Haga clic en "Taller de visión por computadora" arriba y seleccione "Estrella"
Productos secos entregados lo antes posible

Autor丨zzk
Fuente丨 GiantPandaCV
prefacio
¿Ve cómo nuestra empresa implementa un kernel Softmax CUDA eficiente antes? Todavía no entiendo algunos detalles. Sucede que recientemente se va a hacer un Kernel Reduce+Scale similar. El principio y el mecanismo aún son relativamente similares, así que lo desarrollé y lo volví a entender.
antecedentes
Definimos tal operación ReduceScale:
Suponiendo que Tensor es (N, C), primero calcule el valor absMax en la dimensión C, que registramos como scale, y luego divida cada fila por su propia fila scale, y finalmente emita.
Un código numpy ingenuo es este:
import numpy as np
N = 1000
C = 128
x = np.random.randn(N, C)
scale = np.expand_dims(np.max(np.abs(x), axis=1), 1)
out = x / scale
print(out.shape)Base
Aquí, nuestro BaseLine llama directamente a BlockReduce en la biblioteca cub. Un threadBlock procesa una línea de datos, calcula AbsMaxVal y luego escala. El código es el siguiente:
#include "cuda.h"
#include "cub/cub.cuh"
constexpr int kReduceBlockSize = 128;
template<typename T>
__device__ T abs_func(const T& a) {
return abs(a);
}
template<typename T>
__device__ T max_func(const T a, const T b) {
return a > b ? a : b;
}
template<typename T>
struct AbsMaxOp {
__device__ __forceinline__ T operator()(const T& a, const T& b) const {
return max_func(abs_func(a), abs_func(b));
}
};
template<typename T>
__inline__ __device__ T BlockAllReduceAbsMax(T val) {
typedef cub::BlockReduce<T, kReduceBlockSize> BlockReduce;
__shared__ typename BlockReduce::TempStorage temp_storage;
__shared__ T final_result;
T result = BlockReduce(temp_storage).Reduce(val, AbsMaxOp<T>());
if (threadIdx.x == 0) { final_result = result; }
__syncthreads();
return final_result;
}
template<typename T, typename IDX>
__global__ void ReduceScaleBlockKernel(T* x, IDX row_size, IDX col_size) {
for(int32_t row = blockIdx.x, step=gridDim.x; row < row_size; row+= step){
T thread_scale_factor = 0.0;
for(int32_t col=threadIdx.x; col < col_size; col+= blockDim.x){
IDX idx = row * col_size + col;
T x_val = x[idx];
thread_scale_factor = max_func(thread_scale_factor, abs_func(x_val));
}
T row_scale_factor = BlockAllReduceAbsMax<T>(thread_scale_factor);
for(int32_t col=threadIdx.x; col < col_size; col+=blockDim.x){
IDX idx = row * col_size + col;
x[idx] /= row_scale_factor;
}
}
}En el parámetro x son los datos de entrada, row_size es el número de filas, col_size es el tamaño de la columna
La máquina de prueba es A100 40 GB. Para que la diferencia entre los resultados sea más obvia, configuramos el número de filas para que sea relativamente grande, la forma de entrada es (55296 * 8, 128) y el número de bloques de subprocesos activados depende sobre cómo configurar grid_size y block_size en el kernel de CUDA? Este artículo especifica que la configuración aproximada aquí es (55296, 128), el tipo de datos es Flotante y luego observamos los resultados de ncu:
