1. Introducción
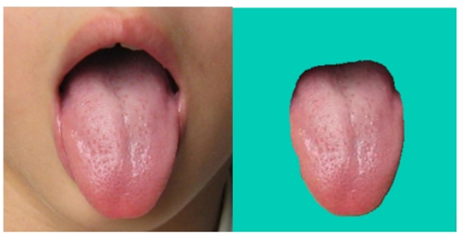
La segmentación de la lengua es la base del diagnóstico y la detección de la lengua. Solo la segmentación precisa de la lengua puede garantizar la precisión del entrenamiento y la predicción posteriores. La verdadera tarea de esta parte es encontrar los píxeles exactos que pertenecen a la lengua en la imagen cargada por el usuario. La segmentación de la lengua pertenece al campo de la segmentación de imágenes biomédicas. El efecto de división es el siguiente:
2 Introducción del conjunto de datos
El conjunto de datos de la imagen de la lengua incluye la imagen de la lengua original y la imagen binaria segmentada, un total de imágenes de 979 * 2. Las imágenes de muestra son las siguientes:

Conjunto de datos + método de adquisición de código fuente:
enlace Xianyu
【闲鱼】https://m.tb.cn/h.Ud0AYdZ?tk=40LV2COORtc CZ0001 「我在闲鱼发布了【舌象图片数据集 舌头图片数据集 舌头图片分割标注完成的数据集】」
点击链接直接打开
3 Introducción del modelo
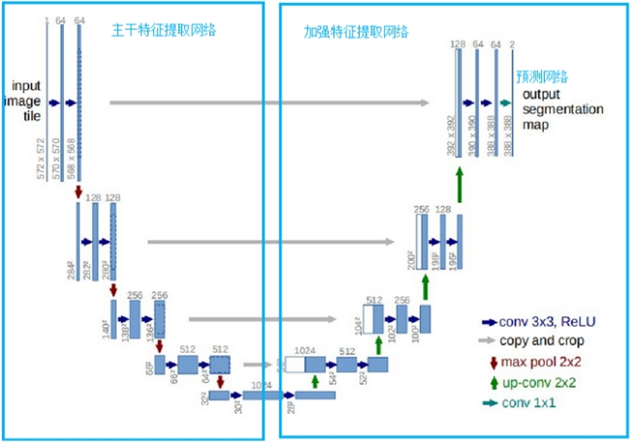
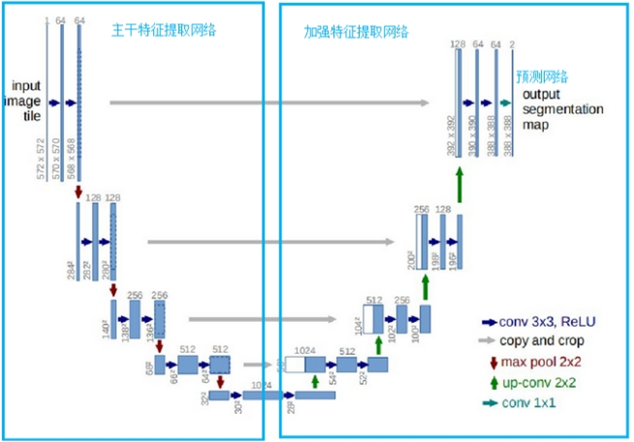
U-Net es un excelente modelo de segmentación semántica. Hay tres partes de U-Net en el diagnóstico de Zhong-e, a saber, la parte de extracción de características principal, la parte de extracción de características mejorada y la parte de predicción. La parte de extracción de características principal se usa para obtener 5 capas de características efectivas preliminares, y luego la parte de extracción de características mejorada se usa para aumentar la muestra de las 5 capas de características efectivas obtenidas anteriormente y realizar la fusión de características. Finalmente, se obtiene una capa de características efectiva que combina todas las características, y la capa de características efectiva final se usa para predecir los píxeles para encontrar los píxeles que pertenecen a la lengua. Los detalles específicos de la operación se muestran en la siguiente figura:
Después del etiquetado, el modelo U-Net se construyó utilizando el marco PyTorch para capturar las características de la imagen de la lengua y predecir la etiqueta de la imagen de la lengua. Para evaluar el modelo, la tasa de pérdida promedio para cada iteración se calcula durante el entrenamiento. La pérdida final por imagen es de alrededor del 2%. Los cambios en la tasa de pérdida promedio específica son los siguientes: el
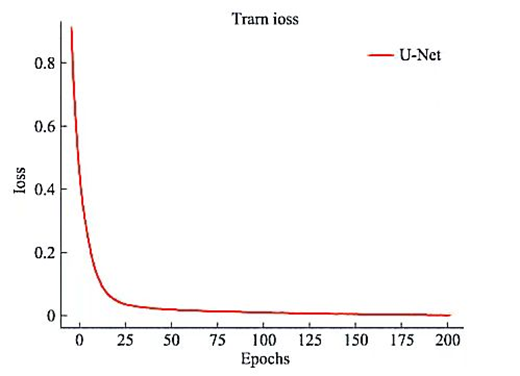
entrenamiento duró 4 días, con un total de 979 imágenes etiquetadas, y la tasa de pérdida promedio prevista final fue de aproximadamente 2%. El modelo predice que el efecto de la segmentación de la lengua es muy ideal. Aquí hay un ejemplo del resultado de la segmentación cuando la tasa de pérdida es del 40% y la tasa de pérdida es del 2%. El ejemplo se muestra en la siguiente figura:
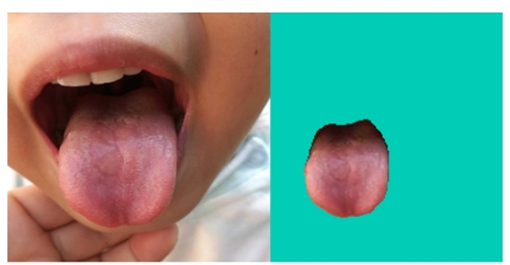
(1) La segmentación resultado cuando la tasa de pérdida es del 40 % Figura

