Directorio de artículos
Visión de conjunto
Las redes neuronales convolucionales (CNN) y otras redes de aprendizaje profundo han logrado avances sin precedentes en una variedad de tareas de visión por computadora, desde clasificación de imágenes hasta detección de objetos, segmentación semántica, subtítulos de imágenes y respuesta visual a preguntas recientes. Aunque estas redes tienen un rendimiento superior, carecen de la capacidad de descomponerse en componentes intuitivos y comprensibles, por lo que es difícil explicarlas. Por lo tanto, cuando los sistemas inteligentes de hoy en día fallan, fallarán anormalmente sin advertencia o explicación, dejando a los usuarios mirando un resultado incoherente y preguntándose por qué.
La interpretabilidad de los modelos de aprendizaje profundo es esencial para generar confianza e integrarla con éxito en nuestra vida diaria. Para lograr este objetivo, la transparencia del modelo es útil para explicar por qué predicen lo que predicen.
En términos generales, esta transparencia es útil en las tres etapas de la evolución de la inteligencia artificial (IA).
-
Primero, cuando la inteligencia artificial es relativamente débil y no se puede “implementar” de manera confiable, el objetivo de la transparencia y la interpretación es identificar los modos de falla.
-
En segundo lugar, cuando la inteligencia artificial es comparable a los seres humanos y se puede "desplegar" de forma fiable, el objetivo es generar la confianza adecuada entre los usuarios.
-
En tercer lugar, cuando la inteligencia artificial es mucho más fuerte que los humanos, el objetivo de la explicación es la enseñanza automática, es decir, enseñar a los humanos cómo tomar mejores decisiones.
En el artículo anterior , discutimos el problema de interpretabilidad en redes neuronales convolucionales, y discutimos una técnica muy popular, a saber, Class Activation Map (Class Activation Map) o CAM, que se utiliza para resolver el problema hasta cierto punto. Este problema. Aunque CAM es una buena tecnología que puede desmitificar el trabajo de CNN y generar confianza en los clientes en las aplicaciones desarrolladas, están sujetas a algunas limitaciones. Una de las desventajas de CAM es que requiere que el mapa de características esté ubicado directamente antes de la capa softmax, por lo que es adecuado para una arquitectura CNN específica, es decir, para realizar un grupo de promedios globales en el mapa de convolución inmediatamente antes de la predicción. (Es decir, la función de conv mapea la capa softmax de agrupación promedio global). Esta arquitectura puede ser menos precisa que la red general en algunas tareas, o puede que no sea adecuada para nuevas tareas en absoluto.
En este artículo, discutiremos una generalización de CAM, la llamada CAM gradiente. "Grad-cam" se publicó en 2017. Tiene como objetivo mejorar las deficiencias de CAM y pretende ser compatible con cualquier tipo de arquitectura. La tecnología no requiere ninguna modificación a la arquitectura del modelo existente, lo que permite que sea aplicable a cualquier arquitectura basada en CNN, incluidas arquitecturas para subtítulos de imágenes y respuesta visual a preguntas. Para la arquitectura convolucional completa, grad-cam se reduce a CAM.
método
Varios estudios previos han afirmado que el desempeño más profundo en CNN captura la mejor estructura de alto nivel. Además, CNN volverá a entrenar naturalmente la información espacial perdida en la capa completamente conectada, por lo que podemos esperar que la capa convolucional final tenga la mejor compensación entre la semántica de alto nivel y la información espacial detallada.
Gradcam es diferente de CAM en que utiliza la información de gradiente que fluye hacia la última capa convolucional de CNN para comprender cada neurona y tomar decisiones interesantes. Para obtener un mapa de posicionamiento discriminatorio de clases de cualquier ancho u de tipo c y altura v, primero calculamos el gradiente de puntuación del yc de tipo c (antes de softmax) para el mapa de características Ak de la capa convolucional. El gradiente de estos reflujos es un conjunto promedio global para obtener el peso importante ak de la clase de neuronas objetivo.
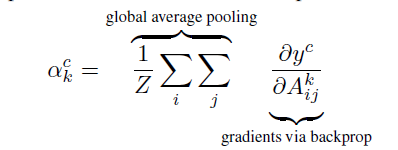
Después de calcular el ak de la clase objetivo c, realizamos una combinación de mapeo de activación ponderada y seguimos su ReLU.
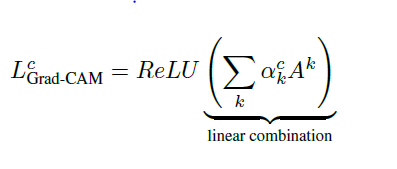
Esto producirá un mapa de calor aproximado del mismo tamaño que el mapa de características convolucional. Aplicamos ReLU a combinaciones lineales porque solo nos interesan las características que tienen un efecto positivo en la clase de interés. Si no hay ReLU, el mapeo de activación de clases enfatizará más contenido, logrando así un desempeño de posicionamiento más bajo.
La siguiente figura muestra el flujo completo de cada tarea de visión por computadora para comprender este importante concepto con mayor claridad.