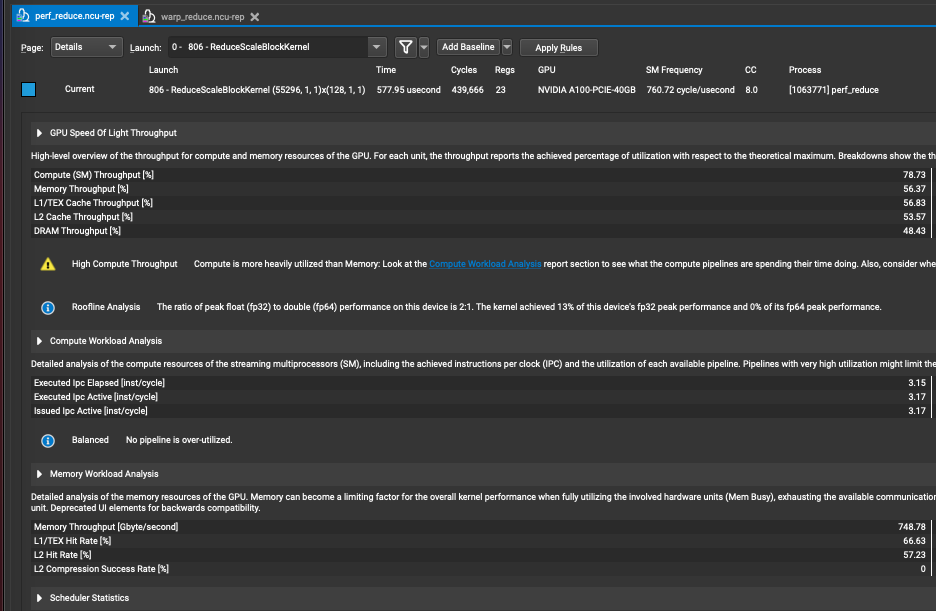
Existen principalmente estos indicadores, el consumo de tiempo es 577.95us y el rendimiento es 748.78Gb/s
Analicémoslo paso a paso basándonos en los puntos mencionados en el artículo de optimización de Softmax:
Paquete de datos de optimización 1
En el anterior de alta eficiencia, fácil de usar y escalable Quiero todo: Diseño y optimización de la biblioteca de plantillas OneFlow CUDA Elementwise La idea de cómo hacer lectura y escritura vectorizada se describe en detalle Cuda admite lectura de hasta 128 bits y escribir, entonces el tipo de datos es Cuando se usa Float, podemos empaquetar 4 Floats consecutivos juntos, leer y escribir al mismo tiempo y mejorar el rendimiento.
Los lectores que han aprendido sobre esto deberían reaccionar. Oye, ¿no hay un tipo llamado float4 en CUDA que hace esto? Sí, pero para admitir la vectorización de otros tipos de datos de manera más flexible, usamos el intercambio de unión. La función de espacio implementa una clase de paquete:
template<typename T, int N>
struct GetPackType {
using type = typename std::aligned_storage<N * sizeof(T), N * sizeof(T)>::type;
};
template<typename T, int N>
using PackType = typename GetPackType<T, N>::type;
template<typename T, int N>
union Pack {
static_assert(sizeof(PackType<T, N>) == sizeof(T) * N, "");
__device__ Pack() {
// do nothing
}
PackType<T, N> storage;
T elem[N];
};Optimizar 2 caché de datos
Toda la lógica del operador necesita leer los datos una vez, calcularlos scaley luego volver a leer los datos scalepara escalarlos. Obviamente, aquí leemos los datos dos veces , y los datos se almacenan en la memoria global, el ancho de banda es relativamente bajo y llevará tiempo leerlos.


Una idea natural es almacenar en caché en registros/memoria compartida. Dado que aquí solo implementamos la versión WarpReduce, la almacenamos en caché en los registros (para otras versiones, consulte el artículo de optimización de Softmax al principio) para reducir una lectura a la memoria global.
template<typename T, typename IDX, int pack_size, int cols_per_thread>
__global__ void ReduceScaleWarpKernel(T* x, IDX row_size, IDX col_size) {
// ...
T buf[cols_per_thread];
// ...Optimización 3 Use Warp para procesar una fila de datos
Comparado con BaseLine, usamos warp como la unidad de Reduce para la operación Primero, veamos brevemente la implementación de WarpReduce.
template<typename T>
struct AbsMaxOp {
__device__ __forceinline__ T operator()(const T& a, const T& b) const {
return max_func(abs_func(a), abs_func(b));
}
};
template<typename T>
__inline__ __device__ T WarpAbsMaxAllReduce(T val){
for(int lane_mask = kWarpSize/2; lane_mask > 0; lane_mask /= 2){
val = AbsMaxOp<T>()(val, __shfl_xor_sync(0xffffffff, val, lane_mask));
}
return val;
}Este código se ve a menudo en otros BlockReduces. Se __shfl_xor_sync usa para lograr la comparación. La instrucción shuffle permite que dos subprocesos en el mismo warp lean directamente los registros del otro.
