Práctica y construcción del entorno Prometheus
1. Preparación e instalación de componentes
El siguiente software se instala mediante la ventana acoplable. Para los comandos de la ventana acoplable, consulte la ventana acoplable desde la entrada hasta la práctica.
1.1 Instalación de Prometheus + clickhouse
# prometheus安装并启动,访问地址localhost:9090
docker pull prom/prometheus
docker run -d -p 9090:9090 prom/prometheus
# 或者指定配置路径
docker run -d -p 9090:9090 -v /home/webedit/monitoring/prometheus/config:/etc/prometheus prom/prometheus
# alertmanager安装并启动,访问地址localhost:9093
docker pull prom/alertmanager
docker run --name alertmanager -d -p 9093:9093 quay.io/prometheus/alertmanager
# grafana安装并启动, 访问地址localhost:3000
docker pull grafana/grafana
docker run -d -p 3000:3000 grafana/grafana
# pushgateway安装并启动,访问地址localhost:9091
docker pull prom/pushgateway
docker run -d -p 9091:9091 prom/pushgateway
# clickhouse安装并启动,用于grafana读取。外网访问地址ip:8123。用于测试grafana集成clickhouse
docker pull yandex/clickhouse-server
docker pull yandex/clickhouse-client
docker run -d --name clickhouse-server -p 8123:8123 -p 9009:9009 -p 9000:9000 --ulimit nofile=262144:262144 --volume=/home/webedit/monitoring/clickhouse/clickhouse-db:/var/lib/clickhouse yandex/clickhouse-server
# 使用clickhouse-client连接
docker run -it --rm --link clickhouse-server:clickhouse-server yandex/clickhouse-client --host clickhouse-server
# 以上组件/软件安装启动后可以先访问下地址看看有没有异常
1.2 complemento de instalación de grafana
# grafana默认是没有clickhouse的数据源插件的,需要安装
# 进入grafana容器,使用grafana-cli plugins install命令安装插件,然后重启容器生效
docker exec -it `docker container ls | grep grafana | awk -F' ' '{print $1}'` bash
grafana-cli plugins install vertamedia-clickhouse-datasource
docker restart `docker container ls | grep grafana | awk -F' ' '{print $1}'`
Agregue una fuente de datos en grafana y seleccione clickhouse. Si está usando la configuración predeterminada, simplemente complete la url y el usuario, url: (ip: 8123), usuario: predeterminado
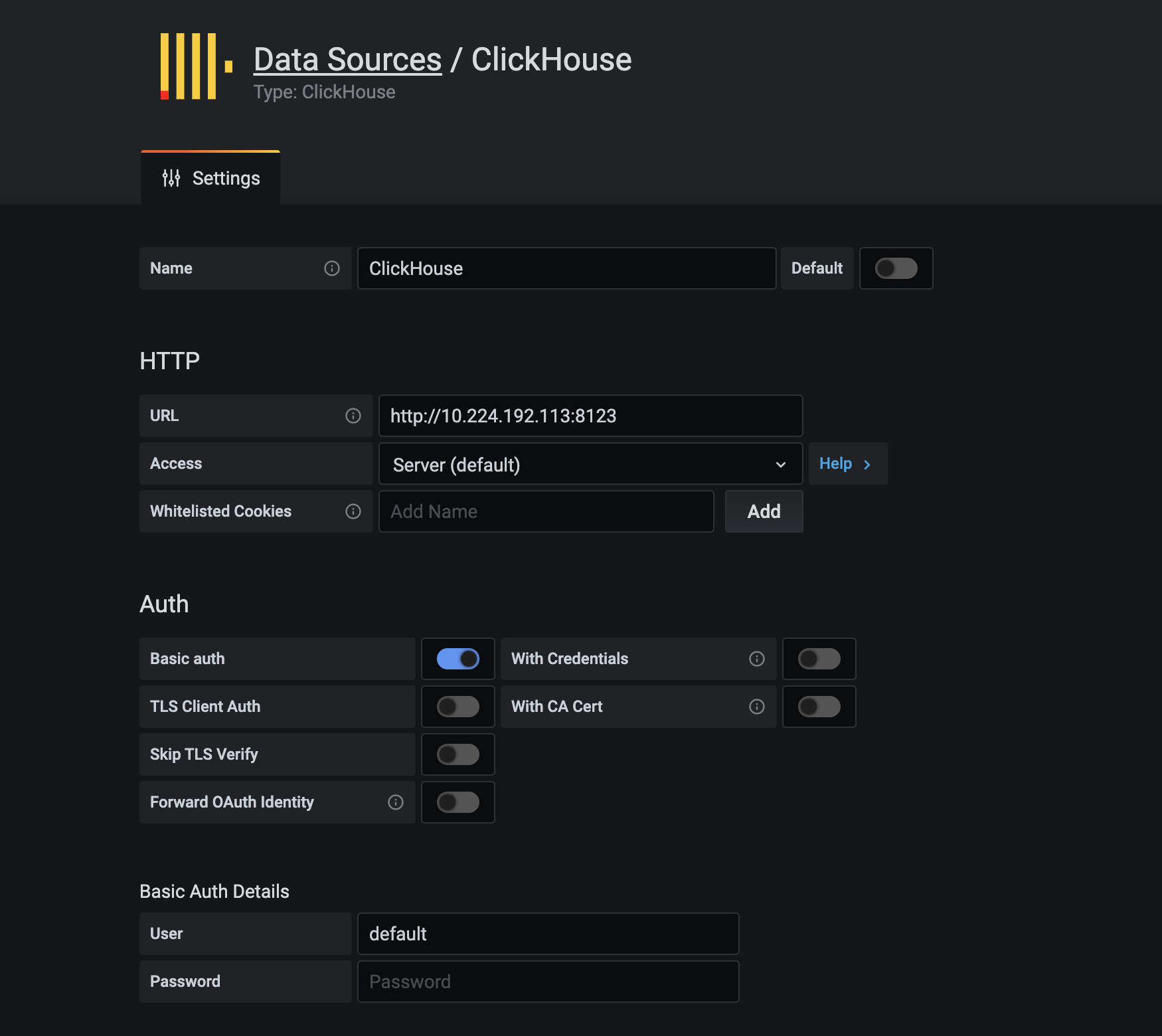
2. Caso de uso de Prometheus
2.1 Caso 1: Exportador de nodos de monitoreo del sistema
- Inicie el exportador de nodos en la máquina a monitorear
# 按照上面的流程启动完后,已经可以监控一些指标了。
# 另外再加一个官方案例:使用NODE EXPORTER监视LINUX主机指标
docker pull prom/node-exporter
docker run -d -p 9100:9100 \
-v "/proc:/host/proc:ro" \
-v "/sys:/host/sys:ro" \
-v "/:/rootfs:ro" \
--net="host" \
--restart=always \
--name node-exporter \
prom/node-exporter
- Configure los indicadores de monitoreo para capturar prometheus.yml (prometheus, alertmanager, pushgateway también expondrá los datos del indicador, agréguelos ~)
