escrito en frente
En el artículo anterior, hablamos sobre cómo diseñar una solución técnica de refactorización factible: artículo teórico. Este artículo presenta principalmente un proyecto de refactorización de sistema completo basado en el reciente proyecto de refactorización en línea: refactorización del sistema de colas de pasajeros. Construir soluciones técnicas.
Introducción detallada de la solución técnica
1. Antecedentes
1. Estado:
* En la actualidad, el cuello de botella de rendimiento de las colas de pasajeros en línea es obvio, y se utiliza principalmente la estructura de almacenamiento Redis List. A medida que aumenta el número de pedidos en la cola, el RT de operaciones como consultar, insertar y juzgar si el pedido está en la cola aumenta exponencialmente.
* La estructura actual de colas de pasajeros no puede satisfacer las necesidades de expansión comercial. Para respaldar la rápida iteración de negocios en el futuro, la reconstrucción de las colas de pasajeros es inminente.
2. Artículos de investigación
* Análisis de viabilidad del uso de Mysql para almacenar información de colas (prueba de presión del entorno fuera de línea)
* Combinación de interfaces externas y alcance de influencia (análisis de unas 20 interfaces externas proporcionadas actualmente),
El formulario es el siguiente:
| nombre de la interfaz | ruta de interfaz | llamador | SWC | RT(995) | TR medio | Observación |
|---|---|---|---|---|---|---|
| poner en cola | /cola/entrar | XXX | XXX | XXX | XXX |
2. Metas
1. La interfaz externa permanece sin cambios, transformada desde el almacenamiento subyacente, compatible con la escena de visualización en línea actual y la visualización de clasificación de pasajeros y desacoplamiento de cola.
La pantalla de clasificación reserva colas ordinarias, colas de canal y colas prioritarias (incluida la prioridad absoluta), ordenadas por tiempo en cola
El factor de clasificación de eliminación de cola se calcula de acuerdo con reglas fijas al ingresar al equipo, y se usa un algoritmo de estrategia más flexible para calcular la prioridad de eliminación de cola. Al eliminar la cola, solo debe clasificarse de acuerdo con el factor de clasificación, determinando así indirectamente el orden de eliminación de cola. .
2. La recopilación ordenada de Redis se usa para la clasificación del almacenamiento de datos, y se agrega el almacenamiento mysql para la información de la cola, que se divide en 128 tablas.
3. Resuelva el problema de cuello de botella de rendimiento actual, admita la iteración rápida de negocios posteriores y la expansión de requisitos posteriores.
3. El plan general
1. Comparación de soluciones antiguas y nuevas
Arquitectura de almacenamiento antes de la refactorización: redis: estructura de datos de lista, clave: punto central de panal + modelo de automóvil + tipo de cola
Arquitectura de almacenamiento refactorizada:
Cola de clasificación: conjunto ordenado redis, clave: punto central de panal + modelo + tipo de cola (para compatibilidad con los antiguos)
Tabla de información de la cola: queue_info_xxx, almacenada en mysql, dividida en tablas según el hash del punto central del panal, y crea un índice único conjunto basado en el número de orden + modelo
Comparación entre lo nuevo y lo antiguo de algunas interfaces
| interfaz | ver clasificación | está en la cola | poner en cola | sacar de la cola | salta a la fila |
|---|---|---|---|---|---|
| antes de refactorizar | 1. Recorra todos los elementos en todas las colas y recorra para determinar la posición de cálculo 2. Consulte el grupo de algoritmos para calcular el tiempo estimado | Atraviese y consulte todos los elementos de la cola, haga un bucle para determinar si contener | Primero juzgue si existe en la cola, y aquí también juzgará si está escrito en la cola redis (lista) de acuerdo con los diferentes tipos de cola visitados | De acuerdo con el ciclo modelo y el ciclo de tipo de cola múltiple, salga del equipo y registre el registro | Tarjeta de beneficios saltando en línea |
| Después de la refactorización | Consulte la información de colas de la "tabla de información de colas" a través del número de pedido. Si hay un registro de colas, juzgue si hay una clasificación. Si no hay clasificación, mostrará M+ (la cola de clasificación tiene control en línea), de lo contrario consulta la "cola de clasificación" y devuelve el pedido directamente. Grupo de algoritmos de consulta para calcular el tiempo estimado | Consulte directamente la "tabla de información de la cola" para determinar si hay un registro | Escriba primero en la "tabla de información de la cola" y, si no supera el umbral de clasificación, escriba la "cola de clasificación" correspondiente | Actualice el estado de la "tabla de información de la cola". Si hay una clasificación, se eliminará de la cola de clasificación, se notificará al candidato de forma asíncrona y se registrará el registro. | El orden de la cola se puede cambiar directamente actualizando el campo "order_by" de la tabla de información de la cola |
Análisis de cuellos de botella antes de la refactorización: cada solicitud eliminará todos los elementos de la cola y los recorrerá (cuando aumenta la cantidad de pedidos en cola, el RT aumentará exponencialmente, lo cual es un gran problema. ¿Puedes pensar en el motivo?)