(2) Resultado de la segmentación cuando la tasa de pérdida es del 2 %

Según los resultados de la predicción del modelo, los píxeles que pertenecen a la lengua se comparan y extraen, y las partes que no pertenecen a la lengua se lleno de verde oscuro El efecto final de segmentación de la lengua es el siguiente:
4 Detalles de implementación del código
4.1 Introducción a los documentos relacionados

Hay imágenes de segmentación y anotación en la carpeta notedata, imágenes originales en la carpeta ordata, archivos de modelos de entrenamiento en la carpeta params, imágenes de muestra de prueba en la carpeta de resultados e imágenes de procesos de entrenamiento en la carpeta train_image.
4.2 utils.py
Clase de herramienta: dado que el tamaño de cada imagen en el conjunto de datos es diferente, para garantizar el progreso sin problemas del trabajo de seguimiento, se debe definir aquí una clase de herramienta para escalar la imagen a 256*256 (puede cambiarla a sus propias necesidades).
from PIL import Image
def keep_image_size_open(path, size=(256, 256)):
img = Image.open(path)
temp = max(img.size)
mask = Image.new('RGB', (temp, temp), (0,0,0))
mask.paste(img, (0,0))
mask = mask.resize(size)
return mask
4.3 datos.py
El objetivo principal aquí es hacer coincidir y fusionar la imagen de la etiqueta en el conjunto de datos con la imagen original ~ ¡Hay explicaciones detalladas en los comentarios del código para los pasos específicos!
import os
from torch.utils.data import Dataset
from utils import *
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor()
])
class MyDataset(Dataset):
def __init__(self, path): #拿到标签文件夹中图片的名字
self.path = path
self.name = os.listdir(os.path.join(path, 'notedata'))
def __len__(self): #计算标签文件中文件名的数量
return len(self.name)
def __getitem__(self, index): #将标签文件夹中的文件名在原图文件夹中进行匹配(由于标签是png的格式而原图是jpg所以需要进行一个转化)
segment_name = self.name[index] #XX.png
segment_path = os.path.join(self.path, 'notedata', segment_name)
image_path = os.path.join(self.path, 'ordata', segment_name.replace('png', 'jpg')) #png与jpg进行转化
segment_image = keep_image_size_open(segment_path) #等比例缩放
image = keep_image_size_open(image_path) #等比例缩放
return transform(image), transform(segment_image)
if __name__ == "__main__":
data = MyDataset("E:/ITEM_TIME/project/UNET/")
print(data[0][0].shape)
print(data[0][1].shape)

