Pytorch corrigió algunos parámetros para el entrenamiento de capas especificadas en la red
Descripción del problema
Similar al aprendizaje de transferencia, después de cargar los pesos del modelo, los parámetros de la capa especificada se fijan y se realiza el entrenamiento de las capas restantes, y los parámetros de la capa fija no se actualizan, solo se actualiza la parte de entrenamiento.
Implementación
1. Establecer las condiciones y establecer los parámetros que cumplen las condiciones para no ser actualizados, el código es el siguiente:
for k,v in model2.named_parameters():
if k in Layer1pre.keys():
v.requires_grad = False
2. Luego debes recordar filtrar los parámetros con filtro:
params = filter(lambda p: p.requires_grad, model.parameters())
criterion = nn.CrossEntropyLoss()
# optimizer = torch.optim.Adam(model2.parameters(), lr=learning_rate)
optimizer = torch.optim.Adam(params, lr=learning_rate)
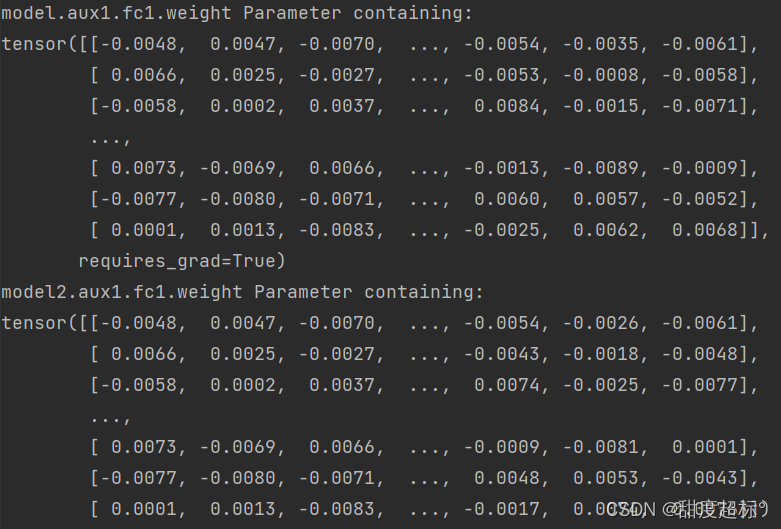
Si falta el paso de filtro, los parámetros fijos no se corregirán y el resultado de salida se actualizará como se muestra en la figura:
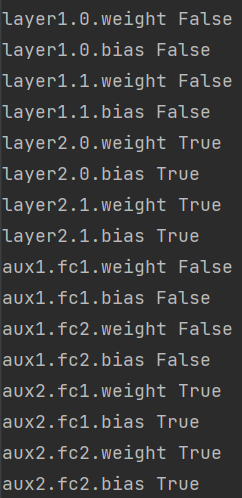
3. Verifique si la configuración es exitosa, la salida fija es Falsa y la salida no fija es Verdadera:
forname, value in model2.named_parameters():
print(name, value.requires_grad) # 打印所有参数requires_grad属性,True或False
Como se muestra en la figura, después del filtro, los parámetros de la primera capa se han establecido en require_grad=False, y solo los parámetros de la segunda capa se actualizarán en el entrenamiento posterior.
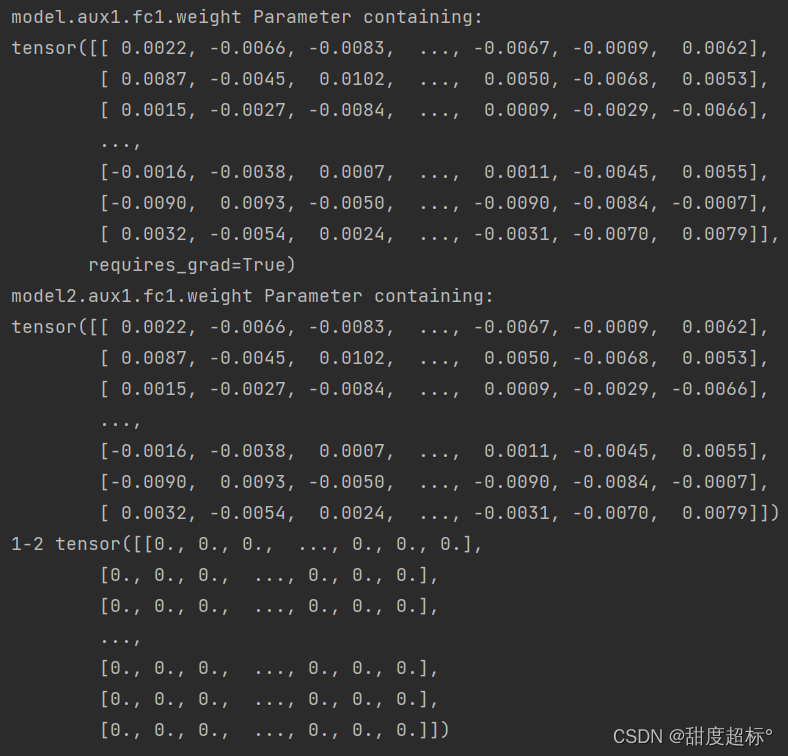
Después de la inspección: los parámetros de la primera capa del modelo 2 no han cambiado, como se muestra en la figura: el
código completo es el siguiente:
# 加载model,model是自己定义好的模型
Layer1pre = torch.load('./ResultData_earlystop/savemodel/checkpoint_model_layer1.pt')
model2 = CNNLayer2(num_classes=10, aux_logits=True)
if use_gpu:
model = model2.cuda()
# 读取参数
model2.load_state_dict(Layer1pre, strict=False)
for k,v in model2.named_parameters():
if k in Layer1pre.keys():
v.requires_grad = False
params = filter(lambda p: p.requires_grad, model.parameters())
criterion = nn.CrossEntropyLoss()
# optimizer = torch.optim.Adam(model2.parameters(), lr=learning_rate)
optimizer = torch.optim.Adam(params, lr=learning_rate)
for name, value in model2.named_parameters():
print(name, value.requires_grad)#打印参数requires_grad属性,True或False
#TrainLoss,TrainAcc,EvalLoss,EvalAcc