Proceso de implementación
- Primero, necesitamos un modelo para ejecutar operaciones de avance. Usamos VGG16 previamente entrenado en Imagenet. Puede utilizar cualquier modelo, porque GradCam no requiere una arquitectura específica como CAM, y es compatible con cualquier red neuronal convolucional.
model = VGG16(weights='imagenet')
- Después de definir el modelo, cargamos una imagen de muestra y la preprocesamos para que sea compatible con el modelo.
def preprocess(img):
img = img_to_array(img)
img = np.expand_dims(img,axis=0)
img = preprocess_input(img)
return img
image_1 = preprocess(image)

- Luego use el modelo para predecir la imagen de muestra y decodificar las tres primeras predicciones. Como puede ver en la imagen a continuación, solo consideramos las tres primeras predicciones del modelo, y la predicción del modelo superior es el boxeador.
predict = model.predict(image_1)
print(decode_predictions(predict,top=3))
target_class = np.argmax(predict[0])
print("Target Class = %d"%target_class)
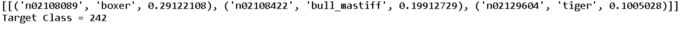
- A continuación, encontramos el gradiente de la puntuación de la clase objetivo yc con respecto al mapa de características Ak de la última capa convolucional. Nos dice intuitivamente la importancia de cada canal para la clase objetivo. La variable gradiente devuelve un tensor, que se utilizará en los siguientes pasos.
last_conv = model.get_layer('block5_conv3')
grads = K.gradients(model.output[:,242],last_conv.output)[0]
- Luego, el gradiente obtenido se somete a un conjunto de promedios globales y se obtiene el peso de neurona importante ak correspondiente a la clase diana, como se muestra en la Figura 1. Esto devolverá un tensor que se pasa a la función Keras, que toma la imagen como entrada y devuelve pooled_gradient y el mapa de activación de la última capa convolucional.
pooled_grads = K.mean(grads,axis=(0,1,2))
iterate = K.function([model.input],[pooled_grads,last_conv.output[0]])
pooled_grads_value,conv_layer_output = iterate([image_1])
- Después de eso, multiplicamos cada mapa de activación con el gradiente de mezcla correspondiente, y estos gradientes se utilizan como pesos para determinar la importancia de cada canal para la clase objetivo. Luego, tome el promedio de todos los mapas de activación en el canal para obtener el mapa final de prominencia discriminante de clases.
for i in range(512):
conv_layer_output[:,:,i] *= pooled_grads_value[i]
heatmap = np.mean(conv_layer_output,axis=-1)

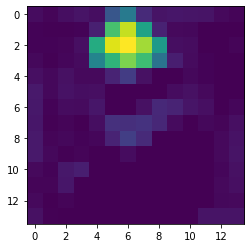
- Luego aplicamos ReLU al mapa de calor generado para mantener solo las características que tienen una influencia positiva en el mapa de calor de salida. Pero vemos que no hay muchas intensidades negativas en el mapa de calor, por lo que no hay mucho cambio en el mapa de calor después de aplicar ReLU.
for x in range(heatmap.shape[0]):
for y in range(heatmap.shape[1]):
heatmap[x,y] = np.max(heatmap[x,y],0)

- Luego separamos cada valor de intensidad del mapa de calor del valor de intensidad máxima para normalizar el mapa de calor de modo que todos los valores estén entre 0 y 1.
heatmap = np.maximum(heatmap,0)
heatmap /= np.max(heatmap)
plt.imshow(heatmap)
- Finalmente, aumentamos la muestra del mapa de calor obtenido para que coincida con el tamaño de la imagen de entrada y lo superponemos en la imagen de entrada para ver el resultado.
upsample = resize(heatmap, (224,224),preserve_range=True)
plt.imshow(image)
plt.imshow(upsample,alpha=0.5)
plt.show()

En conclusión
En este artículo, aprendimos una nueva técnica para explicar las redes neuronales convolucionales, que es una arquitectura de vanguardia, especialmente adecuada para tareas relacionadas con imágenes. Grad Cam ha mejorado su predecesor, Cam, y proporciona un mejor posicionamiento y un mapa claro de diferencia de clase, que nos guía para descubrir la complejidad detrás del modelo similar a una caja negra. La investigación en el campo del aprendizaje automático interpretable se está desarrollando a un ritmo más rápido, lo cual es fundamental para generar confianza en el cliente y ayudar a mejorar los modelos.