Este artículo se centra en la práctica de construcción del sistema de recuperación de desastres de la base de datos de Meituan. El contenido principal incluye la arquitectura empresarial, el desarrollo de capacidades de la plataforma de recuperación de desastres de la base de datos, la construcción del sistema de perforación y algunos logros de estas construcciones. Finalmente, compartirá el pensamiento futuro de la construcción de recuperación de desastres. . Espero que pueda ser útil o inspirador para todos.
1 Introducción a la recuperación ante desastres
2 Arquitectura empresarial de recuperación ante desastres
2.1 Evolución de la arquitectura de recuperación ante desastres
2.2 Arquitectura de recuperación ante desastres de Meituan
3 Construcción de recuperación de desastres de base de datos
3.1 Desafíos
3.2 Alta disponibilidad básica
3.3 Ruta de construcción de recuperación de desastres
3.4 Desarrollo de capacidades de la plataforma
3.5 Construcción del sistema de perforación
4 Pensamiento futuro
4.1 Compensar las deficiencias
4.2 Arquitectura iterativa
1 Introducción a la recuperación ante desastres
Por lo general, dividimos las fallas en tres categorías, una son las fallas del host, la otra son las fallas de la sala de computadoras y la tercera son las fallas regionales. Cada tipo de falla tiene sus propios factores desencadenantes, y desde el mainframe hasta la sala de computadoras y la región, la probabilidad de falla es cada vez menor, pero el impacto de la falla es cada vez mayor.
El objetivo de desarrollar la capacidad de recuperación ante desastres es muy claro, que es poder hacer frente y manejar fallas de gran escala a nivel de sala de cómputo ya nivel regional, para garantizar la continuidad del negocio. En los últimos años, ha habido muchas fallas a nivel de centro de datos en la industria, que han tenido un impacto negativo muy grande en el negocio y la marca de las empresas relacionadas. La capacidad actual de recuperación ante desastres se ha convertido en una necesidad para muchas empresas de TI a la hora de crear sistemas de información.

2 Arquitectura empresarial de recuperación ante desastres
2.1 Evolución de la arquitectura de recuperación ante desastres
La arquitectura de recuperación ante desastres ha evolucionado desde el primer modo activo único (copia de seguridad activa en la misma ciudad) hasta el modo multiactivo en la misma ciudad, y luego evolucionó a multiactivo remoto. De acuerdo con esta ruta, la recuperación ante desastres se puede dividir en tres tipos: recuperación ante desastres 1.0, recuperación ante desastres 2.0 y recuperación ante desastres 3.0.
Recuperación ante desastres 1.0 : el sistema de recuperación ante desastres gira en torno a la construcción de datos y se implementa principalmente de manera activa-en espera, pero la sala de computadoras de respaldo no soporta tráfico y es básicamente una estructura de un solo activo.
Recuperación ante desastres 2.0 : la perspectiva de recuperación ante desastres se transforma de datos a sistema de aplicaciones. La empresa tiene la capacidad de activo-activo en la misma ciudad o multiactivo en la misma ciudad. Adopta la arquitectura de implementación de activo-activo en la misma ciudad. misma ciudad o activo-activo en la misma ciudad más respaldo remoto en frío (dos lugares y tres centros) Cada sala de computadoras que no sea tiene capacidad de procesamiento de tráfico.
Disaster Recovery 3.0 : Centrado en los negocios, adopta principalmente una arquitectura unificada. La recuperación ante desastres se realiza en base a copias de seguridad por pares entre unidades. De acuerdo con la ubicación de implementación de la unidad, puede realizar múltiples activos en la misma ciudad y múltiples activos en diferentes lugares. Las aplicaciones que utilizan una arquitectura unificada tienen buenas capacidades de expansión y recuperación ante desastres.
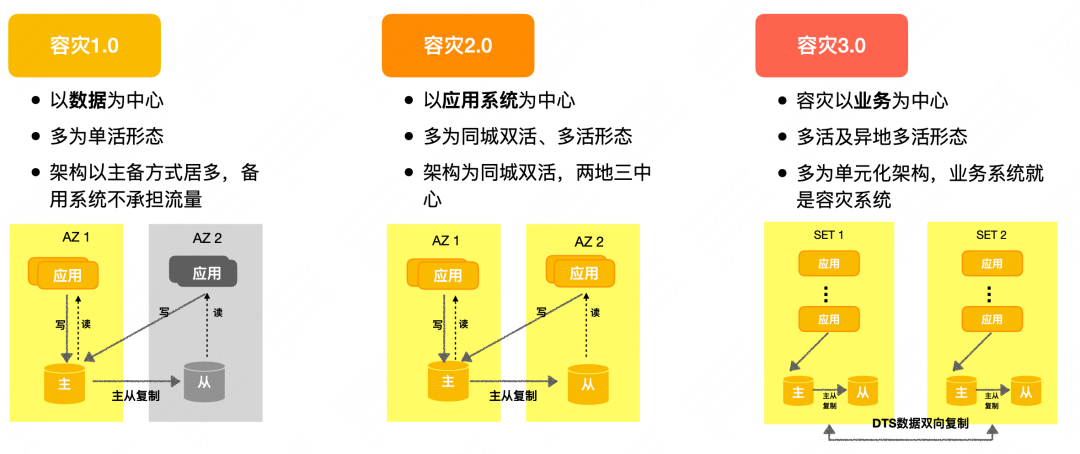
Debido a las diferentes etapas de desarrollo de cada empresa, las soluciones adoptadas también serán diferentes.La mayor parte del negocio de Meituan se encuentra en la etapa 2.0 (es decir, la misma estructura de doble activo o multiactivo de la ciudad), pero a gran escala, recuperación ante desastres regional y expansión regional Las empresas con altos requisitos de seguridad se encuentran en la etapa de recuperación ante desastres 3.0. A continuación, se presentará la arquitectura de recuperación ante desastres de Meituan.
2.2 Arquitectura de recuperación ante desastres de Meituan
La arquitectura de recuperación ante desastres de Meituan incluye principalmente dos tipos, uno es la arquitectura de recuperación ante desastres N+1 y el otro es la arquitectura SET.