# prometheus指标抓取配置
# 全局配置
global:
# 抓取周期
scrape_interval: 15s
# 默认抓取超时 [ scrape_timeout: <duration> | default = 10s ]
# 估算规则的默认周期 # 每15秒计算一次规则。默认1分钟 [ evaluation_interval: <duration> | default = 1m ]
# 和外部系统(例如AlertManager)通信时为时间序列或者警情(Alert)强制添加的标签列表
external_labels:
monitor: 'gucha-monitor'
# 规则文件列表
rule_files:
- 'prometheus.rules.yml'
# 抓取配置列表
scrape_configs:
# 监控自身指标
- job_name: 'prometheus'
# 抓取的时间间隔
scrape_interval: 5s
# 静态指定服务地址。生产环境一般用服务发现,这里用于演示
static_configs:
- targets: ['10.224.192.113:9090']
# node-exporter 指标
- job_name: 'node'
# 指定job的抓取时间周期,可以覆盖全局配置
scrape_interval: 5s
static_configs:
# 这里加了两个不存在的服务,测试prometheus健康检查
- targets: ['localhost:8080', 'localhost:8081']
labels:
group: 'not_exist'
- targets: ['10.224.192.113:9100']
labels:
group: 'node_demo'
- job_name: 'pushgateway'
static_configs:
- targets: ['10.224.192.113:9091']
labels:
instance: pushgateway
- job_name: 'alertmanager'
static_configs:
- targets: ['10.224.192.113:9093']
labels:
instance: alertmanager
- Ahora, usamos node-exporter + grafana para integrar un panel de monitoreo de indicadores de sistema atractivo
1. 在grafana官网中找个好看的dashboard模板,[dashboard](https://grafana.com/grafana/dashboards). 找到自己喜欢的,点进去会有个模板id. 这里找了一个8919的[模板](https://grafana.com/grafana/dashboards/8919)
2. 在grafana中import模板,并选择prometheus数据源,就生成了一个很好看的dashboard了
[Error en la transferencia de la imagen del enlace externo. El sitio de origen puede tener un mecanismo de enlace anti-sanguijuela. Se recomienda guardar la imagen y subirla directamente (img-xpE9wrcX-1616636283402) (https://raw.githubusercontent.com/1458428190/ prometheus-demo / main / images /image-20210318170022275.png)]
2.2 Caso 2: Exportador de clickhouse de monitoreo de aplicaciones
- Inicie clickhouse-exporter, configure la URL de clickhouse y agregue un trabajo de rastreo
# 启动clickhouse-exporter
docker pull f1yegor/clickhouse-exporter
docker run -d -p 9116:9116 f1yegor/clickhouse-exporter -scrape_uri=http://10.224.192.113:8123/
# 添加抓取工作
- job_name: 'clickhouse-metrics'
static_configs:
- targets: ['10.224.192.113:9116']
labels:
instance: clickhouse
- Encuentre una bonita plantilla de panel en el sitio web oficial de grafana, id: 882
[Error en la transferencia de la imagen del enlace externo. El sitio de origen puede tener un mecanismo de enlace anti-sanguijuela. Se recomienda guardar la imagen y subirla directamente (img-J7Atq0Rw-1616636283404) (https://raw.githubusercontent.com/1458428190/ prometheus-demo / main / images /image-20210318170512727.png)]