Ventajas de la arquitectura de almacenamiento refactorizada: Cambie la complejidad de tiempo O(n) original a la complejidad O(1).
2. Diagrama de arquitectura después de la refactorización
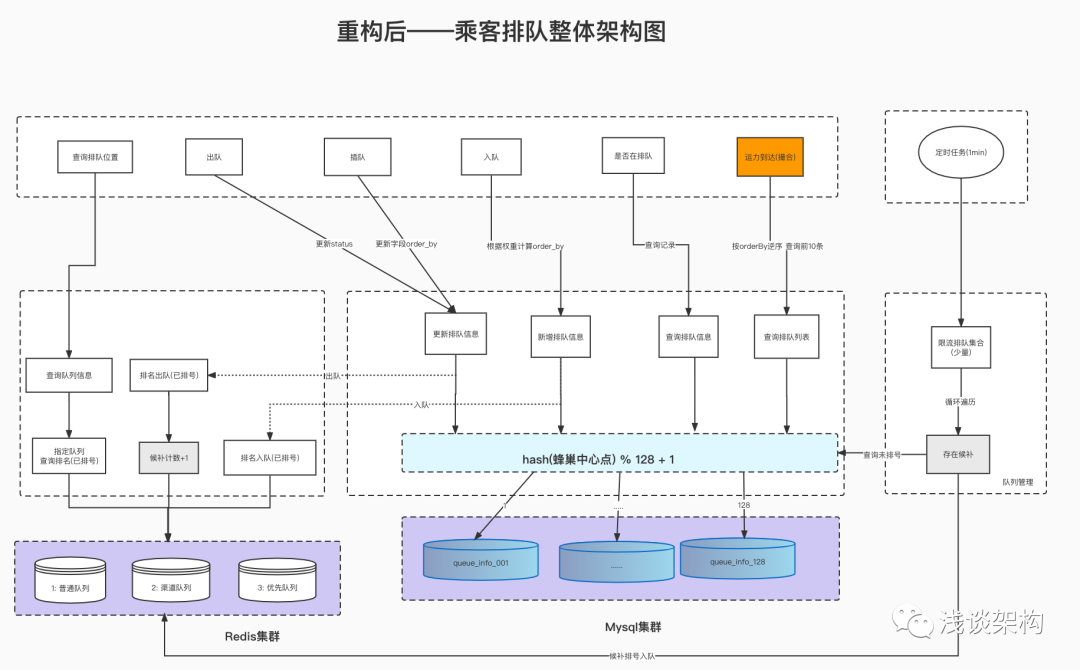
Preguntas sobre las estadísticas del tamaño de la cola:
Cola de flujo ilimitada de clasificación: Obtener directamente a través de ZCARD (O (1) complejidad de tiempo)
Cola de limitación de corriente de clasificación: obtenga la longitud total (O (1)) a través del contador y obtenga la degradación a través de ZCARD
2) Acerca de la nueva coincidencia de capacidad: la lista de consultas [parte naranja] puede tener un problema de cuello de botella: hay 2 direcciones de optimización en la etapa posterior, que pueden clasificarse como N principales y extraerse del truncamiento de la cola del conjunto de búfer: el tamaño excede N y se transfiere a otras mesas para su almacenamiento
Otros diagramas de flujo: diagramas de flujo de encolado y desencolado (se omite aquí)
diseño de estructura de mesa
queue_info_[001 ~ 128]: la tabla de información de cola se divide en tablas de acuerdo con la regla Hive Centerline Point hash% 128, y los datos se archivan por día
queue_manager: la tabla de gestión de colas de clasificación controla principalmente si el estado límite actual está presente y la información de la cola de colmena
queue_log_[001~128]: tabla de registro de entrada y salida de pedidos, dividida en tablas de acuerdo con la regla Hive midline point hash % 128, y se considerará para archivar más tarde.
Estructura detallada de la tabla - omitido
4. Diseño del campo de clasificación (order_by)
Para escenarios de cola, cuanto más corto sea el tiempo, antes. La diferencia horaria se puede calcular en orden inverso, la fórmula es la siguiente: ~(-1L << 39L) & (~(diferencia horaria en milisegundos))
Aquí se omiten otras reglas.
5. Problemas de compatibilidad con escenarios de cola históricos
Visualización de clasificación: cola común, cola de canal, cola de prioridad
Orden fuera de la cola: a través de diferentes configuraciones de coeficientes de peso, finalmente se calculan diferentes clasificaciones
6. Esquema de escala de grises
De acuerdo con la escala de grises de la ciudad, elija primero una ciudad con poco tráfico.
