https://zhuanlan.zhihu.com/p/35405071
论文地址: MobileNetv1
Howard, Andrew G., et al. "Mobilenets: redes neuronales convolucionales eficientes para aplicaciones de visión móvil". preimpresión de arXiv arXiv: 1704.04861 (2017).
1. Introducción
Mobilenet v1 es una arquitectura de red lanzada por Google en 2017. Su objetivo es aprovechar al máximo los recursos limitados de los dispositivos móviles y las aplicaciones integradas para maximizar de manera efectiva la precisión del modelo para cumplir con varios casos de aplicaciones con recursos limitados. Mobilenet v1 también se puede utilizar para tareas como clasificación, detección, incrustación y segmentación para extraer características de convolución de imágenes como otros modelos populares (como VGG y ResNet).
Primero, la convolución separable de la profundidad del núcleo Profundidad cnn + Pointwise cnn
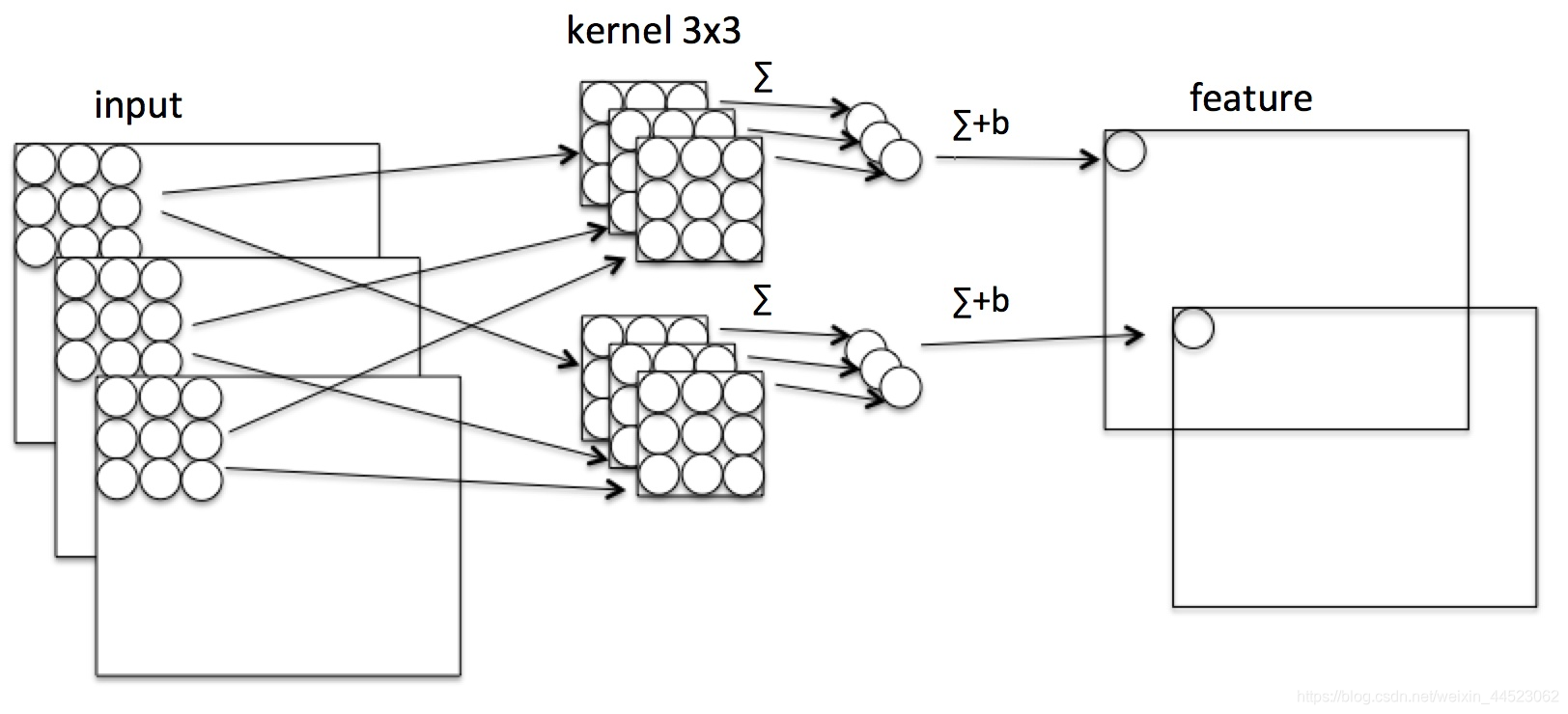