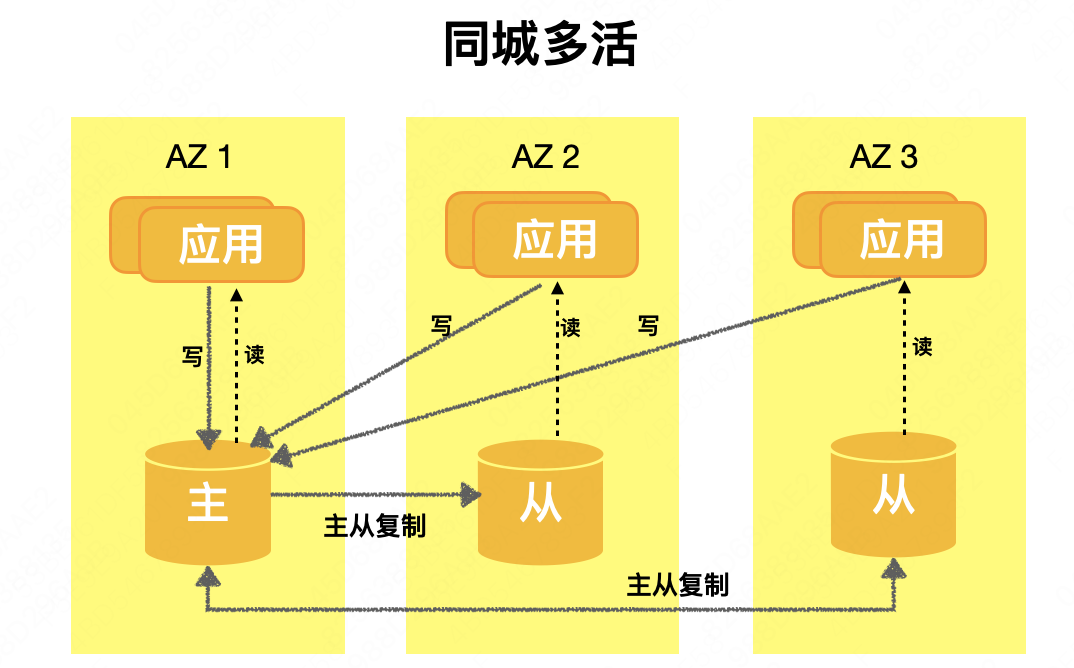
Arquitectura N + 1 : en la industria, también se denomina solución de implementación dispersa o multi-AZ. Un sistema con una capacidad de C se implementa en salas de computadoras N + 1. Cada sala de computadoras puede proporcionar al menos capacidad C / N. Cuando se suspende cualquier sala de computadoras, el sistema restante aún puede soportar la capacidad de C. El núcleo de esta solución es hundir la capacidad de recuperación ante desastres en los componentes de PaaS para completar.Cuando ocurre una falla en el nivel de la sala de equipos o en el nivel regional, cada componente de PaaS completa de forma independiente el cambio de recuperación ante desastres para realizar la recuperación comercial. La arquitectura general se muestra en la siguiente figura. El rendimiento del negocio es salas de múltiples computadoras y multiactivo. La base de datos adopta esta arquitectura maestro-esclavo. Una sola sala de computadoras maneja el tráfico de escritura y las salas de múltiples computadoras equilibran la carga del tráfico de lectura. . La siguiente "Práctica de construcción de sistemas de recuperación de desastres de bases de datos" está orientada a la arquitectura N+1.
Arquitectura unificada : también llamada arquitectura basada en SET, esta es una arquitectura de recuperación ante desastres que es parcial a la capa de aplicación. Divide las aplicaciones, los datos y los componentes básicos en múltiples unidades de acuerdo con una dimensión unificada, y cada unidad maneja una parte de los datos cerrados. -tráfico en bucle. La empresa utiliza la unidad como unidad de implementación y realiza la recuperación ante desastres en la misma ciudad o en un lugar diferente a través de la copia de seguridad mutua de las unidades. El negocio financiero general o el negocio de gran escala elegirán este tipo de arquitectura. Su ventaja es que el tráfico puede ser de circuito cerrado y los recursos están aislados, y tiene una fuerte tolerancia a desastres y capacidades de expansión entre dominios. Sin embargo, la implementación de La arquitectura basada en SET requiere una gran cantidad de sistemas comerciales, y la gestión de transformación, operación y mantenimiento también es más complicada. El diagrama simplificado es el siguiente:
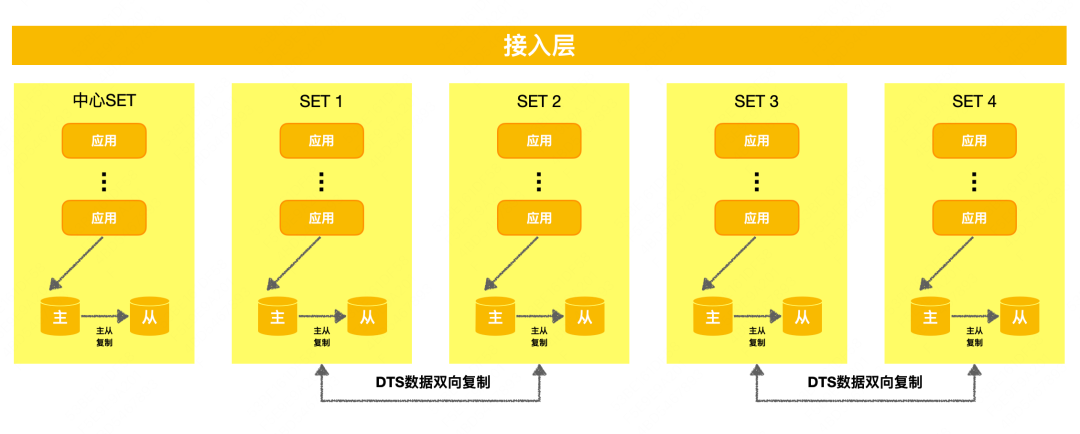
La mayoría de los negocios internos de Meituan tienen una estructura N+1, y negocios como la entrega de alimentos y las finanzas han adoptado una estructura unificada. En general, Meituan tiene multiactividad dentro de la ciudad y multiactividad remota, y las dos soluciones de recuperación ante desastres coexisten.
3 Construcción de recuperación de desastres de base de datos
| 3.1 Desafíos
Desafíos que plantean los clústeres de gran escala : el negocio de la empresa se está desarrollando rápidamente, la escala de los servidores aumenta exponencialmente y la escala de los centros de datos es cada vez más grande. Hay miles de clústeres de bases de datos y decenas de miles de instancias en la gran sala de ordenadores.
Problema de rendimiento : hay un cuello de botella obvio en la capacidad de procesamiento de fallas simultáneas del sistema de alta disponibilidad.
Riesgo de falla de recuperación ante desastres : el enlace de administración y control se vuelve cada vez más complejo con el aumento del número de clústeres, y un problema en un enlace conducirá a la falla de la capacidad general de recuperación ante desastres.
Fallas frecuentes : el número y la escala de los clústeres han aumentado, lo que hace que las fallas a gran escala con baja probabilidad se conviertan en fallas comunes, y la frecuencia y la probabilidad de ocurrencia son cada vez mayores.
El costo de los simulacros es alto y la frecuencia es baja : la verificación de las capacidades centrales es insuficiente, la capacidad de responder a fallas a gran escala se encuentra en un estado desconocido y es difícil "mantenerse actualizado" en las capacidades conocidas de recuperación ante desastres. Tomando las capacidades relevantes para lidiar con fallas a gran escala a nivel de la sala de computadoras, una gran parte se encuentra en un estado desconocido o solo existe en el análisis "en papel", y para las capacidades verificadas a medida que la arquitectura evoluciona e itera, la "frescura" es también muy importante dificultad.
Como uno de los servicios con estado, la base de datos en sí es relativamente más difícil y desafiante para desarrollar la capacidad de lidiar con fallas a gran escala.
| 3.2 Alta disponibilidad básica
Hay dos arquitecturas de bases de datos principales en Meituan, una es la arquitectura maestro-esclavo y la otra es la arquitectura MGR.
