Escrito antes: esta es la segunda parte del ajuste de rendimiento de msql
Consulta de optimización de rendimiento de MySQL
Un proceso de consulta de MySQL
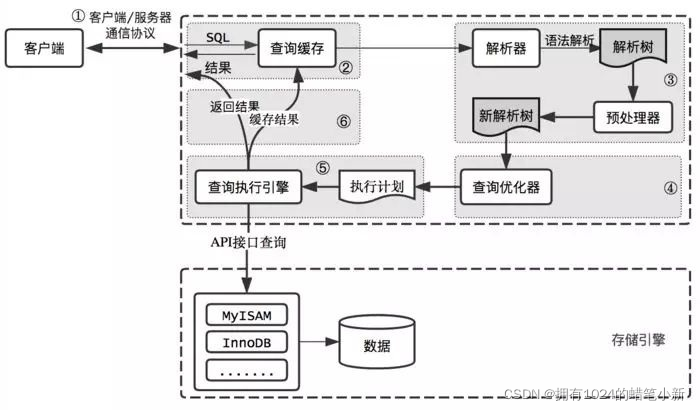
¿Cómo optimizamos sql?, antes que nada, debemos saber que la optimización de sql es principalmente para resolver el problema de la optimización de consultas, por lo que comenzamos con la consulta de la base de datos, la siguiente imagen muestra la ruta de ejecución de la consulta:
① El cliente envía la consulta al servidor;
② El servidor verifica el caché de consultas y, si lo encuentra, devuelve el resultado del caché; de lo contrario, continúa con el siguiente paso.
③ Análisis y preprocesamiento del servidor.
④ El optimizador de consultas optimiza la consulta
⑤ Genere un plan de ejecución y el motor de ejecución llamará a la API del motor de almacenamiento para ejecutar la consulta
⑥ El servidor devuelve el resultado al cliente.
Caché de consulta
Antes de analizar una declaración de consulta, si la caché de consulta está abierta, MySQL primero verificará si la consulta acierta con los datos en la caché de consulta. Si la caché acierta, el resultado se recuperará directamente de la caché y se devolverá al cliente. En este caso, la consulta no se analizará, no se generará ningún plan de ejecución y no se ejecutará.
Análisis de sintaxis y preprocesador
MySQL analiza las declaraciones SQL por palabras clave y genera un "árbol de análisis" correspondiente. El analizador de MySQL validará y analizará la consulta utilizando las reglas de sintaxis de MySQL.
Optimizador de consultas
Una vez que el libro de gramática se verifica y es legal, el optimizador lo convierte en un plan de consulta. Una declaración se puede ejecutar de muchas maneras y, finalmente, devuelve el mismo resultado. El papel del optimizador es encontrar el mejor plan de ejecución entre ellos.
Motor de ejecución de consultas
En la fase de análisis y optimización, MySQL generará un plan de ejecución correspondiente a la consulta, y el motor de ejecución de consultas de MySQL completará toda la consulta de acuerdo con el plan de ejecución. Los motores más utilizados y utilizados con mayor frecuencia son el motor MyISAM y el motor InnoDB. El motor de almacenamiento predeterminado que comienza con MySQL 5.5 se ha cambiado a innodb.
Optimización de la segunda consulta
En el análisis del proceso de consulta anterior, tenemos una comprensión general de cómo se ejecuta MySQL, y más adelante veremos las partes involucradas una por una. Ahora comencemos con la parte de optimización de consultas.
SQL es la parte más importante de nuestra comunicación con la base de datos, por lo que cuando estamos ajustando, debemos dedicar mucho tiempo a la optimización de SQL. Los métodos de análisis comunes incluyen registros de consultas lentas y consultas de análisis EXPLAIN.Al ubicar y analizar los cuellos de botella de rendimiento, el rendimiento del sistema de base de datos se puede optimizar mejor.
consulta lenta
Agregue dos parámetros de configuración debajo de la línea [mysqld] en el archivo de configuración my.cnf[linux] o my.ini[windows]
log-slow-queries=C:/ProgramData/MySQL/MySQL Server 5.5/Data/mysqldata/slow-query.log
long_query_time=5
El parámetro log-slow-queries es la ubicación donde se almacena el registro de consultas lentas. Generalmente, este directorio debe tener el permiso de escritura de la cuenta corriente de mysql. Generalmente, este directorio se establece como el directorio de almacenamiento de datos de mysql;
5 en long_query_time= 5 significa que la consulta supera los cinco segundos para grabar;
También puede agregar el parámetro log-queries-not-using-indexes a my.cnf o my.ini, lo que indica que se registran las consultas que no usan índices.
