductora. x es una oración en el idioma de origen e y es una oración en el idioma de destino.
Y "f" representa el modelo en aprendizaje profundo, como CNN, RNN, LSTM, codificador-descodificador, codificador-descodificador con atención, etc. En comparación con los modelos tradicionales de aprendizaje automático, los modelos de aprendizaje profundo suelen tener dos características:
El modelo tiene una gran capacidad y muchos parámetros;
End-to-end (extremo a extremo).
Con la ayuda de la aceleración informática GPU, el aprendizaje profundo puede optimizar los modelos de gran capacidad de principio a fin, superando así a los métodos tradicionales en rendimiento. Esta es la metodología básica del aprendizaje profundo.
Entonces, ¿cuáles son las desventajas de este enfoque? Personalmente, creo que hay los siguientes puntos.
1. La eficiencia del entrenamiento f no es alta
La eficiencia del entrenamiento se manifiesta en dos aspectos: primero, lleva mucho tiempo entrenar el modelo. Como todos sabemos, el aprendizaje profundo necesita usar GPU para acelerar el entrenamiento, pero incluso este tiempo de entrenamiento es de horas o días. Si la cantidad de datos utilizada es grande y el modelo es complejo (como modelos de reconocimiento facial y reconocimiento de voz con un tamaño de muestra grande), el tiempo de entrenamiento se calculará en semanas o incluso meses.
Otra desventaja en la eficiencia del entrenamiento es que la tasa de utilización de las muestras no es alta. Para dar un pequeño ejemplo: la imagen es amarilla. Para los humanos, solo necesitan mirar algunas "muestras de entrenamiento" para aprender a identificar la pornografía, y es muy simple juzgar qué imágenes son "pornográficas". Sin embargo, entrenar un modelo de pornografía de aprendizaje profundo a menudo requiere decenas de miles de muestras positivas + negativas, como el código abierto yahoo/open_nsfw de Yahoo. En general, los modelos de aprendizaje profundo tienden a necesitar muchos más ejemplos que los humanos para aprender lo mismo. Esto se debe a que los humanos ya tienen mucho "conocimiento previo" en este campo, pero para los modelos de aprendizaje profundo, carecemos de un marco unificado para proporcionarles el conocimiento previo correspondiente.
Entonces, en aplicaciones prácticas, ¿cómo resolver estos dos problemas? Para el problema del tiempo de entrenamiento prolongado, la solución es agregar GPU; para el problema de la utilización de muestras, se puede resolver agregando muestras etiquetadas. Pero no importa agregar GPU o agregar muestras, se necesita dinero , y el dinero suele ser un factor importante que restringe los proyectos reales.
2. La falta de fiabilidad de la propia f ajustada
Sabemos que el aprendizaje profundo puede superar en gran medida a los métodos tradicionales en rendimiento. Sin embargo, dichos indicadores de desempeño a menudo tienen un sentido estadístico y no pueden garantizar la exactitud de los casos individuales. Por ejemplo, un modelo de clasificación de imágenes con una tasa de precisión del 99,5% significa que clasifica correctamente 9950 de las 10 000 imágenes de prueba. Sin embargo, para una nueva imagen, incluso si la confianza de la clasificación generada por el modelo es muy alta, no podemos. se garantiza que el resultado sea correcto. Porque el nivel de confianza y la tasa correcta real no son de naturaleza equivalente. Además, la falta de fiabilidad de f también se manifiesta en la mala interpretabilidad del modelo, en el modelo profundo suele ser difícil para nosotros entender claramente el significado de cada parámetro.
Un ejemplo típico es " contra muestras generadas" . Como se muestra a continuación, la red neuronal reconoce la imagen original como un "panda" con un nivel de confianza del 60 %, pero cuando agregamos un pequeño ruido a la imagen original, la red neuronal reconoce la imagen como un "gibón" con una confianza nivel del 99%. Esto muestra que el modelo de aprendizaje profundo no es tan confiable como se imagina.

En algunos campos clave, como el campo de la medicina, si un modelo no puede garantizar la exactitud de los resultados ni explicarlos bien, solo puede servir como un "asistente" para los humanos y no puede usarse ampliamente.
3. ¿Puedo lograr una "inteligencia artificial fuerte"?
La última pregunta es en realidad un poco metafísica, no un problema técnico específico, pero no está de más discutirlo.
Muchas personas se preocupan por la inteligencia artificial, porque se preocupan por la realización de una "inteligencia artificial fuerte". Siguiendo el método de aprendizaje profundo, parece que podemos entender la inteligencia humana de esta manera: x son las diversas entradas sensoriales de las personas, y es la salida del comportamiento humano, como hablar y comportarse, y f representa la inteligencia humana. Entonces, ¿se puede entrenar la inteligencia humana ajustando violentamente f? Diferentes personas tienen diferentes opiniones sobre esta cuestión, y mi tendencia personal es que no se puede hacer. La inteligencia humana puede ser más similar a la abstracción conceptual, la analogía, el pensamiento y la creación, en lugar de sacar directamente una caja negra F. Los métodos de aprendizaje profundo pueden necesitar un mayor desarrollo para simular la inteligencia real.