2.3 Caso 3: Monitoreo de SpringBoot basado en eureka
-
Agregar descubrimiento de servicios en prometheus.yml
# 使用eureka_sd_configs做服务发现。 缺点:需要在项目里改点配置 - job_name: 'eureka' metrics_path: '/admin/prometheus' # Scrape Eureka itself to discover new services. eureka_sd_configs: - server: http://10.224.192.92:1111/eureka relabel_configs: - source_labels: [__address__, __meta_eureka_app_instance_metadata_prometheus_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ -
Paquete de introducción al proyecto SpringBoot
# SpirngBoot项目引入包 <!-- 第三方开源工具包 --> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> <version>1.1.2</version> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-core</artifactId> <version>1.1.2</version> </dependency> -
Especifique el nombre de la aplicación del indicador
# 指定指标应用名和管理端口 management.metrics.tags.application=${spring.application.name} -
Especifique el puerto de administración (porque el descubrimiento de servicios descubre el puerto de servicio de forma predeterminada, y el puerto de administración expuesto por SprintBoot es otro)
eureka: instance: metadataMap: "prometheus.port": "${management.server.port}" -
Otro método de configuración. Utilice consul_sd_configs para el descubrimiento de servicios [no practicado]- job_name: 'consul-prometheus' scheme: http metrics_path: '/admin/prometheus' consul_sd_configs: #consul 地址 - server: '10.224.192.92:1111' scheme: http services: [SPRINGBOOT_PROMETHEUS_CLIENT] -
Encuentre una plantilla de panel atractiva en el sitio web oficial de grafana, como id: 11378
[Error en la transferencia de la imagen del enlace externo. El sitio de origen puede tener un mecanismo de enlace anti-sanguijuelas. Se recomienda guardar la imagen y subirla directamente (img-wO6FWAZ5-1616636283405) (https://raw.githubusercontent.com/1458428190/ prometheus-demo / main / images /image-20210318171821693.png)]
3. Prometheus con caso de uso de alertmanager
-
Configurar reglas de alarma prometheus.rule.yml
-
10.224.192.113: La velocidad de escritura de 30 segundos del disco en la instancia 9100 excedió 60 durante 1 minuto. Después de activar las condiciones, el registro de alarma generado agrega algunas etiquetas utilizables como severidad: leve para facilitar la agrupación posterior.
-
10.224.192.113: La velocidad de escritura de 30 segundos del disco en la instancia 9100 excedió 70 durante 1 minuto. Después de la condición de activación, el registro de alarma generado agrega algunas etiquetas utilizables como severidad: crítica para facilitar la agrupación posterior.