SHOW VARIABLES LIKE 'long_query_time%'; -- 查看当前多少秒算慢
show global status like '%Slow_queries%'; --查询当前系统中有多少条慢查询记录
Análisis de consultas lentas
Podemos abrir el archivo de registro para ver qué SQL se ejecuta de manera ineficiente. Desde el registro, podemos encontrar el SQL cuyo tiempo de consulta supera los 5 segundos, y el SQL cuyo tiempo de consulta es inferior a 5 segundos no aparece en este registro.
Si hay mucho contenido registrado en el registro de consultas lentas, puede usar la herramienta mysqldumpslow (incluida con la instalación del cliente MySQL) para clasificar y resumir el registro de consultas lentas. mysqldumpslow subtotaliza los archivos de registro y muestra los resultados resumidos después de la agregación.
Ingrese al directorio de almacenamiento de registros y ejecute:
[root@mysql_data]# mysqldumpslow slow-query.log
Reading mysql slow query log fromslow-query.log
Count: 2 Time=11.00s (22s) Lock=0.00s (0s)Rows=1.0 (2), root[root]@mysql
select count(N) from t_user;
comando mysqldumpslow
/path/mysqldumpslow -s c -t 10/database/mysql/slow-query.log
Esto generará las 10 declaraciones SQL con la mayor cantidad de registros, donde:
-s, indica de qué manera ordenar, c, t, l, r se ordenan según el número de registros, el tiempo, el tiempo de consulta y el número de registros devueltos, respectivamente, ac, at, al, ar, indican el correspondiente escena retrospectiva
-t, es el significado de top n, es decir, cuántos datos se devuelven;
-g, puede escribir un patrón de coincidencia regular después de él, que no distingue entre mayúsculas y minúsculas;
P.ej:
/path/mysqldumpslow -s r -t 10/database/mysql/slow-log
Obtenga las 10 consultas que arrojan la mayor cantidad de conjuntos de registros.
/path/mysqldumpslow -s t -t 10 -g “leftjoin” /database/mysql/slow-log
Obtenga las 10 declaraciones de consulta principales con uniones a la izquierda ordenadas por tiempo.
Usando el comando mysqldumpslow, podemos obtener todas las declaraciones de consulta que necesitamos de manera muy clara.Monitorear, analizar y optimizar las declaraciones de consulta de MySQL es un paso muy importante en la optimización de MySQL. Después de habilitar el registro de consultas lentas, el rendimiento de mysql se verá afectado hasta cierto punto debido a la operación de registro, pero se puede habilitar en etapas para localizar cuellos de botella en el rendimiento.
EXPLAIN plan de ejecución (parse plan)
EXPLAIN puede ayudar a los desarrolladores a analizar problemas de SQL EXPLAIN muestra cómo MySQL usa los planes de ejecución de SQL, lo que puede ayudar a los desarrolladores a escribir declaraciones de consulta más optimizadas. Para usar el método, simplemente agregue Explicar antes de la declaración de selección:
EXPLAIN SELECT * FROM products
Las columnas resultantes se describen a continuación:
1) identificación
Identificador SELECCIONAR. Este es el número de secuencia de la consulta SELECT. Esto no es importante. Simplemente identifica que hay múltiples consultas en la instrucción sql ejecutada
2) seleccionar_tipo
Indica el tipo de instrucción SELECT.
- simple: Selección simple (no utiliza uniones ni subconsultas).
- primario: la selección más externa.
- union: La segunda o subsiguiente instrucción select en unión.
- unión dependiente: la segunda declaración de selección o posterior en la unión, dependiendo de la consulta externa.
- resultado de unión: El resultado de la unión.
- subconsulta: La primera selección en la subconsulta.
- subconsulta dependiente: la primera selección en la subconsulta, que depende de la consulta externa.
- derivada: la selección de la tabla derivada (subconsulta de la cláusula from).
- mesa
Muestra de qué tabla se tratan los datos de esta consulta.
4) escriba 【Importante】
Índice distintivo, esta es la columna importante que muestra qué tipo de combinación se utiliza. Los tipos de conexión de mejor a peor son:
system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
En términos generales, es necesario asegurarse de que la consulta alcance al menos el nivel de rango, preferiblemente ref, e index.
- system: Solo hay una fila en la tabla, que es una columna especial de tipo const, que generalmente no aparece, y esto también se puede ignorar.
- const: la tabla de datos tiene como máximo una fila coincidente, porque solo coincide una fila de datos, por lo que es muy rápido
- eq_ref: el manual de mysql dice esto: "Para cada combinación de filas de la tabla anterior, lea una fila de esa tabla. Este es probablemente el mejor tipo de unión, excepto el tipo const. Se usa en todas las partes que usan las uniones y el índice es UNIQUE o PRIMARY KEY". eq_ref se puede usar para la comparación condicional usando =, y la columna es una columna indexada.
