Hola a todos, hoy les presentaré la aplicación de la inteligencia artificial en la educación 1 - basada en el modelo de entrenamiento bajo el marco pytorch, se usa para la clasificación inteligente de gráficos de problemas matemáticos. Este artículo usará el algoritmo CNN para clasificar automáticamente y reconocer los gráficos en problemas matemáticos. Esta aplicación ayuda a los estudiantes a comprender y resolver mejor los problemas relacionados con las matemáticas. Basado en la función de clasificación inteligente de los gráficos matemáticos de CNN, el campo de la educación puede proporcionar ayudas de aprendizaje más inteligentes y personalizadas, mejorar la capacidad de los estudiantes para reconocer y comprender los gráficos matemáticos y mejorar los efectos del aprendizaje.
Directorio de artículos
Introducción al proyecto
1. Trabajo preliminar
1. Biblioteca de importación
2. Carga del conjunto de datos
2. Construcción del modelo CNN
3. Función del modelo de entrenamiento
4. Modelo de entrenamiento y resultados
5. Resumen
Introducción al proyecto
Usando el algoritmo CNN para clasificar automáticamente los gráficos en el tema de matemáticas, los pasos principales son:
1. Recopilación de datos: Primero, es necesario recopilar una gran cantidad de datos gráficos de temas matemáticos como un conjunto de entrenamiento. Estos datos pueden incluir gráficos que se encuentran comúnmente en varios temas matemáticos, como triángulos, cuadrados, círculos, parábolas, etc.
2. Preprocesamiento de datos: después de la recopilación de datos, es necesario preprocesar los gráficos. Esto implica convertir la imagen en una representación de matriz numérica, normalizarla y escalarla para introducirla en un modelo CNN para su procesamiento.
3. Diseño del modelo CNN: a continuación, se debe diseñar un modelo CNN para la clasificación de imágenes. CNN consta de múltiples capas convolucionales, capas de agrupación y capas totalmente conectadas. La capa convolucional se usa para extraer las características de la imagen, la capa de agrupación se usa para reducir la dimensión del mapa de características y la capa completamente conectada se usa para asignar las características extraídas a categorías específicas.
4. Entrenamiento del modelo: use el conjunto de datos preprocesados, divídalo en un conjunto de entrenamiento y un conjunto de verificación, y luego use el conjunto de entrenamiento para entrenar el modelo CNN. Durante el proceso de entrenamiento, los parámetros del modelo se ajustan continuamente a través del algoritmo de propagación hacia atrás, para que pueda clasificar con mayor precisión los gráficos de los problemas matemáticos.
5. Evaluación del modelo: una vez completada la capacitación, utilice el conjunto de validación para evaluar el modelo. Las métricas de evaluación pueden incluir exactitud, precisión, recuperación, etc. Según los resultados de la evaluación, la estructura y los parámetros del modelo se pueden optimizar aún más.
6. Aplicación del modelo: el modelo CNN entrenado y evaluado se puede utilizar para la clasificación inteligente de gráficos en problemas matemáticos reales. Cuando los estudiantes envían preguntas de matemáticas, el sistema puede extraer automáticamente los gráficos y usar el modelo entrenado para clasificar los gráficos, a fin de ayudar a los estudiantes a comprender mejor el problema y dar la respuesta correcta.
1. Trabajo preliminar
1. Importar biblioteca
import torch
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import random
2. Carga del conjunto de datos
En las siguientes operaciones, usaré funciones para dividir el conjunto de datos, dividirlo en conjunto de entrenamiento y conjunto de verificación, convertir los datos en formato Tensor y luego usar DataLoader para cargar los datos.
Dirección de descarga del conjunto de datos: Enlace: https://pan.baidu.com/s/1hI891lQ6gbiCdq5iVZkelw?pwd=uabv
Código de extracción: uabv
# 设置随机数种子
random.seed(42)
# 定义验证集的比例(可以根据需求自行设置)
val_ratio = 0.2
data_dir = "data"
# 定义图像转换
train_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 使用ImageFolder加载数据集
train_dataset = datasets.ImageFolder(data_dir, transform=train_transforms)
# 计算划分后的大小
dataset_size = len(train_dataset)
val_size = int(dataset_size * val_ratio)
train_size = dataset_size - val_size
# 使用random_split函数进行划分
train_dataset, val_dataset = torch.utils.data.random_split(train_dataset, [train_size, val_size])