La imagen de arriba es la convolución ordinaria,
kernel-channel = canal de entrada, scan input-img (HW) correspondiente punto para multiplicar, luego suma
canal de salida =
cantidad de cálculo de multiplicación kernel-num : F = [Ci x 3 x 3] x (H x W) x Co # La salida C aquí es equivalente al número de núcleo
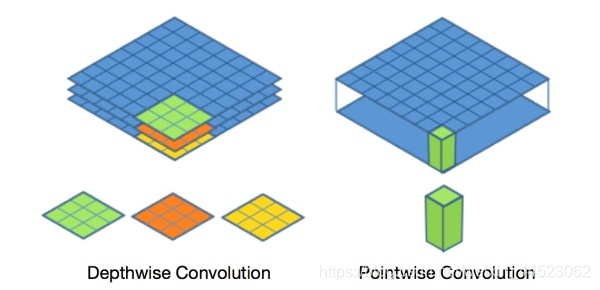
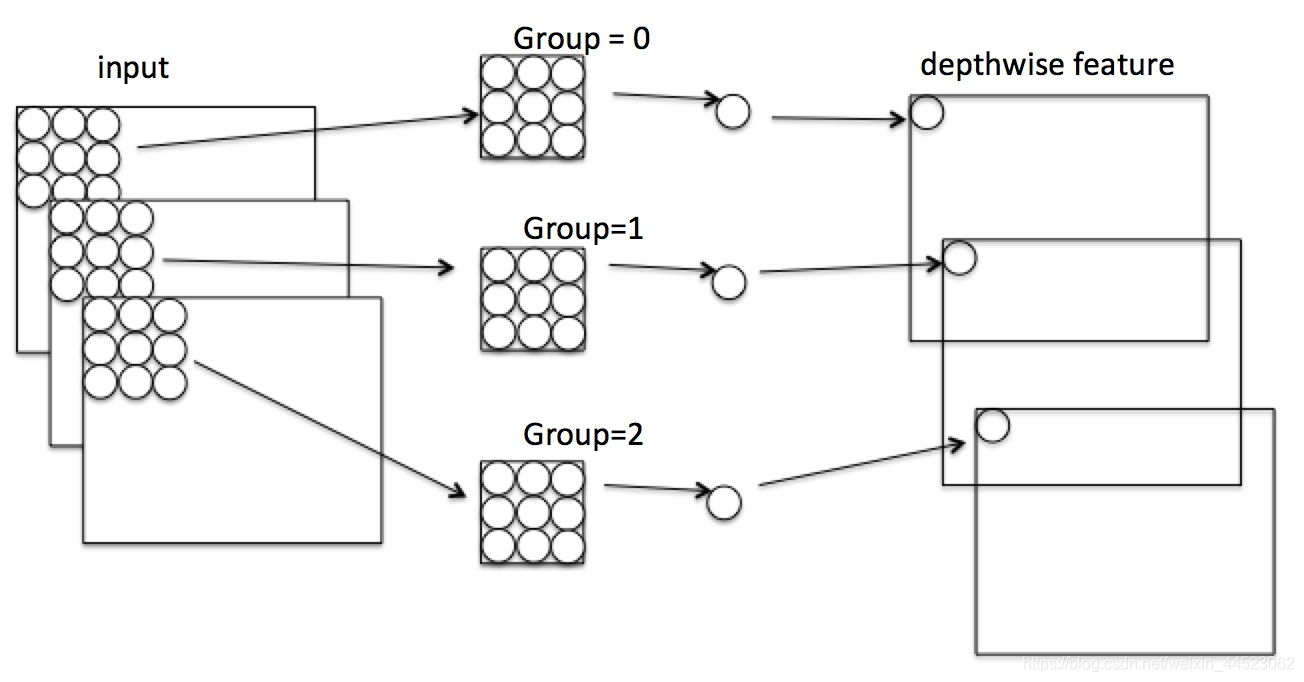
. La figura anterior es convolución en profundidad. Cada canal se separa por convolución para obtener la HW C img, y luego 1 * 1 convolución Fusion)
Cálculo de multiplicación
- 1 Convolución de separación de profundidad en la imagen de la izquierda: F1 = [Ci x 3 x 3] x [H x W]
- 2 convolución 1x1 a la derecha: F2 = [Ci 1 x 1 x 1] x [H x W] x Co
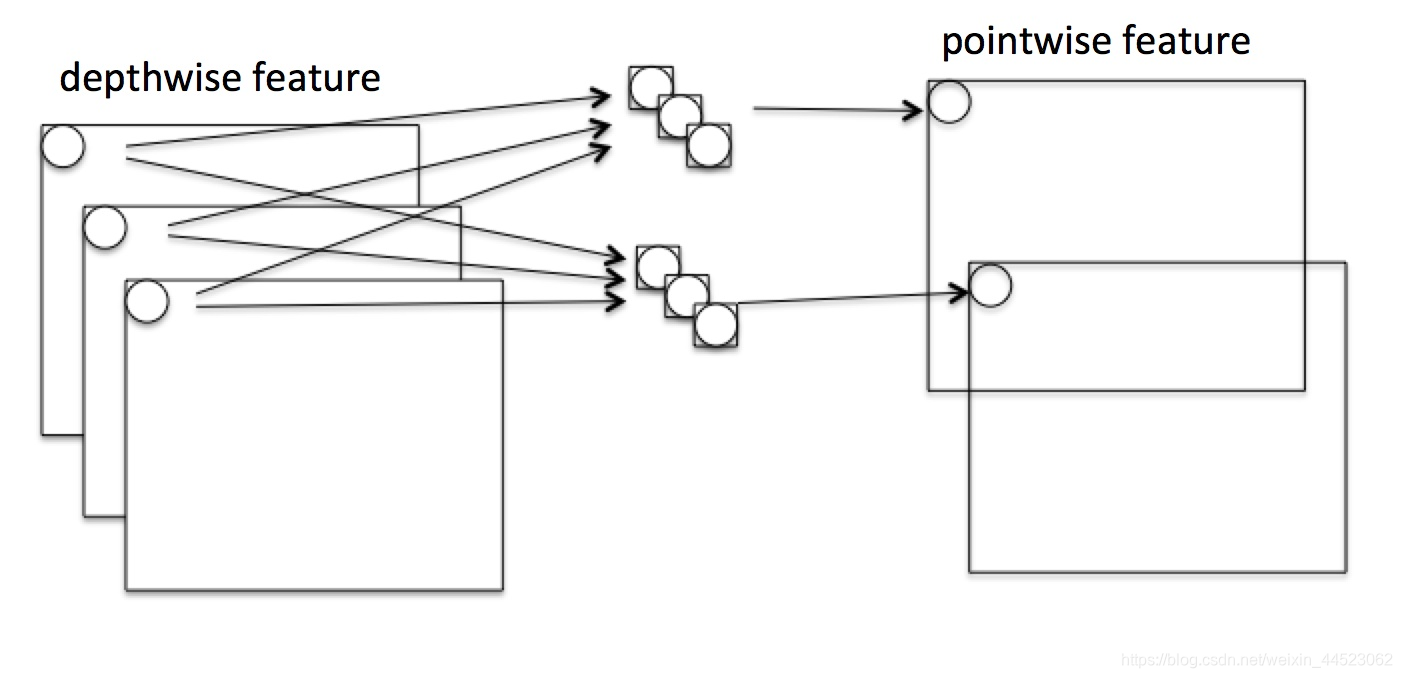
[en profundidad + Piontwise] / cálculo CNN ordinario = 1 / Co + 1/9