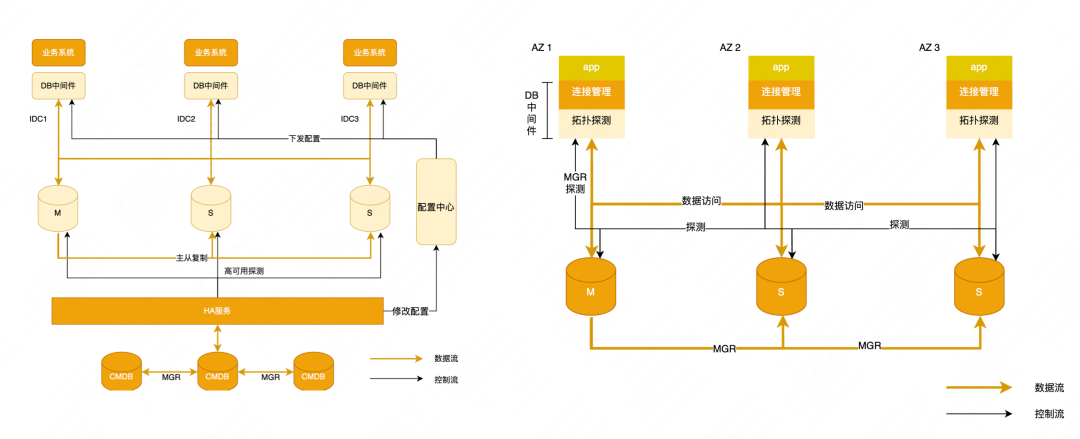
Arquitectura maestro-esclavo : las aplicaciones acceden a la base de datos a través del middleware de la base de datos.Cuando ocurre una falla, se utiliza la alta disponibilidad para la detección de fallas, el ajuste de la topología, la entrega de la configuración y la recuperación de la aplicación.
Arquitectura MGR : la aplicación también accede a la base de datos a través del middleware, pero el middleware está adaptado a MGR. El nombre interno es Zebra para MGR. El middleware realiza automáticamente la detección y percepción de la topología. Una vez que se cambia el MGR, se detectará la nueva topología y se Se realizarán ajustes en la fuente de datos y se reanudará el negocio.
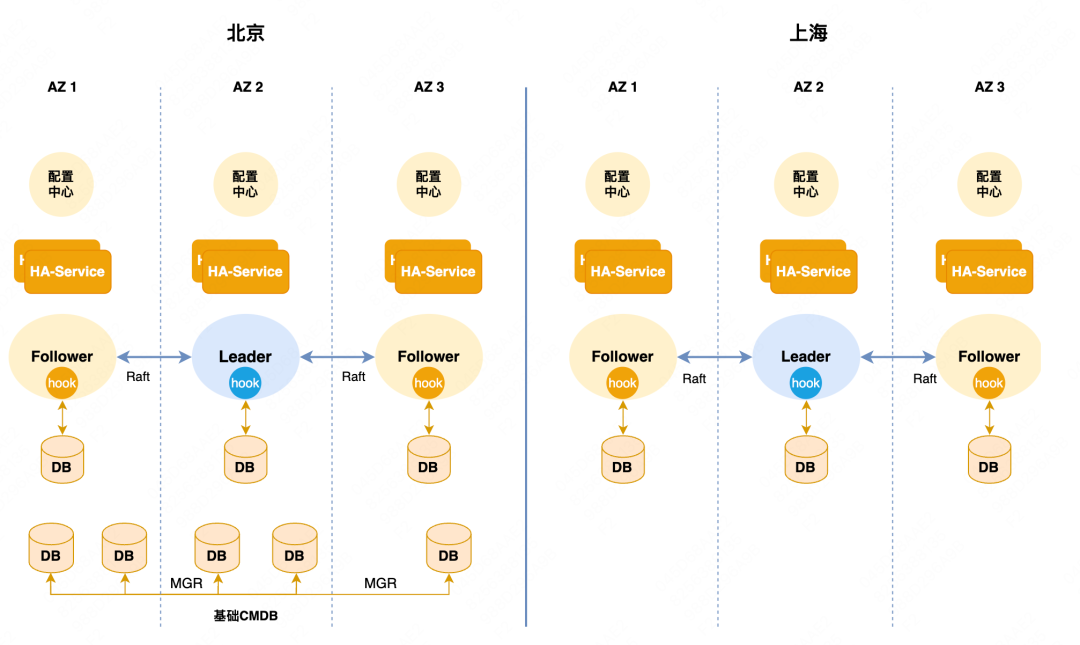
Arquitectura de alta disponibilidad de Meituan : la alta disponibilidad del clúster maestro-esclavo de Meituan se basa en el desarrollo secundario de Orchestrator. Es esencialmente una arquitectura de control y administración centralizada. Como se muestra en la figura a continuación, hay varios grupos de alta disponibilidad y cada grupo aloja una parte Los clústeres de bases de datos se implementan en Beijing y Shanghái en dos regiones Los componentes principales subyacentes solo se implementan en Beijing, como nuestro CMBD central, WorkflowDB, etc. la disponibilidad en el lado de Shanghái fallará y dejará de estar disponible.
3.3 Ruta de construcción de recuperación de desastres
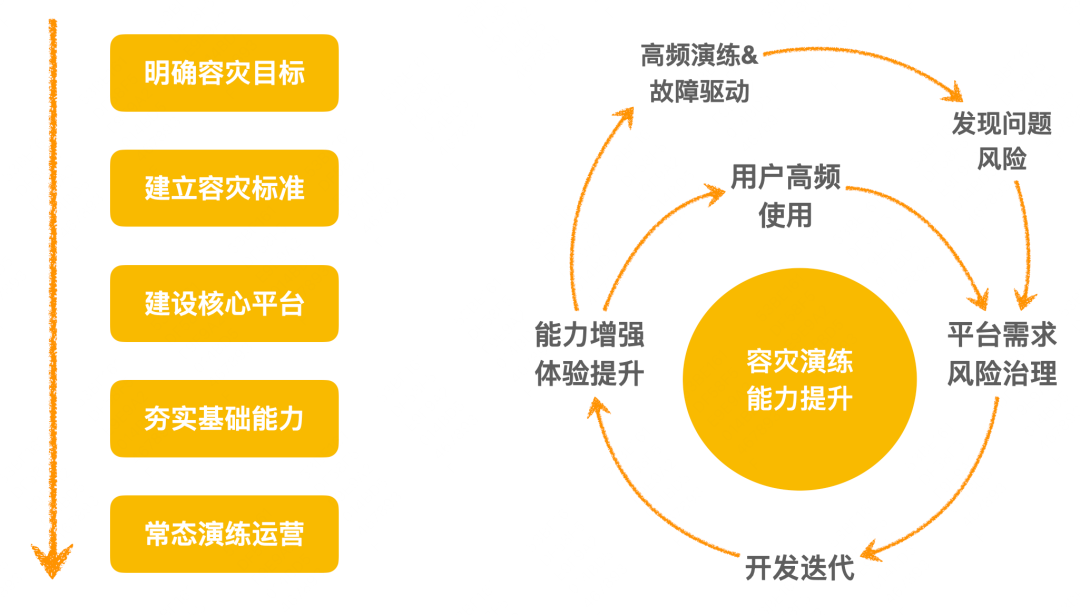
Ruta de construcción de recuperación ante desastres : determine los objetivos de recuperación ante desastres, formule estándares de recuperación ante desastres, construya plataformas de recuperación ante desastres, consolide las capacidades básicas, simulacros de verificación y operación de riesgos.
Volante para la construcción de recuperación ante desastres : el anillo interior es el desarrollo de capacidades de la plataforma, desde la propuesta de requisitos de recuperación ante desastres hasta I + D y lanzamiento, mejora de la experiencia, uso del usuario y nuevos requisitos cuando se descubren problemas y mejora iterativa continua. Otro aspecto es mejorar la construcción de la plataforma de perforación, realizar simulacros de alta frecuencia (o de fallas reales), encontrar problemas, proponer mejoras y promover la mejora iterativa continua de las capacidades de la plataforma.