- ref: el índice de condición de consulta no es ÚNICO ni CLAVE PRINCIPAL. ref se puede usar en columnas indexadas con los operadores = o < o >.
- ref_or_null: este tipo de combinación es como ref, pero con la adición de que MySQL puede buscar específicamente filas que contengan valores NULL. Esta optimización del tipo de combinación se usa a menudo para resolver subconsultas.
- index_merge: este tipo de combinación indica que se utiliza el método de optimización de combinación de índices. En este caso, la columna clave contiene la lista de índices usados y key_len contiene el elemento clave más largo de los índices usados.
- subconsulta_única: este tipo reemplaza la referencia de la subconsulta IN de la siguiente forma: valor IN (SELECCIONE clave_principal DESDE tabla_única DONDE alguna_expr) subconsulta_única es una función de búsqueda de índice que puede reemplazar completamente las subconsultas y es más eficiente.
- index_subquery: este tipo de combinación es similar a unique_subquery. Las subconsultas IN se pueden reemplazar, pero solo para índices no únicos en subconsultas de la forma: valor IN (SELECCIONE key_column FROM single_table WHERE some_expr)
- rango: recuperar solo filas en un rango dado, usando un índice para seleccionar filas.
- index: este tipo de combinación es igual que ALL, excepto que solo se escanea el árbol de índice. Esto suele ser más rápido que TODOS porque los archivos de índice suelen ser más pequeños que los archivos de datos.
- TODO: para cada combinación de filas de la tabla anterior, se realiza un escaneo completo de la tabla. (Peor rendimiento, eliminar todo, al menos índice)
5) posibles_claves
Indica qué índice puede usar MySQL para encontrar filas en esta tabla. Si está vacío, no hay índice asociado. Para mejorar el rendimiento en este momento, puede consultar la cláusula WHERE para ver si se hace referencia a algunos campos o si el campo de búsqueda no es adecuado para la indexación.
6) clave
El índice real utilizado. Si es NULL, no se utiliza ningún índice. Si es principal, significa que se utiliza la clave principal.
7) key_len
El ancho de índice más largo. Si la clave es NULL, la longitud es NULL. Las longitudes más cortas son mejores sin pérdida de precisión.
(Capacidad limitada, comprender relativamente la estructura del índice, tener la capacidad de ajustar el índice, el algoritmo es relativamente fuerte)
8) referencia
Muestra qué columna o constante se usa con la tecla para seleccionar filas de la tabla.
9) filas
Muestra el número de filas que MySQL cree que debe examinar al ejecutar la consulta. Cuanto menor sea el número de filas, mayor será la eficiencia (si hay un índice)
10) adicional
Descripción del estado de ejecución, esta columna contiene los detalles de la consulta de solución de MySQL, el valor de esta columna puede tener más de una de las siguientes situaciones
- Distinto: MySQL deja de buscar más filas para la combinación de filas actual después de encontrar la primera fila coincidente.
- No existe: MySQL puede realizar la optimización de LEFT JOIN en la consulta. Después de encontrar una fila que coincida con los criterios de LEFT JOIN, no verificará más filas en la tabla para la combinación de filas anterior.
- rango verificado para cada registro (mapa de índice: #): MySQL no encontró un buen índice para usar, pero descubrió que si se conoce el valor de la columna de la tabla anterior, tal vez se pueda usar un índice parcial.
- 【Uso de clasificación de archivos】: MySQL requiere un pase adicional para descubrir cómo recuperar filas en orden. En la clasificación, esto significa que los registros de datos reales deben leerse al clasificar [leer archivo de datos IO]
- Usando el índice: recupere la información de la columna en una tabla a partir de la lectura de la fila real usando solo la información en el árbol del índice sin buscar más.
- [Usando temporal]: para resolver consultas complejas, MySQL necesita crear una tabla temporal para acomodar los resultados, lo cual es ineficiente.
- La cláusula Using where:WHERE se usa para restringir qué fila coincide con la siguiente tabla o se envía al cliente.
- Usando sort_union(…), Usando union(…), Usando intersect(…): Estas funciones ilustran cómo fusionar exploraciones de índice para el tipo de unión index_merge.
- Usar índice para agrupar por: similar al método Usar índice para acceder a una tabla, Usar índice para agrupar significa que MySQL ha encontrado un índice que se puede usar para consultar todas las columnas de una consulta GROUP BY o DISTINCT sin buscar adicionalmente el disco duro para acceder a los datos de la tabla real en formato .
Escrito más tarde: el próximo artículo está a punto de escribir sobre la optimización de índices