1. Descripción general de Pix2Pix
La traducción de imágenes es adecuada para una variedad de tareas, desde la simple mejora y edición de fotos hasta tareas más sutiles como escala de grises a RGB. Por ejemplo, digamos que su tarea es el aumento de imágenes y su conjunto de datos es un conjunto de imágenes normales y sus contrapartes aumentadas. El objetivo aquí es aprender un mapeo eficiente de las imágenes de entrada a sus contrapartes de salida.
Los autores de Pix2Pix se basan en el método básico de computación de mapeos de entrada y salida y entrenan una función de pérdida adicional para mejorar este mapeo. Según el artículo de Pix2Pix , su método funciona bien en una variedad de tareas que incluyen (pero no se limitan a) sintetizar fotos a partir de máscaras de segmentación.
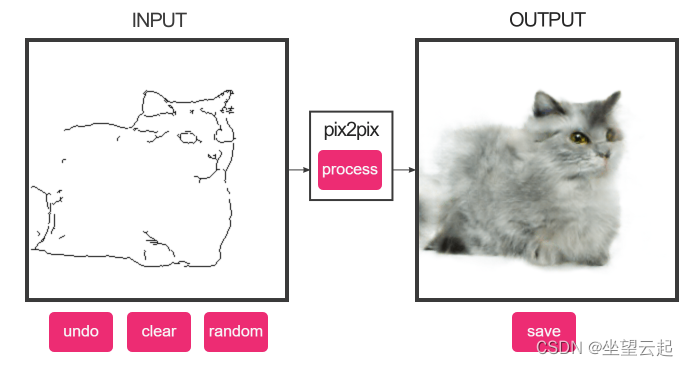
Demostración 1: Generación de gatos a partir de bordes
Demostración 2: Generación de superficies de construcción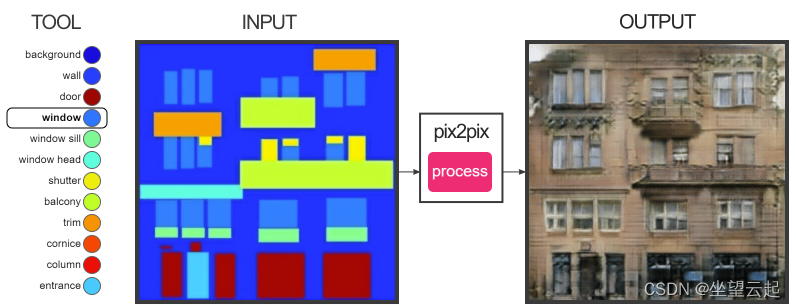
Además de la GAN condicional, Pix2Pix también mezcla la distancia L1 (distancia entre dos puntos) entre las imágenes reales y las generadas.
2. Generador
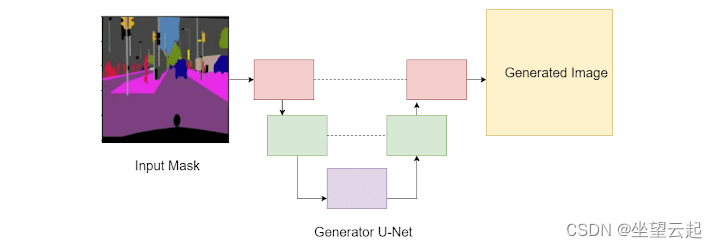
Pix2Pix usa U-Net (abajo) porque tiene conexiones de salto. Una U-Net se caracteriza típicamente por su primer conjunto de capas de muestreo descendente, las capas de cuello de botella, seguidas de capas de muestreo ascendente. El punto clave a recordar aquí es que las capas de muestreo descendente están conectadas a las capas de muestreo ascendente correspondientes, como lo muestran las líneas discontinuas en la imagen a continuación.