(donde Co es el canal de imagen de salida El número es el siguiente: la convolución separable en profundidad reemplaza la CNN ordinaria por un BN más
(
2 modelo de red

El siguiente paquete, puede verse que vgg similares apilados
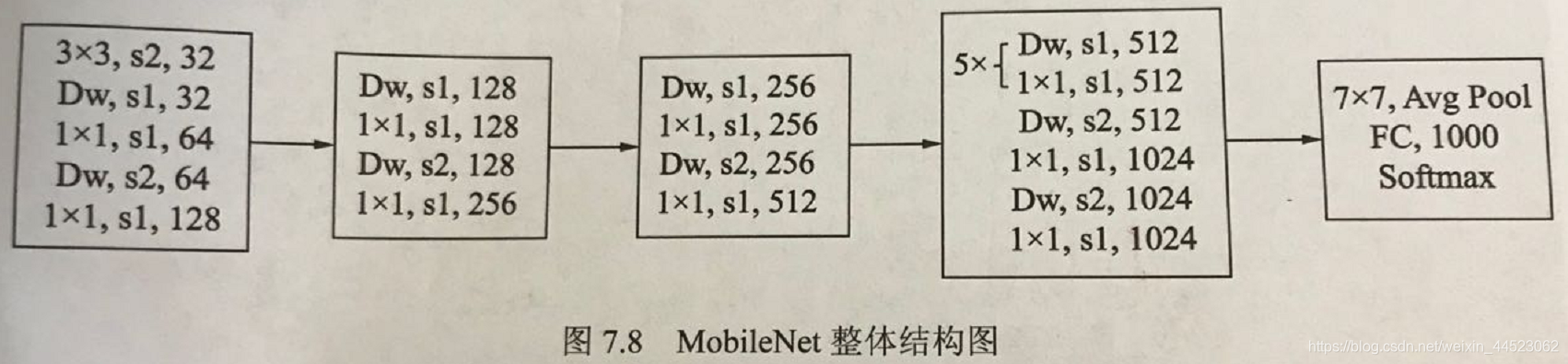
vgg16

se proporcionan dos parámetros súper para controlar el tamaño y la cantidad de modelo de cálculo
- Multiplicador de ancho: se usa para controlar el número de canales, Afa a, cuando <1, el modelo se reducirá y la cantidad de cálculo se reducirá a a²
- Multiplicador de resolución: utilizado para controlar el tamaño del mapa de características, denotado como p, la aplicación de este multiplicador en el mapa de características correspondiente puede reducir la cantidad de cálculo
Se agrega un hiperparámetro α∈ [0,1] para controlar el número de canales del mapa de características: cuanto más pequeño es el alfa, más pequeño es el modelo. La función es cambiar el número de canales de entrada y salida, reducir el número de mapas de características y hacer que la red sea más delgada
