Este artículo es compartido por la comunidad de HUAWEI CLOUD " Uso de consultas parametrizadas para mejorar el rendimiento de las consultas de cifrado: Tomando el motor gráfico GES de HUAWEI CLOUD como ejemplo ", autor: Mayfly and the Sea.
En DBMS, la consulta parametrizada se considera un medio efectivo para prevenir ataques de inyección SQL. HUAWEI CLOUD Graph Engine GES brinda compatibilidad con consultas parametrizadas para lenguajes de consulta gremlin y cypher.El uso de consultas parametrizadas no solo puede evitar que los usuarios front-end ingresen arbitrariamente comandos maliciosos para afectar la ejecución de declaraciones, sino que también puede usar de manera efectiva la memoria caché de compilación de consultas para mejorar el rendimiento de las consultas.
Consulta parametrizada (Parameterized Query), la explicación en Wiki es: cuando el cliente envía y solicita la declaración de consulta al servidor de datos, utiliza un nombre de variable en lugar del valor o la cadena de datos ingresada por el usuario. Y explique en la solicitud body a qué se refiere cada nombre de variable. En este caso, dado que el contenido al que hace referencia el nombre de la variable no participará en la compilación de la consulta del lenguaje SQL, incluso si los datos de entrada del usuario contienen algunas instrucciones destructivas, la base de datos no lo ejecutará.
Por ejemplo, para usar Cypher-JDBC-Driver para acceder a HUAWEI CLOUD Graph Engine, puede configurar los parámetros correspondientes:
public static void main(String[] args) throws ClassNotFoundException {
Class.forName("com.huawei.ges.jdbc.Driver");
String url = "jdbc:ges:http://{
{graph_ip}}:{
{graph_port}}/ges/v1.0/{
{project_id}}/graphs/{
{graph_name}}/action?action_id=execute-cypher-query";
url = url.replace("{
{graph_ip}}", ip).replace("{
{graph_port}}",port + "").replace("{
{project_id}}", projectId).replace("{
{graph_name}}", graphName);
Properties prop = new Properties();
prop.setProperty("X-Auth-Token", token);
try(Connection conn = DriverManager.getConnection(url,prop)){
String query = "match (n:movie) where n.genres=? return n.title";
try(PreparedStatement stmt = conn.prepareStatement(query)){
stmt.setString(1, "Comedy");
try(ResultSet rs = stmt.executeQuery()){
while(rs.next()) {
System.out.println(rs.getString("n.title"));
}
}
}
} catch (SQLException e) {
// do something for e.
}
}
El signo de interrogación en la declaración de consulta es una variable de consulta parametrizada de estilo JDBC, y se establece un valor "Comedy" a través del método setString en el siguiente código. Además, el motor de gráficos también es compatible con consultas parametrizadas de estilo API tranquilas; consulte la documentación del sitio web oficial para obtener más detalles .
Al mismo tiempo, la consulta parametrizada permite que se ejecuten diferentes entradas de usuario utilizando la misma declaración de consulta parametrizada, que puede utilizar de manera eficiente la caché de consultas de la base de datos, ahorrar tiempo de compilación de consultas y mejorar el rendimiento de las consultas. Por ejemplo, la siguiente figura muestra varias consultas de 2 y 3 saltos construidas con el conjunto de datos de Freebase, ejecutadas en el GES de Huawei Cloud Graph Engine y el cambio de QPS antes y después de la consulta parametrizada. Se puede ver que al usar consultas parametrizadas, qps se ha mejorado de 2 a 8 veces.

¿Por qué las consultas parametrizadas pueden mejorar el qps de consulta? Primero, presentemos brevemente lo que hace el servicio de datos después de recibir la declaración de consulta. En el campo de la gestión de datos, cuando un servicio de datos recibe una declaración de consulta, normalmente realiza los siguientes pasos: análisis léxico y gramatical, generación del plan de consulta y ejecución del plan de consulta, como se muestra en la figura.