Autor: Zhang Xu
https://www.zhihu.com/question/40577663/answer/225319588
Después de aprender un poco de pieles, únete a la diversión.
1. El aprendizaje profundo requiere una gran cantidad de datos y, si la cantidad de datos es demasiado pequeña, provocará un sobreajuste grave.
2. El aprendizaje profundo no tiene ventajas obvias cuando se trata de datos tabulares.Actualmente, es relativamente bueno en visión por computadora, procesamiento de lenguaje natural y reconocimiento de voz. En el contexto de los datos tabulares, todo el mundo está más dispuesto a utilizar modelos como xgboost.
3. El soporte teórico es débil y casi nadie ha trabajado sobre la base matemática del aprendizaje profundo. Todo el mundo pululaba con modelos de papeles de agua.
4. Continuando con el artículo anterior, el ajuste de parámetros básicamente ha caído en el modo de alquimia, y el ajuste de parámetros de aprendizaje profundo ya es una metafísica.
5. El consumo de recursos de hardware es grande y la GPU ya es imprescindible, pero el precio es alto, por lo que el aprendizaje profundo también se denomina juego de hombres ricos.
6. Todavía es difícil de implementar y aterrizar, especialmente en escenarios de aplicaciones móviles.
7. El aprendizaje no supervisado sigue siendo difícil.En la actualidad, el entrenamiento de aprendizaje profundo se basa básicamente en el descenso de gradiente para minimizar la función de pérdida, por lo que se requieren etiquetas. Etiquetar grandes cantidades de datos es costoso. Por supuesto, también hay redes de aprendizaje no supervisadas que se están desarrollando rápidamente, pero estrictamente hablando, GAN y VAE son aprendizaje autosupervisado.
Al ver que el primer artículo fue cuestionado en los comentarios, me gustaría expresar mi opinión: un alumno relativamente fuerte generalmente no se preocupa por la falta de preparación. La red neuronal tiene una gran cantidad de parámetros, siempre que haya suficientes rondas de entrenamiento, teóricamente puede ajustarse completamente al conjunto de entrenamiento. Pero esto no es lo que queremos, y la capacidad de generalización de tal modelo será muy pobre. La razón de este resultado es que la cantidad de datos es demasiado pequeña para representar la distribución detrás de todos los datos. En este caso, la red neuronal se ve obligada a adaptarse a la distribución del subconjunto de datos del conjunto de entrenamiento casi indiscriminadamente, lo que da como resultado un sobreajuste.
Autor: zzzz
https://www.zhihu.com/question/40577663/answer/224756448
Creo que el mayor cuello de botella del aprendizaje profundo es también su mayor ventaja, ambas:
1.formación integral
2.aproximación universal
Su ventaja radica en su fuerte capacidad de ajuste.
La desventaja es que casi no tenemos control sobre el proceso de ajuste medio, todo lo que queremos que aprenda solo puede ser a través de una gran cantidad de datos, una red más compleja (módulo de inicio, más capas) y más restricciones (abandono, regularización ), se espera que finalmente aprenda un juicio equivalente a nuestra cognición.
Para dar un ejemplo específico, queremos juzgar si la imagen es un rostro humano.
Uno de los criterios generales de juicio es si la imagen cubre 2 ojos, 1 nariz y 1 boca, y si la información de posición entre ellos se ajusta a la lógica geométrica. Esta es exactamente la idea del dpm tradicional, aunque cada uno de los pasos anteriores (subtarea) puede ser incorrecto, lo que resultará en que el rendimiento general no será particularmente bueno. Pero en términos relativos, cada subtarea solo necesita menos datos de entrenamiento, los resultados intermedios serán más intuitivos y los resultados finales cumplirán con nuestros estándares de juicio humano.
Pero esto se hace mediante el aprendizaje profundo. Excepto por algunos "conocimientos previos" (conocimiento previo), puede definirlo a través de la estructura de la red (por ejemplo, cnn es en realidad una característica del invariante de posición coherente local de la característica predeterminada ), otra cognición La red solo puede aprender por sí misma a través de una gran cantidad de datos. Algunos elementos simples, como el tamaño de la cara, la posición y la rotación, también se pueden simular mediante el aumento de datos, pero para el color de la piel, el patrón de fondo y los factores del cabello, es necesario encontrar datos adicionales para ampliar la comprensión del problema por parte de la red. Pero aun así, no podemos estar seguros de qué conocimiento de alto nivel ha resumido la red. Cuando le muestro una imagen de Erlang God que no está en los datos de entrenamiento, qué tipo de juicio hará.
Esta es la razón por la que los datos son el elemento más importante en el aprendizaje profundo . Cuando sus datos no son lo suficientemente diversos, es posible que solo aprenda algunas soluciones triviales, pero cuando los datos son lo suficientemente completos, es más probable que resuma características que son más expresivas que la simple nariz y los ojos, pero no podemos entenderlo.
Enlace original:
https://www.zhihu.com/question/40577663/answer/902429604
Editor: Wang Jing