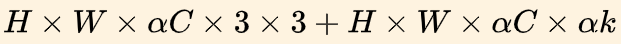
.
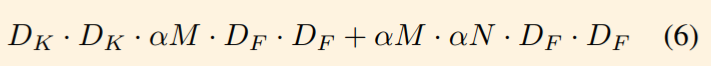
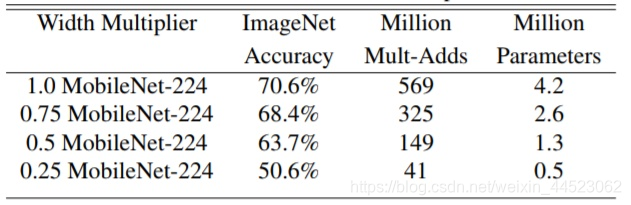
Por supuesto, comprimir el cálculo de la red debe tener un precio. La Figura 11 muestra el rendimiento de [Fórmula] Mobilenet v1 en ImageNet en diferentes momentos. Se puede ver que incluso con [Fórmula] Mobilenet v1 todavía tiene una precisión del 63.7% en ImageNet.
Se agrega un hiperparámetro ρ para controlar la resolución de la imagen de entrada. Cuanto más pequeña sea la ρ, menor será la imagen de entrada.
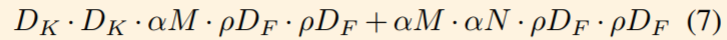

Resultados
1 clasificación
Bajo la premisa de que la cantidad de cálculo y el tamaño del parámetro se reducen muchas veces, acc es equivalente al
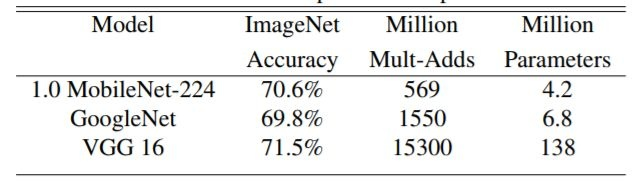
tamaño de la imagen de entrada de Googlenet y VGGnet.