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);Entre ellos mask hay una máscara para el hilo, generalmente todos los hilos tienen que participar en el cálculo, por lo que mask es 0xffffffff
var es el valor del registro, laneMask que es la máscara utilizada para XOR bit a bit
Aquí se introduce un concepto llamado Carril, que representa el número de hilo en la urdimbre del hilo.
El diagrama esquemático es el siguiente:
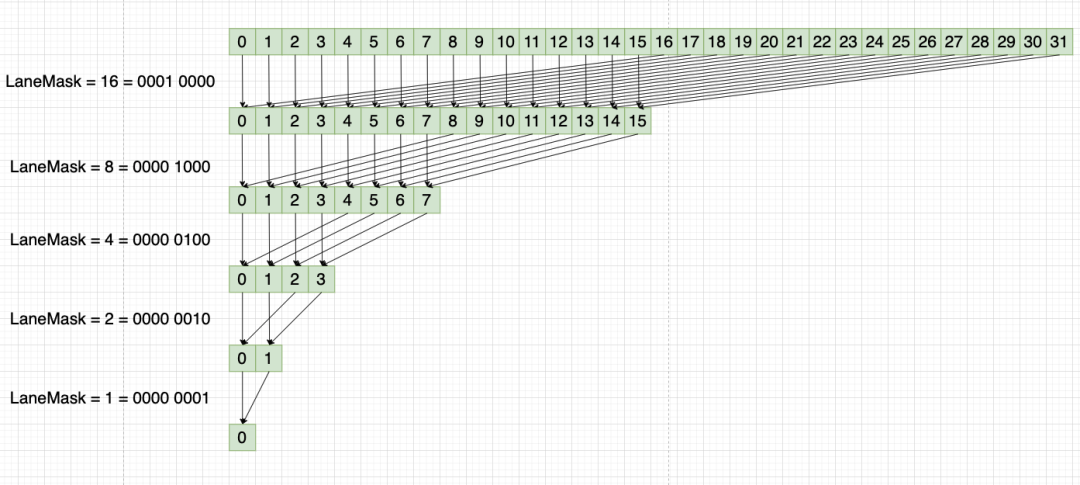
Cuando laneMask = 16, su binario es 0001 0000, y luego cada subproceso de la deformación se XOR con laneMask
Como:
0000 0000 x o 0001 0000 = 0001 0000 = 16
0000 0001 x o 0001 0000 = 0001 0001 = 17
0000 0010 x o 0001 0000 = 0001 0010 = 18
Y así sucesivamente, y finalmente obtener el valor absmax en un Warp.
A continuación comenzamos a escribir Kernel, los parámetros de la plantilla son:
tipo de datos T
Tipo de índice IDX
pack_size El número de paquetes, como el flotador, se puede empaquetar en 4, lo que corresponde a pack_size=4
cols_per_thread El número de elementos que cada subproceso necesita procesar. Por ejemplo, el tamaño de una fila es 128, y tenemos 32 subprocesos en una deformación, entonces aquí es 128/32 = 4
template<typename T, typename IDX, int pack_size, int cols_per_thread>
__global__ void ReduceScaleWarpKernel(T* x, IDX row_size, IDX col_size) {
// ...
}Al igual que BaseLine, nuestro tamaño de bloque todavía está configurado en 128 subprocesos y una deformación es de 32 subprocesos, por lo que nuestro bloque se puede organizar en (32, 4), incluidas 4 deformaciones.
Según esta división de niveles, podemos calcular:
global_thread_group_id El índice global de la deformación actual
num_total_thread_group número total de deformaciones
lane_id ID de subproceso dentro de la deformación
num_packs El número de paquetes, es decir, el número de elementos que cada subproceso necesita procesar / pack_size
const int32_t global_thread_group_id = blockIdx.x * blockDim.y + threadIdx.y;
const int32_t num_total_thread_group = gridDim.x * blockDim.y;
const int32_t lane_id = threadIdx.x;
using LoadStoreType = PackType<T, pack_size>;
using LoadStorePack = Pack<T, pack_size>;
T buf[cols_per_thread];
constexpr int num_packs = cols_per_thread / pack_size;Dado que el número de deformaciones lanzadas es menor que el número de filas, necesitamos introducir un bucle for.