3.4 Desarrollo de capacidades de la plataforma
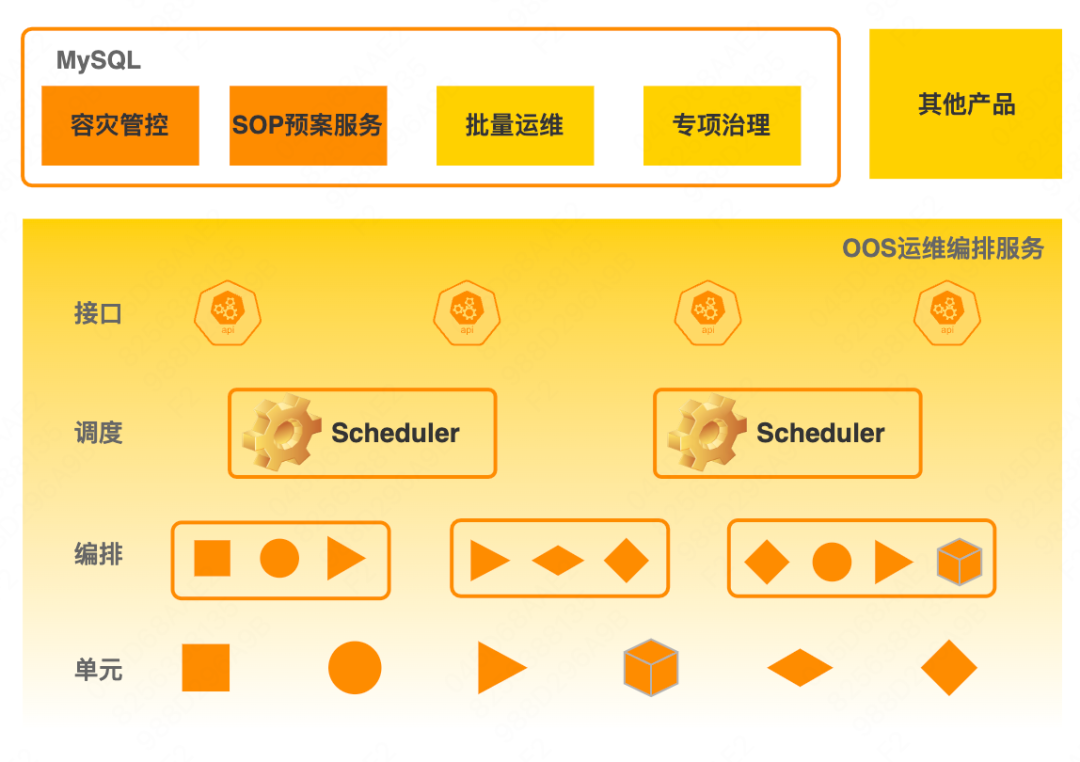
Para construir y mejorar la capacidad de recuperación ante desastres de los servicios de bases de datos, se estableció internamente un proyecto de gestión y control de recuperación ante desastres DDTP (Plataforma de tolerancia ante desastres de bases de datos) para centrarse en mejorar la capacidad de las bases de datos para hacer frente a fallas a gran escala. : una es una plataforma de gestión y control de recuperación ante desastres, y la otra es una plataforma de perforación de base de datos.
La plataforma de gestión y control de recuperación ante desastres se centra principalmente en la defensa. Sus funciones principales incluyen principalmente el escape antes del evento, la observación durante el evento, el stop loss y la recuperación después del evento. La plataforma de ejercicio de la base de datos se centra en el ataque, admite múltiples tipos de fallas y múltiples métodos de inyección de fallas y tiene capacidades básicas como orquestación de fallas y recuperación de fallas. El segundo artículo de esta serie, "Práctica de construcción de ejercicios de ataque y defensa de bases de datos", es una introducción detallada a la plataforma de ejercicios. A continuación, nos centraremos en el contenido principal de la plataforma de gestión y control de recuperación ante desastres, primero mira el panorama:
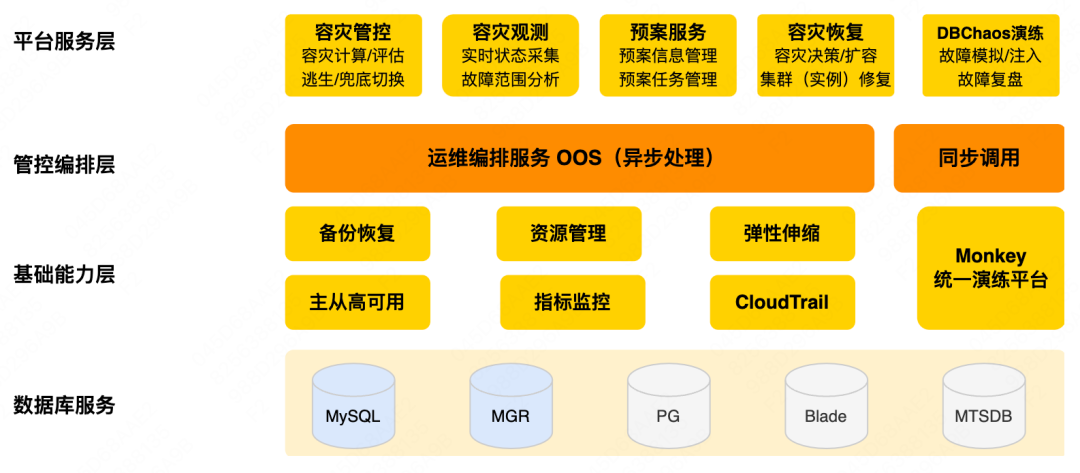
Servicio de base de datos : incluye MySQL, Blade, MGR y otros servicios básicos de base de datos.
Capa de capacidad básica : principalmente copia de seguridad y recuperación, administración de recursos, escalado elástico, alta disponibilidad maestro-esclavo y capacidades de monitoreo de indicadores. Estas capacidades son la parte básica de la garantía de estabilidad, pero deben fortalecerse aún más en escenarios de recuperación ante desastres para manejar grandes escenarios de falla a gran escala.
Capa de orquestación de gestión y control : El núcleo es OOS (Operation Orchestration Service), que orquestará las capacidades básicas bajo demanda para generar los procedimientos de procesamiento correspondientes, también llamados planes orientados a servicios Cada plan corresponde a uno o más escenarios específicos de operación y mantenimiento. Los planes de recuperación ante desastres también se encuentran en esta categoría.
Capa de servicio de la plataforma : es la capa de capacidad de la plataforma de gestión y control de recuperación ante desastres, que incluye: 1) gestión y control de recuperación ante desastres , evaluación del cálculo de recuperación ante desastres y gestión de peligros ocultos, así como recuperación ante desastres y escape antes del fallo, de abajo hacia arriba conmutar durante fallas, extracción de fallas, etc. 2) Observación de recuperación ante desastres , aclarando el alcance de las fallas y apoyando las decisiones de recuperación ante desastres durante las fallas. 3) Recuperación de tolerancia a desastres : después de una falla, la capacidad de tolerancia a desastres del clúster se puede restaurar rápidamente mediante funciones como la reparación de instancias y la expansión del clúster. 4) Plan de servicio , incluyendo la gestión y ejecución de planes de emergencia por averías comunes, etc.