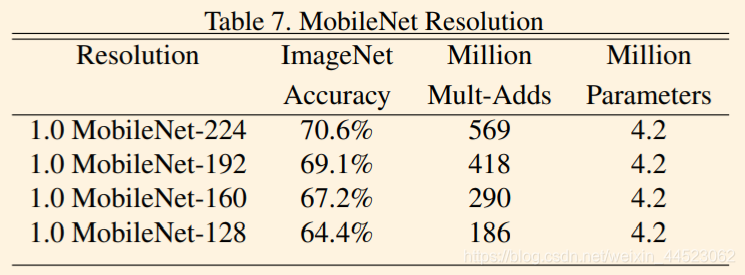
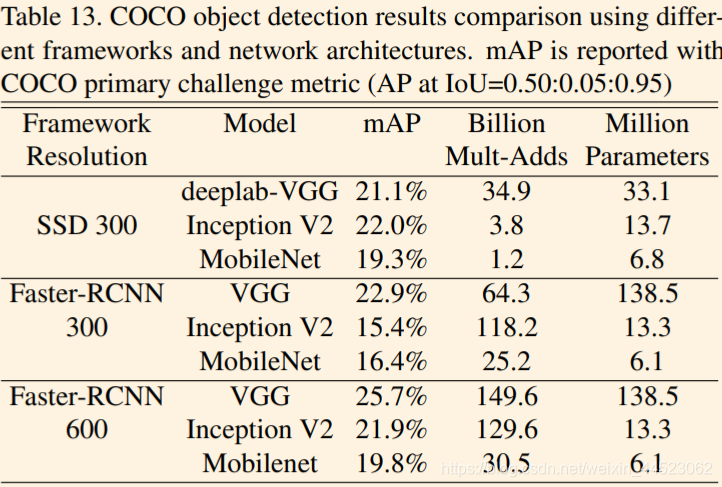
2 Detección de objetivos, que es bastante diferente del mAP de una red grande, pero la cantidad de cálculo cae mucho
3 clasificación de la cara
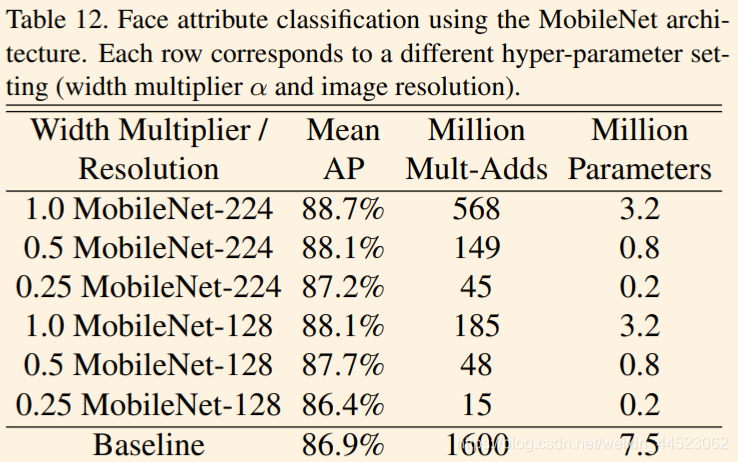
知识 蒸馏 , Facenet 教 Mobilenet 学习 识别 人 脸
El modelo FaceNet es un modelo de reconocimiento facial de última generación [25]. Construye incrustaciones faciales basadas en la pérdida de triplete. Para construir un modelo móvil de FaceNet, utilizamos la destilación para entrenar minimizando las diferencias al cuadrado de la salida de FaceNet y MobileNet en los datos de entrenamiento. Los resultados para modelos MobileNet muy pequeños se pueden encontrar en la tabla 14.
Interludio: ¿Cuál es la destilación del conocimiento que se propuso en 2015?
Papeles
lo que el conocimiento de destilación es: Que tenemos que hacer la distribución softmax del nuevo modelo y la lucha en parejas reales, y ahora sólo tenemos que dejar que el nuevo modelo y el modelo original adaptado a Softmax en una línea de distribución de entrada dado (nueva aproximación de funciones de la función original)
modelo de los productos crudos Un cierto logits es [fórmula], el logits generado por el nuevo modelo es [formula] para
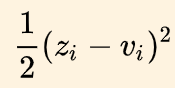 hacer que esta función sea cercana a 0.
hacer que esta función sea cercana a 0.
