Hace algún tiempo, el sistema del que era responsable de probar tuvo problemas al ejecutarse en el entorno de producción . El sistema tiene altos requisitos en cuanto al tiempo de respuesta. Cuando ocurre el problema, la concurrencia es muy alta. Se produce una gran cantidad de tiempos de espera de solicitudes. La proporción de solicitudes de tiempo de espera aumenta cada vez más a medida que pasa el tiempo. Al final, casi todas las solicitudes fallan. . Después de reiniciar todos los procesos, pronto se produjo un tiempo de espera nuevamente.
Después de la investigación, se descubrió que una declaración de consulta de la base de datos se modificó cuando la nueva versión implementó una determinada función. Después de la modificación, las condiciones de consulta de la declaración de consulta no utilizaron el campo de índice y la tabla consultada era enorme en el entorno de producción. , Entonces esta operación de consulta El consumo de tiempo ha cambiado de milisegundos a segundos, lo que forma la llamada consulta lenta, que junto con una gran cantidad de concurrencia, ocurre una tragedia.
Después del incidente, nuestro equipo de pruebas reflexionó: ¿Por qué no se descubrió un problema tan grave en el entorno de pruebas? Se resumen dos razones : en primer lugar, la cantidad de concurrencia en el entorno de prueba para las pruebas funcionales no es alta y no se producirá ningún tiempo de espera incluso si una sola solicitud se ralentiza; en segundo lugar, el volumen de datos de la tabla de la base de datos del entorno de prueba es mucho menor que el del entorno de producción , por lo que las operaciones de consulta única son mucho más rápidas que las de producción, por lo que las solicitudes rara vez se agotan durante las pruebas de estrés.
buscar
En resumen, es difícil identificar manualmente una consulta lenta durante el proceso de prueba. Para evitar que este tipo de problema vuelva a ocurrir, hicimos algunos intentos en las pruebas de versiones posteriores.
Debido a que ya contamos con herramientas internas de escaneo de código, cada versión identificará algunos problemas mediante el escaneo, por lo que primero pensamos en escanear estáticamente el código original, buscar todas las declaraciones de consulta de la base de datos y luego analizarlas. Después de la operación real, descubrimos que nuestro sistema utiliza una gran cantidad de marcos para las operaciones de bases de datos. Diferentes módulos usan diferentes marcos. Las declaraciones de la base de datos extraídas son todas extrañas y contienen elementos de código, que no son declaraciones que se puedan ejecutar directamente. Para sistemas grandes , manual Es demasiado trabajo analizar estas declaraciones y este método no es factible.
Entonces pensamos que podemos resolver este problema desde el lado de la base de datos. Al activar el interruptor de registro de consultas lentas de Mysql, podemos registrar todas las operaciones de consulta de la base de datos que son más largas que el tiempo de configuración long_query_time durante la prueba funcional y luego analizar si Hay un problema de consulta lenta uno por uno.
Durante el proceso, detectamos muchas declaraciones de consulta que se ejecutaban lentamente, pero después del análisis, descubrimos que la mayoría de estas declaraciones fueron realizadas por probadores para consultar manualmente la base de datos. Lo que es aún más lamentable es que debido al pequeño orden de magnitud de datos de prueba, problemas de producción que ocurrieron antes El tiempo de ejecución de la declaración de consulta problemática en el entorno de prueba no excedió long_query_time, por lo que no se pudo identificar.
Se puede ver que este método tiene una alta probabilidad de falsos positivos y falsos negativos y no es factible.