¡Se puede ver que el conjunto de datos ha sido regularizado!
4.4 red.py
¡La escritura de la red Unet!
from torch import nn
import torch
from torch.nn import functional as F
class Conv_Block(nn.Module): #卷积
def __init__(self, in_channel, out_channel):
super(Conv_Block, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, 3, 1, 1, padding_mode='reflect',
bias=False),
nn.BatchNorm2d(out_channel),
nn.Dropout2d(0.3),
nn.LeakyReLU(),
nn.Conv2d(out_channel, out_channel, 3, 1, 1, padding_mode='reflect',
bias=False),
nn.BatchNorm2d(out_channel),
nn.Dropout2d(0.3),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class DownSample(nn.Module): #下采样
def __init__(self, channel):
super(DownSample, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(channel, channel,3,2,1,padding_mode='reflect',
bias=False),
nn.BatchNorm2d(channel),
nn.LeakyReLU()
)
def forward(self,x):
return self.layer(x)
class UpSample(nn.Module): #上采样(最邻近插值法)
def __init__(self, channel):
super(UpSample, self).__init__()
self.layer = nn.Conv2d(channel, channel//2,1,1)
def forward(self,x, feature_map):
up = F.interpolate(x, scale_factor=2, mode='nearest')
out = self.layer(up)
return torch.cat((out,feature_map),dim=1)
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.c1=Conv_Block(3,64)
self.d1=DownSample(64)
self.c2=Conv_Block(64, 128)
self.d2=DownSample(128)
self.c3=Conv_Block(128,256)
self.d3=DownSample(256)
self.c4=Conv_Block(256,512)
self.d4=DownSample(512)
self.c5=Conv_Block(512,1024)
self.u1=UpSample(1024)
self.c6=Conv_Block(1024,512)
self.u2=UpSample(512)
self.c7=Conv_Block(512,256)
self.u3=UpSample(256)
self.c8=Conv_Block(256,128)
self.u4=UpSample(128)
self.c9=Conv_Block(128,64)
self.out = nn.Conv2d(64,3,3,1,1)
self.Th = nn.Sigmoid()
def forward(self,x):
R1 = self.c1(x)
R2 = self.c2(self.d1(R1))
R3 = self.c3(self.d2(R2))
R4 = self.c4(self.d3(R3))
R5 = self.c5(self.d4(R4))
O1 = self.c6(self.u1(R5,R4))
O2 = self.c7(self.u2(O1,R3))
O3 = self.c8(self.u3(O2,R2))
O4 = self.c9(self.u4(O3,R1))
return self.Th(self.out(O4))
if __name__ == "__main__":
x = torch.randn(2, 3, 256, 256)
net = UNet()
print(net(x).shape)