7. Esquema de reversión
Apague el interruptor de escala de grises de la ciudad, los datos existentes en la cola se verán afectados y la herramienta de migración necesita actualizar los datos
8. Plan de archivo de datos y plan ascendente
Archivo de datos: la información de colas de pasajeros se archiva por día
Estrategia final: el estado de cola a largo plazo (configurable) no ha cambiado (puede ser anormal), forzado a salir
9. Monitoreo de datos y alarma
Colas de pasajeros Monitoreo de Grafana: Indicadores de monitoreo: ciudad, colmena, modelo, número de colas comunes, número de colas de canales, número de colas prioritarias Alarma: alarma sonora cuando el número de colas supera el umbral
10. Planificación del tiempo
Las interfaces para la investigación de programas (20 interfaces) agregan programas de renovación, personas responsables y elementos de progreso
| nombre de la interfaz | ruta de interfaz | llamador | SWC | RT(995) | TR medio | Observación | Plan de actualización | Responsable | cronograma |
|---|---|---|---|---|---|---|---|---|---|
| poner en cola | /cola/entrar | XXX | XXX | XXX | XXX |
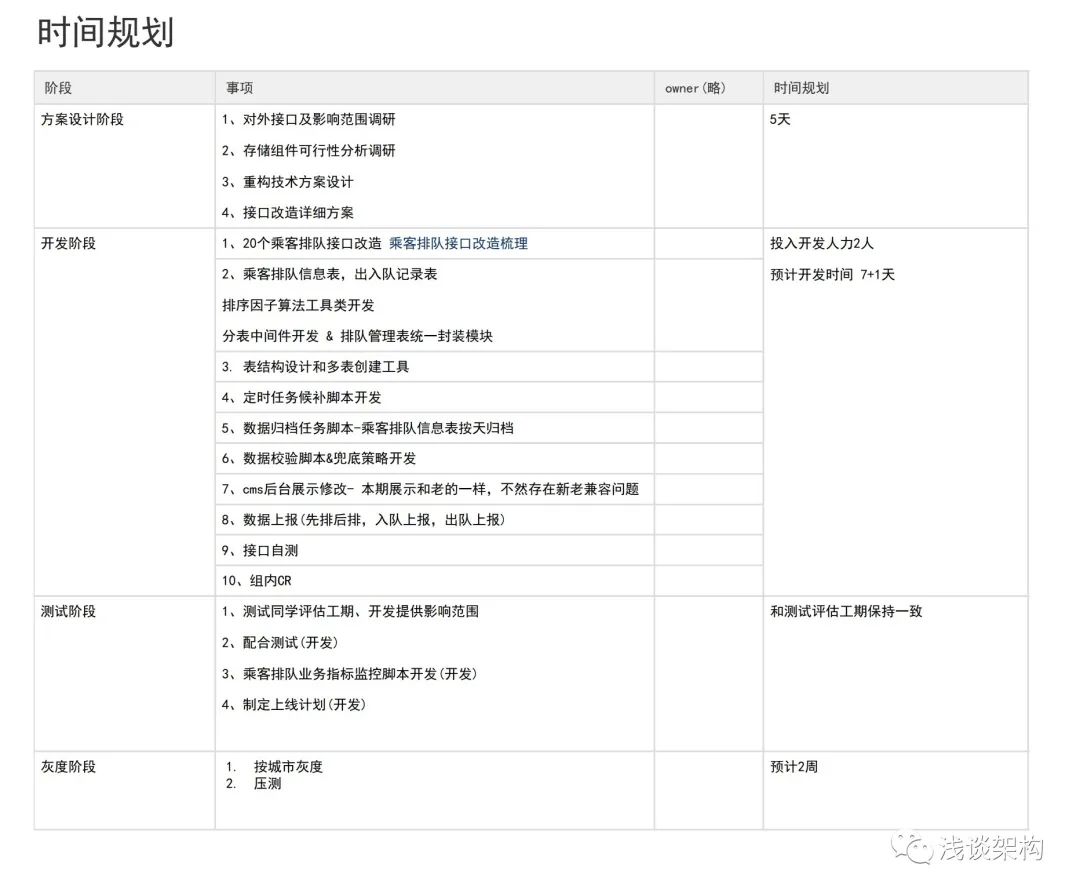
Nota: La autocomprobación de la interfaz y CR se completan en la fase de desarrollo, y las alarmas de monitoreo no afectan el desarrollo de la prueba y se pueden desarrollar en la fase de prueba.
11. Grupo de asociación
levemente
12. Recursos necesarios
levemente
Resumir
La refactorización debe tener en cuenta muchos detalles y debe tener en cuenta todos los cuellos de botella posibles, así como los problemas posteriores de optimización y expansión.
Todos los cambios deben ser personalmente responsables (para evitar omisiones), y todas las autopruebas (pruebas unitarias) deben pasar antes de la prueba.
En la actualidad, el desarrollo del código de esta solución se ha completado básicamente. El próximo artículo continuará utilizando la reconstrucción del sistema de colas como escenario y hablará sobre cómo diseñar la solución de prueba de esfuerzo en la etapa de escala de grises. lo.
Bienvenido a prestar atención a la cuenta pública "Hablando de arquitectura", compartir artículos técnicos originales de vez en cuando y tener la oportunidad de compartir los detalles técnicos de la reconstrucción del sistema con usted en el futuro.