3.4.1 Capacidad hasta estándar
La base de datos ha establecido un conjunto de estándares de cálculo de recuperación ante desastres N + 1, que se dividen en niveles 6. Si el nivel de recuperación ante desastres del clúster es ≥ 4, se cumple el estándar de recuperación ante desastres, de lo contrario, no se cumple el estándar de recuperación ante desastres.
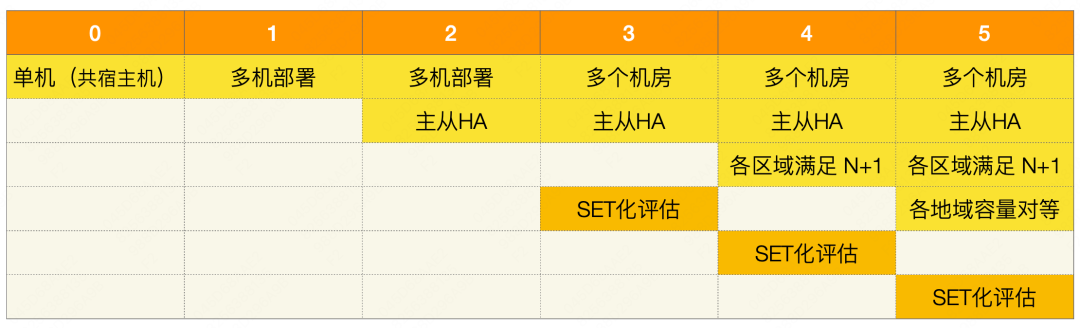
Se puede ver en el estándar que a partir del nivel 3, se implementa en múltiples salas de computadoras. La diferencia entre el Nivel 3, el Nivel 4 y el Nivel 5 es que el Nivel 3 no cumple con el requisito N+1, es decir, si fallan todos los nodos en una sala de computadoras, los nodos restantes no pueden soportar el tráfico máximo. Los niveles 4 y 5 cumplen con el requisito N+1 y el nivel 5 cumple con la paridad de capacidad entre regiones. Además de los estándares básicos, los clústeres basados en SET tienen reglas especiales, como políticas de enrutamiento de ciclo cerrado, salas de computadoras unificadas vinculadas a clústeres SET, capacidad SET igual para copias de seguridad mutuas y modelos unificados dentro del clúster. Estas reglas se incluirán en el cálculo de recuperación ante desastres para determinar el nivel final de recuperación ante desastres del clúster.
En la construcción de datos básicos de recuperación ante desastres, se codificarán las reglas anteriores y se simplificará el proceso de cálculo, y los datos básicos se mantendrán actualizados casi en tiempo real. Los datos de recuperación ante desastres son los datos básicos utilizados en la plataforma de gestión y control de recuperación ante desastres para la conmutación de escape y detener las pérdidas durante incidentes. Al mismo tiempo, los riesgos ocultos (es decir, los peligros ocultos de no cumplir con los estándares de recuperación ante desastres) serán construido sobre la base de datos de recuperación de desastres, y estos riesgos se eliminarán a través de cierto peligro oculto.
3.4.2 Escape antes del fallo
La capacidad de escapar antes de una falla es el cambio de la base de datos maestra por lotes y la extracción de la base de datos esclava. Se utiliza principalmente para recibir advertencias tempranas antes de fallas, percibir desastres con anticipación y cortar rápidamente todos los servicios de la base de datos en una sala de computadoras o el tráfico de la base de datos esclava fuera de línea para reducir real El impacto de la falla.
Sabemos que para un clúster con una arquitectura maestro-esclavo, si se produce una conmutación por error debido a una interrupción del suministro eléctrico o de la red, es probable que se produzca una pérdida de datos. Una vez que se pierden los datos, la empresa debe confirmar y realizar el trabajo posterior, lo que a veces es muy engorroso. Si puede escapar con anticipación, evitará estos riesgos. Al mismo tiempo, además del escape de la base de datos maestra, la base de datos esclava también puede "eliminar" el tráfico por adelantado, de modo que el lado comercial sea "insensible" a las fallas.
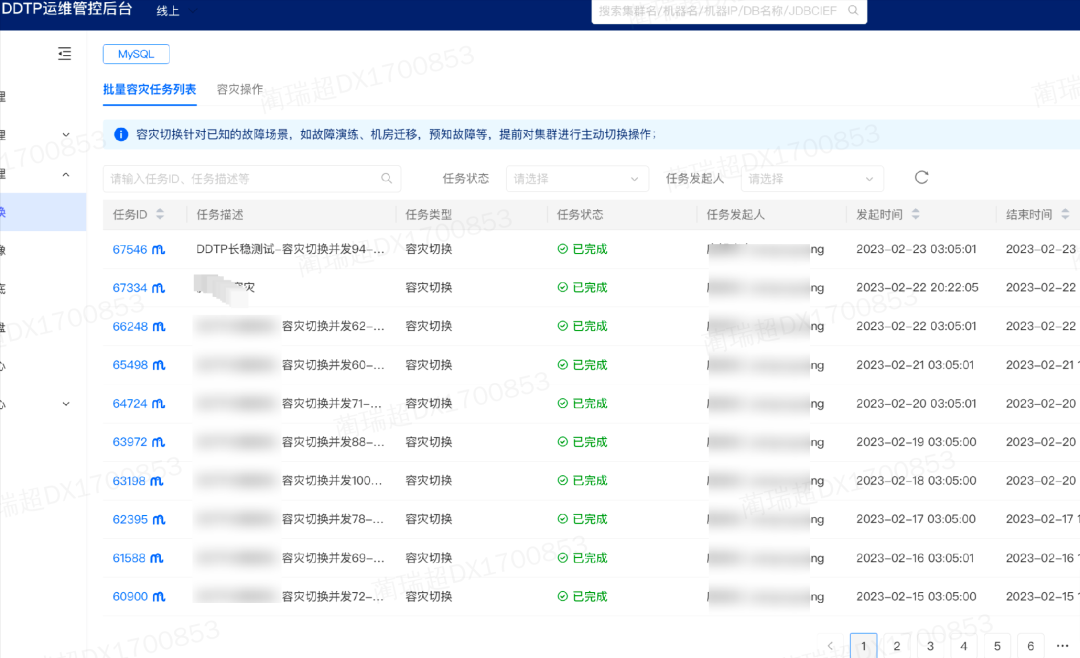
3.4.3 Observación durante fallas
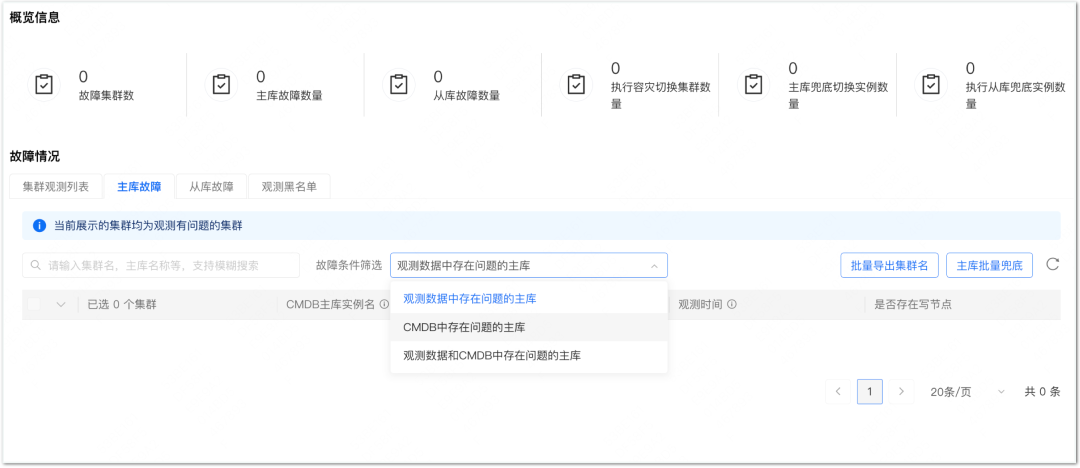
Cuando ocurre una falla a gran escala, generalmente habrá un bombardeo de alarmas, un bombardeo de consultas telefónicas, etc. Si no hay una capacidad general de reconocimiento de fallas, el manejo de fallas será confuso, el tiempo de procesamiento será relativamente largo y el impacto de la falla será magnificada Por lo tanto, hemos construido un tablero de observación de recuperación de desastres, que puede observar fallas en tiempo real, con precisión y confiabilidad, para garantizar que los estudiantes en servicio puedan comprender la situación de fallas en tiempo real.