El resultado de la coincidencia indica que no hay problema ~
4.5 tren.py
código de entrenamiento~
from torch import nn
from torch import optim
import torch
from data import *
from net import *
from torchvision.utils import save_image
from torch.utils.data import DataLoader
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weight_path = 'params/unet.pth'
data_path = 'E:/ITEM_TIME/project/UNET/'
save_path = 'train_image'
if __name__ == "__main__":
dic = []###
data_loader = DataLoader(MyDataset(data_path),batch_size=3,shuffle=True) #batch_size用3/4都可以看电脑性能
net = UNet().to(device)
if os.path.exists(weight_path):
net.load_state_dict(torch.load(weight_path))
print('success load weight')
else:
print('not success load weight')
opt = optim.Adam(net.parameters())
loss_fun = nn.BCELoss()
epoch = 1
while True:
avg = []###
for i, (image,segment_image) in enumerate(data_loader):
image,segment_image = image.to(device),segment_image.to(device)
out_image = net(image)
train_loss = loss_fun(out_image, segment_image)
opt.zero_grad()
train_loss.backward()
opt.step()
if i%5 == 0:
print('{}-{}-train_loss===>>{}'.format(epoch,i,train_loss.item()))
if i%50 == 0:
torch.save(net.state_dict(), weight_path)
#为方便看效果将原图、标签图、训练图进行拼接
_image = image[0]
_segment_image = segment_image[0]
_out_image = out_image[0]
img = torch.stack([_image,_segment_image,_out_image],dim=0)
save_image(img, f'{save_path}/{i}.jpg')
avg.append(float(train_loss.item()))###
loss_avg = sum(avg)/len(avg)
dic.append(loss_avg)
epoch += 1
print(dic)

Se puede ver que el código se ejecuta correctamente ~ la tasa de pérdida anterior es el efecto después de 4 días de entrenamiento, debe ser muy malo al principio, ¡necesita paciencia!
4.6 prueba.py
Pruebe el código para segmentar inteligentemente la imagen ~
from net import *
from utils import keep_image_size_open
import os
import torch
from data import *
from torchvision.utils import save_image
from PIL import Image
import numpy as np
net = UNet().cpu() #或者放在cuda上
weights = 'params/unet.pth' #导入网络
if os.path.exists(weights):
net.load_state_dict(torch.load(weights))
print('success')
else:
print('no loading')
_input = 'xxxx.jpg' #导入测试图片
img = keep_image_size_open(_input)
img_data = transform(img)
print(img_data.shape)
img_data = torch.unsqueeze(img_data, dim=0)
print(img_data)
out = net(img_data)
save_image(out, 'result/result.jpg')
save_image(img_data, 'result/orininal.jpg')
print(out)
#E:\ITEM_TIME\UNET\ordata\4292.jpg
img_after = Image.open(r"result\result.jpg")
img_before = Image.open(r"result\orininal.jpg")
#img.show()
img_after_array = np.array(img_after)#把图像转成数组格式img = np.asarray(image)
img_before_array = np.array(img_before)
shape_after = img_after_array.shape
shape_before = img_before_array.shape
print(shape_after,shape_before)
#将分隔好的图片进行对应像素点还原,即将黑白分隔图转化为有颜色的提取图
if shape_after == shape_before:
height = shape_after[0]
width = shape_after[1]
dst = np.zeros((height,width,3))
for h in range(0,height):
for w in range (0,width):
(b1,g1,r1) = img_after_array[h,w]
(b2,g2,r2) = img_before_array[h,w]
if (b1, g1, r1) <= (90, 90, 90):
img_before_array[h, w] = (144,238,144)
dst[h,w] = img_before_array[h,w]
img2 = Image.fromarray(np.uint8(dst))
img2.save(r"result\blend.png","png")
else:
print("失败!")
Visualización de resultados:
(1) Imagen original (orininal.jpg):

(2) Imagen de segmentación del modelo (result.jpg):
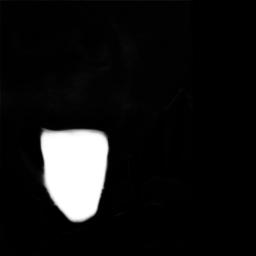
(3) Imagen de restauración de píxeles correspondiente (blend.png): La imagen en (2) es blanca La pieza es lleno con los píxeles de la imagen original, y la parte negra se llena con verde

¡En este punto, la segmentación del cuerpo de la lengua está completa!