# 使用图像数据集和转换定义dataloaders
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=10)
2. Construya el modelo DenseNet
# 加载预训练的densenet121模型
model = models.densenet121(pretrained=True)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
3. Función de modelo de entrenamiento
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if (i+1) % 10 == 0: # 每10个批次打印一次训练信息
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}, Accuracy: {:.2f}%'
.format(epoch+1, num_epochs, i+1, len(train_loader),
running_loss/10, (correct/total)*100))
running_loss = 0.0
# 在每个训练周期结束后计算验证集上的准确率
model.eval()
val_correct = 0
val_total = 0
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, val_predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (val_predicted == labels).sum().item()
val_accuracy = (val_correct / val_total) * 100
print('Epoch [{}/{}], Validation Accuracy: {:.2f}%'
.format(epoch+1, num_epochs, val_accuracy))
model.train()
Hay 4 categorías en el conjunto de datos de entrenamiento de reconocimiento de patrones: circular (círculo), parábola (parábola), cuadrado (cuadrado), triángulo (triángulo)
 triángulo (triángulo)
triángulo (triángulo)
 cuadrado (cuadrado)
cuadrado (cuadrado)

4. Modelo de formación y resultados
Epoch [1/10], Step [10/20], Loss: 7.5273, Accuracy: 5.00%
Epoch [1/10], Step [20/20], Loss: 1.6058, Accuracy: 34.69%
Epoch [1/10], Validation Accuracy: 85.71%
Epoch [2/10], Step [10/20], Loss: 0.2691, Accuracy: 88.00%
Epoch [2/10], Step [20/20], Loss: 0.2711, Accuracy: 89.29%
Epoch [2/10], Validation Accuracy: 93.88%
Epoch [3/10], Step [10/20], Loss: 0.0364, Accuracy: 98.00%
Epoch [3/10], Step [20/20], Loss: 0.1827, Accuracy: 95.92%
Epoch [3/10], Validation Accuracy: 93.88%
Epoch [4/10], Step [10/20], Loss: 0.0616, Accuracy: 98.00%
Epoch [4/10], Step [20/20], Loss: 0.1900, Accuracy: 96.43%
Epoch [4/10], Validation Accuracy: 93.88%
Epoch [5/10], Step [10/20], Loss: 0.0877, Accuracy: 99.00%
Epoch [5/10], Step [20/20], Loss: 0.0481, Accuracy: 98.98%
Epoch [5/10], Validation Accuracy: 93.88%
Epoch [6/10], Step [10/20], Loss: 0.1381, Accuracy: 98.00%
Epoch [6/10], Step [20/20], Loss: 0.0590, Accuracy: 97.45%
Epoch [6/10], Validation Accuracy: 93.88%
Epoch [7/10], Step [10/20], Loss: 0.0234, Accuracy: 99.00%
Epoch [7/10], Step [20/20], Loss: 0.0865, Accuracy: 98.47%
Epoch [7/10], Validation Accuracy: 97.96%
Epoch [8/10], Step [10/20], Loss: 0.0303, Accuracy: 99.00%
Epoch [8/10], Step [20/20], Loss: 0.0073, Accuracy: 99.49%
Epoch [8/10], Validation Accuracy: 97.96%
Epoch [9/10], Step [10/20], Loss: 0.0254, Accuracy: 100.00%
Epoch [9/10], Step [20/20], Loss: 0.0191, Accuracy: 100.00%
Epoch [9/10], Validation Accuracy: 97.96%
Epoch [10/10], Step [10/20], Loss: 0.0116, Accuracy: 100.00%
Epoch [10/10], Step [20/20], Loss: 0.0337, Accuracy: 99.49%
Epoch [10/10], Validation Accuracy: 97.96%
Gráfico de tasa de precisión de resultados de prueba y verificación:
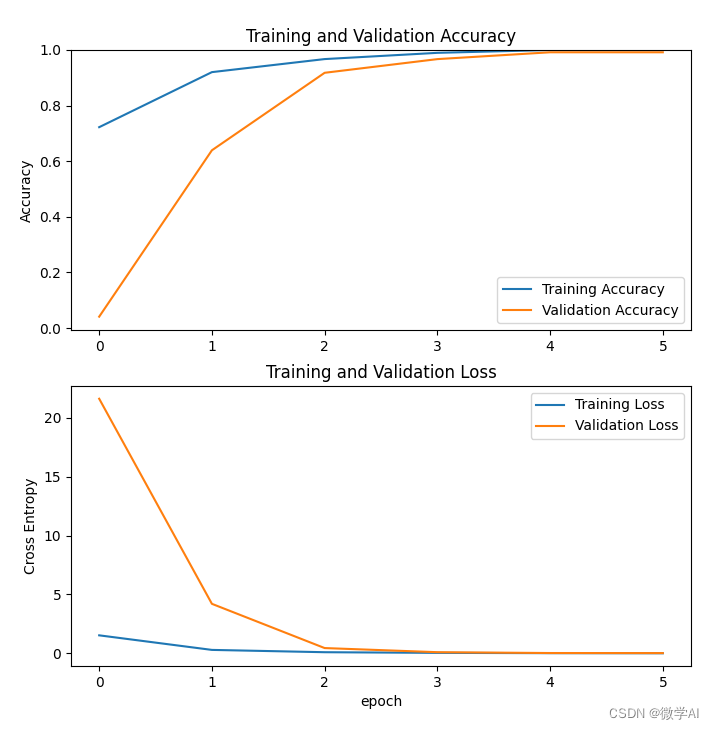
después de 10 iteraciones, la tasa de precisión del conjunto de entrenamiento es tan alta como 99.49% y la tasa de precisión del conjunto de verificación es tan alta como 97.96%.
V. Resumen
Este artículo presenta un ejemplo de la aplicación de la inteligencia artificial en el campo de la educación, es decir, utilizando el algoritmo CNN bajo el marco PyTorch para clasificar y reconocer de manera inteligente gráficos en preguntas de matemáticas. A través de esta aplicación, se puede ayudar a los estudiantes a comprender mejor y resolver problemas relacionados con las matemáticas.
Resumen de ideas:
Antecedentes de la aplicación: presenta la aplicación de la inteligencia artificial en el campo de la educación y cómo utilizar la clasificación inteligente y los gráficos de reconocimiento para mejorar el efecto de aprendizaje de los estudiantes.
Entrenamiento de modelos basado en el marco PyTorch: se menciona que el marco PyTorch se usa para construir y entrenar un modelo CNN para lograr la clasificación y el reconocimiento automáticos de gráficos en problemas matemáticos.
Introducción a la función: explica las ventajas de la función de clasificación inteligente basada en CNN de gráficos matemáticos, como proporcionar ayudas de aprendizaje inteligentes y personalizadas para ayudar a los estudiantes a mejorar su capacidad para reconocer y comprender gráficos matemáticos.
Mejora: enfatizar el valor potencial de la aplicación puede mejorar los resultados de aprendizaje de los estudiantes y mejorar su comprensión de los gráficos matemáticos.