Como se muestra en la figura a continuación, si ocurre una falla, puede obtener rápidamente la lista de clústeres o instancias defectuosas e iniciar una acción de cambio de abajo hacia arriba en la página correspondiente, logrando así una parada de pérdida rápida. El requisito principal para observar el mercado es en tiempo real, preciso y confiable. Puede mejorar su propia disponibilidad reduciendo las dependencias del servicio.
3.4.4 Stop loss durante la falla
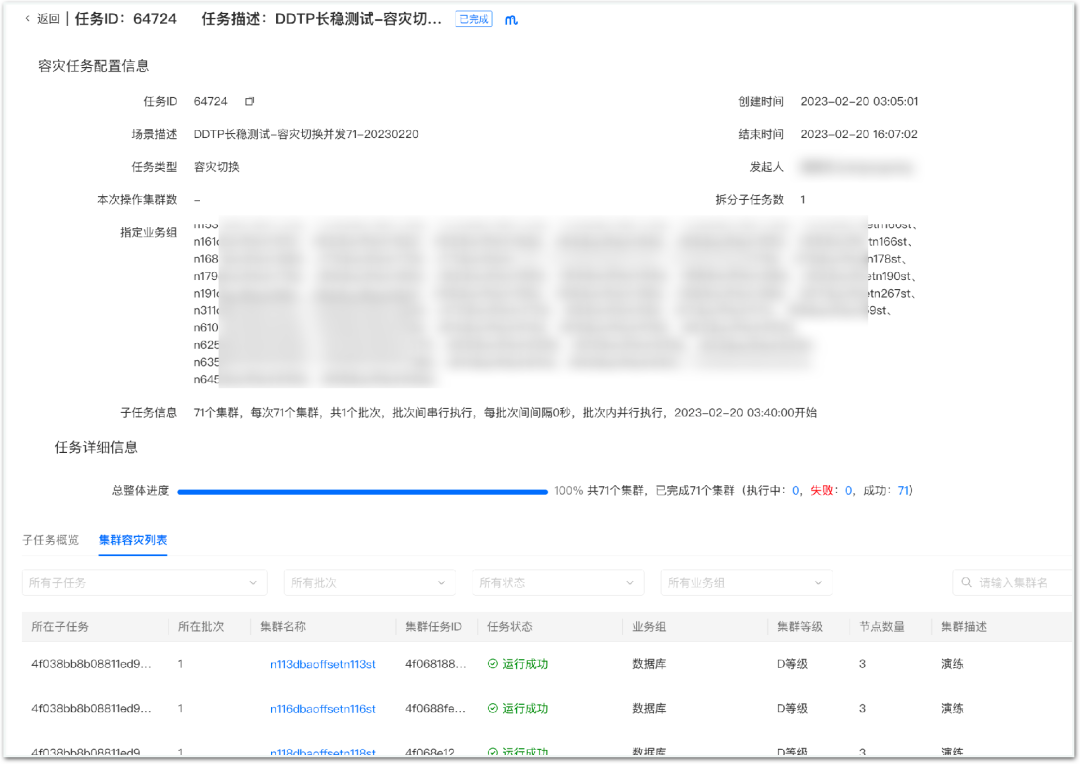
Antes de introducir el stop loss en la falla, entendamos primero el servicio del plan. La función central del servicio del plan de contingencia es administrar fallas comunes y las diversas contingencias de procesamiento correspondientes, y proporcionar capacidades de control de ejecución, de modo que los planes de contingencia se puedan ejecutar de manera conveniente y controlable.
Stop loss en caso de fallo : Después de tener un plan, podemos llevar a cabo un stop loss bottom-up. Como se muestra en la figura a continuación, cuando ocurre una falla a gran escala, HA manejará automáticamente la falla. Si el cambio de clúster falla o se pierde, entrará en la etapa de abajo hacia arriba. En primer lugar, comience con la plataforma DDTP. Si la plataforma no está disponible debido a una falla, puede proporcionar el resultado final en la capa de orquestación de operación y mantenimiento. Si el servicio de orquestación de operación y mantenimiento también falla, debe verificar manualmente los detalles a través de la herramienta CLI. CLI es la herramienta de nivel inferior de DBA, y esta y la alta disponibilidad son dos enlaces independientes. La CLI realizará lógicas como detección de topología de clúster, elección de maestro, ajuste de topología, modificación de configuración y distribución de configuración, que son equivalentes a los pasos de conmutación manual de clúster.
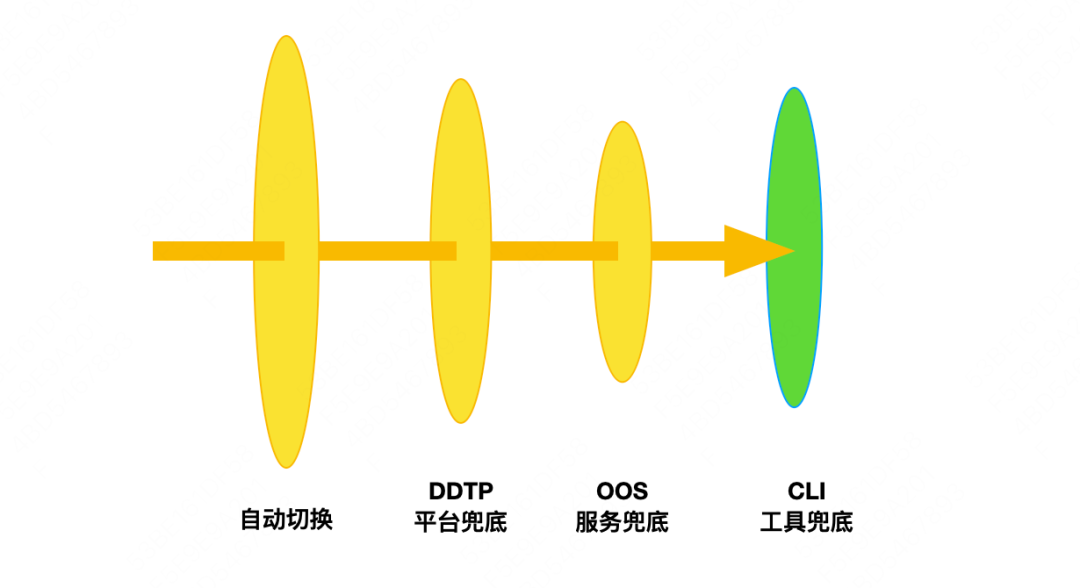
El principio general es dar prioridad a mejorar la tasa de éxito de la conmutación automática de alta disponibilidad y reducir el número de grupos en la transmisión transparente a la etapa ascendente. En segundo lugar, mejore la confiabilidad del plan, dé prioridad a la pantalla blanca, descienda paso a paso, reduzca la facilidad de uso y mejore la confiabilidad.