Supongamos que tenemos cols = 256, entonces cada hilo en la urdimbre necesita procesar 256 / 32 = 8 elementos, y 4 flotantes se pueden empaquetar juntos, por lo que cada hilo en nuestra urdimbre necesita procesar 2 paquetes, así que también Para introducir un bucle for en num_packs para asegurarse de que se lea toda la línea:

Después de leer un paquete a la vez, los colocamos en registros y los almacenamos en caché uno por uno, y calculamos AbsMaxVal en el hilo.
for(IDX row_idx = global_thread_group_id; row_idx < row_size; row_idx += num_total_thread_group){
T thread_abs_max_val = 0.0;
for(int pack_idx = 0; pack_idx < num_packs; pack_idx++){
const int32_t pack_offset = pack_idx * pack_size;
const int32_t col_offset = pack_idx * kWarpSize * pack_size + lane_id * pack_size;
const int32_t load_offset = (row_idx * col_size + col_offset) / pack_size;
LoadStorePack load_pack;
load_pack.storage = *(reinterpret_cast<LoadStoreType*>(x)+ load_offset);
#pragma unroll
for(int i = 0; i < pack_size; i++){
buf[pack_offset] = load_pack.elem[i];
thread_abs_max_val = max_func(thread_abs_max_val, abs_func(buf[pack_offset]));
}
}Luego llamamos WarpAbsMaxAllReduce a reduce para obtener AbsMaxVal en la deformación del hilo y escalamos los datos almacenados en caché numéricamente.
T warp_max_val = WarpAbsMaxAllReduce<T>(thread_abs_max_val);
#pragma unroll
for (int col = 0; col < cols_per_thread; col++) {
buf[col] = buf[col] / warp_max_val;
}Finalmente, similar a la lectura al principio, volvemos a escribir el valor en el registro, y la lógica de cálculo del índice relevante es la misma:
for(int pack_idx = 0; pack_idx < num_packs; pack_idx++){
const int32_t pack_offset = pack_idx * pack_size;
const int32_t col_offset = pack_idx * pack_size * kWarpSize + lane_id * pack_size;
const int32_t store_offset = (row_idx * col_size + col_offset) / pack_size;
LoadStorePack store_pack;
#pragma unroll
for(int i = 0; i < pack_size; i++){
store_pack.elem[i] = buf[pack_offset + i];
}
*(reinterpret_cast<LoadStoreType*>(x)+ store_offset) = store_pack.storage;
}El código completo es el siguiente:
template<typename T>
__inline__ __device__ T WarpAbsMaxAllReduce(T val){
for(int lane_mask = kWarpSize/2; lane_mask > 0; lane_mask /= 2){
val = AbsMaxOp<T>()(val, __shfl_xor_sync(0xffffffff, val, lane_mask));
}
return val;
}
template<typename T, typename IDX, int pack_size, int cols_per_thread>
__global__ void ReduceScaleWarpKernel(T* x, IDX row_size, IDX col_size) {
const int32_t global_thread_group_id = blockIdx.x * blockDim.y + threadIdx.y;