-
El resto de la configuración ~ ver notas
-
groups:
- name: example
rules:
# 告警名称
- alert: node_disk_reads_completed_total
# promQL 10.224.192.113:9100实例下的磁盘30s写速率超过60
expr: rate(node_disk_writes_completed_total{
instance="10.224.192.113:9100"}[30s]) > 60
# 持续1分钟
for: 1m
# 标签,比如加个严重程度
labels:
severity: slight
# 告警模板内容
annotations:
summary: "summary test {
{ $labels.instance }} slight"
description: "{
{ $labels.instance }} rate(node_disk_writes_completed_total) = {
{ $value }})"
- alert: node_disk_reads_completed_total
# promQL 10.224.192.113:9100实例下的磁盘30s写速率超过70
expr: rate(node_disk_writes_completed_total{
instance="10.224.192.113:9100"}[30s]) > 70
# 持续1分钟
for: 1m
# 标签
labels:
severity: critical
annotations:
summary: "summary test {
{ $labels.instance }} critical"
description: "{
{ $labels.instance }} rate(node_disk_writes_completed_total) = {
{ $value }})"
- alertmanager 配置 alertmanager.yml
global:
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'FAMAPDNAOUPJMMOV'
smtp_require_tls: false
route: #每个输入警报进入根路由
receiver: 'team-b' #根路由不得包含任何匹配项,因为它是所有警报的入口点
group_by: ['alertname', 'instance'] #将传入警报分组的标签。例如,将alertname和instance值相同的分为同一个组
group_wait: 30s #当传入的警报创建了一组新的警报时,请至少等待多少秒发送初始通知
group_interval: 5m #发送第一个通知时,请等待多少分钟发送一批已开始为该组触发的新警报
repeat_interval: 3h #如果警报已成功发送,请等待多少小时以重新发送警报
routes: #子路由,父路由的所有属性都会被子路由继承
- match_re: #此路由在警报标签上执行正则表达式匹配,以捕获与服务列表相关的警报
severity: ^(slight|critical)$
receiver: team-a
routes: #服务有严重警报,任何警报子路径不匹配,即通过父路由配置直接发送给收件人
- match:
severity: critical
receiver: team-b
#如果另一个警报正在触发,则禁止规则允许将一组警报静音,如果同一警报已经严重,我们将使用此选项禁用任何警告级别的通知
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'slight'
equal: ['alertname']
#如果警报名称相同,则应用抑制,如果源警报和目标警报中均缺少“equal”中列出的所有标签名称,则将应用禁止规则!
receivers:
- name: 'team-a'
email_configs:
- to: '[email protected],[email protected]'
- name: 'team-b'
email_configs:
- to: '[email protected]'
# 配置钩子,扩展通知方式
# webhook_configs:
# - url: 'http://prometheus-webhook-dingtalk.kube-ops.svc.cluster.local:8060/dingtalk/webhook1/send'
# send_resolved: true
- Utilice la configuración para iniciar alertmanager, especifique el archivo de configuración
docker run -d -p 9093:9093 -v /home/webedit/monitoring/alertmanager/config/alertmanager.yml:/etc/alertmanager/config.yml --name alertmanager quay.io/prometheus/alertmanager --config.file=/etc/alertmanager/config.yml