Código de referencia
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import concatenate
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras import Model
from tensorflow.keras import Input
class Pix2Pix(object):
def __init__(self, imageHeight, imageWidth):
# initialize the image height and width
self.imageHeight = imageHeight
self.imageWidth = imageWidth
def generator(self):
# initialize the input layer
inputs = Input([self.imageHeight, self.imageWidth, 3])
# down Layer 1 (d1) => final layer 1 (f1)
d1 = Conv2D(32, (3, 3), activation="relu", padding="same")(
inputs)
d1 = Dropout(0.1)(d1)
f1 = MaxPool2D((2, 2))(d1)
# down Layer 2 (l2) => final layer 2 (f2)
d2 = Conv2D(64, (3, 3), activation="relu", padding="same")(f1)
f2 = MaxPool2D((2, 2))(d2)
# down Layer 3 (l3) => final layer 3 (f3)
d3 = Conv2D(96, (3, 3), activation="relu", padding="same")(f2)
f3 = MaxPool2D((2, 2))(d3)
# down Layer 4 (l3) => final layer 4 (f4)
d4 = Conv2D(96, (3, 3), activation="relu", padding="same")(f3)
f4 = MaxPool2D((2, 2))(d4)
# u-bend of the u-bet
b5 = Conv2D(96, (3, 3), activation="relu", padding="same")(f4)
b5 = Dropout(0.3)(b5)
b5 = Conv2D(256, (3, 3), activation="relu", padding="same")(b5)
# upsample Layer 6 (u6)
u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2),
padding="same")(b5)
u6 = concatenate([u6, d4])
u6 = Conv2D(128, (3, 3), activation="relu", padding="same")(
u6)
# upsample Layer 7 (u7)
u7 = Conv2DTranspose(96, (2, 2), strides=(2, 2),
padding="same")(u6)
u7 = concatenate([u7, d3])
u7 = Conv2D(128, (3, 3), activation="relu", padding="same")(
u7)
# upsample Layer 8 (u8)
u8 = Conv2DTranspose(64, (2, 2), strides=(2, 2),
padding="same")(u7)
u8 = concatenate([u8, d2])
u8 = Conv2D(128, (3, 3), activation="relu", padding="same")(u8)
# upsample Layer 9 (u9)
u9 = Conv2DTranspose(32, (2, 2), strides=(2, 2),
padding="same")(u8)
u9 = concatenate([u9, d1])
u9 = Dropout(0.1)(u9)
u9 = Conv2D(128, (3, 3), activation="relu", padding="same")(u9)
# final conv2D layer
outputLayer = Conv2D(3, (1, 1), activation="tanh")(u9)
# create the generator model
generator = Model(inputs, outputLayer)
# return the generator
return generator3. Discriminador
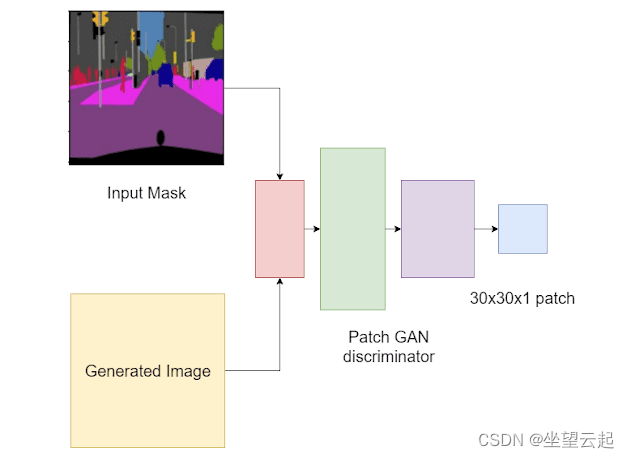
El discriminador es un discriminador Patch GAN. Un discriminador GAN normal toma una imagen como entrada y genera un valor único de 0 (falso) o 1 (verdadero). El discriminador GAN de parches analiza la entrada como parches de imágenes locales. Evaluará si cada parche en la imagen es real o falso.
Código de referencia
def discriminator(self):
# initialize input layer according to PatchGAN
inputMask = Input(shape=[self.imageHeight, self.imageWidth, 3],
name="input_image"
)
targetImage = Input(
shape=[self.imageHeight, self.imageWidth, 3],
name="target_image"
)
# concatenate the inputs
x = concatenate([inputMask, targetImage])
# add four conv2D convolution layers
x = Conv2D(64, 4, strides=2, padding="same")(x)
x = LeakyReLU()(x)
x = Conv2D(128, 4, strides=2, padding="same")(x)
x = LeakyReLU()(x)
x = Conv2D(256, 4, strides=2, padding="same")(x)
x = LeakyReLU()(x)
x = Conv2D(512, 4, strides=1, padding="same")(x)
# add a batch-normalization layer => LeakyReLU => zeropad
x = BatchNormalization()(x)
x = LeakyReLU()(x)
# final conv layer
last = Conv2D(1, 3, strides=1)(x)
# create the discriminator model
discriminator = Model(inputs=[inputMask, targetImage],
outputs=last)
# return the discriminator
return discriminatorEn cuarto lugar, el proceso de formación.
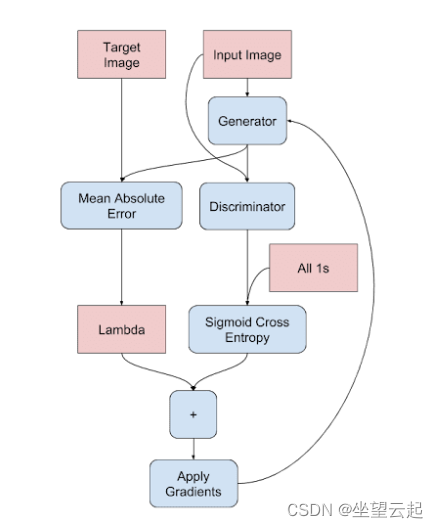
En Pix2Pix, Patch GAN recibirá un par de imágenes: máscara de entrada e imagen generada y máscara de entrada e imagen objetivo. Esto se debe a que la salida depende de la entrada. Por lo tanto, es importante mantener la imagen de entrada en la mezcla ( como se muestra en la siguiente figura , donde el discriminador toma dos entradas).
 https://github.com/bashendixie/ml_toolset/tree/main/%E6%A1 %88% E4%BE%8B100%20%E4%BD%BF%E7%94%A8Pix2Pix%E8%BF%9B%E8%A1%8C%E5%9B%BE%E5%83%8F%E7%BF %BB% E8%AF%91
https://github.com/bashendixie/ml_toolset/tree/main/%E6%A1 %88% E4%BE%8B100%20%E4%BD%BF%E7%94%A8Pix2Pix%E8%BF%9B%E8%A1%8C%E5%9B%BE%E5%83%8F%E7%BF %BB% E8%AF%91