const int32_t num_total_thread_group = gridDim.x * blockDim.y;
const int32_t lane_id = threadIdx.x;
using LoadStoreType = PackType<T, pack_size>;
using LoadStorePack = Pack<T, pack_size>;
T buf[cols_per_thread];
constexpr int num_packs = cols_per_thread / pack_size;
for(IDX row_idx = global_thread_group_id; row_idx < row_size; row_idx += num_total_thread_group){
T thread_abs_max_val = 0.0;
for(int pack_idx = 0; pack_idx < num_packs; pack_idx++){
const int32_t pack_offset = pack_idx * pack_size;
const int32_t col_offset = pack_idx * kWarpSize * pack_size + lane_id * pack_size;
const int32_t load_offset = (row_idx * col_size + col_offset) / pack_size;
LoadStorePack load_pack;
load_pack.storage = *(reinterpret_cast<LoadStoreType*>(x)+ load_offset);
#pragma unroll
for(int i = 0; i < pack_size; i++){
buf[pack_offset] = load_pack.elem[i];
thread_abs_max_val = max_func(thread_abs_max_val, abs_func(buf[pack_offset]));
}
}
T warp_max_val = WarpAbsMaxAllReduce<T>(thread_abs_max_val);
#pragma unroll
for (int col = 0; col < cols_per_thread; col++) {
buf[col] = buf[col] / warp_max_val;
}
for(int pack_idx = 0; pack_idx < num_packs; pack_idx++){
const int32_t pack_offset = pack_idx * pack_size;
const int32_t col_offset = pack_idx * pack_size * kWarpSize + lane_id * pack_size;
const int32_t store_offset = (row_idx * col_size + col_offset) / pack_size;
LoadStorePack store_pack;
#pragma unroll
for(int i = 0; i < pack_size; i++){
store_pack.elem[i] = buf[pack_offset + i];
}
*(reinterpret_cast<LoadStoreType*>(x)+ store_offset) = store_pack.storage;
}
}
}Aquí somos convenientes para probar y escribir directamente algunos parámetros de plantilla al llamar
constexpr int cols_per_thread = 128 / kWarpSize;
ReduceScaleWarpKernel<float, int32_t, 4, cols_per_thread><<<55296, block_dim>>>(device_ptr, row_size, col_size);Finalmente, echemos un vistazo a los resultados de ncu: 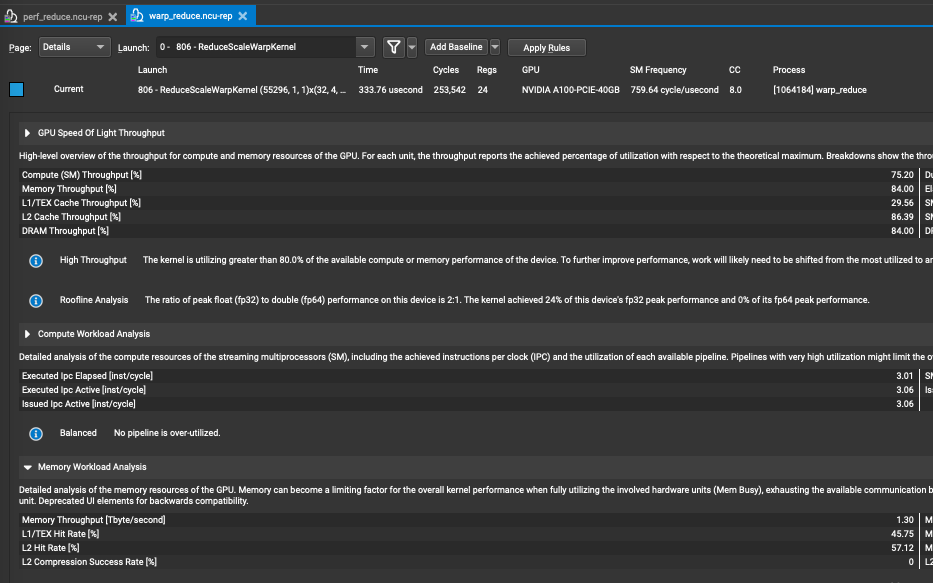 el rendimiento alcanzó 1.3T y el tiempo es 333us, que es un 73% más rápido que BaseLine.
el rendimiento alcanzó 1.3T y el tiempo es 333us, que es un 73% más rápido que BaseLine.
Resumir
Hay más casos especiales, puede consultar el código optimizado por Softmax, aquí solo se implementa el primer método de cálculo Warp. Creo que se ve bien, pero todavía es un poco difícil de entender si lo escribo yo mismo. Espero que este blog pueda ayudar a los lectores a entender el uso de algunos warps.
Este artículo es solo para uso académico, si hay alguna infracción, comuníquese para eliminar el artículo.