3.4.5 Recuperación después de una falla
Aunque el clúster tiene la capacidad N+1, cuando falla una sala de computadoras, los nodos restantes del clúster pueden admitir el tráfico máximo, pero no tiene la capacidad de recuperación ante desastres para otra falla AZ, por lo que después de la falla, según el recurso condiciones de cada sala de computadoras, a través de la capacidad El centro de toma de decisiones ante desastres expande rápidamente el clúster para complementar la capacidad de recuperación ante desastres del clúster principal, haciéndolo capaz de recuperación ante desastres AZ nuevamente.
Una de las grandes desventajas de la solución anterior es que necesita tener suficientes recursos para expandir la capacidad, lo cual es muy difícil.Actualmente, estamos construyendo capacidades de recuperación más rápidas, como la reparación en el lugar de las instancias, la expansión en el lugar de los clústeres. , etc. Después de la recuperación AZ, puede reutilizar rápidamente los recursos de la máquina en la sala de computadoras fallida y realizar una recuperación ante desastres y una recuperación rápida.
| 3.5 Construcción del sistema de perforación
Varias capacidades básicas de recuperación ante desastres no solo pueden existir a nivel de diseño de arquitectura y evaluación teórica, sino que deben ser utilizables en la práctica, lo que requiere verificación a través de simulacros. Al inicio del proyecto de gestión y control de la recuperación ante desastres, se formuló una estrategia basada en simulacros para verificar e impulsar la mejora de diversas capacidades básicas. Hasta el momento, se ha establecido preliminarmente un sistema de ejercicio de enlace largo, de alta frecuencia, a gran escala y en varios entornos.

Múltiples entornos : hemos creado una variedad de entornos de exploración para satisfacer las diversas necesidades de exploración de recuperación ante desastres de cada componente de PaaS. El primero es el entorno estable a largo plazo de la plataforma de gestión y control de recuperación ante desastres, el segundo es el entorno de aislamiento fuera de línea dedicado a los simulacros y el tercero es el entorno de producción, que tiene un área de simulacro y un entorno de producción normal.
Alta frecuencia : En la actualidad, puede alcanzar los niveles diarios y semanales. El nivel diario es un simulacro normalizado, que se inicia principalmente automáticamente en un entorno estable a largo plazo, y la escala del simulacro es de cientos de grupos; el nivel semanal es principalmente para simulacros reales regulares de corte de energía y red en entornos aislados y simulacros áreas
Gran escala : Es un simulacro realizado en el entorno de producción, que se utiliza para verificar las capacidades de procesamiento a gran escala y alta concurrencia de alta disponibilidad básica, planes de emergencia, planes de escape, recuperación de desastres y funciones de recuperación, y determinar el capacidad de servicio del sistema de gestión y control.
Vínculo largo : todo el vínculo de recuperación ante desastres involucra muchos componentes, incluida la base de datos CMDB, la base de datos de procesos, los componentes de alta disponibilidad, el centro de configuración, el servicio del plan, etc. Incorporaremos gradualmente estos componentes en el simulacro, permitiendo que uno o más componentes sirvan simultáneamente fallas, descubra problemas potenciales y verifique el impacto de fallas simultáneas de múltiples nodos de múltiples servicios en la capacidad general de manejo de fallas.
3.5.1 Simulacro de ambiente de aislamiento
Como su nombre indica, el simulacro de entorno aislado es un entorno de simulacro completamente aislado de la sala de cómputo de producción. Tiene sus propios TOR y gabinetes independientes. Los riesgos se pueden aislar completamente y se pueden realizar operaciones independientes de red o fallas de energía. Los componentes de PaaS y los servicios comerciales que participan en el simulacro deben implementarse de forma independiente en este entorno. En el entorno aislado, además de realizar regularmente varios simulacros de recuperación ante desastres para descubrir problemas de recuperación ante desastres, también puede verificar las capacidades de implementación independientes de cada PaaS, proporcionando una base para el soporte comercial internacional.
3.5.2 Simulacro de entorno de producción
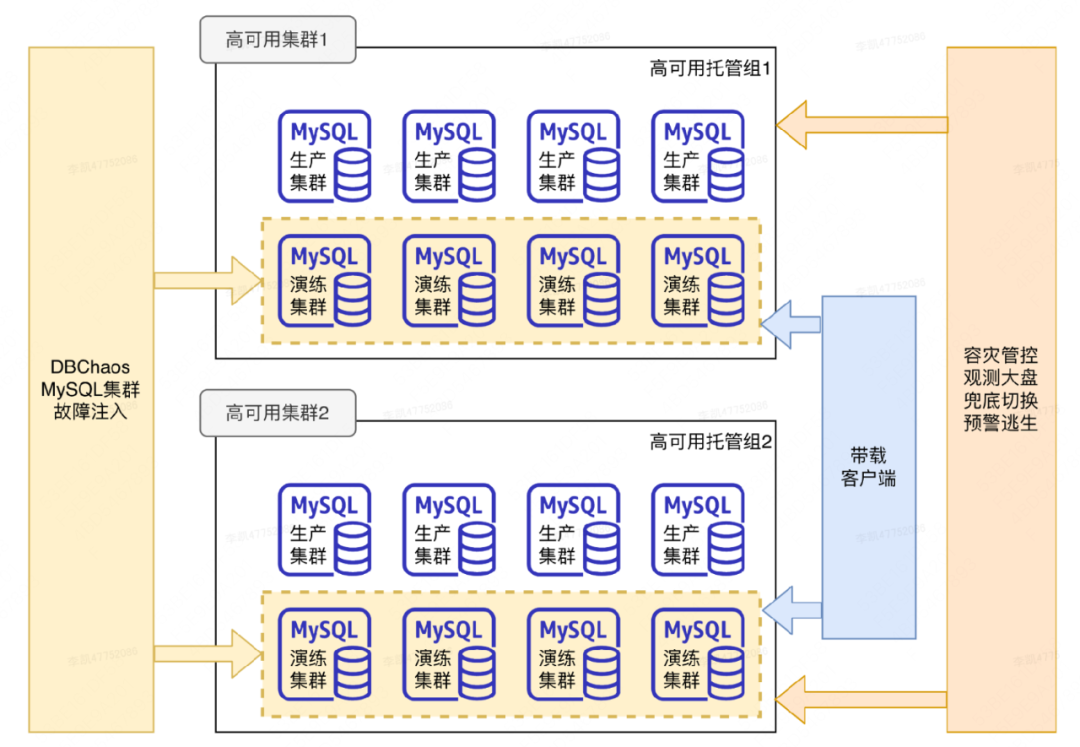
Simulacros de fallas normalizados y a gran escala : este tipo de simulacros se realizan de forma continua todos los días.Las fallas se inyectan en el clúster de la base de datos a través de la plataforma de perforación y se utiliza la alta disponibilidad para la conmutación por error. Verifique la capacidad de conmutación simultánea de alta disponibilidad a través de diferentes escalas de perforación. Además, en la plataforma de gestión y control de recuperación ante desastres, es posible verificar la capacidad de escape, el plan de stop loss y la observación de fallas a gran escala. Con todo, utiliza la combinación de "ataque" y "defensa" para realizar la verificación, aceptación y optimización de capacidades.