En la química del algoritmo de propagación inversa , la destilación es un método efectivo para separar componentes con diferentes puntos de ebullición. Los pasos generales son Primero se aumenta la temperatura para vaporizar los componentes de bajo punto de ebullición, y luego se enfría y condensa para lograr el propósito de separar la sustancia objetivo. En el proceso mencionado anteriormente, primero dejamos que la temperatura [fórmula] aumente, y luego restauramos la "temperatura baja" durante la fase de prueba, para extraer el conocimiento en el modelo original, por lo que es realmente bueno llamarlo destilación
class MobileNetv1(nn.Module):
def __init__(self):
super(MobileNetv1, self).__init__()
def conv_bn(dim_in, dim_out, stride):
return nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, stride, 1, bias=False),
nn.BatchNorm2d(dim_out),
nn.ReLU(inplace=True)
)
def conv_dw(dim_in, dim_out, stride):
return nn.Sequential(
nn.Conv2d(dim_in, dim_in, 3, stride, 1, groups= dim_in, bias=False),
nn.BatchNorm2d(dim_in),
nn.ReLU(inplace=True),
nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=False),
nn.BatchNorm2d(dim_out),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn( 3, 32, 2),
conv_dw( 32, 64, 1),
conv_dw( 64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 20)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
Resumen
- Use Depthwise y Pointwise para lograr una separación profunda y reducir la cantidad de cálculo y el tamaño del modelo
(baja latencia y tamaño del modelo mencionados repetidamente en el artículo) - El modelo es más retro, similar al apilamiento vgg, sin residuos, fusión de características y otras tecnologías.
- Desventajas: cada canal de convolución de descomposición en profundidad es independiente, la dimensión del núcleo de convolución es pequeña, solo hay pocas características de entrada en la función de salida, además, relu es fácil convertirse en cero, la extracción de características del tutor falla y el núcleo de convolución es redundante
Su propio código de pytorch del resultado del experimento (sin ajuste)
6 mobilenetv1 2080 t-bs: 64 v-bs: 64 lr: 0.01 100epoch
El conjunto de datos clasificación GHIM-20, básicamente ajustado en época = 8000 x 64/9000 = 57 rondas

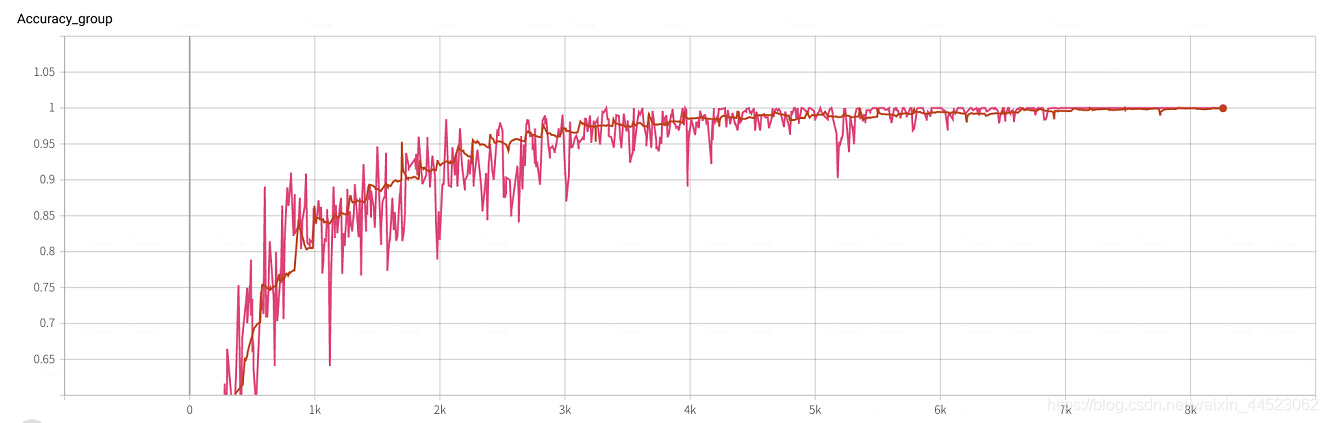

Además: El experimento sobre los factores influyentes de la capacitación básica en redes de clasificación es el siguiente blog, que estudia el efecto de la tasa de aprendizaje del kernel por lotes en la calidad del modelo de capacitación
https://blog.csdn.net/weixin_44523062/article/details/105457045