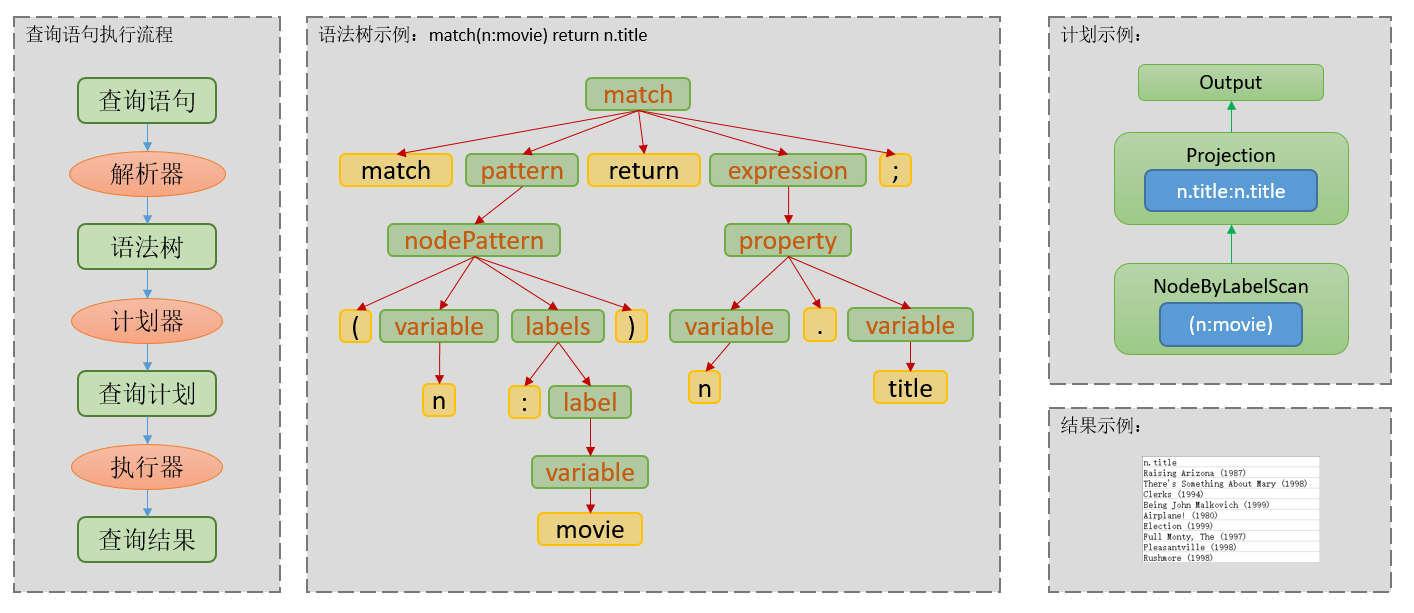
Aquí hay una breve introducción a la generación de planes de consulta. En la actualidad, la mayoría de las estrategias de generación de planes de consulta son generación de planes de consulta basada en costos, generación de planes de consulta basada en reglas o una combinación de ambas. Independientemente de la generación del plan de consulta, es una tarea computacionalmente intensiva, que consume los recursos informáticos del servidor. Al mismo tiempo, el sistema solo puede procesar un número limitado de tareas de generación del plan de consulta en paralelo. Dentro del generador de planes, la mayoría de las bases de datos tendrán un caché de consultas incorporado, es decir, dentro de un cierto rango de tiempo, cuando se ingresa la misma declaración de consulta en el planificador, el planificador primero verificará si hay un plan disponible de la consulta. caché Si el plan es demasiado largo o no hay un plan disponible, el proceso de generación del plan se ejecutará.
Por lo tanto, cuando se utiliza una consulta parametrizada, dado que el cuerpo de la declaración de consulta que usa diferentes parámetros es el mismo, es más probable que se considere la misma declaración de consulta en la etapa de compilación de la consulta, para lograr el efecto de "consultas múltiples, una compilación", lo que mejora el rendimiento de las consultas. Eficiencia de la compilación.
apéndice:
Escala de formato de gráfico de propiedad de conjunto de datos de base libre:
| número de puntos | 61440292 |
| número de lados | 136253874 |
| número de etiquetas | 5417 |
查询语句:
2hop_Q1: coincidencia (n1)-[r]->(m1)-->(p1) donde id(n1)=$vertex return id(p1) límite 100
2hop_Q2: coincidencia (n1)-[r]- >(m1)-->(p1) donde id(n1)=$vertex return p1.name limit 100
2hop_Q3: match(n)-[r]->(m)-->(p) where id(n) =$vertex and m.games > 10 and p.name contiene 'NBA' return p
3hop_Q1: match (n1)-[r1]-(m1)-[r2]-(p1)--(p2) where id(n1) )=$vertex and m1.game > 0 return id(p2) límite 100
3hop_Q2: coincidencia (n1)-[r1]-(m1) coincidencia (m1)-[r2]-(p1) coincidencia (p1)--( p2) donde id(n1)=$vertex y m1.games > 0 return id(p2)
Referencias relacionadas:
[1] Consulta parametrizada_Enciclopedia de Baidu: https://baike.baidu.com/item/%E5%8F%82%E6%95%B0%E5%8C%96%E6%9F%A5%E8%AF %A2/ 4841802?fr=aladino
[2] API de cifrado GES: API de operación de cifrado (2.2.16)_Graph Engine Service GES_API Reference_Business API_HUAWEI CLOUD
[3] Github - opencypher: https://github.com/opencypher/openCypher
Haga clic en Seguir para conocer las nuevas tecnologías de HUAWEI CLOUD por primera vez ~