Descarga y estudio de productos secos
Respuesta entre bastidores: material didáctico de la Universitat Autònoma de Barcelona , puede descargar el material didáctico de alta calidad 3D Vison acumulado por universidades extranjeras durante varios años
Respuesta de fondo: libros de visión por computadora , puede descargar el pdf de libros clásicos en el campo de la visión 3D
Respuesta entre bastidores: cursos de visión 3D, puede aprender excelentes cursos en el campo de la visión 3D
Cursos de calidad visual 3D recomendados:
1. Tecnología de fusión de datos multisensor para conducción autónoma
2. ¡Una ruta de aprendizaje completa para la detección de objetivos de nube de puntos 3D en el campo de la conducción autónoma! (Modo único + multimodal/datos + código)
3. Comprender a fondo la reconstrucción visual en 3D: análisis de principios, explicación del código y optimización y mejora
4. El primer curso de procesamiento de nubes de puntos doméstico para combate a nivel industrial
5. Visión láser - Clasificación del algoritmo SLAM de fusión IMU-GPS
y
explicación
del código Principio del algoritmo clave SLAM láser para interiores y exteriores, código y combate real (cartógrafo + LOAM + LIO-SAM)
11. El despliegue real de modelos de aprendizaje profundo en la conducción autónoma
12. Modelo de cámara y calibración (monocular + binocular + ojo de pez)
13. ¡Pesado! Cuadricópteros: algoritmos y práctica
14. ROS2 desde el inicio hasta el dominio: teoría y práctica
¡Pesado! Taller de Visión por Computador - Se ha establecido un Grupo de Intercambio de Aprendizaje
Escanee el código para agregar un asistente de WeChat, y puede solicitar unirse al taller de visión 3D: grupo de intercambio WeChat de redacción y envío de artículos académicos, que tiene como objetivo intercambiar asuntos de redacción y envío, como conferencias principales, revistas principales, SCI e EI.
Al mismo tiempo , también puede solicitar unirse a nuestro grupo de intercambio de dirección de subdivisión. En la actualidad, hay principalmente aprendizaje de código fuente de la serie ORB-SLAM, visión 3D , CV y aprendizaje profundo , SLAM , reconstrucción 3D , posprocesamiento de nubes de puntos , conducción automática, introducción de CV, medición 3D, VR / AR, reconocimiento facial 3D, imágenes médicas, detección de defectos, reidentificación de peatones, seguimiento de objetivos, aterrizaje visual de productos, competencia visual, reconocimiento de matrículas, selección de hardware, estimación de profundidad, intercambios académicos , intercambios de búsqueda de empleo y otros grupos de WeChat, escanee la siguiente cuenta de WeChat más el grupo, comentarios: "dirección de investigación + escuela/empresa + apodo", por ejemplo: "visión 3D + Universidad Jiaotong de Shanghái + Jingjing". Comente de acuerdo con el formato, de lo contrario no será aprobado. Después de que la adición sea exitosa, se invitará al grupo WeChat relevante de acuerdo con la dirección de la investigación. Póngase en contacto con las presentaciones originales .

▲Presione prolongadamente para agregar un grupo de WeChat o contribuir

▲Presione prolongadamente para seguir la cuenta oficial
Visión 3D desde la entrada hasta el planeta del conocimiento competente : cursos de video para el campo de la visión 3D (serie de reconstrucción 3D , serie de nube de puntos 3D, serie de luz estructurada , calibración mano-ojo, calibración de cámara , láser/visión SLAM, conducción automática, etc. ) , resumen de puntos de conocimiento, entrada y ruta de aprendizaje avanzado, el último papel compartido y respuesta a preguntas para un cultivo en profundidad, y orientación técnica de ingenieros de algoritmos de varias fábricas grandes. Al mismo tiempo, Planet cooperará con empresas conocidas para lanzar trabajos de desarrollo de algoritmos relacionados con la visión 3D e información de acoplamiento de proyectos, creando un área de reunión para fanáticos acérrimos que integra tecnología y empleo. conocimiento para crear un mejor mundo de IA.
Aprenda la tecnología central de la visión 3D, escanee y vea la introducción, reembolso incondicional dentro de los 3 días

Hay materiales tutoriales de alta calidad en el círculo, que pueden responder preguntas y ayudarlo a resolver problemas de manera eficiente
Lo encuentro útil, por favor dale me gusta y mira ~