- Asociar prometheus y alertmanger. Agregar prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets: ['10.224.192.113:9093']
4. Caso de seguimiento de indicadores empresariales
- Un caso de demostración basado en SpringBoot + eureka. Los paquetes y configuraciones que deben introducirse son los mismos que los de "Supervisión de la implementación de SpringBoot basada en eureka" anterior
// 上报瞬时指标,这段代码可以周期运行。等待prometheus server拉取。
Metrics.gauge("mp.mkt.automkt.cnt.gauge", ImmutableList.of(new ImmutableTag("jobType", "vipUserMktJob")),
RandomUtil.randomLong(19000, 25000)));
Metrics.gauge("mp.mkt.automkt.cnt.gauge", ImmutableList.of(new ImmutableTag("jobType", "dwUserMktJob")),
RandomUtil.randomLong(19000, 25000)));
- grafana añadir vista
[Error en la transferencia de la imagen del enlace externo. El sitio de origen puede tener un mecanismo de enlace anti-sanguijuela. Se recomienda guardar la imagen y subirla directamente (img-1ODfSkzW-1616636283407) (https://raw.githubusercontent.com/1458428190/ prometheus-demo / main / images /image-20210318173825123.png)]
- Configure las reglas de alarma, consulte las notas para conocer sus efectos ~
# 营销系统业务告警
- alert: mkt-alert
# promQL vip自动化营销触发数,过去5分钟平均值小于2w
expr: avg(mp_mkt_automkt_cnt_gauge{
jobType="vipUserMktJob"}[5m]) < 25000
# 添加告警标签
labels:
severity: slight
type: automkt
annotations:
summary: "vip自动化营销近5分钟内平均触发数低于25000,severity: slight"
description: "vip自动化营销近5分钟内平均触发数 = {
{ $value }})"
- alert: mkt-alert
# promQL
expr: avg(mp_mkt_automkt_cnt_gauge{
jobType="vipUserMktJob"}[5m]) < 20000
# 持续1分钟
for: 1m
# 标签
labels:
severity: critical
type: automkt
annotations:
summary: "vip自动化营销近5分钟内平均触发数低于20000,severity: critical"
description: "vip自动化营销近5分钟内平均触发数 = {
{ $value }})"
- alert: mkt-alert
# promQL
expr: avg(mp_mkt_automkt_cnt_gauge{
jobType="dwUserMktJob"}[5m]) < 200000
# 持续1分钟
for: 1m
# 标签
labels:
severity: slight
type: automkt
annotations:
summary: "plus自动化营销数据异常,severity: slight"
description: "触发数:{
{ $value }})"
- La configuración de la alarma se modifica parcialmente en función de la configuración anterior.
global:
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'FAMAPDNAOUPJMMOV'
smtp_require_tls: false
route: #每个输入警报进入根路由
receiver: 'team-b' #根路由不得包含任何匹配项,因为它是所有警报的入口点
group_by: ['alertname', 'instance'] #将传入警报分组的标签。将alertname和instance值相同的分为同一个组
group_wait: 30s #等待30秒发送初始通知,用于聚合同一个分组的报警信息
group_interval: 5m #分组执行报警逻辑的时间周期
repeat_interval: 3h #如果警报已成功发送,请等待多少小时以重新发送警报