innovación
Las herramientas existentes no pueden satisfacer nuestras necesidades de identificar declaraciones de consulta lentas, por lo que decidimos crear nuestro propio conjunto de herramientas. A través de muchos análisis y experimentos, obtuvimos una solución eficiente, precisa y versátil:
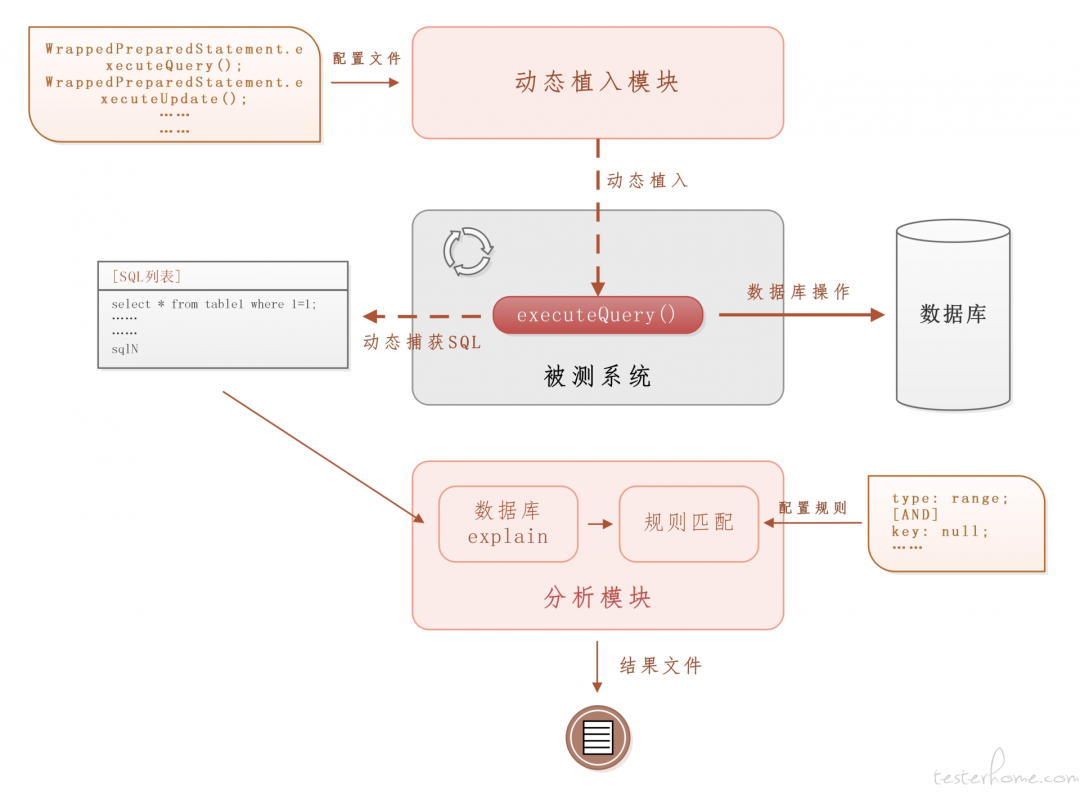
Después del análisis, es necesario resolver dos problemas para identificar declaraciones de consulta lentas : primero, cómo obtener la declaración de consulta ejecutada por el sistema ; segundo, cómo analizar si una determinada consulta es una consulta lenta .
Para resolver el primer problema, pensamos en utilizar tecnología de instrumentación .
Para una operación de consulta, no importa cómo esté escrito el código de la aplicación de la capa superior o qué marco de base de datos se utilice, esta operación eventualmente interactuará con la base de datos de destino y, al interactuar, debe ser una declaración SQL estándar. Con base en esto, realizamos un análisis integral de esta aplicación. Nuestro sistema está implementado en Jboss. A través del análisis capa por capa, encontramos este método que realmente realiza operaciones de consulta e interacción con la base de datos. Se encuentra en el paquete JCA de Jboss. y se reparte de la siguiente manera: Dos lugares:
① org.jboss.jca.adapters.jdbc.WrappedPreparedStatement.executeQuery()② org.jboss.jca.adapters.jdbc.WrappedStatement.executeQuery()
A través de una gran cantidad de experimentos, hemos determinado que todas las operaciones de consulta de bases de datos en nuestro sistema deben llamar a uno de ①② para completarse (otros sistemas pueden llamar a otros métodos de JCA con una lógica de implementación diferente). Al establecer un punto de interrupción en ①②, encontramos que la declaración SQL dentro del método ①② es completamente visible.