Las características principales de este tipo de simulacro son: primero, los clústeres participantes están alojados en el grupo de alta disponibilidad del entorno de producción, lo que significa que el simulacro verifica las capacidades de alta disponibilidad del entorno de producción; segundo, la gran escala Los clústeres que participan en el simulacro son clústeres no comerciales. Es un clúster recién creado que se usa especialmente para simulacros antes de cada simulacro. La escala puede ser muy grande. Actualmente, se pueden perforar más de 1500 clústeres al mismo tiempo. El tercero es tener un cierto efecto de simulación Para hacer que el ejercicio sea más realista y evalúe con precisión el RTO y aumente la capacidad de carga del grupo de ejercicios.
Simulacros de zona real : los simulacros de entorno aislado y los simulacros a gran escala descritos anteriormente son todos de naturaleza simulada y son bastante diferentes de los escenarios de fallas reales. Para compensar la brecha con la clave principal realmente defectuosa, construimos un simulacro AZ dedicado basado en la nube pública, que puede entenderse como una sala de computadoras independiente. Los componentes PaaS de negocios y componentes participantes implementan algunos nodos de servicio que transportan tráfico comercial al simulacro AZ. Durante el simulacro real, se realizará una desconexión real de la red. Los negocios y los componentes pueden observar y evaluar su propio estado de recuperación ante desastres cuando la red está desconectada. Será más realista verificar la recuperación de desastres real de componentes y servicios a través de salas de computación reales, clústeres de componentes reales y tráfico comercial real.
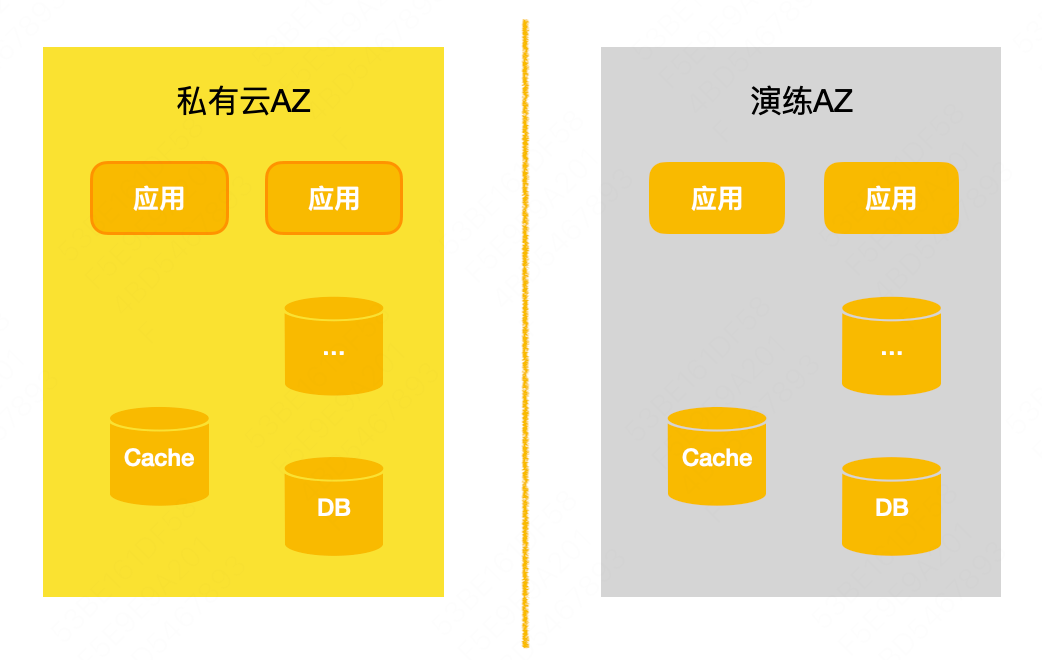
Game Day : Además, aún estamos evaluando y demostrando la viabilidad de realizar simulacros en salas de cómputo reales. Con la normalización de los simulacros de entornos aislados y los simulacros de áreas especiales, las capacidades básicas de recuperación ante desastres de cada componente serán cada vez más fuertes, y normalizado en salas de informática reales El objetivo final del simulacro de sala de informática también se logrará.
4 Pensamiento futuro
Después de más de dos años de construcción, aunque ha logrado ciertos resultados en conmutación automática de alta disponibilidad, gestión de operación de capacidad de recuperación ante desastres, observación de fallas a gran escala, plan de pérdida de parada de fallas, recuperación ante desastres y otros aspectos. Sin embargo, todavía hay muchas deficiencias en las capacidades que deben cubrirse, y los nuevos desarrollos comerciales también han traído nuevas necesidades y desafíos. En el futuro, continuaremos mejorando en dos direcciones: compensar las deficiencias e iterar la arquitectura técnica.
| 4.1 Compensar las deficiencias
Capacidad de escape a gran escala insuficiente y capacidad de detención de pérdidas : con la implementación de nuestro centro de datos autoconstruido, la escala de nuestro AZ autoconstruido será mayor, lo que tendrá mayores requisitos de capacidades. Mejoraremos gradualmente las capacidades principalmente a través de la plataforma iteración y verificación de ejercicios.
Las fallas en las líneas arrendadas entre dominios conducen a fallas en la alta disponibilidad a nivel de región : A continuación, exploraremos soluciones unificadas o soluciones de implementación independientes para lograr una administración de ciclo cerrado a nivel de región o más detallada.
Nuevos desafíos para las empresas que van al extranjero : ir al extranjero traerá nuevos requisitos y desafíos a la arquitectura de recuperación ante desastres. Ya sea para adoptar la "jurisdicción de brazo largo" o el despliegue independiente, ya sea para reutilizar el sistema de tecnología existente o crear una nueva arquitectura, estos problemas Todavía es necesario mejorar aún más la exploración y la demostración.
Eficiencia de recuperación ante desastres : las funciones básicas de la plataforma son relativamente completas, pero la toma de decisiones y la coordinación del procesamiento de recuperación ante desastres aún deben realizarse manualmente, y la eficiencia es relativamente baja. y otras capacidades se automatizarán gradualmente; simulacros multientorno El costo es relativamente alto, y los simulacros automatizados deben llevarse a cabo gradualmente para incorporar gradualmente los escenarios de perforación central en el entorno estable a largo plazo y permitir que se ejecuten automáticamente los escenarios de falla a través del tiempo o determinadas estrategias, solo debemos centrarnos en el funcionamiento de los indicadores básicos.
| 4.2 Arquitectura iterativa
Las tecnologías relacionadas con las bases de datos se están desarrollando rápidamente. Por ejemplo, se implementarán gradualmente nuevas tecnologías como Database Mesh y Serverless. En ese momento, el middleware, la alta disponibilidad y el kernel experimentarán cambios relativamente grandes. La introducción de productos de separación informática causará relativamente grandes cambios en las capacidades de recuperación ante desastres. La creación de capacidad de recuperación ante desastres se repetirá junto con estas evoluciones de productos determinadas.
La construcción de recuperación ante desastres es algo muy desafiante, y también es algo que todas las empresas deben enfrentar después de que su negocio crezca. Bienvenidos a todos a dejar un mensaje al final del artículo y comunicarse con nosotros.
5 Autores
Ruichao, de la plataforma básica de investigación y desarrollo de Meituan - departamento de tecnología básica.