routes: #子路由,父路由的所有属性都会被子路由继承
- match_re: #正则匹配 标签severity=slight或者critical
severity: ^(slight|critical)$
receiver: team-a
routes: #严重警报,通知给team-b
- match:
severity: critical
receiver: team-b
routes: #自动化营销的严重报警,通知给team-automkt
- match:
alertname: mkt-alert
type: automkt
receiver: team-automkt
#同一个alertname,如果已经出过严重的报警,就屏蔽轻微的报警
#抑制规则
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'slight'
equal: ['alertname']
#如果警报名称相同,则应用抑制,如果源警报和目标警报中均缺少“equal”中列出的所有标签名称,则将应用禁止规则!
receivers:
- name: 'team-a'
email_configs:
- to: '[email protected],[email protected]'
- name: 'team-b'
email_configs:
- to: '[email protected]'
# 自动化营销相关负责人
- name: 'team-automkt'
email_configs:
- to: '[email protected],[email protected]'
# 配置钩子,扩展通知方式
# webhook_configs:
# - url: '短信 popo'
# send_resolved: true
- Ejemplo de alarma de Alertmanager. Se puede mostrar en segundo plano (este fondo también se puede configurar con reglas silenciosas)
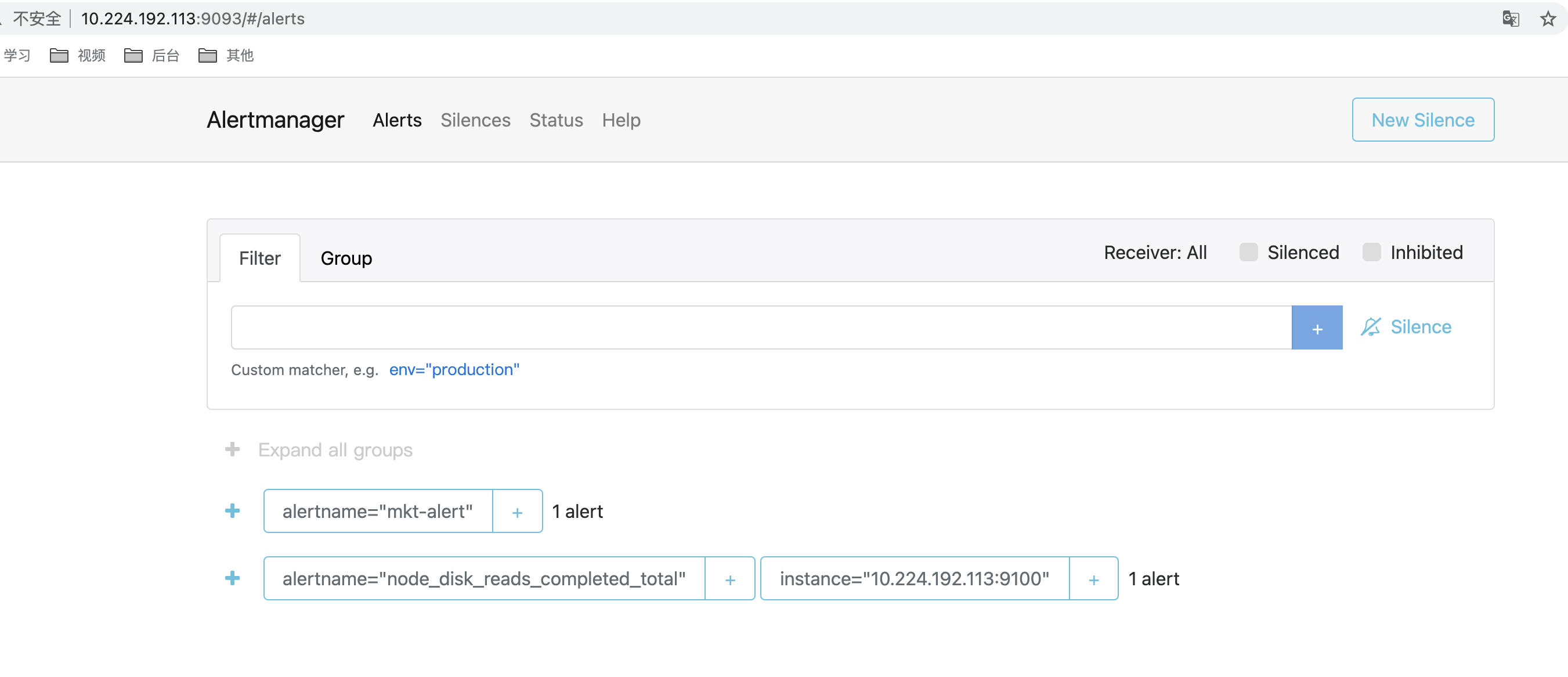
5. Caso de uso de puerta de entrada
<!-- 引入包 -->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_pushgateway</artifactId>
<version>0.10.0</version>
</dependency>
String url = "10.224.192.113:9091";
CollectorRegistry registry = new CollectorRegistry();
Gauge guage = Gauge.build("my_custom_metric", "This is my custom metric.").create();
guage.set(23.12);
guage.register(registry);
PushGateway pg = new PushGateway(url);
Map<String, String> groupingKey = new HashMap<String, String>();
groupingKey.put("instance", "my_instance");
pg.pushAdd(registry, "my_job", groupingKey);
String url = "10.224.192.113:9091";
CollectorRegistry registry = new CollectorRegistry();
Gauge guage = Gauge.build("my_custom_metric", "This is my custom metric.").labelNames("app", "date").create();
String date = new SimpleDateFormat("yyyy-mm-dd HH:mm:ss").format(new Date());
guage.labels("my-pushgateway-test-0", date).set(25);
guage.labels("my-pushgateway-test-1", date).dec();
guage.labels("my-pushgateway-test-2", date).dec(2);
guage.labels("my-pushgateway-test-3", date).inc();
guage.labels("my-pushgateway-test-4", date).inc(5);
guage.register(registry);
PushGateway pg = new PushGateway(url);
Map<String, String> groupingKey = new HashMap<>();
groupingKey.put("instance", "my_instance");
pg.pushAdd(registry, "my_job", groupingKey);
Observaciones:
prometheus.rule.yml和alertmanager.yml配置有点麻烦
grafana可以配置alertmanager报警