A continuación, utilizamos Java Instrument Api y sus componentes derivados de código abierto para crear un programa agente. Inicie el agente y el agente insertará dinámicamente códigos auxiliares en estos dos lugares cuando se esté ejecutando el programa del sistema de aplicación. El contenido del código auxiliar es muy simple: imprima la instrucción SQL que se está ejecutando en la memoria del cuerpo del método actual en una ubicación fija ( suponiendo que coloquemos la declaración SQL en el archivo de registro A). En comparación con escribir una oración adicional de impresión dentro del cuerpo del método de ①②, simplemente realizar una operación de impresión no causará ninguna interferencia en la lógica empresarial.
Entonces hemos logrado algo como esto: cuando el sistema de aplicación quiere realizar una operación de consulta de base de datos, llamará a uno de ①② para ejecutar la consulta SQL. Cuando se llama a ①②, la instrucción SQL en ejecución se enviará al archivo de registro A. De esta manera, cada operación de consulta registrará la declaración de consulta real en el archivo de registro A, completando así la colección de declaraciones de consulta.
A través de instrumentación obtuvimos una gran cantidad de declaraciones SQL y luego resolvimos el segundo problema, cómo determinar si una declaración de consulta es una consulta lenta.
Debido a la diferencia de orden de magnitud entre los datos de prueba y de producción, obviamente no es científico juzgar por el tiempo de ejecución. Al mismo tiempo, obtuvimos un total de decenas de miles de declaraciones SQL y, obviamente, el análisis manual directo no es factible.
Pensamos en el comando de explicación proporcionado por Mysql para expandir las declaraciones SQL y juzgar científicamente la velocidad de ejecución a través del plan de ejecución de Mysql. Cada declaración SQL ejecutable se puede obtener directamente usando el comando de explicación.
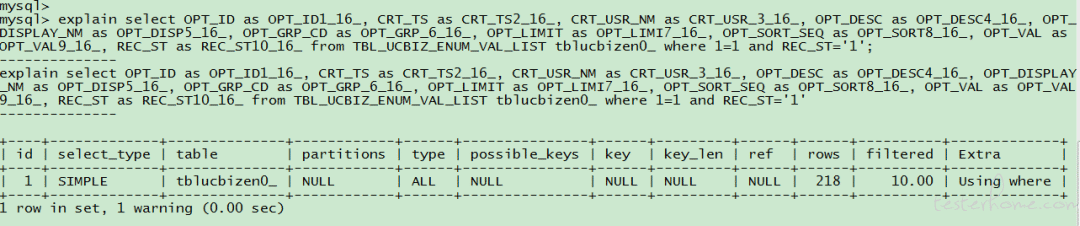
Cada etiqueta de columna en el plan de ejecución se puede utilizar como un elemento de preocupación en el proceso de coincidencia. Lo llamamos elemento indicador. Usamos los dos elementos indicadores más importantes relacionados con la eficiencia de la consulta:
1.clave: Indica la clave del índice que se utilizará cuando se ejecute esta declaración SQL;
2.tipo: Método de acceso, que indica que la ejecución de la declaración SQL es la forma de encontrar las filas requeridas en la tabla de la base de datos. Los valores posibles son los siguientes:
sistema > const > eq_ref > ref > texto completo > ref_or_null > index_merge > subconsulta_única > subconsulta_index > rango > índice > TODOS
Del sistema a TODOS, el rendimiento va de bueno a malo, en general se debe garantizar que alcance al menos el nivel de rango.
En el primer paso, convertimos todas las declaraciones SQL en el archivo de registro A en planes de ejecución una por una;
El segundo paso es establecer un conjunto de reglas basadas en las necesidades reales del sistema para filtrar el plan de ejecución y encontrar declaraciones que puedan ser consultas lentas;
Las reglas para hacer coincidir consultas lentas en nuestro sistema son:
ingrese [NULL] O escriba [ rango, índice, TODOS] O Filas >= 1000
Esta regla significa: Si una instrucción SQL no está indexada, o el método de acceso es uno de rango, índice y TODO, o el número estimado de filas escaneadas es mayor o igual a 1000, entonces puede ser una consulta lenta.
El tercer paso es analizar manualmente las declaraciones que pueden ser consultas lentas.