loss_train_epochs = [] # 里面包含epoch个训练loss值
acc_train_epochs = []
loss_eval_epoch_all = []
acc_eval_epoch_all = []
loss_train_avg = [] # [0 for epoch in range(num_epochs)]
accuracy_train_avg = []
loss_eval_avg = []
accuracy_eval_avg = []
early_stopping = EarlyStopping(patience=patience, verbose=True, layer=2)
for epoch in range(num_epochs):
epoch_start = time.time()
print('*' * 15, f'Epoch: {
epoch + 1}', '*' * 15)
# print(f'epoch {epoch+1}')
running_loss = 0.0
running_acc = 0.0
preds_all = []
targets_all = []
model2.train()
for i, data in enumerate(train_loader, batch_size):
img, label = data
if use_gpu:
img = img.cuda()
label = label.cuda()
# 向前传播
logits= model2(img)
# print('logits.type:',logits.type)
# loss
loss = criterion(logits, label)
running_loss += loss.item()
# running_loss2 += loss2.item()
# print('loss:', loss, running_loss)
_, pred = torch.max(logits, 1)
# print('Lab result:', label)
running_acc += (pred == label).float().mean()
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
TrainLoss = running_loss / len(train_loader)
TrainAcc = running_acc / len(train_loader)
loss_train_epochs.append(copy.deepcopy(TrainLoss))
acc_train_epochs.append(copy.deepcopy(TrainAcc.numpy()))
print(f'TrainLoss: {
TrainLoss:.6f}')
print(f'TrainAcc: {
TrainAcc:.6f}')
model2.eval()
eval_loss = 0.
eval_acc = 0.
for data in eval_loader:
img, label = data
if use_gpu:
img = img.cuda()
label = label.cuda()
with torch.no_grad():
logits = model2(img)
loss = criterion(logits, label)
eval_loss += loss.item()
_, pred = torch.max(logits, 1)
eval_acc += (pred == label).float().mean()
EvalLoss = eval_loss / len(eval_loader)
EvalAcc = eval_acc / len(eval_loader)
if best_acc2 < EvalAcc:
best_acc2 = EvalAcc
best_epoch = epoch + 1
best_experiment = m + 1
torch.save(model2.state_dict(), save_path)
# bestacc = best_acc
loss_eval_epoch_all.append(copy.deepcopy(EvalLoss))
acc_eval_epoch_all.append(copy.deepcopy(EvalAcc.numpy()))
# early_stopping needs the validation loss to check if it has decresed,
# and if it has, it will make a checkpoint of the current model
early_stopping(EvalLoss, model2,2)
if early_stopping.early_stop:
print("Early stopping")
break
# load the last checkpoint with the best model
model2.load_state_dict(torch.load('./ResultData_earlystop/savemodel/checkpoint_model_layer2.pt'))
print("model.aux1.fc1.weight", model.aux1.fc1.weight)
print("model2.aux1.fc1.weight", model2.aux1.fc1.weight)
print("1-2", model2.aux1.fc1.weight-model2.aux1.fc1.weight)