A través del segundo paso de selección, redujimos la cantidad de declaraciones SQL que debían analizarse de cientos de miles a una docena, y luego las analizamos manualmente una por una.
De esta forma completamos la prueba de consulta lenta del sistema. La declaración SQL que causó problemas de producción en el pasado fue un éxito perfecto, y otras declaraciones de consulta sospechosas de ser lentas se determinaron manualmente como no lentas en función de factores como la frecuencia de las consultas y el orden de magnitud de la tabla de datos de producción.
olas rompiendo
Posteriormente, al implementar ubicaciones de instrumentación de agentes configurables y reglas de filtrado de consultas lentas, optimizamos esta solución en un marco general y la extendimos a múltiples sistemas en el departamento, y descubrimos varios peligros ocultos de las consultas lentas.
Para este método de prueba de consulta lenta basado en instrumentación, las ventajas resumidas son las siguientes :
1. Las declaraciones SQL tienen una cobertura completa y alta precisión. Solo la preparación del análisis del punto de instrumentación puede garantizar la captura de todas las declaraciones SQL ejecutadas cuando el programa se está ejecutando (dado que se pueden capturar las declaraciones SQL ejecutadas reales, depende de la integridad de la prueba funcional) y el análisis basado en el plan de ejecución. es más poderoso Es científico, no se ve afectado por el tamaño de los datos y tiene mayor precisión.
2. Tiene una excelente versatilidad . La posición de inserción es configurable, pudiendo utilizarse diferentes sistemas simplemente modificando la configuración. Los stubs son generalmente algunas clases y métodos específicos del paquete del controlador de la base de datos que implementa la interacción subyacente con la base de datos y no están relacionados con la implementación de la aplicación específica. En otras palabras, no importa cuál sea la función del programa, no importa el marco de la base de datos. Se utiliza, siempre que la configuración sea correcta. Las clases de interacción de la base de datos y sus métodos se pueden adaptar.
3. No invasivo, conectable e imperceptible para la aplicación bajo prueba. Cuando el agente se inicia, la instrumentación será dinámica. Cuando el agente se detiene, el punto de instrumentación desaparecerá. No es necesario realizar ninguna modificación en el código fuente de la aplicación bajo prueba. El proceso de detección no tiene ningún impacto en las funciones y se puede completar silenciosamente durante las pruebas funcionales.
algo de practica
Algunos estudiantes de la comunidad TesterHome tienen algunas ideas y prácticas después de ver esta idea:
1. Se siente realmente increíble. Nuestras ideas para resolver este problema son muy similares. Un proyecto de código abierto en el que trabajé hace dos años utilizó esta idea, pero no se ha promovido. Después de cambiar de empresa, solía ir con más frecuencia. Ha pasado mucho tiempo. No más actualizaciones. https://github.com/bugVanisher/no-slow-query
2. El complemento Mybatis es suficiente. Afinidad natural. Un paquete jar. Referenciado por toda la empresa. El costo del agente Java es relativamente alto.
Este es un complemento que creé para evitar que las etiquetas se invaliden. Lo mismo se aplica a otros métodos https://github.com/Forest10/forest10-tool/blob/master/src/main/java/com/forest10/mybatis /interceptor/BatchModifyForbiddenInterceptor.java
3. Implementado en base a las ideas del cartel original (autor) y ha sido de código abierto.
https://github.com/tangyiming/sql-detect
Contiene complementos de instrumentación, front-end y back-end de plataforma, aplicación de demostración, DDL de base de datos y recursos de datos.
Finalmente: se ha compilado y subido el video tutorial completo de prueba de software a continuación. Los amigos que lo necesiten pueden obtenerlo ellos mismos [garantizado 100% gratis]

Documento de entrevista de prueba de software
Debemos estudiar para encontrar un trabajo bien remunerado. Las siguientes preguntas de la entrevista provienen de los últimos materiales de entrevista de empresas de Internet de primer nivel como Alibaba, Tencent, Byte, etc., y algunos jefes de Byte han dado respuestas autorizadas. Después de terminar esto set Creo que todos pueden encontrar un trabajo satisfactorio según la información de la entrevista.

